




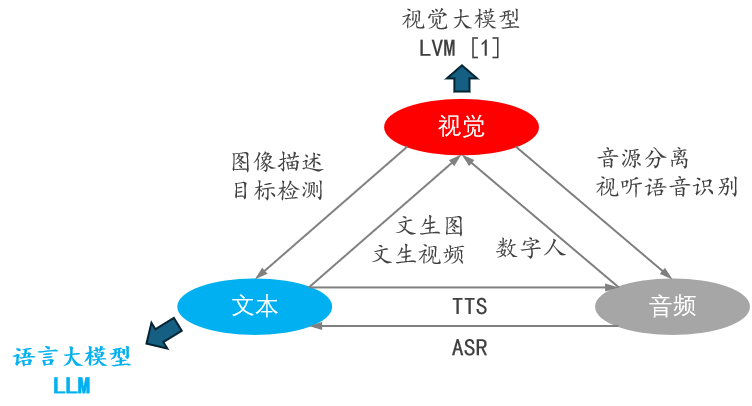
1 多模态大语言模型(MLLM)的定义
1.1 模态与MLLMs的定义
-
模态的定义:模态(modal)是事情经历和发生的方式,我们生活在一个由多种模态(Multimodal)信息构成的世界,包括视觉信息、听觉信息、文本信息、嗅觉信息等等;

-
MLLMs 的定义:由LLM扩展而来的具有接收与推理多模态信息能力的模型;

1.2 几个概念的区分
1.2.1 单模态模型
-
输入的是一种模态,输出的也是同一种模态;
-
比如输入的是文本,输出的也是文本;
-
视觉单模态大模型的 Prompts 是图片。给定一些图像序列,模型从中发现一些规律,然后生成一张新的图片;

1.2.2 跨模态大模型
- 输入的是一种模态,却输出另一种模态;
- 比如输入的是一段视频,输出的却是一段音频;
-
比较具有代表性的案例:数字人。比如一个老师在讲课,有一个虚拟形象可以根据老师的口型和语气,也输出类似的表情和语气;
-
下面是一些开源项目推荐:
-
西安交大、腾讯:SadTalker。CVPR 2023] SadTalker:Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation;
西安交大、腾讯:SadTalker
- 浙大、字节:Real3D-Portrait。yerfor/Real3DPortrait: Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis; ICLR 2024 Spotlight; Official code;
浙大、字节:Real3D-Portrait
-
腾讯游戏:Ani-Portrait。Zejun-Yang/AniPortrait: AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation;
-
蚂蚁:EchoMimic。AAAI 2025] EchoMimic:通过可编辑的地标调节实现逼真的音频驱动肖像动画;
蚂蚁:EchoMimic1
蚂蚁:EchoMimic2
- 快手、中科大、复旦:LivePortrait。KwaiVGI/LivePortrait: Bring portraits to life!;
快手、中科大、复旦:LivePortrait1
-
Facebook Research:Audio2Photoreal。facebookresearch/audio2photoreal: 由音频驱动的逼真编解码器头像的代码和数据集;
-
TTS、音色克隆、少样本:GPT-SoVITS。RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning);
TTS、音色克隆、少样本:GPT-SoVIT
-
ChatTTS。2noise/ChatTTS: A generative speech model for daily dialogue.;
-
SUNO:文本/歌词 -> 音乐生成。My account | Suno;
-
开源的文生音频工具推荐:(文生声音、文生音乐):
- MetaAI:facebookresearch/audiocraft: Audiocraft is a library for audio processing and generation with deep learning. It features the state-of-the-art EnCodec audio compressor / tokenizer, along with MusicGen, a simple and controllable music generation LM with textual and melodic conditioning.;
- StabilityAI:huggingface.co/stabilityai/stable-audio-open-1.0。
1.2.3 多模态模型
-
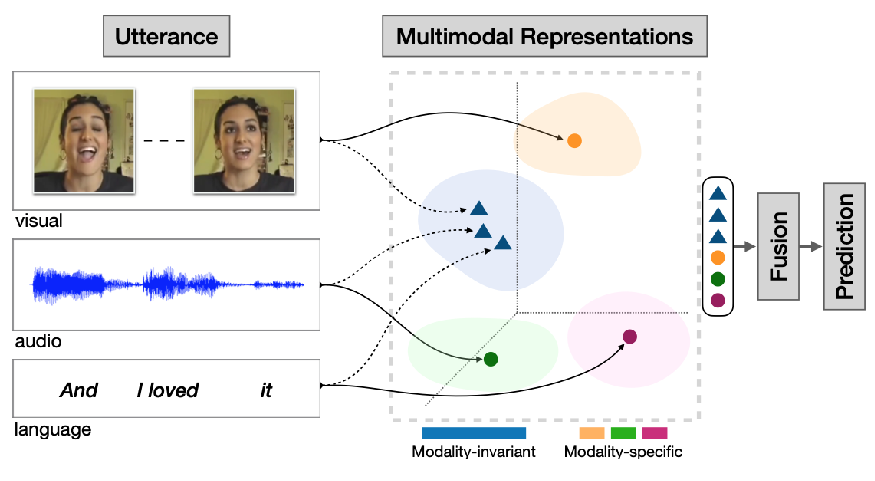
下面是关于多模态表示(Multimodal Representations)的示意图,展示了如何融合视觉(visual)、音频(audio)和语言(language)三种模态信息来进行预测(Prediction);
-
输入部分
- 视觉模态(visual):图中展示了人物面部表情的图像,表明通过捕捉面部表情等视觉信息作为输入。比如可以是视频中人物说话时的表情变化,不同表情可能传达不同情感等信息;
- 音频模态(audio):以音频波形的形式呈现,代表说话时的语音信息,包含语调、语速、音量等特征。例如,激动时可能语速加快、音量增大,这些音频特征都能传递情感或意图等信息;
- 语言模态(language):以文本 “And I loved it” 为例,体现语言层面的语义信息,即说话的具体内容;
-
多模态表示部分
-
模态不变(Modality - invariant)与模态特定(Modality - specific):图中右侧的坐标区域代表多模态表示空间。其中不同颜色区域和点表示不同模态信息在该空间中的分布;
-
蓝色三角形:代表模态不变信息,即各个信息中的共性部分,这意味着这些信息在不同模态中具有一致性,不依赖于特定模态。例如,表达积极情感时,可能在视觉(如微笑表情)、音频(欢快语调)和语言(正面词汇)上都有体现,这些共性信息就是模态不变的;
-
其他颜色的点(橙色、绿色、紫色等):代表各个模态的特定信息,是每个模态独有的特征。比如视觉模态中人物的独特面部特征、音频模态中独特的音色等;
-
-
-
融合与预测部分
- 融合(Fusion):将来自不同模态(视觉、音频、语言)的表示信息汇聚在一起,整合各模态的优势;
- 预测(Prediction):经过融合后的多模态信息用于最终的预测任务,例如情感分析(判断话语表达的是积极、消极还是中性情感)、意图识别(判断说话者的目的)等。
-
1.2.4 多模态大语言模型
-
由LLM扩展而来的具有接收与推理多模态信息能力的模型:
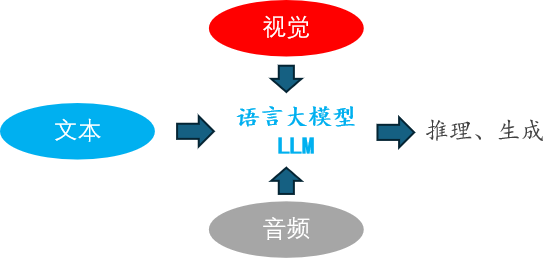
2 多模态(图-文)模型的发展历程
- 以 视觉-文本 多模态模型 为例,有四个关键里程碑。
2.1 Vision Transformer(ViT)模型
-
ViT 模型实现了图像表示的 token 化;
- 左侧展示了像素化图像;
- 右侧是图像像素数值矩阵;

-
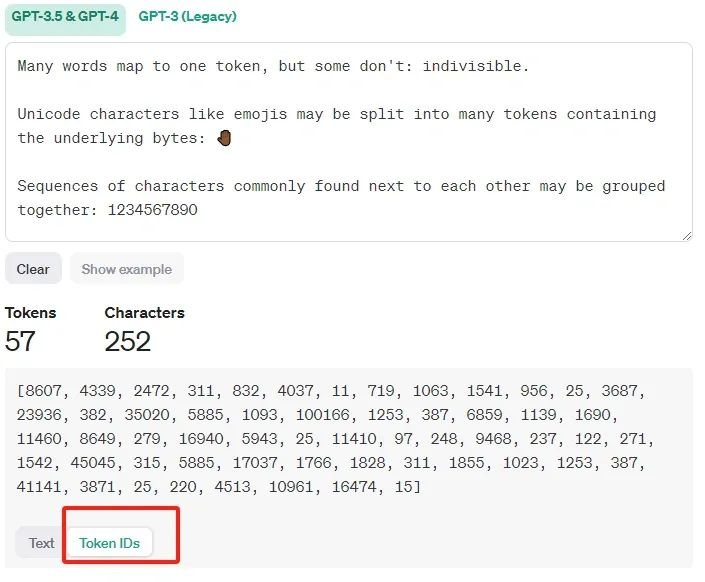
下面通过 GPT - 3.5 & GPT - 4 相关界面,呈现文本的 Tokens 和 Characters 数量,以及 Token IDs ;
- 示例说明单词与 token 的映射关系,有的单词对应一个 token,有的不是 ;
- 像表情符号等 Unicode 字符会被拆分,常相邻字符序列可能会被归为一组;
-
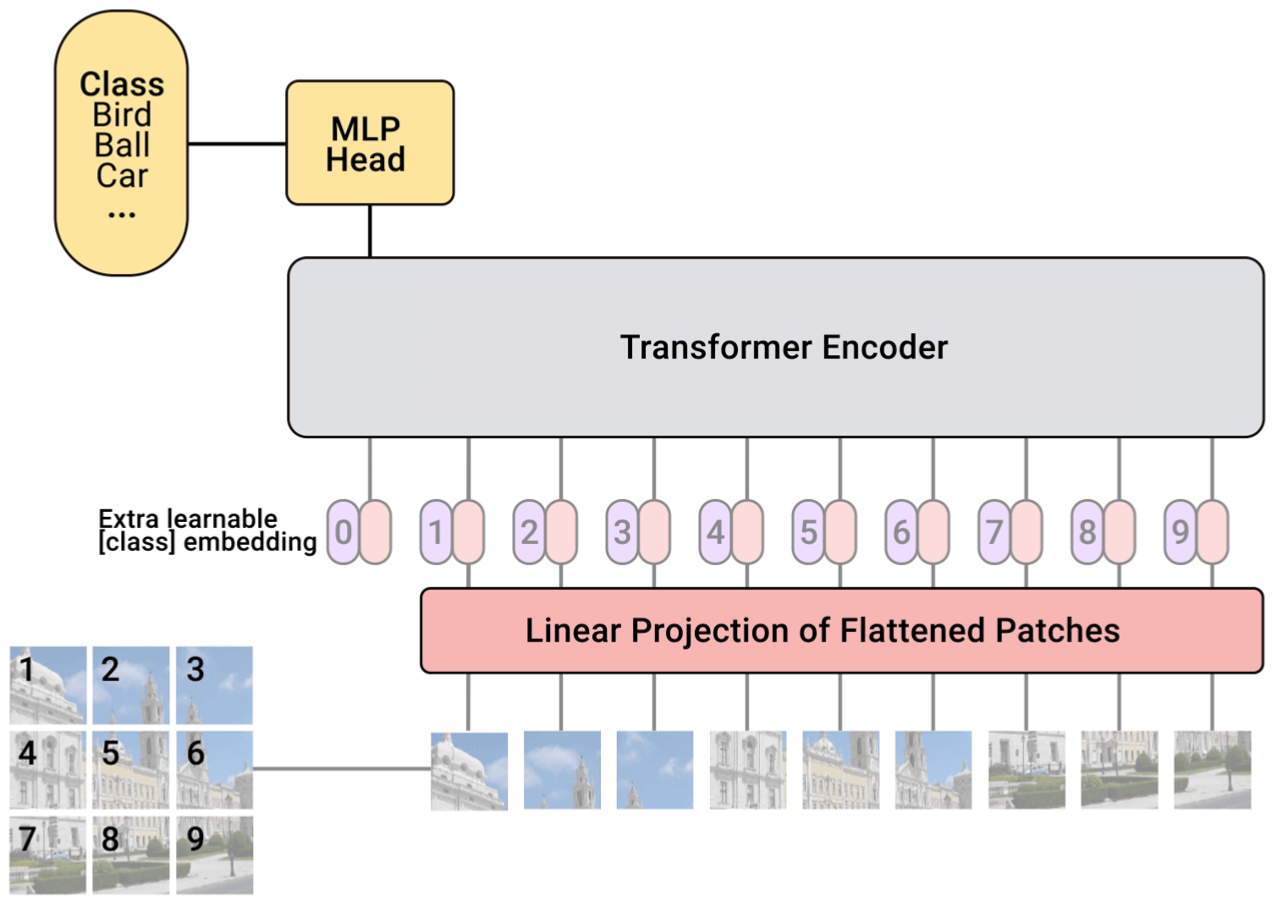
Vision Transformer(ViT)模型的结构:
- 输入部分:图像被分割成多个小块(如左下角的九宫格图像块 ),这些小块经过 “Linear Projection of Flattened Patches”(扁平图像块的线性投影)处理,将图像块转化为适合模型处理的特征向量;
- 特征处理部分:在特征向量前添加一个可学习的 “class” 嵌入(Extra learnable [class] embedding ),与其他图像块特征一起输入到 “Transformer Encoder”(Transformer 编码器)中 。Transformer 编码器通过自注意力机制等操作对这些特征进行处理,捕捉图像块之间的关系;
- 输出部分:Transformer 编码器的输出连接到 “MLP Head”(多层感知器头) ,MLP Head 根据编码器输出的特征进行分类,判断图像属于 “Bird”“Ball”“Car” 等类别中的哪一类;
-
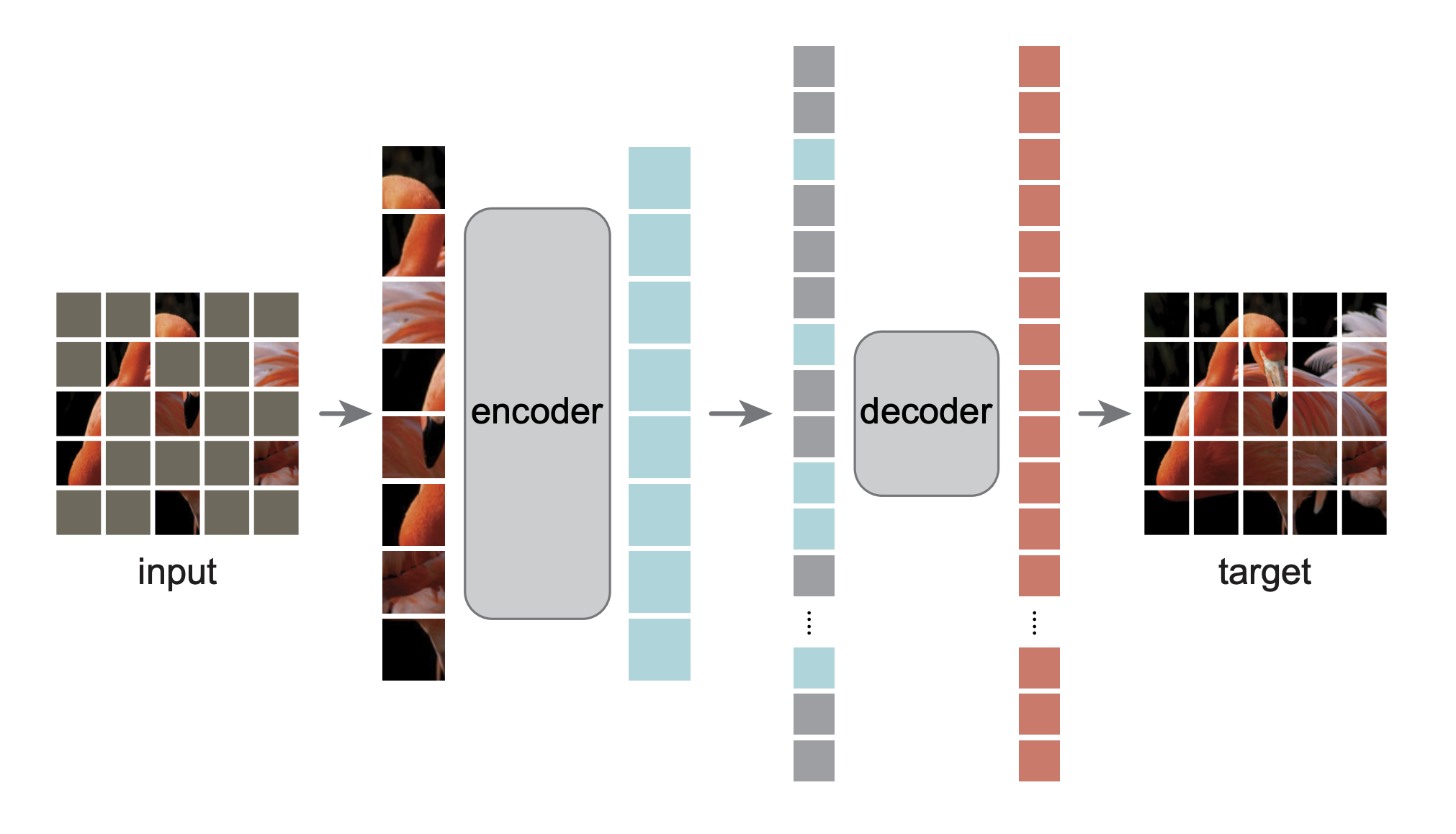
ViT 模型采用 Mask Image Modeling(掩码图像建模)进行无监督图像特征学习;
- 下图展示了输入图像经分块处理后,通过 encoder(编码器)、decoder(解码器),最终恢复为目标图像的过程,体现模型学习图像特征、重建图像的机制;
2.2 基于 Transformer 的图-文联合建模
-
以VisualBert为例:
- 左侧:展示一张人物打网球图片及对应英文描述“A person hits a ball with a tennis racket”;
- 右侧:是VisualBert模型架构示意;
- 图像和文本信息分别处理成特征向量(如文本的 e 1 e_1 e1 - e N e_N eN ,图像的 f 1 f_1 f1 - f K f_K fK ),添加位置、片段等信息后输入Transformer;
- Transformer对联合特征处理,输出用于两个目标(Objective 1和Objective 2 );
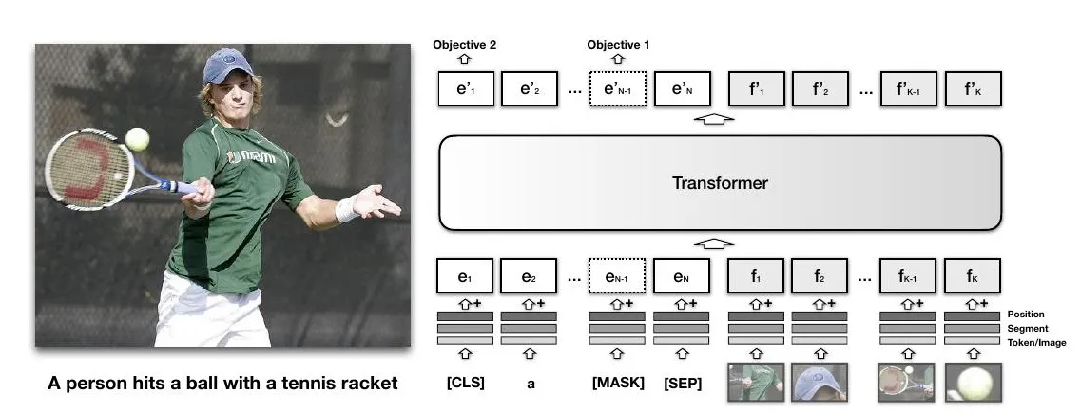
-
通过联合建模,让模型学习图像和文本间潜在对齐关系 ,比如理解图片中人物动作、使用的网球拍等视觉元素与文本描述的对应联系。
2.3 大规模图-文 Token 对齐模型:CLIP
2.3.1 CLIP 模型
-
基于4亿的互联网上采集的图文对训练的;
-
工作原理:
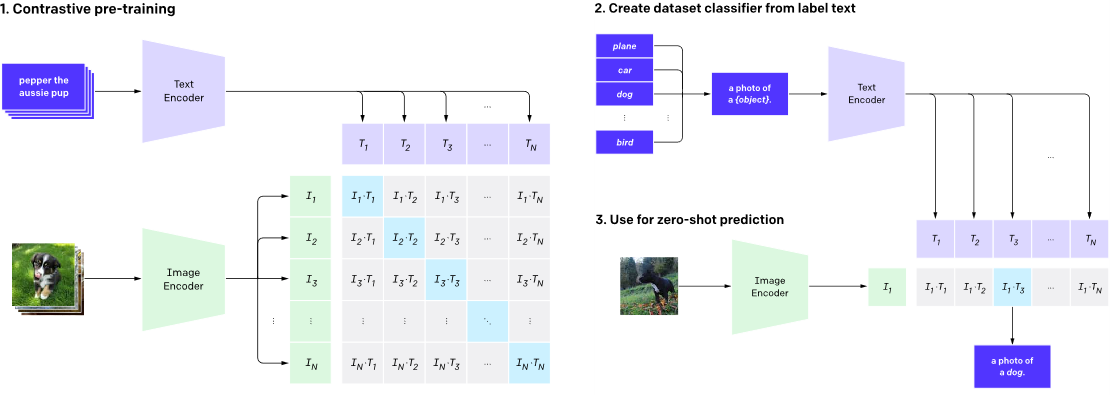
- Contrastive pre-training(对比预训练):
- 文本处理:将文本(如“pepper the aussie pup” )输入Text Encoder(文本编码器),得到文本特征向量 T 1 T_1 T1 - T N T_N TN;
- 图像处理:把图像输入Image Encoder(图像编码器),得到图像特征向量 I 1 I_1 I1 - I N I_N IN;
- 对比学习:构建特征向量组合矩阵,通过对比学习让模型学习图像和文本特征间对应关系,使匹配的图文对(如特定文本描述对应图像)特征更接近;
- Create dataset classifier from label text(从标签文本创建数据集分类器):
- 将标签文本(如“plane”“car”“dog”“bird”等 )加上前缀(如“a photo of a {object}” )后输入Text Encoder,得到文本特征向量 T 1 T_1 T1 - T N T_N TN ,用于构建分类器;
- Use for zero-shot prediction(用于零样本预测):
- 将未知图像输入Image Encoder得到特征向量 I 1 I_1 I1 ,与之前得到的文本特征向量计算相似度,找出相似度最高的文本描述(如“a photo of a dog” ),实现零样本预测,即在未见过的图像类别上进行分类预测;
- Contrastive pre-training(对比预训练):
-
OpenAI的开源 CLIP 模型地址:openai/clip-vit-base-patch32 at main,示例:
-
识别下面的图片:

-
代码:
from transformers import CLIPProcessor, CLIPModel import os from PIL import Image # 获取当前文件所在目录 current_dir = os.path.dirname(os.path.abspath(__file__)) # 获取model文件夹所在目录 model_dir = os.path.join(current_dir, "model") # 拼接 clip-vit-base-patch32 文件夹路径 clip_vit_base_patch32_path = os.path.join(model_dir, 'clip-vit-base-patch32') # 模型名称 MODEL_NAME = clip_vit_base_patch32_path model = CLIPModel.from_pretrained(MODEL_NAME) processor = CLIPProcessor.from_pretrained(MODEL_NAME, use_fast=True) # 启用快速处理器 # 打开并显示图片 image = Image.open("data_examples/truck.png") # image.show() cls_list = ["dog", "woman", "man", "car", "truck", "a black truck", "bird", "a white truck", "black cat"] # 分别处理文本和图像 text_input = processor.tokenizer(cls_list, return_tensors="pt", padding=True) # 将文本标签转换为模型可接受的输入格式(如 token IDs、attention mask) image_input = processor.image_processor(image, return_tensors="pt") # 将图片转换为像素张量(归一化、调整尺寸等) input = {**text_input, **image_input} # 合并文本和图像输入 outputs = model(**input) print(outputs.keys()) # 结果:odict_keys(['logits_per_image', 'logits_per_text', 'text_embeds', 'image_embeds', 'text_model_output', 'vision_model_output']) # logits_per_image:每个图像于 cls_list 中所有文本标签的相似度;[1×9] # logits_per text:logits per image 的矩阵转置 logits_per text = logits_per image.t() # text_embeds:每个文本标签对应的特征矩阵 # image_embeds:每个图像对应的特征矩阵 # text_model_output:文本模型(未经过)特征映射的输出 # vision_model_output:图像模型(未经过)特征映射的输出 # 计算概率分布。将相似度分数 logits_per_image 通过 softmax 转换为概率分布(总和为 1) logits_per_image = outputs.logits_per_image probs = logits_per_image.softmax(dim=1) for i in range(len(cls_list)): print(f"{cls_list[i]}: {probs[0][i]}") # 结果: # dog: 0.00019476815941743553 # woman: 0.0003470058727543801 # man: 0.0035062667448073626 # car: 0.0053071193397045135 # truck: 0.8265160322189331 # a black truck: 0.08789926767349243 # bird: 0.000317923171678558 # a white truck: 0.07588759064674377 # black cat: 2.407079045951832e-05 -
结果:可以看到 truck 的置信度较高,说明成功识别出了这张图片是什么;
-
-
图片与中文匹配的 CLIP 模型:
-
介绍:
- 该模型为 CLIP 模型的中文版本,使用大规模中文数据进行训练(~2 亿图文对)旨在帮助用户快速实现中文领域的图文特征&相似度计算、跨模态检索、零样本图片分类等任务;
- 该模型基于 open_clip project 建设,并针对中文领域数据以及在中文数据上实现更好的效果做了优化;
-
安装包:
pip install cn_clip-
可能会报错:在 Windows 系统上安装
cn_clip时,其依赖的lmdb==1.3.0需要从源码编译,而编译过程中缺少patch-ng模块; -
解决:安装预编译的 lmdb 替代版本
pip install lmdb --upgrade # 安装最新版 lmdb(如 1.4.1) pip install cn_clip --no-deps # 不安装依赖 pip install numpy tqdm six timm -
检查是否安装成功:
pip show cn_clip
-
-
代码:
import torch import cn_clip.clip as clip # 中文多模态CLIP模型的库 from PIL import Image # 处理图像输入 # load_from_name:加载预训练模型 # available_models:查看支持的模型列表 from cn_clip.clip import load_from_name, available_models # 检测是否有GPU可用,优先使用CUDA加速 device = "cuda" if torch.cuda.is_available() else "cpu" # 打印可用的模型 print("Available models:", available_models()) # Available models: ['ViT-B-16', 'ViT-L-14', 'ViT-L-14-336', 'ViT-H-14', 'RN50'] # B 代表 Big,L 代表 Large,H 代表 Huge; # B L H 后面紧跟的数字代表图像 patch 化时,每个 patch 的分辨率大小,14 代表图像是按照 14x14 的分辨率被划分成相互没有 overlap 的图像块; # -336 表示,输入图像被 resize 到 336x336 分辨率后进行的处理。默认是 224x224 的分辨率; # RN50 表示采用的是 ResNet50 架构(用的较少) # 下载并加载ViT-B-16模型和对应的图像预处理函数 model, preprocess = load_from_name( "ViT-B-16", device=device, download_root='./') # 切换到推理模式(关闭Dropout等训练层) model.eval() # 预处理图像 # Image.open:加载图片 # preprocess:标准化、调整大小(224x224)、转换为张量 # unsqueeze(0):增加批次维度(从[C,H,W]到[1,C,H,W]) # .to(device):将数据移至GPU/CPU image = preprocess(Image.open("data_examples/truck.png") ).unsqueeze(0).to(device) # 定义文本标签并分词 cls_list = ["狗", "汽车", "白色皮卡", "火车", "皮卡"] text = clip.tokenize(cls_list).to(device) # clip.tokenize:将中文文本转换为模型可接受的token IDs(如[5, 512]张量,512是最大长度) # 提取图文特征 with torch.no_grad(): # 禁用梯度计算,节省内存 image_features = model.encode_image(image) # encode_image:提取图像特征(形状[1, 512]) text_features = model.encode_text(text) # 提取文本特征(形状[5, 512],5个标签) # 特征归一化。将特征向量归一化为单位长度,方便计算余弦相似度 image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True) # 计算相似度 logits_per_image, logits_per_text = model.get_similarity(image, text) probs = logits_per_image.softmax(dim=-1).cpu().numpy() for i in range(len(cls_list)): print(f"{cls_list[i]}: {probs[0][i]}") # 结果: # 100%|███████████████████████████████████████| 718M/718M [00:22<00:00, 33.8MiB/s] # Loading vision model config from C:\python3.12.7\Lib\site-packages\cn_clip\clip\model_configs\ViT-B-16.json # Loading text model config from C:\python3.12.7\Lib\site-packages\cn_clip\clip\model_configs\RoBERTa-wwm-ext-base-chinese.json # Model info {'embed_dim': 512, 'image_resolution': 224, 'vision_layers': 12, 'vision_width': 768, 'vision_patch_size': 16, 'vocab_size': 21128, 'text_attention_probs_dropout_prob': 0.1, 'text_hidden_act': 'gelu', 'text_hidden_dropout_prob': 0.1, 'text_hidden_size': 768, 'text_initializer_range': 0.02, 'text_intermediate_size': 3072, 'text_max_position_embeddings': 512, 'text_num_attention_heads': 12, 'text_num_hidden_layers': 12, 'text_type_vocab_size': 2} # 狗: 0.00012731552124023438 # 汽车: 0.14404296875 # 白色皮卡: 0.09014892578125 # 火车: 0.034210205078125 # 皮卡: 0.7314453125 -
结果:可以看到 皮卡 的置信度较高,说明成功识别出了这张图片是什么。
-
2.3.2 从 CLIP 到 SigLIP 的技术演进
-
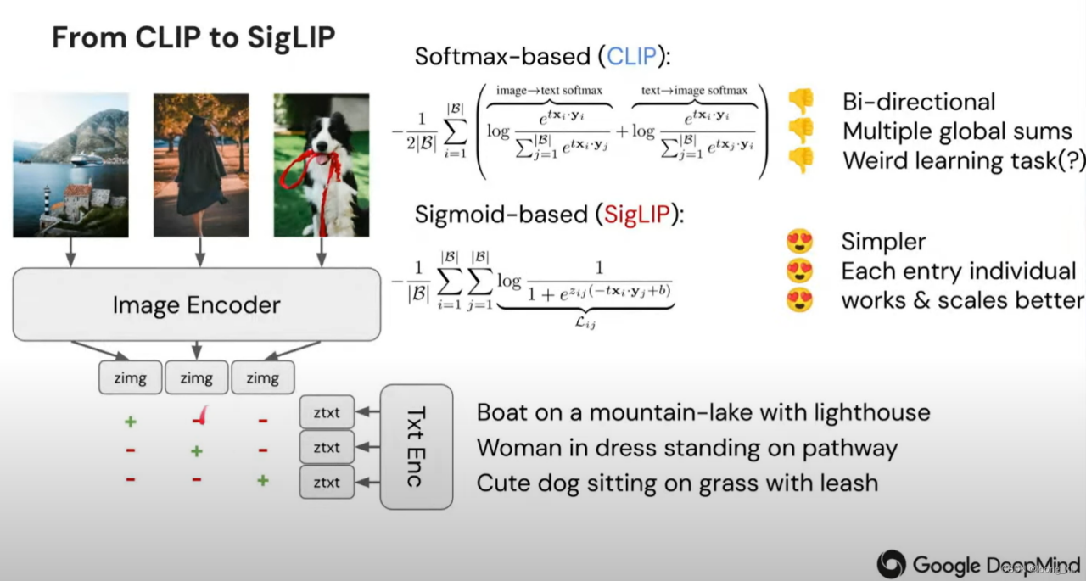
下图展示了从 CLIP 到 SigLIP 的技术演进,由 Google DeepMind 制作 。核心内容如下:
-
图像与文本编码
- 左侧显示三张图像,分别是山水灯塔景观、穿裙子的女士、叼着绳子的狗;
- 图像经 “Image Encoder”(图像编码器)处理得到图像特征表示 “zimg” ;
- 文本描述经 “Txt Enc”(文本编码器)处理得到文本特征表示 “ztxt”;
-
对比 CLIP 和 SigLIP 的损失函数
- 基于 Softmax 的 CLIP:
- 损失函数涉及双向的 softmax 操作,包括 “image→text softmax” 和 “text→image softmax”;
- 公式计算复杂,右侧批注指出存在双向计算、多次全局求和,学习任务较为复杂(标记为 “Weird learning task (?)” );
- 基于 Sigmoid 的 SigLIP:
- 损失函数基于 Sigmoid 函数,公式相对简单;
- 右侧批注表明其更简单,每个元素独立起作用,扩展性更好;
- 基于 Softmax 的 CLIP:
-
整体来看,SigLIP 相较于 CLIP,通过改进损失函数设计,优化多模态特征匹配学习过程,提升模型性能和可扩展性;
-
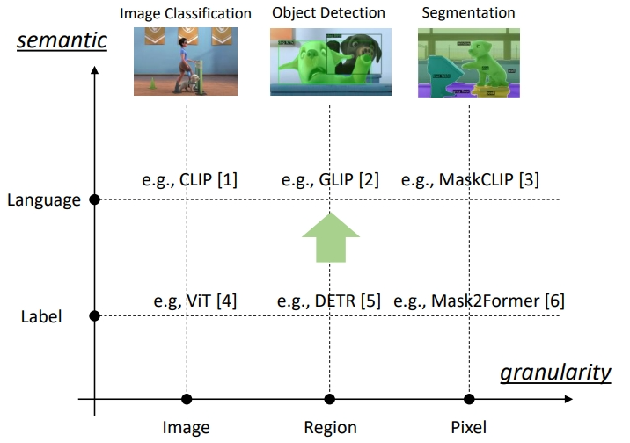
2.3.3 开域下的图像分类、目标检测和图像分割
- “开域” 指的是模型能够处理的任务或数据范围不受限于预先定义的特定类别或封闭集合,具备泛化到新的、未见过场景的能力;
-
横轴(granularity):表示粒度,从左到右分别是 Image(图像级别)、Region(区域级别)、Pixel(像素级别) ,体现对图像处理的精细程度逐渐增加;
-
纵轴(semantic):表示语义层面,从下到上分别是 Label(标签层)和 Language(语言层) ,意味着语义理解从简单标签上升到语言描述层面;
-
三个主要任务
- Image Classification(图像分类) :例如 CLIP 模型,利用自然语言监督学习可迁移视觉模型,在语言层和图像级别实现图文关联;
- Object Detection(目标检测) :如 GLIP 模型,能在区域级别定位和识别目标,实现语言到图像区域的映射;
- Segmentation(图像分割) :像 MaskCLIP 模型,在像素级别对图像进行分割,结合语言描述实现更精细的语义分割;
-
模型举例:
-
ViT(Vision Transformer) :用于图像分类,处于标签层和图像级别;
-
DETR(Detection Transformer) :用于目标检测,处于标签层和区域级别;
-
Mask2Former :用于图像分割,处于标签层和像素级别;
-
-
这些模型展示了多模态模型在不同粒度和语义层次上,从简单图像分类到复杂图像分割任务的发展和应用,通过图文 Token 对齐在开域场景下发挥作用。
2.3.4 文生图任务的复兴
-
下图展示了文生图(Text - to - Image)任务相关模型的发展时间线,体现了大规模图 - 文 Token 对齐模型推动下文生图任务的复兴历程 ;

- 早期模型
- StackGAN(2016 年 12 月):较早用于图像生成的生成对抗网络(GAN)模型,通过堆叠生成器逐步提升图像质量;
- AttnGAN(2017 年 11 月):引入注意力机制的 GAN,能更好地根据文本描述生成图像,增强文本与图像区域的对应;
- StyleGAN(2018 年 12 月):NVIDIA 提出,专注于生成高质量人脸图像等,通过控制样式空间实现对生成图像风格的精细调节;
- CLIP 模型及之后
- CLIP(2021 年):由 OpenAI 提出,是图 - 文多模态领域重要里程碑,实现图文特征对齐,为后文生图模型发展奠定基础;
- DALL - E(2021 年 2 月):OpenAI 开发,能根据文本描述生成图像,展现出强大的文本到图像映射能力;
- CogView(2021 年 5 月):清华大学提出,基于 Transformer 架构,可生成具有复杂场景的图像;
- NUWA(2021 年 11 月):微软研发,具备处理多种模态数据能力,可实现文本生成图像等任务;
- VQ - Diff.(2021 年 11 月)、Latent - Diff.(2021 年 12 月):基于扩散模型(Diffusion Model),在潜在空间进行图像生成,提升生成效率和质量;
- GLIDE(2021 年 12 月):OpenAI 模型,利用扩散模型,可生成高分辨率图像,在文本生成图像任务上表现出色;
- MaskGIT(2022 年 2 月):谷歌研究的模型,结合 Transformer 和生成式图像转换技术,实现文本到图像的生成;
- Make - A - Scene(2022 年 3 月):Meta AI 的成果,专注于场景生成,能根据文本生成复杂场景图像;
- DALL - E 2(2022 年 4 月):OpenAI 升级版,相比 DALL - E 生成图像质量和准确性大幅提升;
- CogView2(2022 年 4 月):清华大学进一步改进版,图像生成能力增强;
- Imagen(2022 年 7 月):谷歌研究的扩散模型,生成图像具有高保真度和丰富细节;
- Parti(2022 年 8 月):谷歌研究,基于 Transformer 架构,在文本生成图像任务中表现优异;
- NUWA - Infinity(2022 年 11 月):微软研发,可实现无限分辨率图像生成;
- SD(StableDiffusion,2022 年 11 月):基于扩散模型,开源且广泛应用,能根据文本生成多样化高质量图像;
- eDiff - I(2023 年 1 月):NVIDIA 的模型,在图像生成质量和效率上有提升;
- MUSE(2023 年 3 月):谷歌研究,可实现多模态理解和生成;
- GigaGAN(2023 年 3 月):Adobe Research 的成果,用于生成高分辨率图像;
- Bing image creator(2023 年 3 月):微软推出的图像生成工具;
- Midjourney(2023 年 5 月):广受欢迎的文生图工具,能生成高质量创意图像;
- IF(2023 年 5 月) :致力于实现高质量图像生成,在文生图领域有独特表现。
- 早期模型
2.4 多模态大语言模型出现
2.4.1 GPT4v 简介
-
GTP4v:OpenAI 的 GPT - 4 with Vision;
-
特性:
- 输入:支持接收文本、图像信息输入,且能处理图 - 文交替的输入形式,还支持含多张图像的序列输入,但不支持视频输入;
- 输出:以自然语言文本形式输出结果;
-
示例展示
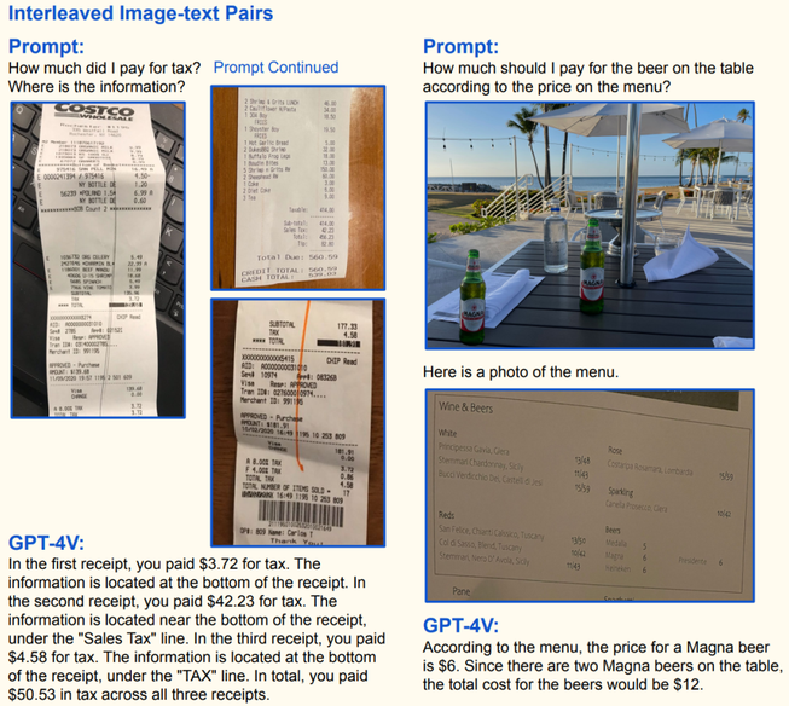
- 左侧示例:
- 用户提问 “我交了多少税?信息在哪里?” 并提供三张收据图片;
- GPT - 4V 识别出:
- 第一张收据交税 3.72 美元,信息在收据底部;
- 第二张交税 4.23 美元,在 “Sales Tax” 栏附近;
- 第三张交税 4.58 美元,在 “TAX” 栏,总计交税 50.53 美元;
- 右侧示例:
- 用户询问 “根据菜单价格,桌上啤酒该付多少钱?” 并给出啤酒桌和菜单图片;
- GPT - 4V 根据菜单判断 Magna 啤酒单价 6 美元,桌上有两瓶,总价 12 美元。
- 左侧示例:
2.4.2 GPT4v特性1——遵循文字提示
-
GPT4v 能够按照文本指令,对图像内容进行理解、信息提取并以规定形式输出结果;
-
示例一:GPT4v 能依据不同字数要求准确描述图像内容
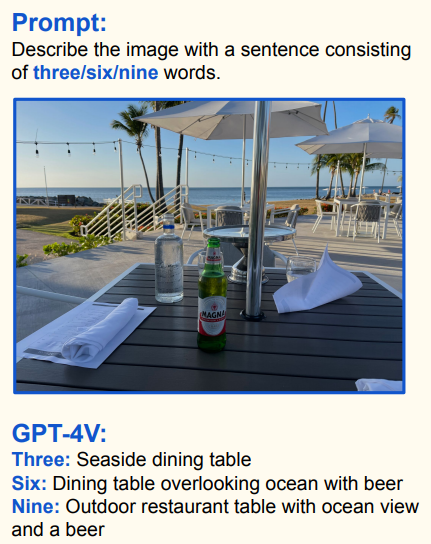
- Prompt(提示):要求用三词、六词、九词描述一张户外餐桌配啤酒的图像;
- GPT4v 回复:
- 三词:Seaside dining table(海边餐桌);
- 六词:Dining table overlooking ocean with beer(俯瞰大海的餐桌配啤酒);
- 九词:Outdoor restaurant table with ocean view and a beer(带海景的户外餐厅餐桌和一瓶啤酒);
-
示例二:
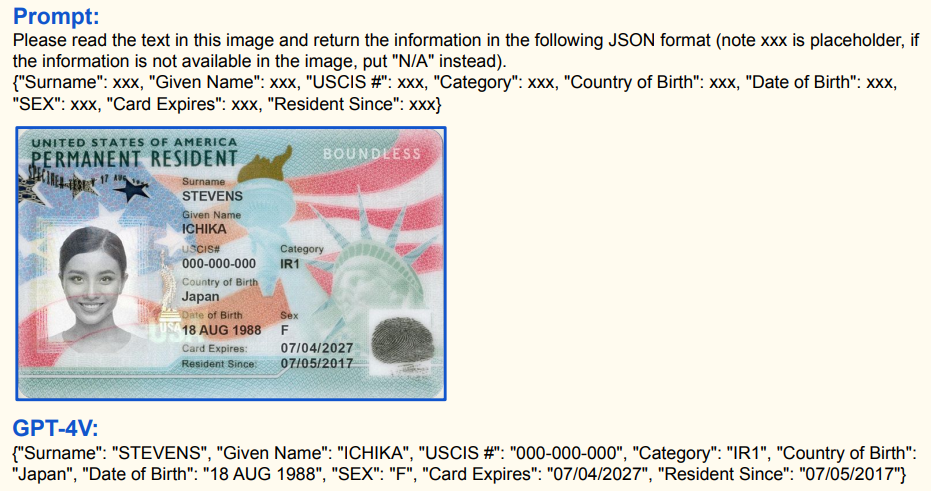
- Prompt(提示):要求读取美国永久居民卡图像中的文字信息,并以 JSON 格式输出(无对应信息处填 “N/A” );
- GPT4v 回复:按格式准确提取并输出姓氏(Surname)、名字(Given Name) 、USCIS 编号(USCIS # )、类别(Category)、出生国家(Country of Birth)、出生日期(Date of Birth)、性别(SEX)、卡片过期日期(Card Expires)、自…… 起为居民(Resident Since)等信息。
2.4.3 GPT4v特性2——理解视觉指向和参考
-
GPT4v 能够依据视觉指向,准确理解并描述图像局部区域内容,以及解决图像中相关数学问题的能力;
-
示例一:

- 任务:描述图像中黄色线条圈定区域;
- 图像内容:户外海边餐饮场景;
- GPT4v回复:指出圈定区域是电线上一排悬挂的小圆形灯,灯间距均匀,横跨在有桌椅遮阳伞的露台上方,起装饰和夜间照明作用;
-
示例二:
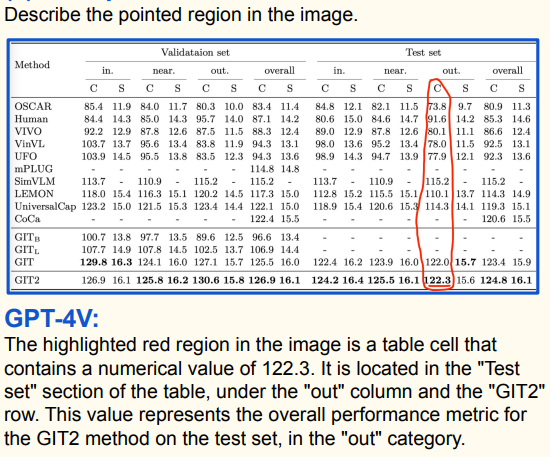
- 任务:描述图像中红色圆圈圈定区域;
- 图像内容:一张包含不同方法在验证集和测试集上性能数据的表格;
- GPT4v回复:说明该区域单元格数值为122.3 ,位于表格“Test set”部分“out”列和“GIT2”行,代表GIT2方法在测试集“out”类别下的整体性能指标;
-
示例三:
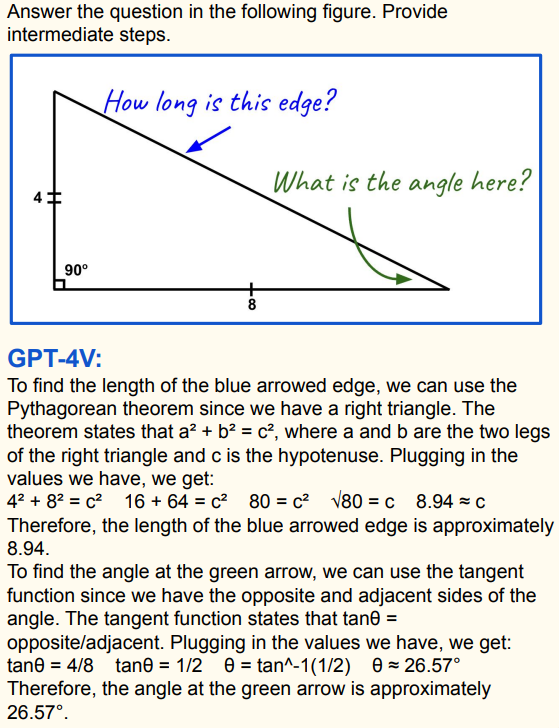
- 任务:回答图中直角三角形蓝色箭头边长度和绿色箭头处角度问题,并给出中间步骤;
- 图像内容:直角三角形,两条直角边分别为4和8;
- GPT4v回复: - 求蓝色箭头边长度:运用勾股定理 a 2 + b 2 = c 2 a^{2}+b^{2}=c^{2} a2+b2=c2( a = 4 a = 4 a=4、 b = 8 b = 8 b=8 ),计算得出 c = 4 2 + 8 2 = 80 ≈ 8.94 c=\sqrt{4^{2} + 8^{2}}=\sqrt{80}\approx8.94 c=42+82=80≈8.94 。 - 求绿色箭头处角度:利用正切函数 tan θ = 对边 邻边 \tan\theta=\frac{对边}{邻边} tanθ=邻边对边 ,即 tan θ = 4 / 8 = 1 / 2 \tan\theta = 4/8 = 1/2 tanθ=4/8=1/2 ,通过反正切函数得出 θ = arctan ( 1 / 2 ) ≈ 26.5 7 ∘ \theta=\arctan(1/2)\approx26.57^{\circ} θ=arctan(1/2)≈26.57∘。
2.4.4 GPT4v特性3——支持视觉+文本联合提示
-
GPT4v 具有在视觉 - 文本联合任务中的推理能力;
-
示例:结合视觉图形和文本提示,分析图形规律并给出合理答案
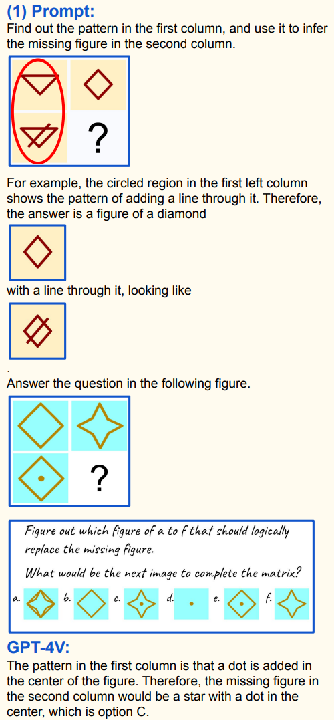
- 上方示例
- Prompt(提示):找出第一列图形规律,推断第二列缺失图形;
- 图形规律:第一列圈出图形规律是在原菱形图形基础上添加一条线;
- 答案:第二列缺失图形应为带一条线的菱形;
- 下方示例
- Prompt(提示):从 a - f 选项中找出能逻辑替换缺失图形的选项;
- 图形规律:第一列图形规律是在图形中心添加一个点;
- GPT4v 回复:第二列缺失图形应为中心带点的星形,即选项 C。
- 上方示例
2.4.5 GPT4v特性4——少样本上下文学习
-
GPT4v 具有在少样本情境下快速学习和应用知识的能力;
-
示例:通过车速表读数

-
任务与设置
- Prompt(提示):询问车速表读数 ,属于上下文少样本(2 - shot)学习任务 。即通过少量示例引导模型完成新任务;
-
示例及 GPT4v 回复
- 第一个车速表示例:指针大致在 80 到 100 英里每小时中间,80 和 100 中间值是 90,因指针刚过 90 ,GPT4v 判断车速约 91 英里每小时;
- 第二个车速表示例:指针大致在 20 到 40 英里每小时中间,20 和 40 中间值是 30 ,指针接近但未到 30 ,GPT4v 判断车速约 29 英里每小时;
- 第三个车速表示例:指针在 0 到 20 英里每小时的长刻度处,0 到 20 中间长刻度是 10 ,指针接近但未到 10 ,GPT4v 判断车速约 9 英里每小时。
-
体现 GPT4v 能基于少量示例,学习车速表读数判断方式,在新的车速表图像中准确推断车速,展示其在少样本情境下快速学习和应用知识的能力。
-
2.4.6 GPT4v特性5——强大的视觉认知能力
-
识人:

-
识地:

-
识菜:

-
LOGO:

-
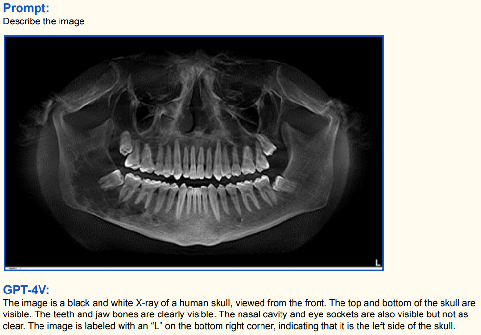
医疗图像描述:
-
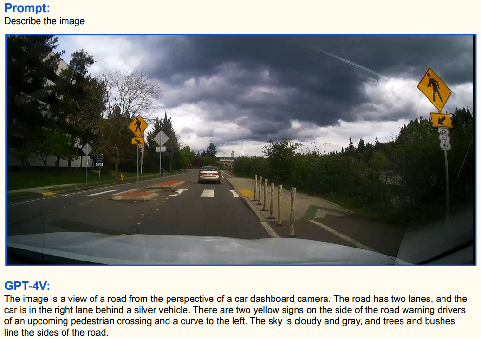
通用场景分析:
-
文本识别:

-
图标文档理解:
-
计数:

-
目标定位:

2.4.7 GPT4v特性6——时序视觉信号理解
-
GPT4v 能够理解和分析时序视觉信号,从一系列图像中准确提取事件发生的关键信息,展示其在处理动态视觉内容方面的能力;
-
示例:

- 任务与设置
- Prompt(提示):
- 询问球员在哪一帧踢球,守门员是否挡住球;
- 提供了六帧足球比赛图像(标记为 a - f );
- Prompt(提示):
- GPT4v 回复
- 球员踢球帧:指出球员在 c 帧踢球 。在该帧中可观察到球员做出踢球动作;
- 守门员是否挡球:判断球未被守门员挡住 。依据是 f 帧中球在球网内,守门员倒在地上,表明球成功进球。
- 任务与设置
2.4.8 Gemini 简介
-
Google:Gemini;
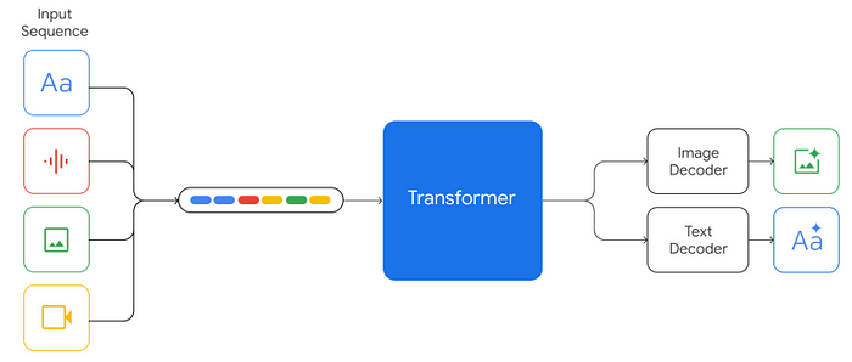
-
Gemini 模型特性
- 输入:可接收文本、语音、图像、视频信息输入 ,具备处理多种模态数据的能力;
- 输出:能输出自然语言文本、图像;
- 架构:通过 Transformer 架构处理输入的多种模态数据(文本、语音、图像、视频),再分别由 Image Decoder 输出图像,Text Decoder 输出自然语言文本;
-
“伪” 多模态 VS “原生” 多模态
- DeepMind CEO哈萨比斯:“到目前为止,大多数模型都是通过训练单独的模块,然后将它们拼接在一起来近似地实现多模式。对于某些任务来说,这没问题,但在多模态空间中,你无法进行这种深度复杂的推理。”
- 以 GPT - 4v 和 Gemini 为例 :
- “伪” 多模态模型特点:目前多数模型属于此类,通过分别训练文本、图像等单独模块,再拼接起来实现多模态功能。在一些简单任务上能正常运作。但模块拼接方式缺乏深度融合,在多模态空间中,面对需要综合理解多种模态信息并进行深度推理的复杂任务时,表现受限;
- “原生” 多模态模型优势:Gemini 为为原生多模态模型,从设计和架构上,能更自然地处理和融合多种模态信息,有望在多模态空间中进行深度复杂推理,克服 “伪” 多模态模型的局限。
2.4.9 Gemini特性1——支持多模态内容输出
-
Gemini 能够根据多模态任务指令,同时输出自然语言文本和图像,展示其在多模态内容生成方面的能力;
-
示例:
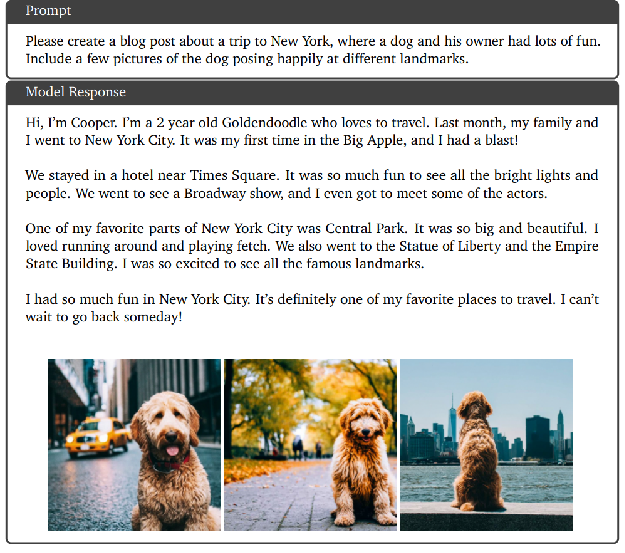
-
Prompt(提示):
- 要求创作一篇关于纽约旅行的博客文章,且内容设定为狗狗和主人在纽约玩得开心,同时要包含狗狗在不同地标开心摆姿势的几张图片;
- 这是一个融合文本创作和图像生成要求的多模态任务指令。
-
Model Response(模型回复):
- 文本部分:
- 以狗狗 Cooper(一只 2 岁的金毛寻回犬)的视角展开,讲述上个月和家人去纽约旅行的经历;
- 提到住在时代广场附近酒店,看百老汇演出、见到演员,游览中央公园、自由女神像、帝国大厦等标志性景点,表达在纽约玩得很开心,将其列为最喜欢的旅行地之一;
- 文本内容丰富,符合博客风格和主题要求;
- 图像部分:输出了三张狗狗在不同场景的图片,分别是在街道(背景有黄色出租车)、公园步道(背景有树木)、能看到城市天际线的水边 ,展现狗狗在纽约不同地标开心的状态,与文本内容和提示要求相契合。
- 文本部分:
2.4.10 Gemini特性2——复杂图像理解与代码生成
-
Gemini 能够理解图像中的复杂信息,并准确生成相应的代码,展示其在跨模态(图像理解到代码生成)任务上的强大能力;
-
示例:
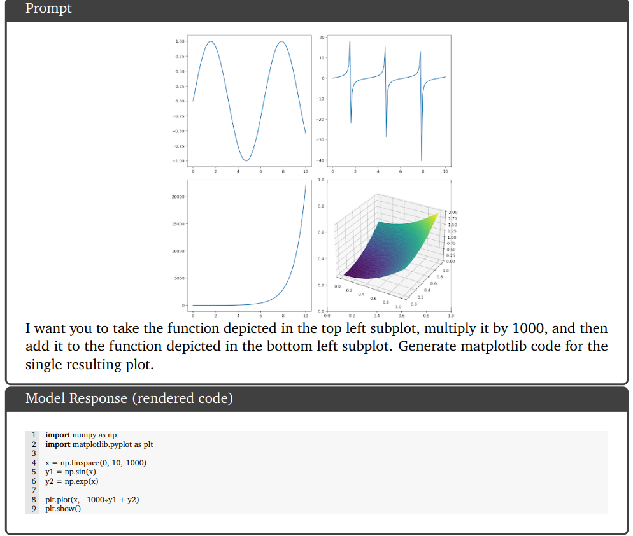
-
Prompt(提示):
- 要求对左上角子图中的函数乘以 1000 ,再与左下角子图中的函数相加,然后生成用于绘制最终结果图的 matplotlib 代码;
- 这需要模型理解图像中函数图形所代表的函数信息,并进行数学运算和代码生成;
-
Model Response(模型回复):
- 代码部分:生成的 Python 代码,导入了必要的库
numpy和matplotlib.pyplot,定义了自变量x,并对左上角子图函数(假设为正弦函数,代码中y1 = np.sin(x))乘以 1000 ,对左下角子图函数(假设为指数函数,代码中y2 = np.exp(x)),最后将二者相加并使用plt.plot()绘制图形,符合提示要求。
- 代码部分:生成的 Python 代码,导入了必要的库
2.4.11 Claude3 简介

- 输入:支持文本、图像信息输入 ,并且可以处理含多张图像的序列输入,但不支持视频输入;
- 这意味着 Claude3 能在图文结合的场景下工作,处理多图相关任务;
- 输出:以自然语言文本形式输出结果 ,可用于回答问题、生成文本描述等。
2.4.12 GPT4-o(Omini) 简介
- 输入:可以接收文本、语音、图像、视频信息输入;
- 输出:自然语言、语音、图像、视频(未开放)。
2.4.13 总结
- 将各种模态的输入与输出整合到一起,是未来发展的必然方向。
3 多模态大语言模型的应用
3.1 工业
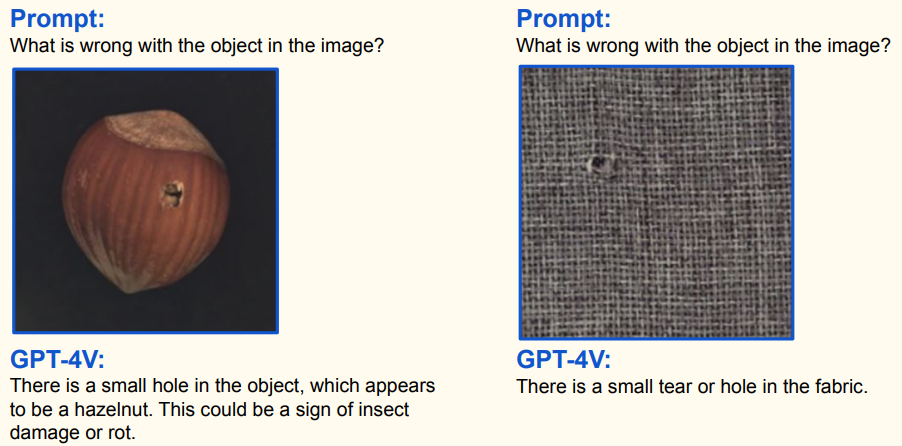
- 对于榛子图像,GPT - 4V 指出物体(榛子)上有个小洞,可能是虫害或腐烂迹象;
- 织物图像,GPT - 4V 说明织物上有小撕裂或孔洞;

- 白色汽车图像,GPT - 4V 评估该车副驾驶一侧前保险杠受损,损伤可能是刮擦或碰撞,主要为外观损伤,需进一步检查确定是否有结构损伤及潜在问题;
- 蓝色汽车图像,GPT - 4V 判断车辆前端严重受损,引擎盖变形、前保险杠部分损坏,可能是正面碰撞,外观损伤为主,可能有框架或引擎结构损伤,维修需更换引擎盖、保险杠等,费用可能数千美元。 这体现了 GPT - 4V 在图像内容理解和损伤评估等方面的应用能力。
3.2 医疗
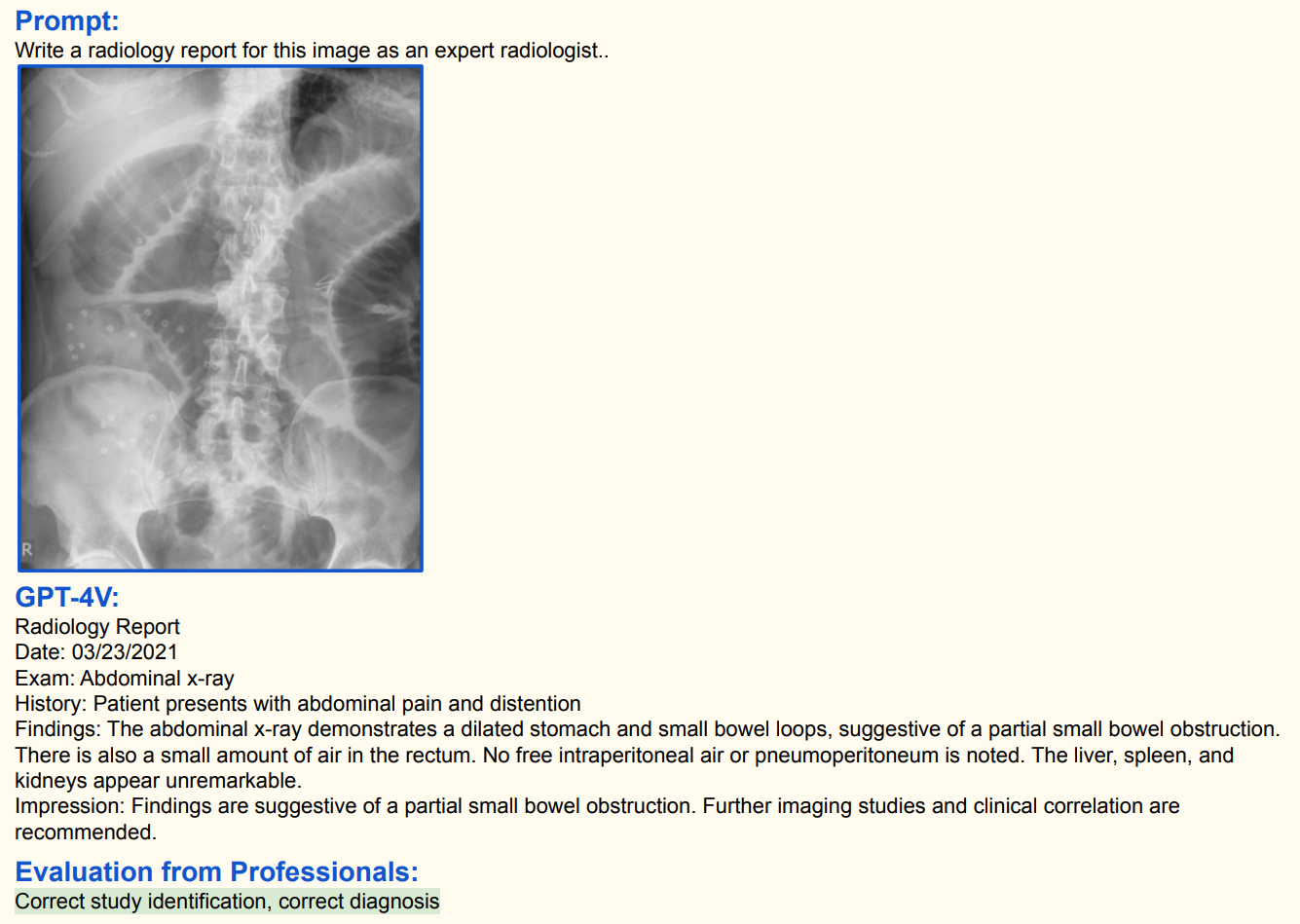
- Prompt(指令):要求以放射科专家身份撰写该图像的放射学报告;
- GPT - 4V 生成的放射学报告:
- 日期:2021 年 3 月 23 日。
- 检查项目:腹部 X 光。
- 病史:患者存在腹痛和腹胀症状。
- 检查结果:腹部 X 光显示胃和小肠袢扩张,提示可能存在部分小肠梗阻;直肠内有少量气体;未发现腹腔内游离气体(排除胃肠穿孔等严重情况);肝脏、脾脏和肾脏未见明显异常。
- 诊断印象:检查结果提示部分小肠梗阻,建议进一步影像学检查并结合临床症状综合判断 。
- 专业人员评估:识别正确,诊断正确。这体现了 GPT - 4V 在医疗影像解读方面具备一定能力,能生成规范且准确的放射学报告,但实际医疗应用中仍需专业医生进一步评估确认。
3.3 视觉内容认知与编辑
-
初始指令与操作:用户提供了原始图像(一尊雕塑图像),使用的编辑指令是 “have it look like a graphic novel”(让它看起来像一本漫画小说) ,得到了初步编辑后的图像。但用户对效果不满意,询问如何改进指令;
-
GPT - 4V 的建议:GPT - 4V 建议指令应更具体,例如使用 “make the image look like a black and white comic book illustration”(让图像看起来像黑白漫画插图 )或 “add bold lines and high contrast to the image to make it look like a graphic novel cover”(给图像添加粗线条和高对比度,使其看起来像漫画小说封面 ),这样能让 AI 更好理解预期效果,生成更理想图像;
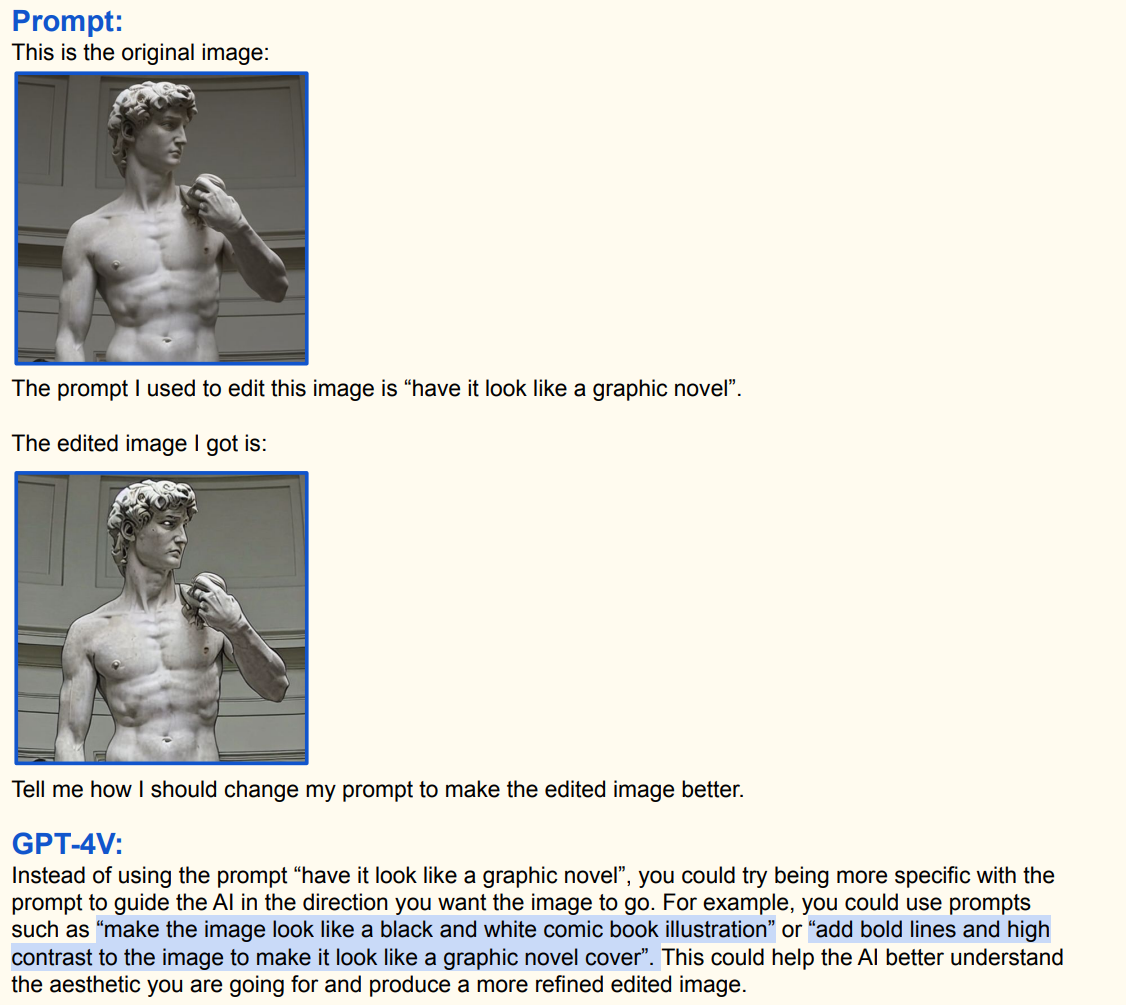
-
Instruct Pix2Pix 示例:展示了使用 Instruct Pix2Pix 工具,分别输入 “make the image look like a black and white comic book illustration”(让图像看起来像黑白漫画插图 )和 “add bold lines and high contrast to the image to make it look like a graphic novel cover”(给图像添加粗线条和高对比度,使其看起来像漫画小说封面 )指令后生成的不同效果图像,体现了更明确指令对图像编辑效果的改善作用。 这展示了多模态大语言模型在视觉内容编辑中,根据文本指令操控图像的能力,以及指令优化对结果的影响;

3.4 具身智能
-
多模态大语言模型 GPT - 4V 在具身智能领域,对家庭机器人任务规划的应用:
-
任务设定:假设机器人要去厨房冰箱取东西,根据当前位置图像规划行动。
-
行动规划过程
-
机器人初始在客厅,GPT - 4V 判断厨房 likely 在右侧方向,规划行动为右转并朝走廊前进;

-
机器人到达走廊,从当前视角看到厨房在右侧,下一步行动规划为右转并朝厨房前进;
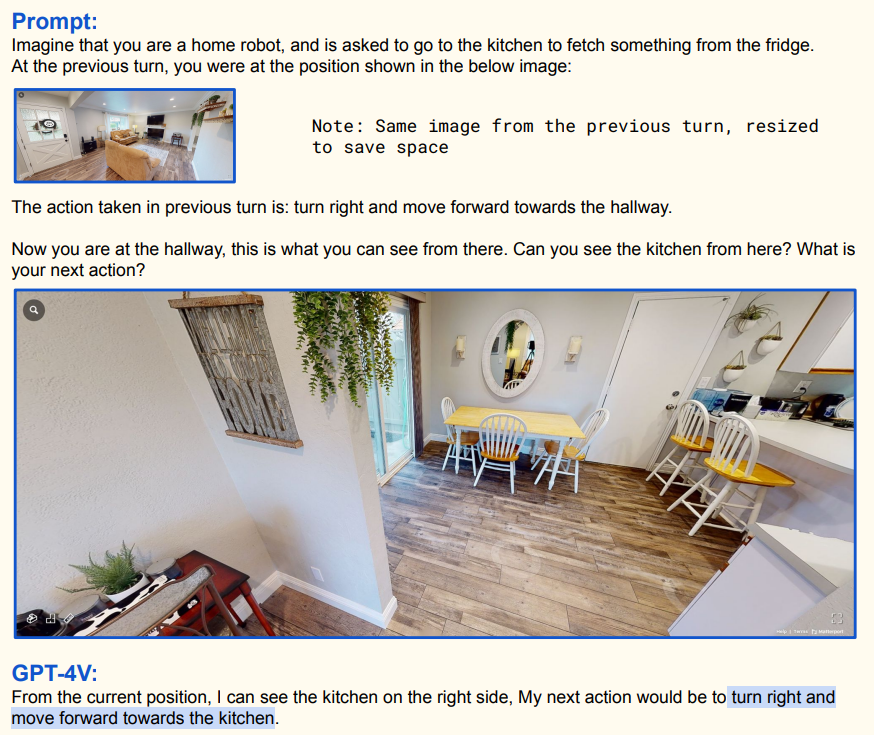
-
机器人接近厨房看到冰箱,规划先向前并稍向左移动对准冰箱门,然后用机械臂打开冰箱门取物品。这体现了 GPT - 4V 结合视觉信息(图像)与文本指令,为机器人规划行动步骤的能力,属于具身智能范畴,即让智能体在实际环境中通过多模态感知(视觉等)与行动交互来完成任务;

-
-
-
多模态大语言模型在具身智能等多方面的应用,以 PaLM - E 为例:
- 模型介绍:PaLM - E 是具身多模态语言模型,融合视觉信息(VIT )与大语言模型(PaLM ),能处理多模态数据进行任务规划等;
具身智能
-
应用场景:
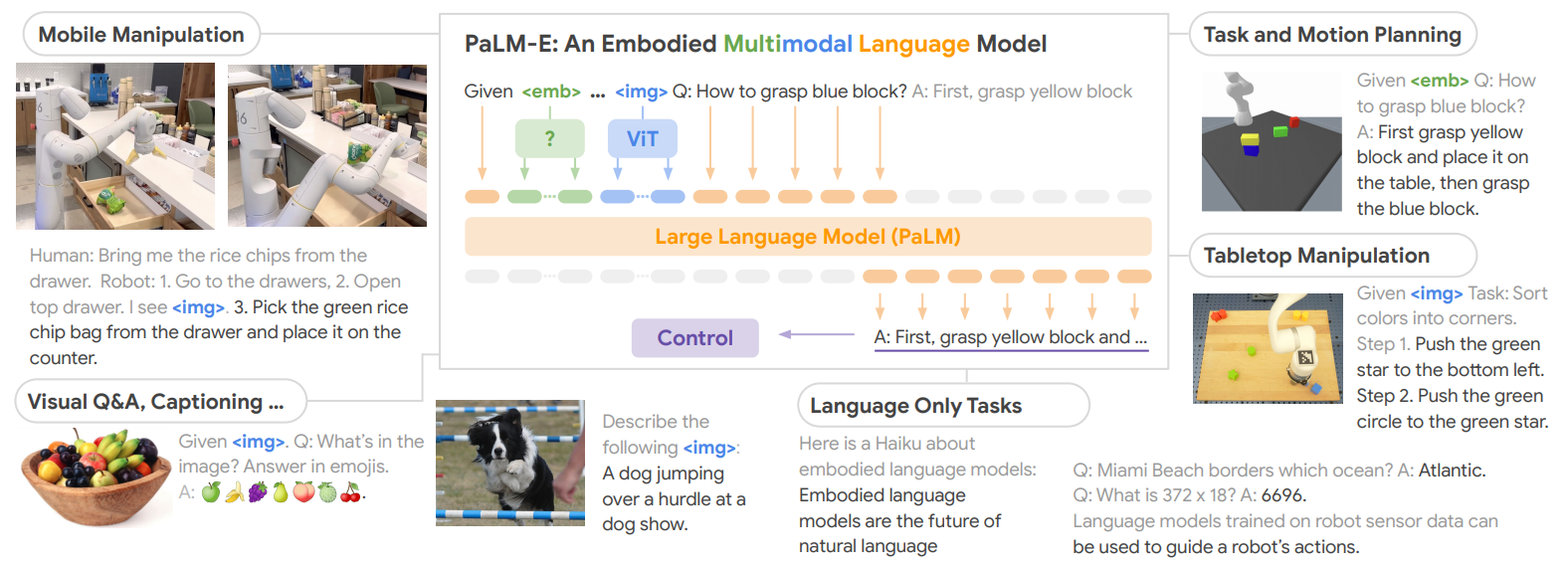
- 移动操作(Mobile Manipulation):如人类指令 “从抽屉拿薯片”,机器人结合视觉信息( )规划去抽屉、打开抽屉、取薯片并放置到台面等步骤。
- 任务与运动规划(Task and Motion Planning):给定抓取蓝色方块任务,模型规划先抓黄色方块放蓝色方块上的步骤。
- 桌面操作(Tabletop Manipulation):对颜色分类任务,规划推动绿色星星到指定位置等步骤。
- 视觉问答(Visual Q&A):针对图像内容用表情符号回答问题,如问水果碗里有什么,用对应水果表情回答。
- 仅语言任务(Language Only Tasks):包括描述图像(如描述狗展上狗跳障碍 )、创作俳句、回答常识问题(如迈阿密海滩毗邻大西洋 )等。
-
意义:这类模型通过在机器传感器数据上训练,能用自然语言指导机器人行动,推动具身智能发展,也拓展了多模态大语言模型在不同场景的应用边界。 同时给出了相关研究论文引用及虚拟实验环境开源地址,便于进一步研究探索。
3.5 新一代人机交互
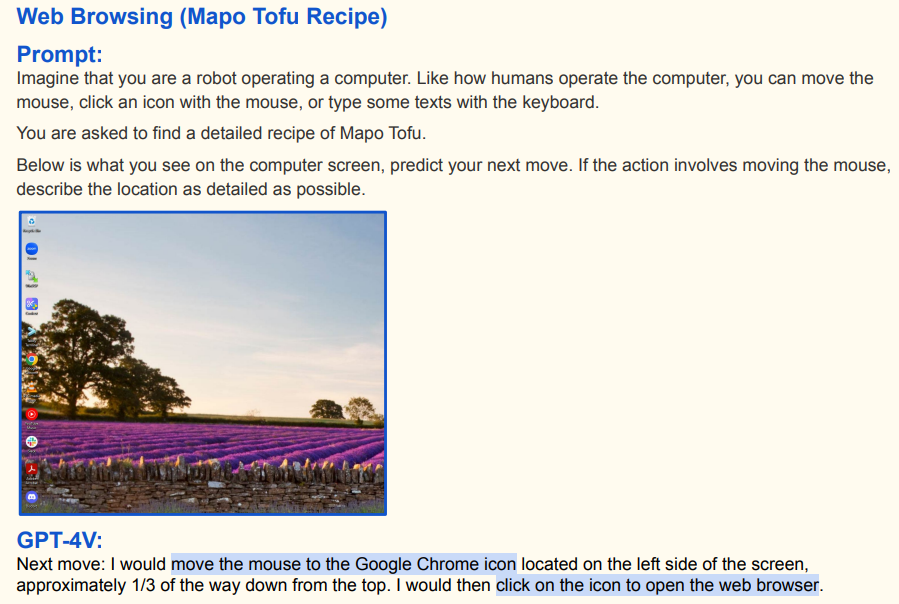
-
下面展示了多模态大语言模型在模拟机器人操作电脑获取麻婆豆腐食谱任务中的应用,具体过程如下:
-
打开浏览器:初始指令要求机器人像人类一样操作电脑找麻婆豆腐食谱。GPT - 4V 观察电脑桌面图像后,规划将鼠标移动到屏幕左侧约上三分之一处的谷歌浏览器图标 ,点击打开浏览器。这体现其结合视觉(桌面图标布局)与文本指令(找食谱)规划操作的能力;
-
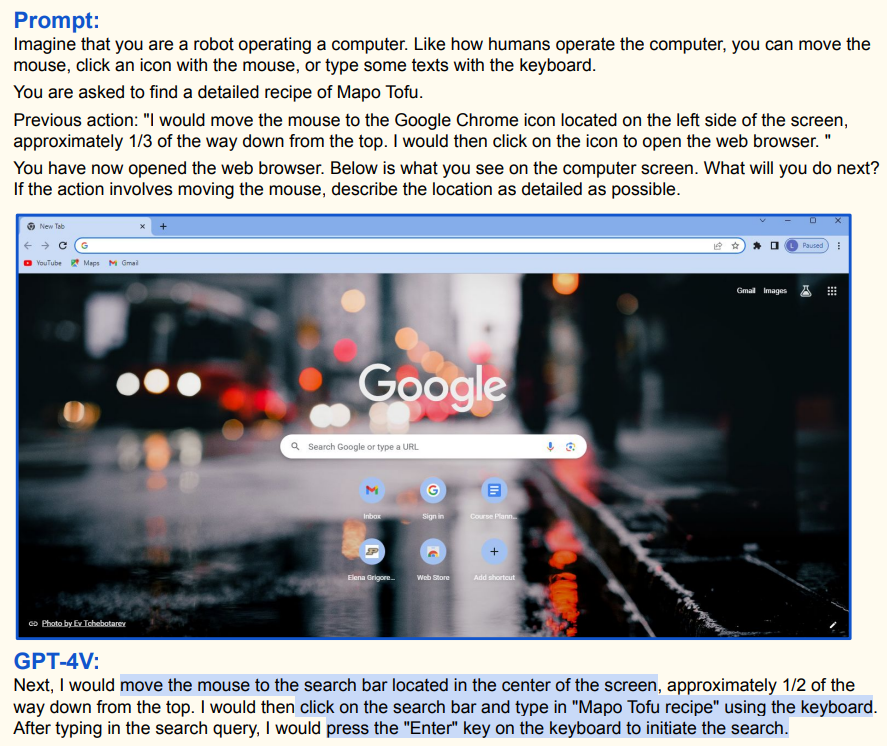
输入搜索词:浏览器打开后,GPT - 4V 看到谷歌搜索页面,规划把鼠标移到屏幕中间约上二分之一处的搜索栏 ,点击后用键盘输入 “Mapo Tofu recipe” 并按回车键搜索 ,基于当前界面视觉信息和找食谱任务指令规划下一步操作;
-
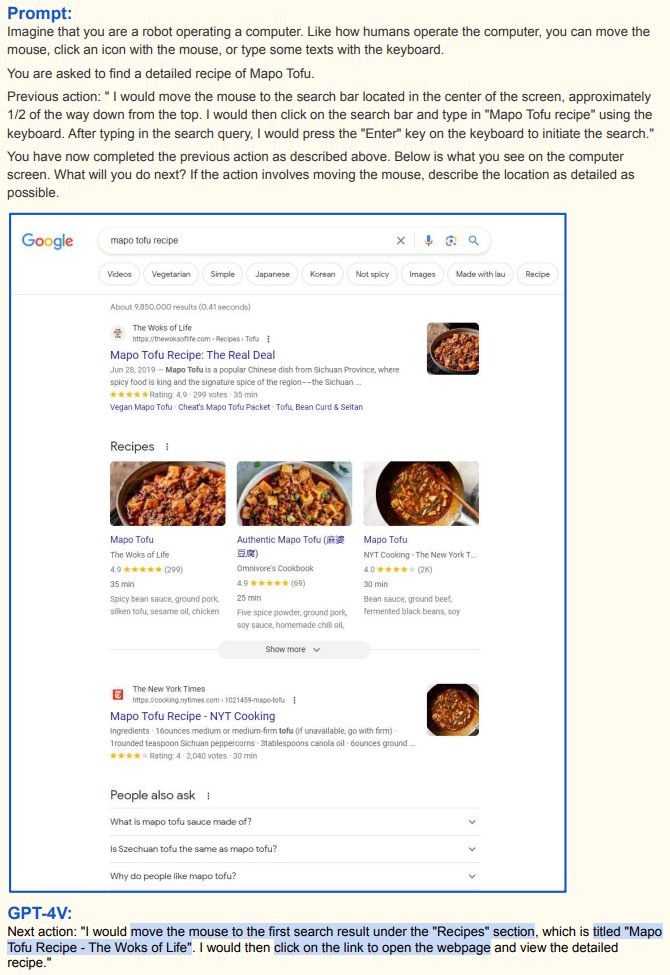
选择搜索结果:搜索结果页面出现后,GPT - 4V 观察到 “Recipes” 部分首个结果标题为 “Mapo Tofu Recipe - The Woks of Life” ,决定将鼠标移到该链接并点击,以打开网页查看详细食谱,依据视觉信息筛选合适结果;
-
跳转至食谱部分:进入网页看到麻婆豆腐介绍及图片后,GPT - 4V 注意到页面右上角 “Jump to Recipe” 按钮 ,规划将鼠标移到该按钮并点击,跳转到详细食谱部分,利用网页视觉元素(按钮位置)推进任务;
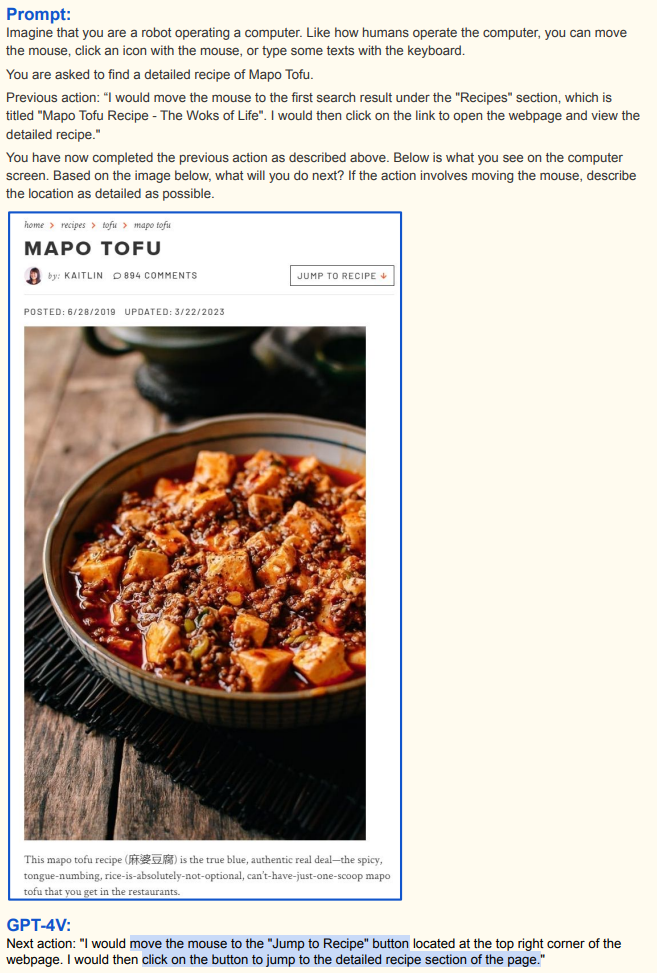
-
打印食谱:看到详细食谱内容(食材、做法等)后,GPT - 4V 发现食谱部分右上角 “Print Recipe” 按钮 ,规划将鼠标移到该按钮并点击,打印详细食谱,根据当前视觉信息和获取食谱任务完成最后操作;
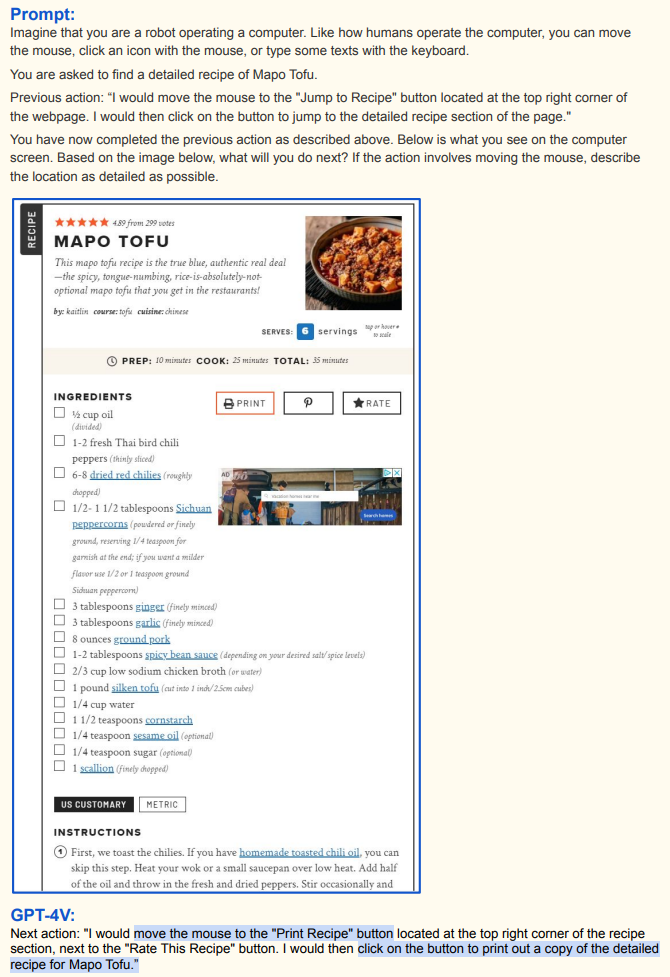
-
-
整个过程体现了多模态大语言模型结合视觉内容(电脑屏幕显示图像)与文本指令(找麻婆豆腐食谱),像人类一样规划电脑操作步骤完成任务的能力,是新一代人机交互和具身智能在虚拟操作场景的应用示例。
4 图文对话系统的搭建
4.1 开源社区多模态大语言模型一览
-
以下排名不一定实时,需根据实际情况排名;
-
视觉推理:
Rank Model Version Cognition任务得分 🏅️ Qwen-VL-Max - 643.57 🥈 InternVL-Chat-V1.5 InternLM2-20B 550.00 🥉 InternLM-XComposer2-VL InternLM2-7B 530.71 4 GPT-4V - 517.14 5 Qwen-VL-Plus - 502.14 6 WeMM InternLM-7B 445.00 7 Gemini Pro - 436.79 8 MMICL FlanT5xxl 428.93 9 MiniCPM-V-2 MiniCPM-2B 406.07 10 Monkey-Chat Qwen-7B 401.43 11 MiniCPM-Llama3-V 2.5 LLaMA3-8B 400.71 12 LLaVA-1.6 Vicuna-34B 397.14 13 InternLM-XComposer-VL InternLM-7B 391.07 14 ChatTruth-7B Qwen-7B 387.86 15 360VL LLaMA3-70B 371.43 16 InfMLLM Vicuna-13B 368.93 17 DataOptim-LLaVA Vicuna-13B 361.07 18 Qwen-VL-Chat Qwen-7B 360.71 19 PureMM Vicuna-13B 360.36 20 LLaMA-Adapter V2 LLaMA-Adapter-v2.1-7B 356.43 -
视觉感知:
Rank Model Version Perception任务得分 🏅️ Qwen-VL-Max - 1790.04 🥈 ChatTruth-7B Qwen-7B 1735.88 🥉 InternLM-XComposer2-VL InternLM2-7B 1712.00 4 PureMM Vicuna-13B 1686.52 5 Qwen-VL-Plus - 1681.25 6 InfMLLM Vicuna-13B 1673.75 7 InternVL-Chat-V1.1 LLaMA2-13B 1672.35 8 Honeybee Vicuna-13B 1661.13 9 360VL LLaMA3-70B 1640.86 10 InternVL-Chat-V1.5 InternLM2-20B 1637.84 11 OmniLMM Zephyr-7B-beta 1636.90 12 LLaVA-1.6 Vicuna-34B 1631.47 13 WeMM InternLM-7B 1621.66 14 MiniCPM-Llama3-V 2.5 LLaMA3-8B 1619.29 15 ShareGPT4V Vicuna-13B 1618.70 16 RBDash Vicuna-13B 1610.15 17 BELLE-VL Qwen-14B 1595.34 18 TransCore-M PCITransGPT-13B 1588.16 19 HyperLLaVA Vicuna-13B 1575.61 20 LVIS-INSTRUCT4V Vicuna-13B 1574.89 21 MindSource-VL-Chat MindSource-7B 1567.99 22 DataOptim-LLaVA Vicuna-13B 1563.56 23 SPHINX LLaMA2-13B 1560.15 24 LLaVA Vicuna-13B 1531.31 25 InternLM-XComposer-VL InternLM-7B 1528.44 26 Monkey-Chat Qwen-7B 1522.39 27 CogAgent Vicuna-7B 1497.79 28 Gemini Pro - 1496.57 29 Bunny-3B Phi-2 1488.80 30 Qwen-VL-Chat Qwen-7B 1487.57
4.2 图文多模态大语言模型的评测
4.2.1 MME数据集
-
MME(Multimodal Evaluation of large - language models,大语言模型多模态评测)评测集是用于评估多模态大语言模型性能的数据集,相关资源在 GitHub 上开源(链接:BradyFU/Awesome-Multimodal-Large-Language-Models at Evaluation);

-
各任务类型及示例解析:
- Perception (Coarse - Grained Tasks,粗粒度感知任务)
- Existence(存在性):判断图像中物体是否存在。如 “Is there an elephant in this image?”,需根据图像判断有无大象;
- Count(数量):确定图像中物体数量。像 “Is there a total of two person appear in the image?”,要数图像中人物数量;
- Position(位置):判断物体间位置关系。例如 “Is the motorcycle on the right side of the bus?”,依据图像判断摩托车和公交车位置关系;
- Color(颜色):判断图像中物体颜色相关情况。如 “Is there a red coat in the image?”,看图像里有无红色外套;
- Perception (Fine - Grained Tasks,细粒度感知任务)
- Poster(海报相关):判断电影海报相关信息。如 “Is this movie directed by francis ford coppola?”,根据海报判断导演信息;
- Celebrity(名人):判断图像中名人身份。像 “Is the actor inside the red box called Audrey Hepburn?”,依据图像判断红框内演员是否为奥黛丽・赫本;
- Scene(场景):判断图像描绘场景。例如 “Does this image describe a place of moat water?”,根据图像判断是否为护城河场景;
- Landmark(地标):判断图像中的地标建筑。如 “Is this an image of Beijing Guozijian?”,依据图像判断是否为北京国子监;
- Artwork(艺术品):判断艺术品相关信息。像 “Does this artwork belong to the type of still - life?”,根据图像判断艺术品是否为静物画类型;
- Perception (OCR Task,光学字符识别任务):识别图像中的文字信息。如 “Is the phone number in the picture ‘0131 555 6363’?”,需识别图片中的电话号码是否为给定号码;
- Cognition (Reasoning Tasks,认知推理任务)
- Commonsense Reasoning(常识推理):基于常识进行判断。如 “Should I stop when I’m about to cross the street?”,根据交通常识判断;
- Numerical Calculation(数值计算):计算图像中数学问题答案。例如 “Is the answer to the arithmetic question in the image 65?”,需计算图像中数学题答案并判断;
- Text Translation(文本翻译):判断翻译是否恰当。如 “Appropriate to translate 老味道 into English ‘classic taste’?”,判断 “老味道” 翻译成 “classic taste” 是否合适;
- Code Reasoning(代码推理):判断 Python 代码输出结果。如 “Python code. Is the output of the code ‘Hello’?” ,需分析代码得出输出是否为 “Hello”。
- Perception (Coarse - Grained Tasks,粗粒度感知任务)
4.2.2 其它数据集
-
MMMU、MMVet、MathVista 都是用于图文多模态大语言模型评测的数据集,下面给出一些示例;
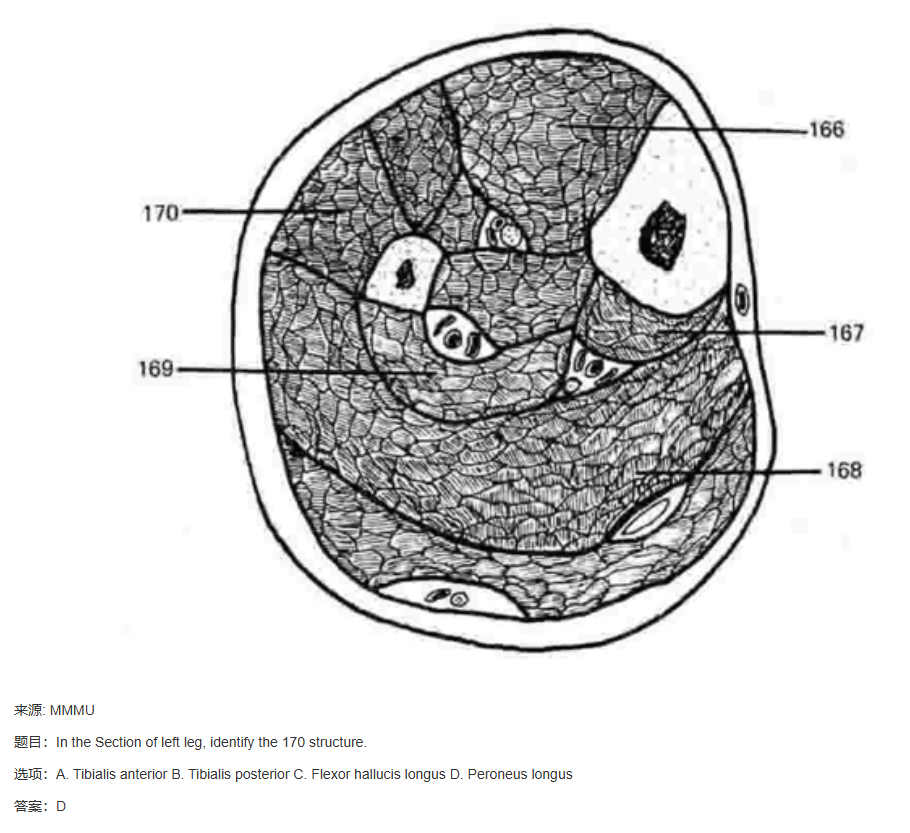
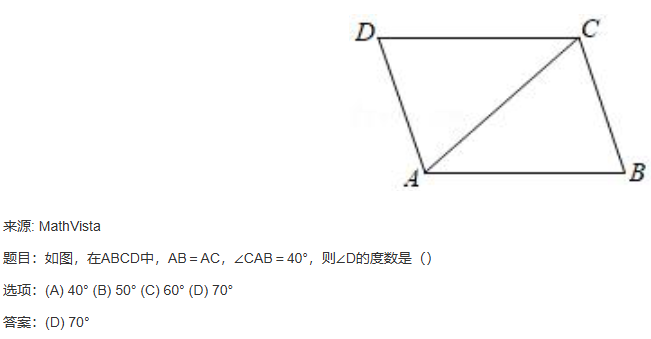

4.2.3 各类benchmark(基准测试)上的综合测试
- “benchmark” 常见释义为 “基准;基准测试”,是一种标准化测试,用于衡量系统、组件或算法性能。比如通过运行特定数学运算测 CPU 性能,依据插入、查询等操作速度评估数据库管理系统;
- 组成部分:
- 测试用例:具体任务或操作,代表真实典型工作负载,确保结果具实际意义;
- 性能指标:量化测试结果,如响应时间、吞吐量、每秒操作数、延迟、能效等;
- 数据集:数据库、机器学习测试常需特定数据集,模拟真实数据处理;
- 测试脚本和控制:自动化测试脚本控制流程,确保测试可重复;
- 评分系统:标准化评估测试结果,便于不同系统配置比较;
- 测试规范:详述测试执行、预期结果及结果解释方式;
- 应用场景:
- 硬件性能测试:3DMark 测图形卡性能,Cinebench 测 CPU 和图形性能;
- 软件和系统性能测试:PCMark 和 SPEC 评估计算机系统性能;MLPerf 评估机器学习和深度学习系统性能;TensorFlow Benchmark 测试 TensorFlow 库性能;
- 组成部分:
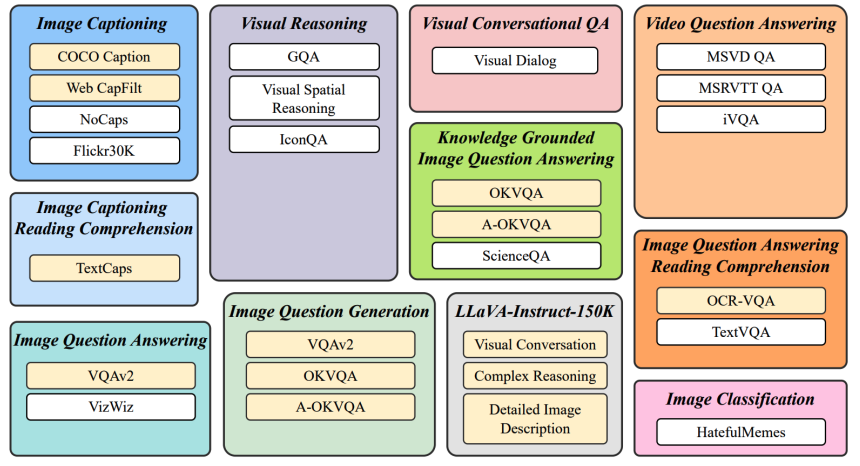
- Image Captioning(图像描述)
- 任务:要求模型根据图像生成描述性文本;
- 常用数据集:COCO Caption、Web CapFilt、NoCaps、Flickr30K 。例如 COCO Caption 数据集包含大量日常场景图像,用于训练和评估模型生成准确、丰富图像描述的能力;
- Visual Reasoning(视觉推理)
- 任务:模型需基于图像进行推理,如判断物体间关系、场景理解等;
- 常用数据集:GQA(用于一般视觉推理问题)、Visual Spatial Reasoning(侧重于空间关系推理) 、IconQA(可能涉及图标相关推理) ;
- Visual Conversational QA(视觉对话问答)
- 任务:围绕图像进行多轮对话式问答,模拟真实对话场景;
- 常用数据集:Visual Dialog ;
- Video Question Answering(视频问答)
- 任务:针对视频内容进行问答,涉及对视频中事件、动作、情节等理解;
- 常用数据集:MSVD QA、MSRVTT QA、iVQA ;
- Knowledge Grounded Image Question Answering(基于知识的图像问答)
- 任务:不仅要理解图像,还需结合外部知识进行问答;
- 常用数据集:OKVQA、A - OKVQA、ScienceQA ;
- Image Question Answering Reading Comprehension(图像问答阅读理解)
- 任务:将图像理解与阅读理解结合,回答基于图像和相关文本的问题;
- 常用数据集:OCR - VQA、TextVQA ;
- Image Question Generation(图像问题生成)
- 任务:根据图像生成相关问题;
- 常用数据集:VQAv2、OKVQA、A - OKVQA ;
- Image Question Answering(图像问答)
- 任务:回答基于图像的问题;
- 常用数据集:VQAv2、VizWiz;
- LLaVA-Instruct-150K
- 任务:涵盖视觉对话、复杂推理、详细图像描述等多种与图像相关的任务;
- Image Classification(图像分类)
- 任务:将图像分类到预定义类别中;
- 常用数据集:HatefulMemes(可能专注于包含仇恨性内容相关图像分类);
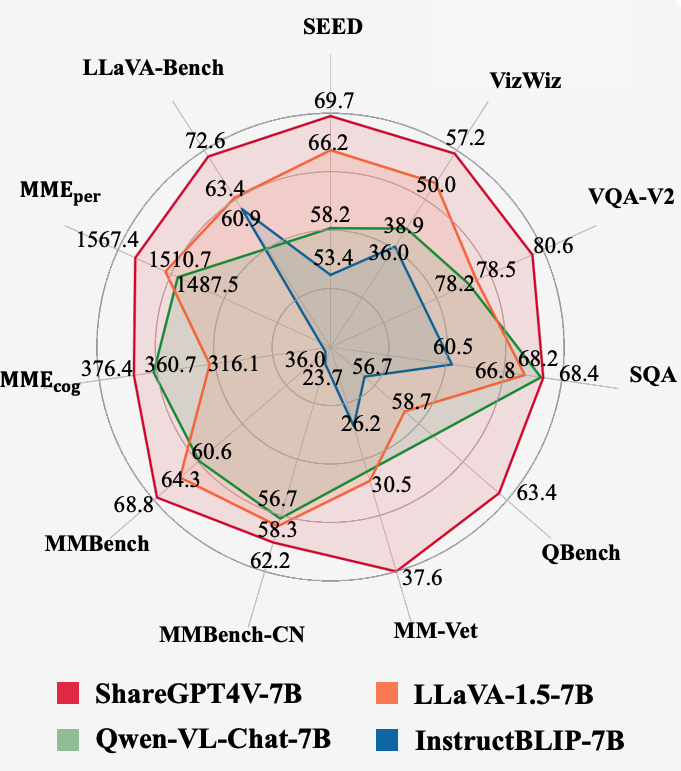
- 上面雷达图展示了不同模型(ShareGPT4V-7B、LLaVA-1.5-7B、Qwen-VL-Chat-7B、InstructBLIP-7B )在多个评测基准(如 LLaVA-Bench、VizWiz、VQA-V2 等 )上的表现得分。模型在不同基准上的得分反映其在对应任务类型上的能力,通过雷达图可直观对比各模型在不同评测任务上的优势与劣势。
4.3 从零开始搭建图文对话系统
- 以LLaVA为例,LLaVA(Large Language and Vision Assistant)是一个开源的多模态人工智能模型,旨在通过视觉指令调优,构建具有类似 GPT - 4V 级别能力的大型语言与视觉助手,由 Haotian Liu、Chunyuan Li 等研究人员共同开发;
- 多模态大语言模型的训练过程如下。
4.3.1 模型训练方案
-
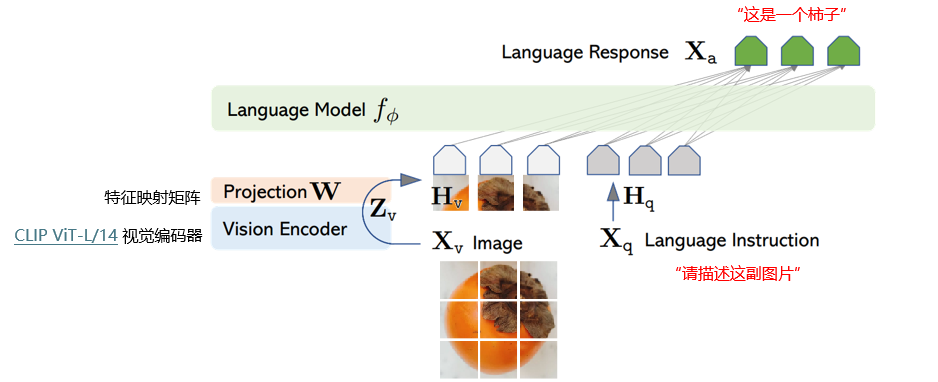
模型组件:
- 视觉编码器(Vision Encoder ):
- 采用 CLIP ViT-L/14 视觉编码器,负责将输入图像 X v X_v Xv(如柿子图片 )转化为视觉特征 Z v Z_v Zv;
- CLIP 模型能在大规模图文对上预训练,提取通用视觉特征;
- 特征映射矩阵(Projection W W W ):将视觉特征 Z v Z_v Zv 映射为 H v H_v Hv,使视觉特征与语言模型特征空间适配;
- 语言模型(Language Model f ϕ f_ϕ fϕ ):处理语言指令 X q X_q Xq(如 “请描述这副图片” ),得到语言特征表示 H q H_q Hq,结合视觉特征 H v H_v Hv 生成语言响应 X a X_a Xa(如 “这是一个柿子” );
- 视觉编码器(Vision Encoder ):
-
两阶段训练过程——阶段一:特征对齐的预训练。只更新特征映射矩阵;
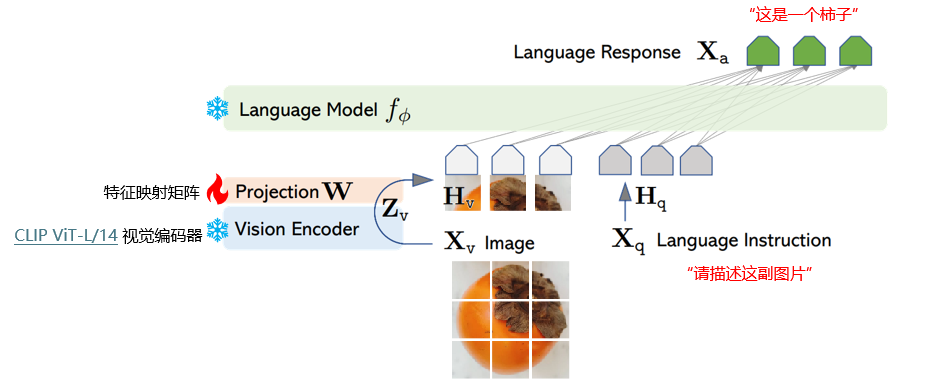
- 训练重点是特征映射矩阵 W W W ;
- 通过此阶段,让视觉特征与语言模型特征空间更好对齐,使视觉信息能有效融入语言模型,此时语言模型参数基本固定;
-
两阶段训练过程——阶段二:端到端微调。特征投影矩阵和LLM都进行更新;
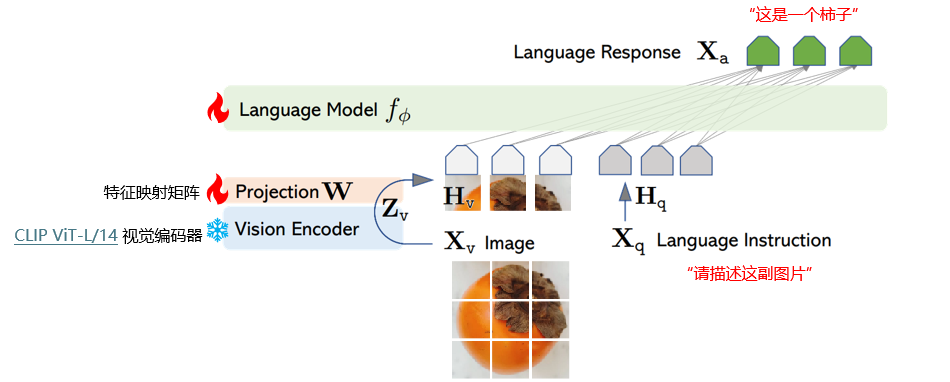
- 对特征映射矩阵 W W W 和语言模型 f ϕ f_ϕ fϕ 同时进行更新;
- 利用大量图文对数据和语言指令 - 响应数据,让模型在整体上学习如何根据视觉和语言输入准确生成合适语言输出,提升图文理解和对话能力。
4.3.2 数据准备
-
图 - 文对齐数据:
-
数据来源:LAION Dataset、Conceptual Captions Dataset 、SBU Captions Dataset 等,共 558K 条数据。这些数据集提供大量图像及对应文本描述,是模型学习图文关联基础;
-
标注方式:基于 BLIP 进行短文本描述打标。通过 BLIP 模型自动生成或辅助生成图像的文本描述,使图像和文本初步对齐,为模型后续学习视觉和语言信息对应关系提供数据;
-
-
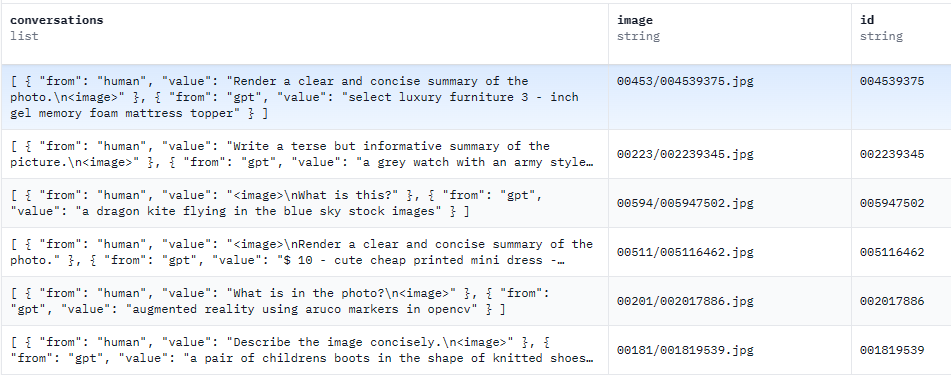
图 - 文指令数据:
-
数据来源:包括 coco、gqa、ocr_vqa 等多个子数据集,总计 665K 条数据 。这些子数据集涵盖不同类型图文任务数据,丰富模型训练场景;

-
数据生成:部分基于 GPT4 生成 。利用 GPT4 强大语言生成能力,根据图像生成相关指令和回答,如对话式问答、复杂推理问题及答案等,提升数据多样性和质量,帮助模型学习复杂图文理解和推理能力;

-
-
利用 Text - only GPT4 处理不同类型图像文本信息,生成多样训练数据:
-
输入数据类型:

- Captions(文本描述):对图像场景文字叙述,如 “一群人带着各种行李站在黑色车辆外” 等,从不同角度描述图像内容;
- Boxes(边界框信息):用坐标表示图像中物体位置,如 “person: [0.681, 0.242, 0.774, 0.694]” ,确定人物、背包、行李箱等物体在图像中的位置;
-
生成数据类型:
-
图像精细描述(detailed description ):基于输入信息,详细阐述图像场景,像 “这是一个地下停车场,有一辆黑色 SUV 停着……” ,丰富图像的文本表达;

-
对话(conversation ):构建问答形式对话,如 “图像中是什么类型的车辆? - 图像中是一辆黑色运动型多用途汽车(SUV )” ,模拟人与模型交互问答场景;

-
“复杂” 推理(complex reasoning ):提出并解答需推理的问题,如 “这些人面临什么挑战? - 他们面临将所有行李装入黑色 SUV 的挑战……” ,锻炼模型推理能力;

-
-
-
自定义数据准备:
-
用户可自行设定图像文件路径、非重复 id,并编写相关图文问答对,丰富训练数据,满足特定领域或个性化训练需求;
-
例1:

-
例2:

-
4.3.3 模型训练
-
两个阶段的训练参数及相关信息:
-
特征对齐的预训练:
Hyperparameter Global Batch Size Learning rate Epochs Max length Weight decay LLaVA-v1.5-13B 256 1e-3 1 2048 0 - 超参数设置
- Global Batch Size(全局批量大小):256 ,一次训练处理的数据样本数量,较大值利于利用计算资源加速训练,但可能内存需求大;
- Learning rate(学习率):1e - 3 ,控制模型每次更新参数的步长,该值决定模型学习速度和稳定性;
- Epochs(训练轮数):1 ,表示训练数据遍历次数;
- Max length(最大长度):2048 ,可能指输入序列最大长度;
- Weight decay(权重衰减):0 ,用于防止模型过拟合的正则化手段;
- 训练资源与耗时:使用 8 块 A100(80GB) GPU ,耗时 5.5 小时 ,基于 DeepSpeed ZeRO - 2 优化技术;
- 输入与结构:输入图像分辨率 336px ,训练参数聚焦特征映射层结构(2 层全连接层) ;
- 训练脚本:LLaVA/scripts/v1_5/finetune.sh at main · haotian-liu/LLaVA;
- 超参数设置
-
端到端微调:
Hyperparameter Global Batch Size Learning rate Epochs Max length Weight decay LLaVA-v1.5-13B 128 2e-5 1 2048 0 - 超参数设置
- Global Batch Size:128 ,比预训练阶段小,微调时更精细调整模型;
- Learning rate:2e - 5 ,较小学习率使模型微调时更新更细致;
- Epochs:1 ;
- Max length:2048 ;
- Weight decay:0 ;
- 训练资源与耗时:同样 8 块 A100(80GB) GPU ,耗时 20 小时 ,基于 DeepSpeed ZeRO - 3 优化技术;
- 输入与结构:输入图像分辨率 336px ,训练参数涉及特征映射层结构(2 层全连接层)及大语言模型(LLM)整体;
- 训练脚本:与预训练相同,LLaVA/scripts/v1_5/finetune.sh at main · haotian-liu/LLaVA;
- 超参数设置
-
4.3.4 模型部署
-
部署架构
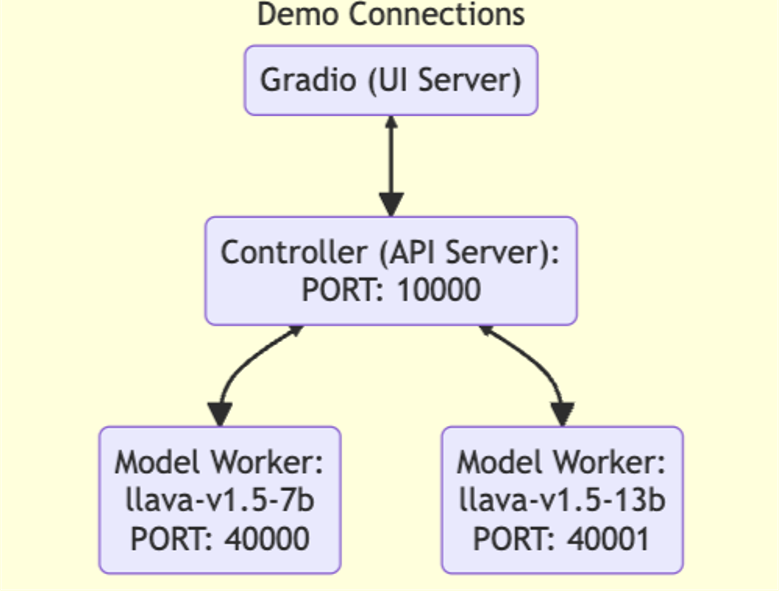
- Gradio(UI Server):提供用户界面,用于和模型交互,方便用户输入请求、查看模型输出;
- Controller(API Server):作为 API 服务器,端口为 10000 ,负责协调和管理模型工作节点(Model Worker) ,处理来自 UI 服务器的请求并分配给合适的工作节点;
- Model Worker:运行具体模型实例,如 llava-v1.5-7b 和 llava-v1.5-13b ,分别监听端口 40000 和 40001 ,接收 Controller 分配的任务并进行推理计算,返回结果;
-
部署步骤
- 启动 API server:执行命令
python -m llava.serve.controller --host 0.0.0.0 --port 10000,让 API 服务器在指定主机和端口监听,为后续服务提供基础; - 启动 WebUI:使用命令
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b,启动模型工作节点,指定主机、与 Controller 通信地址、自身监听端口及加载的模型路径; - 启动 Worker:如
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port <different from 40000, say 40001> --worker http://localhost:<change accordingly, i.e. 40001> --model-path <ckpt2> --load-4bit,可启动额外工作节点,通过调整端口和模型路径等参数,实现多模型或多实例部署。
- 启动 API server:执行命令
4.3.5 模型效果评测
-
评测设置
- 评测数据:基于 30 张未见图片,每张图片对应对话、详细描述、推理 3 种指令,共 90 组图文指令;
- 评测方式:使用 GPT - 4 对 LLaVA 和 GPT - 4 自身输出结果进行 1 - 10 打分;
-
评测结果
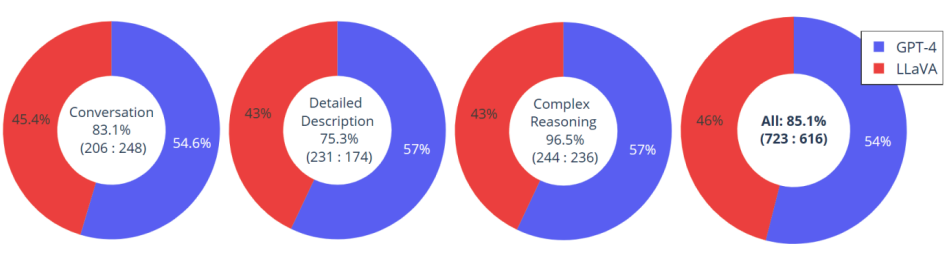
- 各项任务得分
- Conversation(对话):LLaVA 得分占比 45.4% ,GPT - 4 占 54.6% ,整体准确率 83.1%(206 : 248 是正确结果数量对比 );
- Detailed Description(详细描述):LLaVA 占 43% ,GPT - 4 占 57% ,准确率 75.3%(231 : 174 为相关数据对比 ) ;
- Complex Reasoning(复杂推理):LLaVA 和 GPT - 4 占比分别为 43% 和 57% ,准确率 96.5%(244 : 236 为相关数据对比 ) ;
- 综合表现:LLaVA 生成结果与 GPT - 4 生成结果平均相关程度达 85.1%(723 : 616 为综合对比数据 ) ,说明 LLaVA 在图文处理任务上与 GPT - 4 有一定相似性和准确性,但在各项具体任务上仍与 GPT - 4 存在差距。
- 各项任务得分
4.4 LLaVa衍生与改进
4.4.1 衍生
-
AI导盲llavavision:lxe/llavavision: A simple “Be My Eyes” web app with a llama.cpp/llava backend;
llavavision是一个简单的 “Be My Eyes” 风格的 Web 应用程序 ,项目地址为 lxe/llavavision 。它以 llama.cpp/llava 为后端,借助 [SkunkworksAI BakLLaVA - 1](https://huggingface.co/SkunkworksAI/BakLLaVA - 1) 模型来描述所看到的事物,并使用 [Web Speech API](https://developer.mozilla.org/en - US/docs/Web/API/Web_Speech_API) 进行文本朗读;- 例:右侧手机截图展示了应用界面,屏幕上方是摄像头捕获的户外场景画面,有秋千、遮阳伞等设施。屏幕下方文字是对画面的描述:这是一个有围栏的后院区域,有带多个秋千的游乐场,一些秋千挨在一起,一些分散开。院子里还有一张桌子和一条长凳,供孩子和家长休息。天气晴朗,阳光照射,还设置了几把伞,可能用于遮阳或挡雨;
- 界面上有 “Switch Camera”(切换摄像头)、“Describe”(描述)、“Clear”(清除)按钮 ,用户可通过这些按钮操作,实现切换摄像头、获取图像描述和清除描述内容等功能。
-
AI就诊LLaVA - Med:microsoft/LLaVA-Med: Large Language-and-Vision Assistant for Biomedicine, built towards multimodal GPT-4 level capabilities.;
- 简介:是面向生物医学领域的大型语言与视觉助手,目标是达到多模态 GPT - 4 级别的能力 ,由微软相关团队开发,项目地址为 microsoft/LLaVA - Med;
- 训练过程:
- Stage 1(可选):医学概念对齐阶段,在 600K 样本上训练 1 个 epoch,耗时 7 小时。此阶段让模型的视觉与语言表征在医学概念上对齐;
- Stage 2:医学指令微调阶段,在 60K 样本上训练 3 个 epoch,耗时 8 小时。通过此阶段让模型针对医学领域的指令进行优化,提升在医学任务上的表现;
- 应用场景:可用于医学视觉聊天(Medical Visual Chat)和医学视觉问答(Medical VQA) ,包括放射学视觉问答(VQA - Radiology) 、SLAKE 、病理学视觉问答(Pathology - VQA)等任务;

-
视频相关Video - LLaVA:PKU-YuanGroup/Video-LLaVA: 【EMNLP 2024🔥】Video-LLaVA: Learning United Visual Representation by Alignment Before Projection;
- 简介:由 PKU - YuanGroup 开发,相关研究成果发表于 EMNLP 2024 ,项目地址为 PKU - YuanGroup/Video - LLaVA 。该模型通过在投影前进行对齐来学习统一的视觉表征;
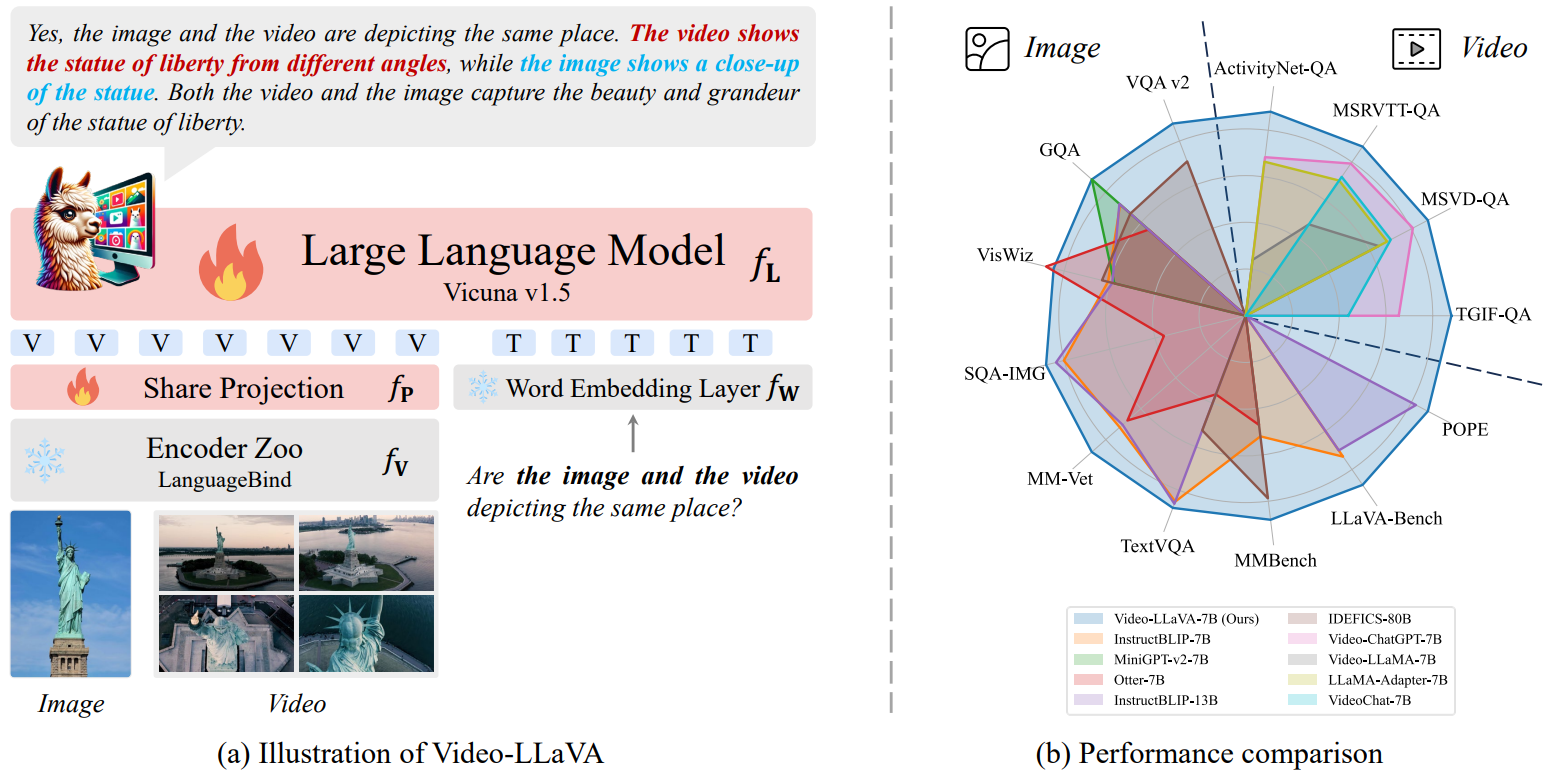
- 模型架构:基于 Vicuna v1.5 大语言模型,结合 LanguageBind 编码器等组件。通过共享投影层(Share Projection f P f_P fP )、词嵌入层(Word Embedding Layer f W f_W fW )等,将图像和视频的视觉信息与语言模型融合。例如判断图像和视频是否描绘同一地点时,模型可综合分析视觉特征与语言指令;
- 性能表现:右侧雷达图展示了 Video - LLaVA - 7B 与其他模型在多个视频和图像问答基准测试(如 ActivityNet - QA、MSRVTT - QA 等 )上的性能对比,体现其在多模态任务上的竞争力;
-
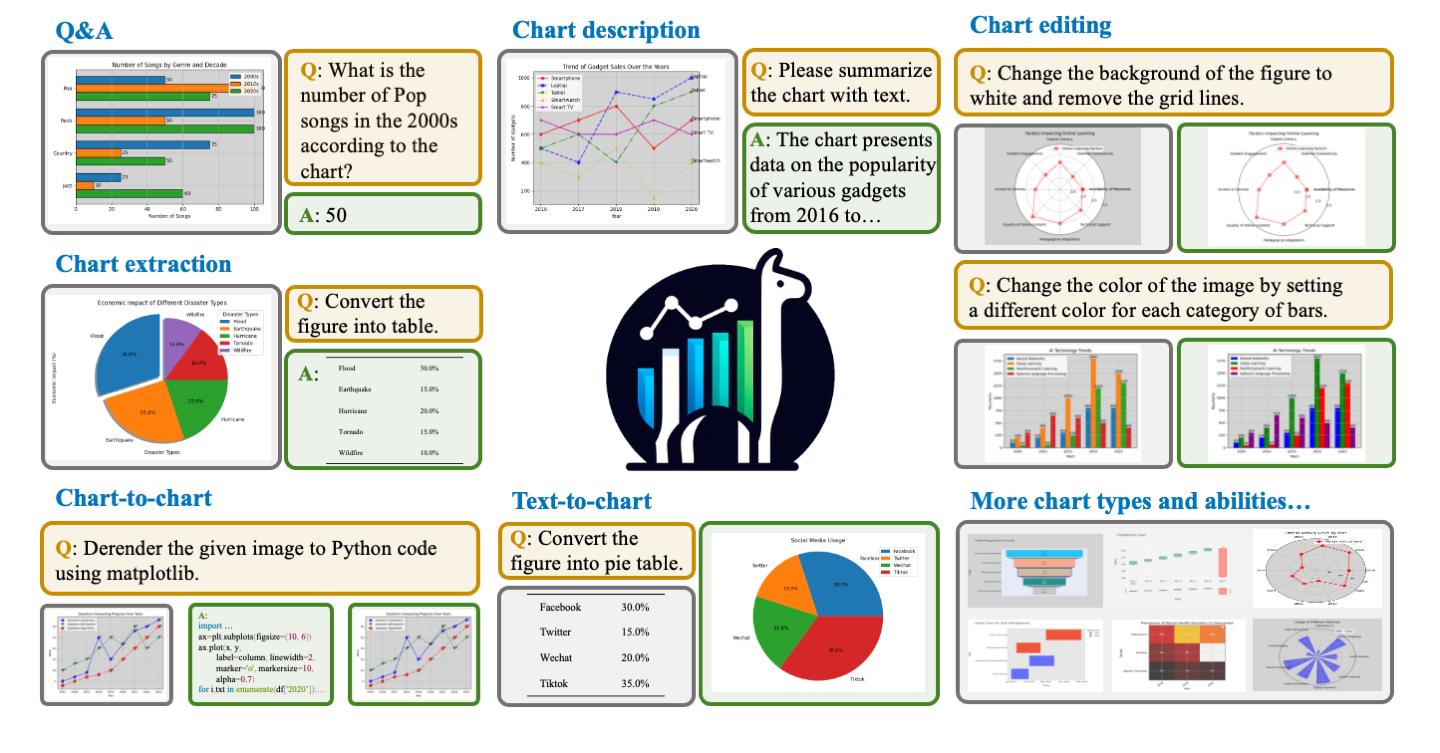
图表问答与生成ChartLlama - code:tingxueronghua/ChartLlama-code;
- 简介:用于图表问答与生成的项目,项目地址为 tingxueronghua/ChartLlama - code 。
- 功能展示:
- 问答(Q&A):能回答基于图表数据的问题,如根据图表回答 2000 年代流行歌曲数量;
- 图表描述(Chart description):用文本总结图表内容;
- 图表编辑(Chart editing):可按指令修改图表属性,如更改背景颜色、去除网格线、改变图表颜色等;
- 图表提取(Chart extraction):将图表信息转换为表格形式;
- 图表转换(Chart - to - chart):将给定图表转换为 Python 代码(如使用 matplotlib );
- 文本转图表(Text - to - chart):根据文本信息生成相应图表,如将文本数据转换为饼图;
4.4.2 改进方向
- Vision Encoder 改进:
- 提升分辨率:早期 LLaVA 输入图像分辨率为 224 像素,后来提升到 336 像素 ,如 LLaVA 1.5 。更高分辨率让模型能捕捉更多图像细节,增强对图像内容的理解。像 LLaVA 1.6 引入 “AnyRes” 技术,支持如 672x672、336x1344、1344x336 等更大分辨率,还能通过图片裁切、编码和合并处理不同分辨率输入,提升视觉编码器灵活性;
- 改进视觉指令调整数据混合:通过更合理混合不同来源、类型的视觉指令数据,模型能学习到更丰富多样视觉知识和模式,提升视觉推理能力,比如对图像中物体关系、场景理解等。同时,优化数据混合也有助于增强光学字符识别(OCR)能力,更准确识别图像中的文字信息;
- 扩展应用场景:使模型在更多不同场景实现更好视觉对话,涵盖医疗、教育、日常交互等领域,提升在各种实际应用中的适用性和效果;
- 增强知识和推理能力:借助 SGLang 等技术,让模型具备更好世界知识和逻辑推理能力,能基于图像信息进行更深入分析、推理和回答,提升智能程度和实用性;
- Projection 改进:
- 升级映射结构:从 LLaVA 到 LLaVA 1.5,将原来单个线性层的投影层替换为多层感知机(MLP)。MLP 有多个线性层堆叠,可捕捉更复杂非线性关系,更好对齐视觉和语言特征,提升多模态生成效果。例如在描述图像内容时,能更精准将视觉特征转化为语言表述;
- 优化特征对齐范式:多模态大语言模型关键在于特征对齐,改进 Projection 机制围绕优化 All - to - one(LLM)的特征对齐范式展开。通过调整投影过程中的参数、算法等,使视觉特征经投影后能更精准与语言模型特征空间匹配融合,让模型在处理图文混合信息时理解和生成能力更优。
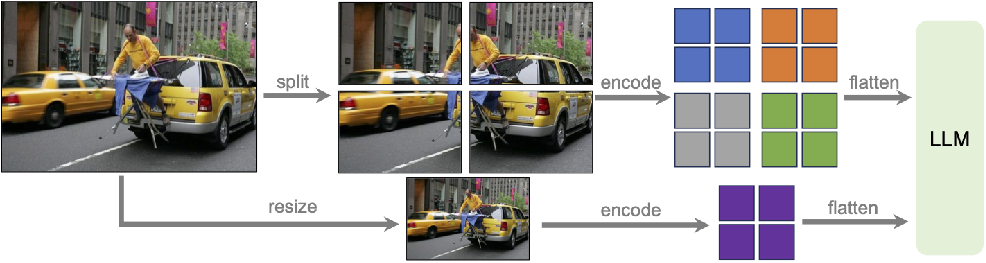
4.4.3 Vision Encoder 改进:LLaVA1.6(LLaVA-Next)
-
LLaVA 1.6(LLaVA - Next)在 Vision Encoder 方面的改进;
-
分辨率提升:将输入图像分辨率大幅增加,支持 672x672、336x1344、1344x336 等多种宽高比 。更高分辨率使模型能捕捉更多视觉细节,比如图像中物体纹理、文字细节等,为后续分析和理解提供更丰富信息;
-
视觉指令调整优化:通过改进视觉指令调整数据混合,模型的视觉推理能力增强,能更准确分析图像中物体关系、场景逻辑等。同时,OCR(光学字符识别)能力也得到提升,可更精准识别图像中的文字内容;
-
应用场景拓展:能在更多不同场景实现更好的视觉对话。无论是日常生活场景、专业领域场景(如医疗影像分析、工业检测等),还是教育、娱乐等场景,都能更有效地与用户交互,提供准确的视觉相关回答;
-
知识与推理能力增强:具备更好的世界知识和逻辑推理能力。借助 SGLang 技术,实现高效部署和推理,使模型在处理图像相关问题时,能结合广泛的世界知识进行更合理的逻辑推理,给出更具深度和准确性的回答;
-
图像预处理流程:上图中展示了图像预处理过程
- 包括将图像 “split”(分割)成不同部分分别 “encode”(编码)再 “flatten”(展平)输入到 LLM(大语言模型);
- 以及对图像进行 “resize”(调整大小)后再 “encode” 和 “flatten” 输入 LLM;
- 这种灵活的预处理方式有助于适应不同分辨率和图像结构,提升模型对图像信息的处理效率和效果。
4.4.4 Vision Encoder 改进:Fuyu-8B
-
Fuyu 模型架构:
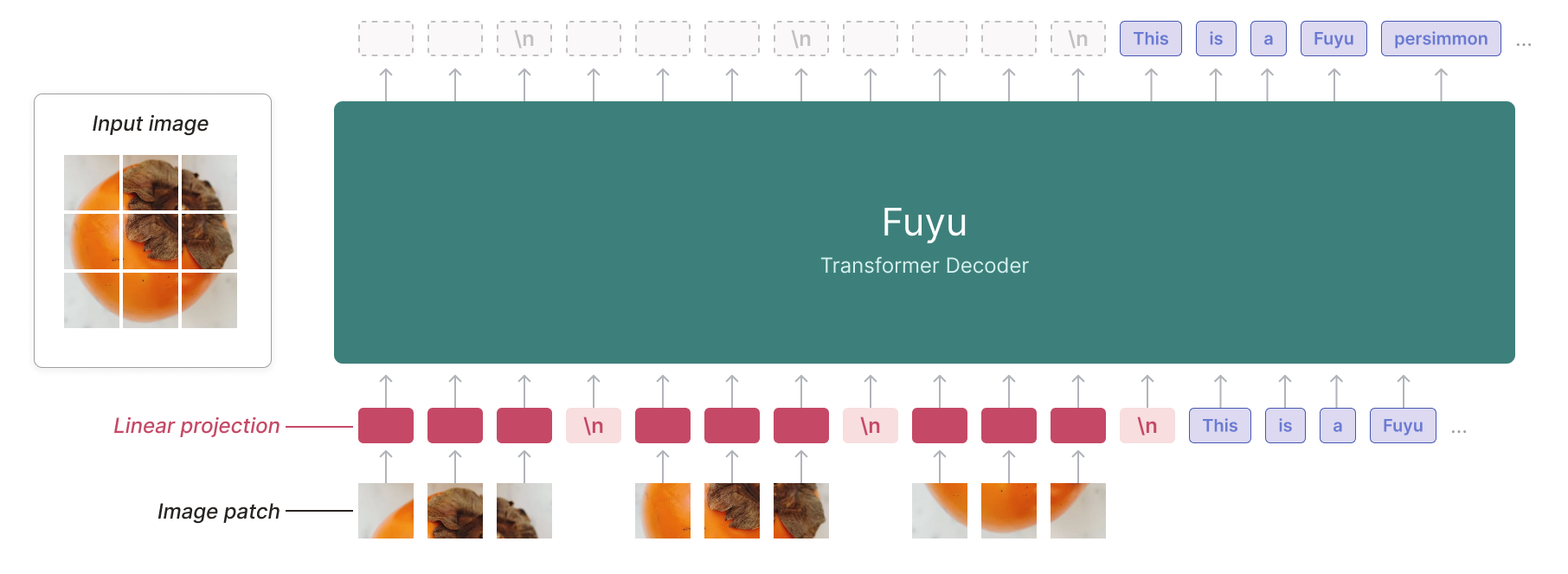
- 输入图像:展示了一张柿子的图片,作为模型的视觉输入源;
- 图像分块(Image patch):将输入图像划分为多个小块,这是常见的图像特征提取预处理步骤,便于模型捕捉图像局部特征;
- 线性投影(Linear projection):对图像块进行线性投影操作,将图像特征映射到合适的特征空间,以便后续处理;
- Fuyu Transformer Decoder:模型核心部分,采用 Transformer Decoder 架构,接收经过处理的图像特征和文本信息(图中示例文本为 “This is a Fuyu persimmon” ),进行综合处理和生成输出;
-
Fuyu 模型应用案例:
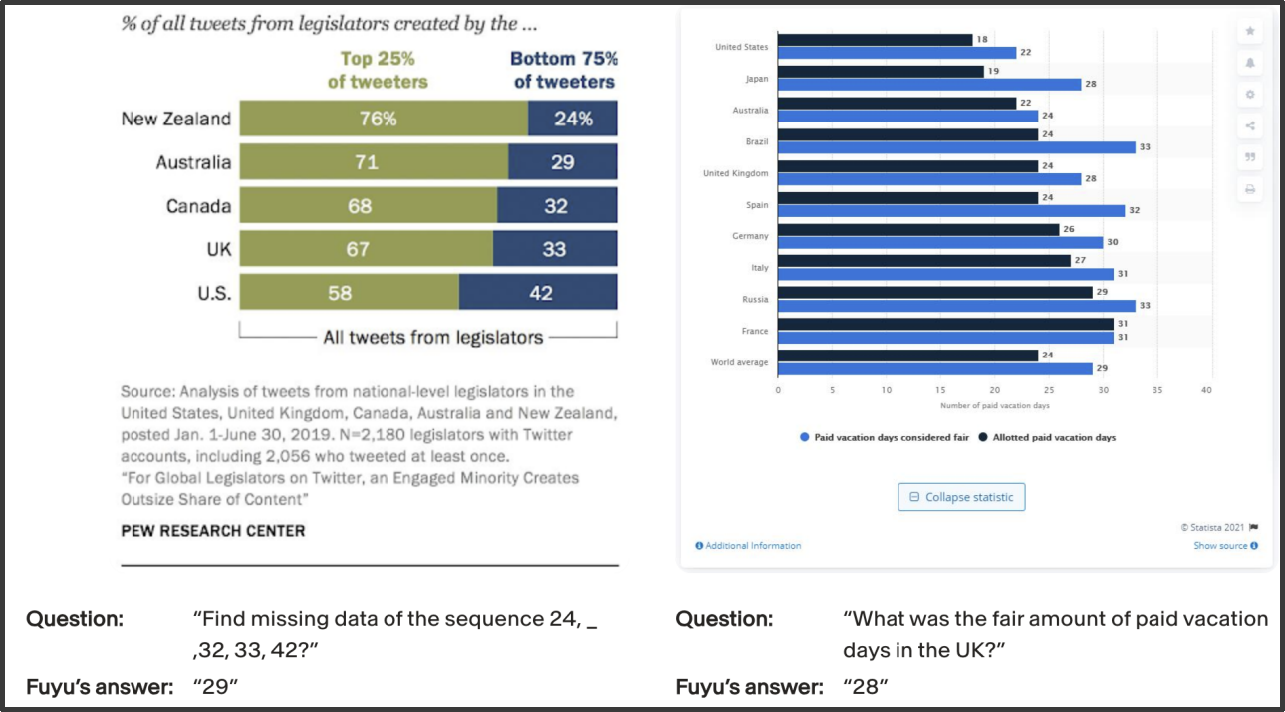
- 左侧图表:展示了新西兰、澳大利亚、加拿大、英国、美国等国家立法者发布推文的情况,按推文发布量前 25% 和后 75% 的用户进行划分 。来源是皮尤研究中心(PEW RESEARCH CENTER)对 2019 年 1 月 1 日 - 6 月 30 日期间部分国家立法者推文的分析;
- 右侧图表:呈现了不同国家带薪休假天数情况,区分了被认为合理的带薪休假天数(Paid vacation days considered fair)和实际允许的带薪休假天数(Allowed paid vacation days );
- 问题与回答
- 数学问题:问题是 “Find missing data of the sequence 24, _, 32, 33, 42?” ,Fuyu 回答为 “29” 。从数列规律看,该数列可能是依次递增,差值不固定,通过尝试可发现相邻数字差值有一定规律,推测出缺失数字为 29;
- 图表问题:问题是 “What was the fair amount of paid vacation days in the UK?” ,Fuyu 回答为 “28” 。从右侧图表中可找到英国(UK)对应的合理带薪休假天数数值为 28。
4.4.5 Vision Encoder 改进:MiniCPM-Llama3-V 2.5
-
MiniCPM - Llama3 - V 2.5 在 Vision Encoder 方面的改进;
-
图像编码方式:采用类似 LLaVa1.6 的分区 + 整图组合的图像编码方式 ,能兼顾图像局部细节和整体特征,提升视觉信息处理效果;
-
特征提取器替换:使用支持更高分辨率图像特征提取的 SigLip 替代 CLIP ,siglip - so400m - 14 - 980 - flash - attn2 - navit ,可更好处理高分辨率图像,捕捉更多视觉细节;
-
分辨率映射技术:采用类似 q - former 的技术,支持将任意分辨率图像映射到固定长度的视觉编码 ,增强模型对不同分辨率图像的适应性;
-
高效加速技术:通过模型量化、CPU、NPU、编译优化等手段,实现高效的终端设备部署 ,提升模型运行效率,降低资源消耗;
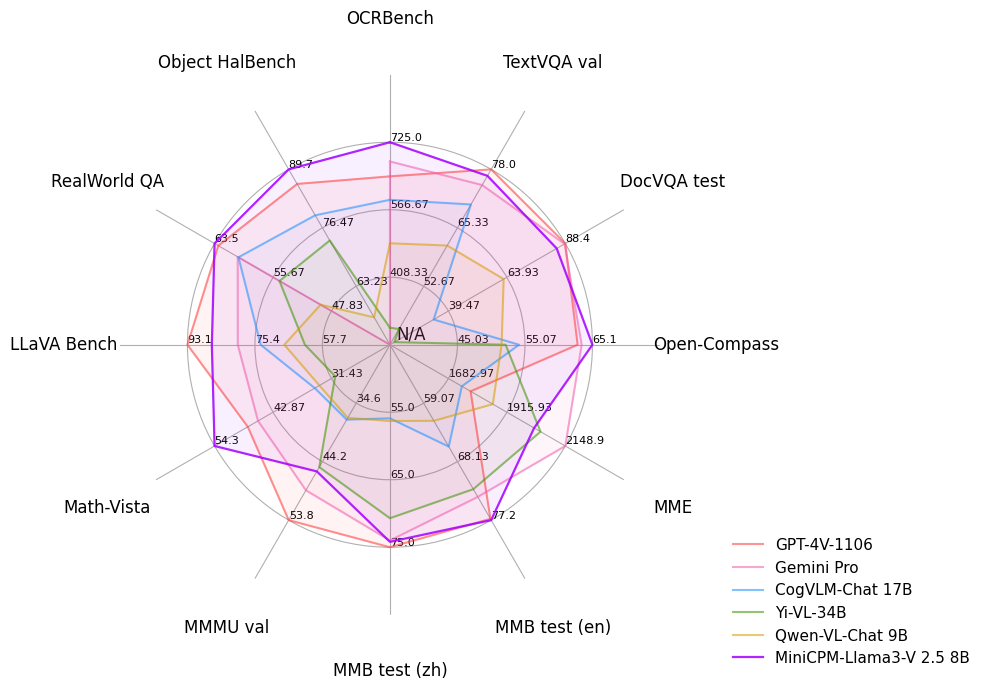
-
性能评估:雷达图展示了 MiniCPM - Llama3 - V 2.5 在多个评测基准(如 OCRBench、TextVQA val 等 )上的性能表现,并与 GPT - 4V - 1106、Gemini Pro 等模型对比 ,直观呈现其优势与不足;
-
下面介绍了面壁 Ultra 对齐技术,包括其对大模型推理能力的提升、对齐数据集特点(多类型、高质量 )、推理过程质量保障措施、在 Eurax - 8x28B 模型上的应用及对模型推理效率和准确性的优化等内容;

4.4.6 Vision Encoder 改进:MiniCPM-V 2.6 (Qwen2-7B)
-
MiniCPM - V 2.6(Qwen2 - 7B)在 Vision Encoder 方面的改进及微调训练;
-
模型主要改进
- 端侧设备部署:支持在端侧设备部署,能在 iPad 上运行实时视频理解任务 ,拓展了应用场景,使模型可在移动终端高效处理视觉相关任务;
- 模型组件选择:采用 Qwen2 - 7B 作为大语言模型(LLM) ,沿用 SigLip - 400M ,并使用 SigLip 替代 CLIP 进行更高分辨率图像特征提取,提升对图像信息的捕捉和处理能力;
- 模型规模与性能:具有 8B 参数规模,在 20B 以下模型中,在单图、多图、视频理解任务上达到 SOTA(State - of - the - Art,当前最优 )水平;
-
微调训练
-
微调框架:支持 SWIFT 框架微调训练,涵盖 LoRa 微调训练和全参数微调训练 ,提供灵活的模型优化方式;
-
训练类型:支持多图微调训练和视频微调训练 ,可针对不同模态数据进行优化,提升模型在多模态任务上的表现;
-
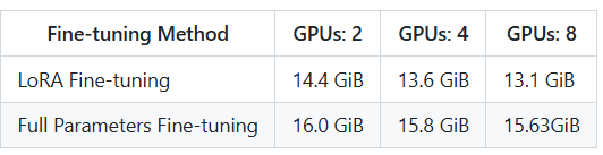
资源需求:下表展示了不同微调方法(LoRa Fine - tuning 和 Full Parameters Fine - tuning )在使用不同数量 GPU(2 个、4 个、8 个 ,以 A800 80GB 为例,基于 DeepSpeed ZERO - 3,bs = 1 )时所需显存情况,为模型训练资源配置提供参考;
-
-
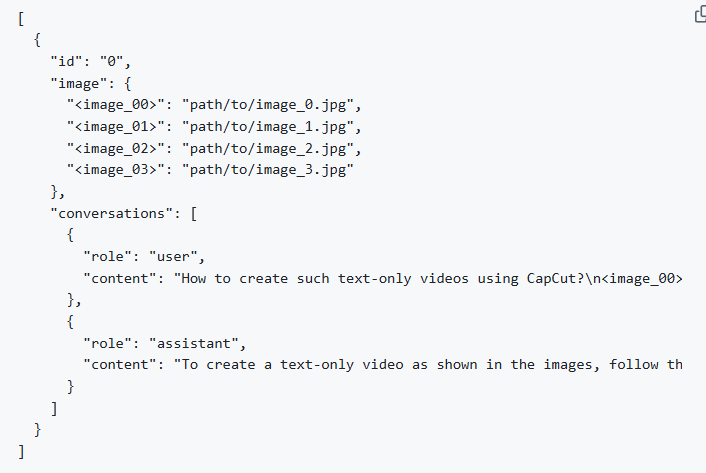
下图展示了包含图像路径(如 image_00、image_01 等对应的路径 )和对话内容(用户提问及助手回答 )的 JSON 数据格式示例,体现模型输入输出的数据组织形式;
4.4.7 Projection机制改进
-
InternLM - XComposer2:
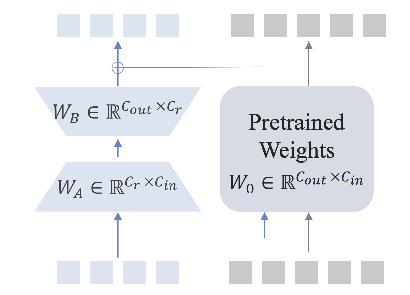
- Projection机制架构:
- 展示了Projection机制的结构,涉及权重矩阵 W A ∈ R C r × C i n W_A \in \mathbb{R}^{C_r \times C_{in}} WA∈RCr×Cin、 W B ∈ R C o u t × C r W_B \in \mathbb{R}^{C_{out} \times C_r} WB∈RCout×Cr 以及预训练权重 W 0 ∈ R C o u t × C i n W_0 \in \mathbb{R}^{C_{out} \times C_{in}} W0∈RCout×Cin;
- 通过这些矩阵运算,将图像特征(如柿子图像块 )进行投影变换,使其与语言模型的特征空间更好地对齐,便于后续多模态信息融合处理 ;
- Projection机制架构:
-
InternLM - XComposer2.5:
-
Screenshot - to - Code功能:具备将截图转换为代码并渲染的能力。如图中展示了从人物信息截图生成相关代码并渲染出新的展示形式,可用于界面设计、文档处理等场景,将视觉元素转化为可操作的代码,提高开发和处理效率;

-
高分辨率图像对话功能:支持在4K分辨率图像上进行对话交互,能够详细分析图像内容。如对展示迪拜各种信息的4K分辨率信息图表进行深入解读,包括迪拜的棕榈岛、酒店数量、犯罪率、所得税税率等信息,体现其在处理高分辨率复杂图像时的强大理解和分析能力;

-
4.5 目前开源的 SoTA 多模态 LLM
-
“SOTA” 是 “State - of - the - Art” 的缩写,意为 “当前最优”“最先进水平”;
-
InternVL 2 训练数据集构造:
- 提供简单、详细的微调训练教程(Fine-tune on a Custom Dataset — InternVL) ,方便开发者基于自定义数据集对模型进行优化。
- 其训练数据集构造与 LLaVA 类似,但有独特支持特性;
-
支持特性:
-
目标定位、检测数据输入输出:以 JSON 格式展示,包含图像 id、路径、宽高信息。对话部分,用户可要求提供特定描述区域的边界框坐标(如 “请提供‘穿蓝色衬衫的女士’所在区域的边界框坐标” ),模型给出对应坐标 ,适用于图像目标检测与定位任务;
{ "id": 2324, "image": "COCO_train2014_000000581857.jpg", "width": 427, "height": 640, "conversations": [ { "from": "human", "value": "<image>\nPlease provide the bounding box coordinate of the region this sentence describes: <ref>the lady with the blue shirt</ref>" }, { "from": "gpt", "value": "<ref>the lady with the blue shirt</ref><box>[[243, 469, 558, 746]]</box>" },] } -
视频数据输入:JSON 示例中,包含视频 id、路径。对话部分可实现用户要求对给定视频进行详尽描述,模型给出描述内容 ,支持视频模态数据处理;

-
多图像输入:JSON 显示可输入多个图像路径,附带各图像宽高列表。对话部分支持用户针对多图依次提问,模型给出相应回答 ,满足多图像场景的多模态交互需求;

-
4.6 高性能 MLLM 模型部署
-
必要条件:
- 批量化推理与高并发支持:模型要能同时处理多个推理任务,应对大量请求,提升效率;
- 量化版本模型推理支持:量化可减少模型存储和计算资源消耗,使模型在资源受限环境也能高效运行;
- 加速手段:比如 KV cache ,这是一种在语言模型推理时缓存关键值对的技术,可减少重复计算,加快推理速度;
-
推荐框架:
- SGlang 框架:是 llava 推荐的多模态推理框架,基于 vLLM 封装 ,提供 OpenAI Compatible API ,在多模态 mLLM 支持上,除 llava 外相对其他框架有优势;
- LMDeploy 框架:支持框架有限,但部署简单快捷 ,具备 Pytorch 接口和 OpenAI Compatible Server;
- vLLM 框架:支持多种框架,部署简便 ,有 Pytorch 接口和 OpenAI Compatible Server ,V6 版本还支持多图推理。
4.7 MLLM 开发推荐开源项目
-
MoE-LLaVA
- 名称及含义:Mixture of Experts for Large Vision - Language Models(大型视觉 - 语言模型的专家混合);
- 代码地址:PKU-YuanGroup/MoE-LLaVA: Mixture-of-Experts for Large Vision-Language Models;
- 功能特性:
- 支持 Qwen、Phi2、StableLM、Mistral、MiniCPM 等多种 LLM 架构的 LLaVa 改造训练;
- 支持 SigLip、CLIP 视觉编码器;
- 基本代码结构与 LLaVa 类似;
-
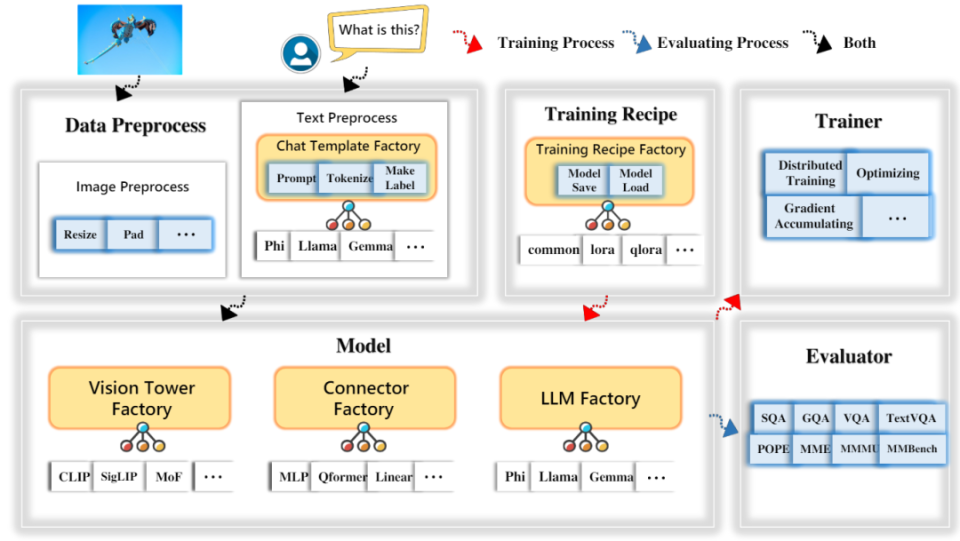
TinyLLaVA Factory
-
名称及含义:A Modularized Codebase for Small - scale Large Multimodal Models(小型大规模多模态模型的模块化代码库);
-
功能特性:
- 摒弃 LLaVA 代码中繁杂的图片和 Prompt 处理过程,提供标准可扩展的预处理流程;
- 图片预处理可自定义 Processor,也能使用官方视觉编码器的 Processor;
- 文本预处理定义基类 Template,提供添加 System Message、Tokenize 等函数,用户可继承基类扩展不同 LLM 的 Chat Template;
-
下图示展示了数据预处理、文本处理、训练流程、模型构建等模块及训练、评估流程;
-
4.8 支持视频的 MLLM
-
MiniGPT4-Video
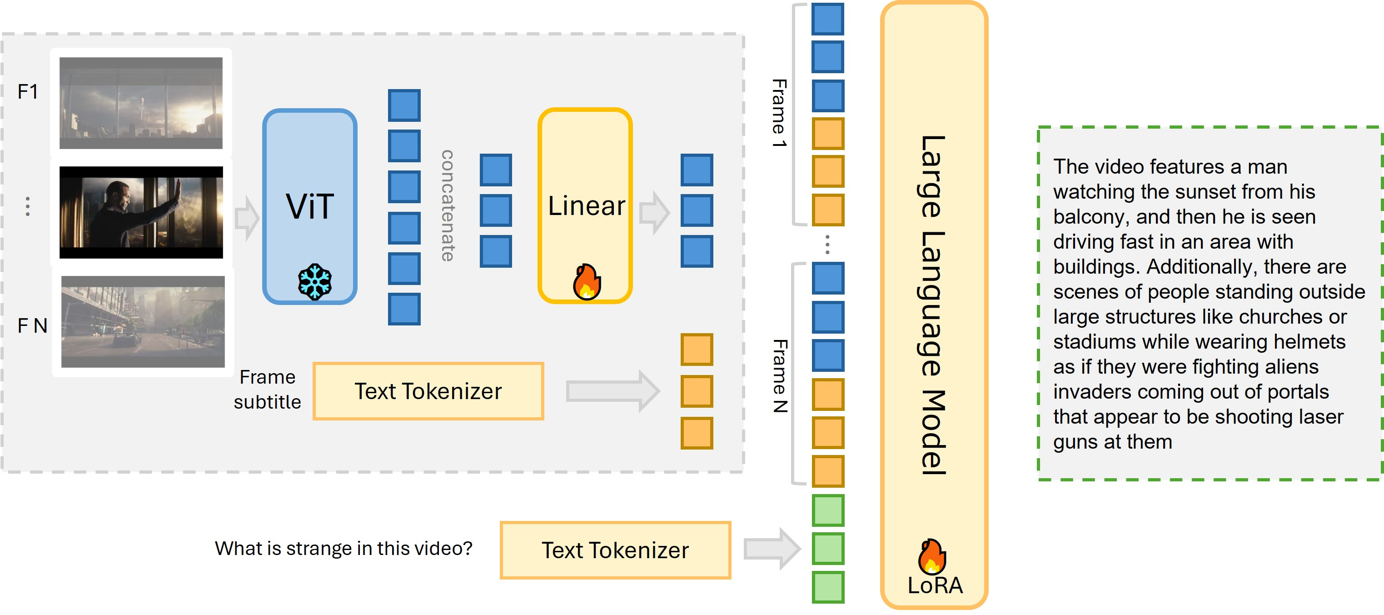
- 架构:通过 VIT 提取视频帧特征,经线性层处理后,结合文本标记器输出,输入到大语言模型,采用 LoRA 技术微调;
- 原理:将视频帧视觉信息转化为特征向量,与文本信息融合,让模型理解视频内容并生成相关文本回复;
-
LLaVA-Next-Video
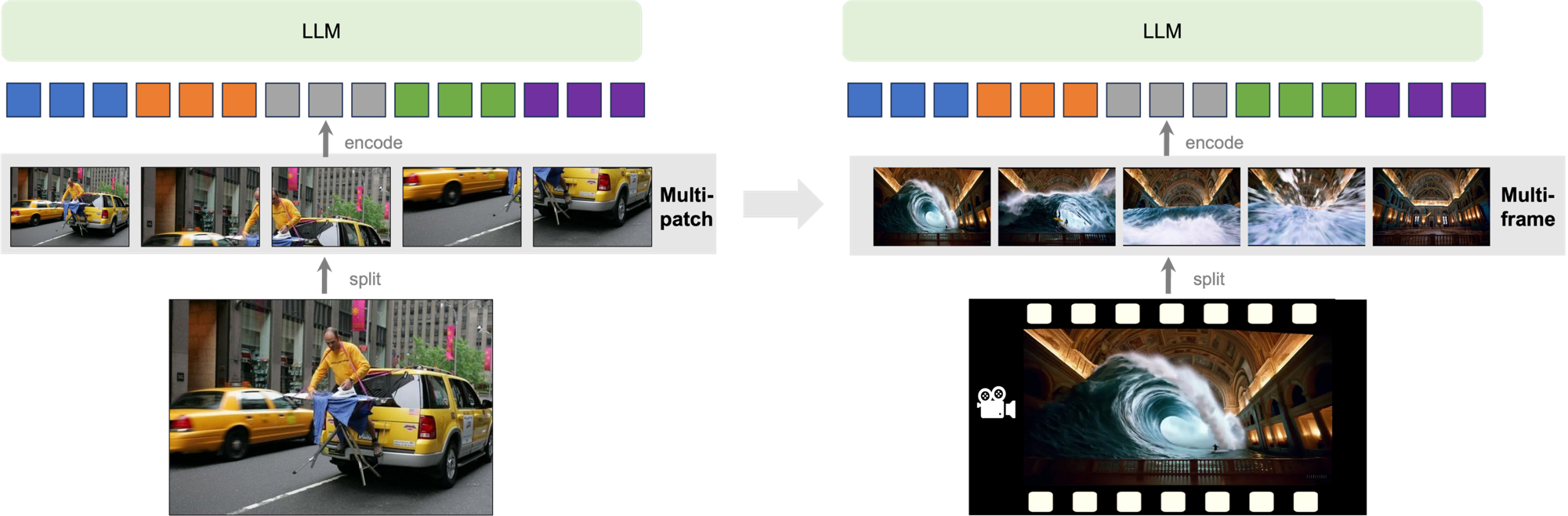
- 架构:涉及多 patch 和多 frame 处理,利用大语言模型(LLM)处理视频相关信息;
- 原理:对视频多帧及图像块进行编码处理,使模型能综合理解视频时空信息,完成相关任务;
-
VideoLLaMA2
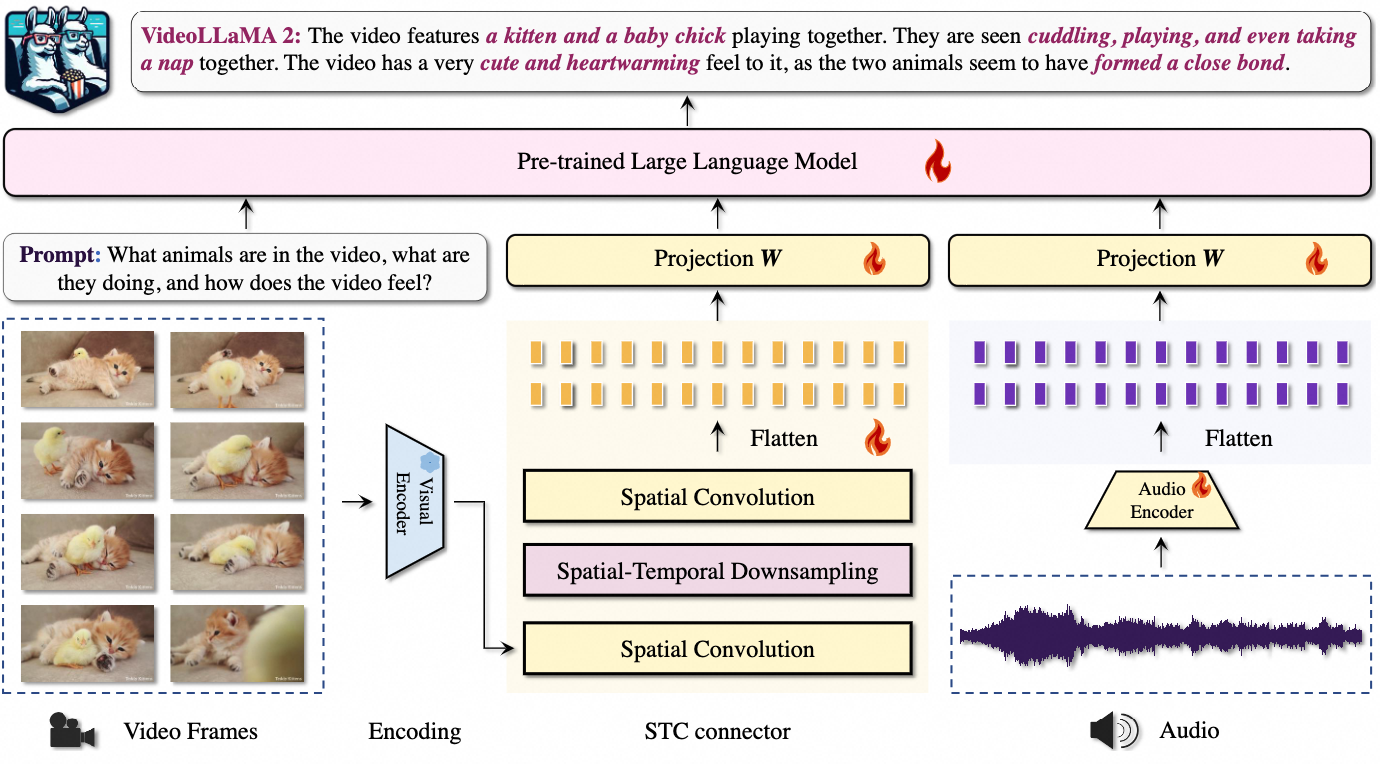
- 架构:输入视频帧经编码、时空下采样、空间卷积等操作,结合音频信息,通过投影层与预训练大语言模型交互;
- 原理:对视频视觉和音频信息分别处理并融合,借助大语言模型实现对视频内容理解与问答等功能;
-
VideoLLaVA

- 架构:图像和视频分别经 Encoder Zoo 处理,通过共享投影层与大语言模型(Vicuna v1.5 )交互,词嵌入层参与文本处理;
- 原理:将图像和视频信息统一处理,利用大语言模型判断图像与视频是否描绘同一地点等任务。
5 Beyond VL:支持更多模态输入的大语言模型
5.1 Qwen-Audio
-
Qwen-Audio:一种支持实时语音输入的多模态大语言模型;
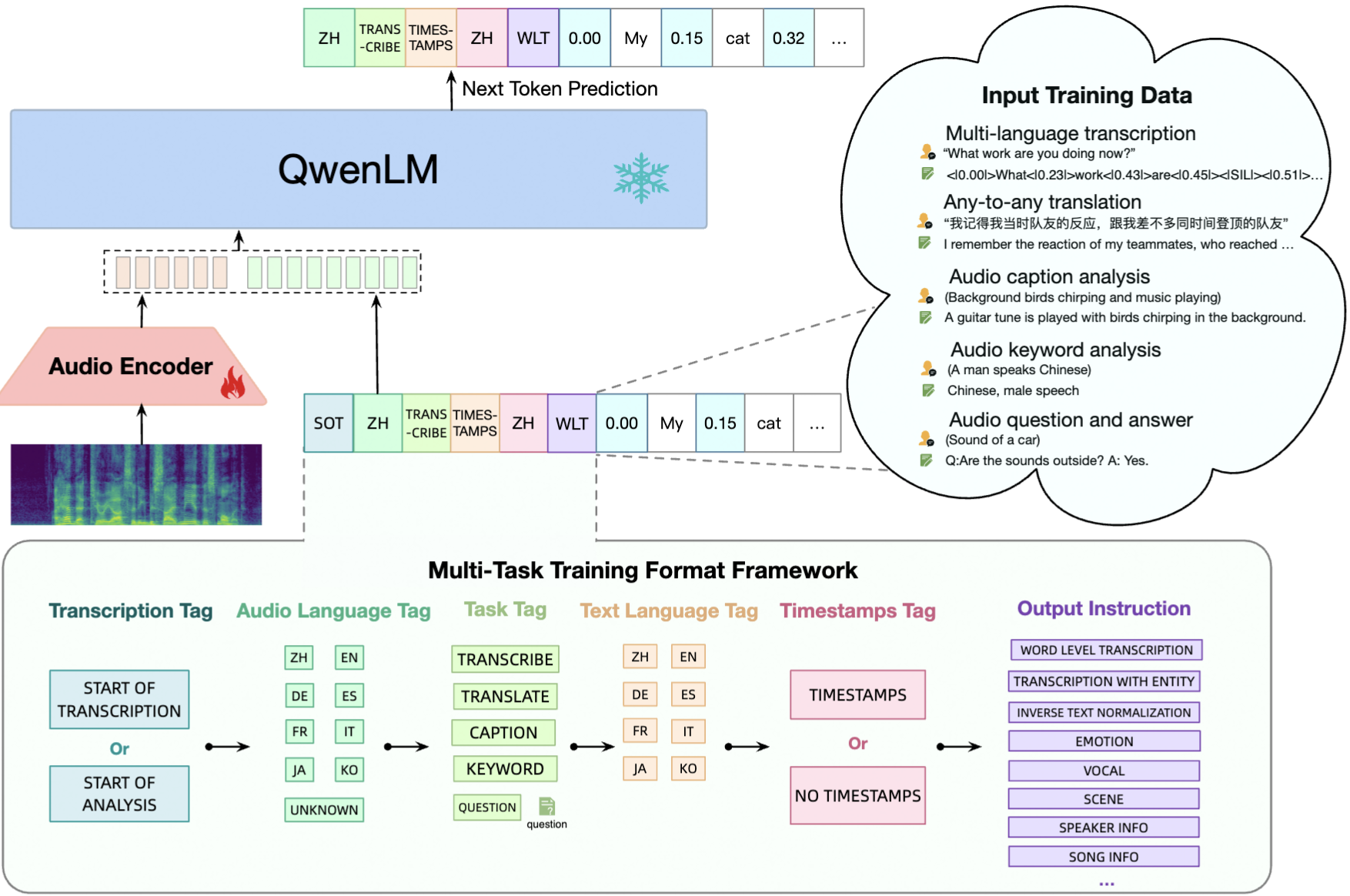
-
模型架构:
- Audio Encoder(音频编码器):负责将输入的音频信号(频谱图形式)转换为特征表示;
- QwenLM(大语言模型):接收音频编码器输出的特征,结合多种标签信息进行下一个 Token 预测,实现语音相关任务;
-
输入训练数据类型:
- 多语言转录:包含不同语言的语音转文本内容,如 “What work are you doing now?”;
- 任意语言翻译:涉及不同语言间的翻译数据;
- 音频字幕分析:对音频内容生成描述性字幕,如 “Background birds chirping and music playing”;
- 音频关键词分析:提取音频中的关键信息,如 “A man speaks Chinese”;
- 音频问答:针对音频内容进行问答交互,如 “Q:Are the sounds outside? A: Yes”;
-
多任务训练格式框架:涵盖转录标签、音频语言标签、任务标签、文本语言标签、时间戳标签等多种标签,对应不同输出指令,如单词级转录、带实体转录等。
-
支持功能:
- 多语言语音识别:识别多种语言语音内容。
- 语音翻译:实现语音在不同语言间转换。
- 分析语音场景:分析音频所处场景信息。
- 语音分析:综合分析音频各类特征 。
5.2 Mini-Omni
-
Mini-Omni:一种支持实时语音问答的多模态大语言模型;
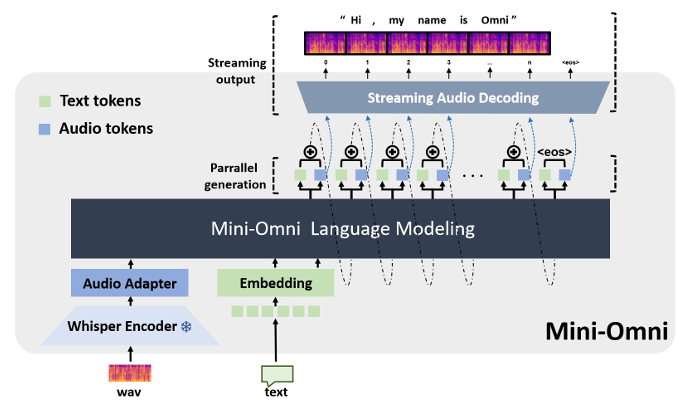
-
模型架构:
- 输入层:
- 接收音频(wav 格式)和文本输入;
- 音频经 Whisper Encoder 编码,再通过 Audio Adapter 处理;
- 文本通过 Embedding 模块处理 。
- 核心层:Mini - Omni Language Modeling 进行语言建模,实现文本 tokens 和 audio tokens 的并行生成;
- 输出层:通过 Streaming Audio Decoding 实现流式音频解码,输出结果,如 “Hi, my name is Omni”;
- 输入层:
-
运行机制:
- 并行生成:在模型处理过程中,文本和音频相关 tokens 并行生成,提高处理效率;
- 流式处理:支持流式音频解码,可实时处理和输出音频内容,实现实时语音问答等交互功能。
5.3 LLaMA-Omni
-
LLaMA-Omni:一种支持实时语音问答的多模态大语言模型;
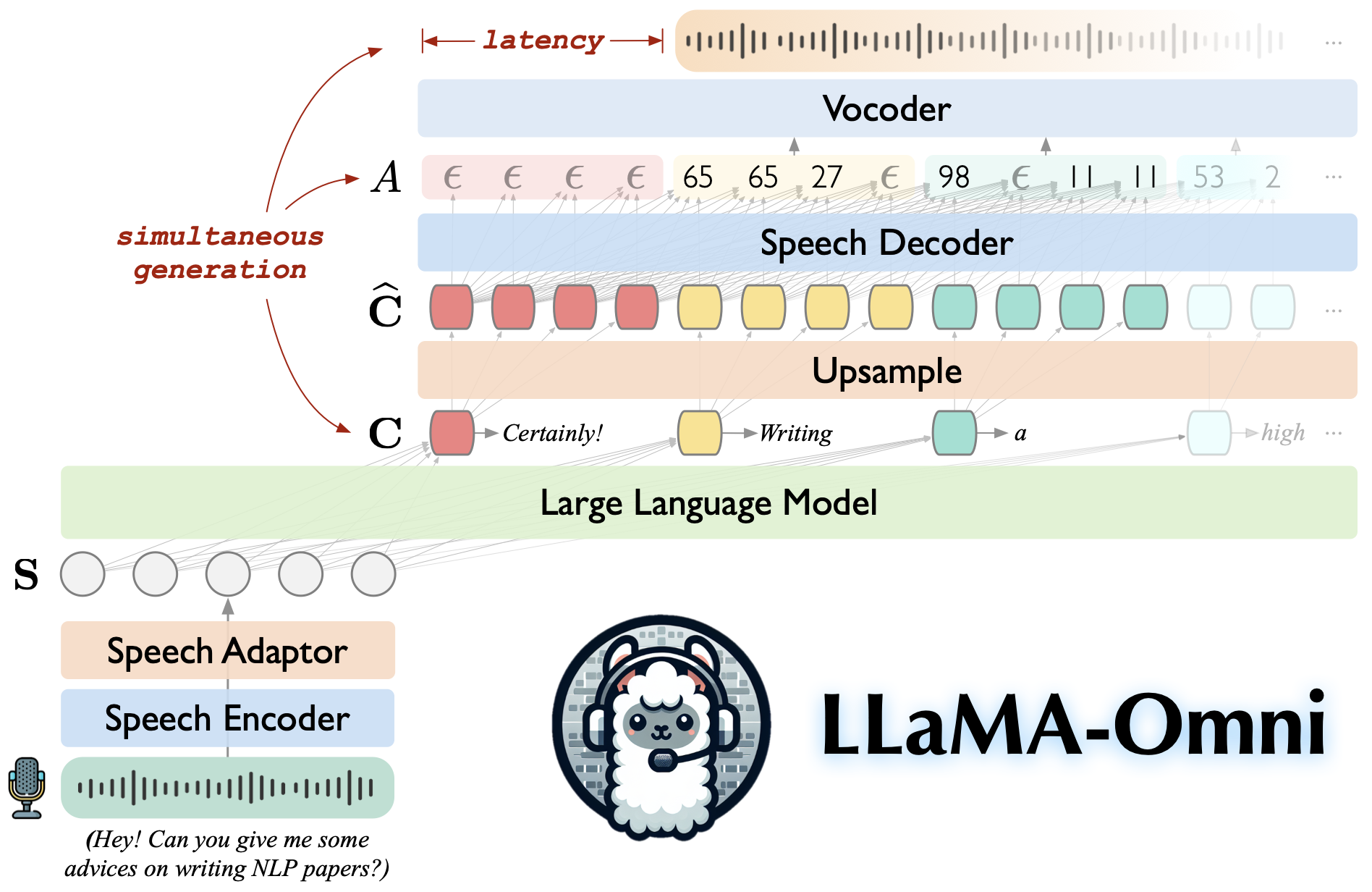
-
模型架构及运行流程:
- 输入阶段:语音信号通过麦克风输入,先经 Speech Encoder 编码,再由 Speech Adaptor 进行特征映射处理,转化为适合大语言模型处理的形式 ,输入到大语言模型(Large Language Model );
- 处理阶段:大语言模型生成文本表示(C),同时 Speech Decoder 生成中间表示(Â),两者可同时生成(simultaneous generation )。中间表示经 Upsample 处理后得到(Ĉ );
- 输出阶段:最终通过 Vocoder 将处理后的信号转换为语音输出,整个过程存在一定延迟(latency );
-
多模态 LLM 关键要素:
- Encoder(特征编码):负责将非文本模态(如语音)信息转化为模型可处理的特征表示;
- Adaptor(特征映射):对编码后的特征进行调整、映射,使其适配大语言模型;
- Decoder(特征解码):将模型处理后的特征转换为可理解的输出形式,如语音信号。
5.4 X-LLM
-
模型架构及运行流程
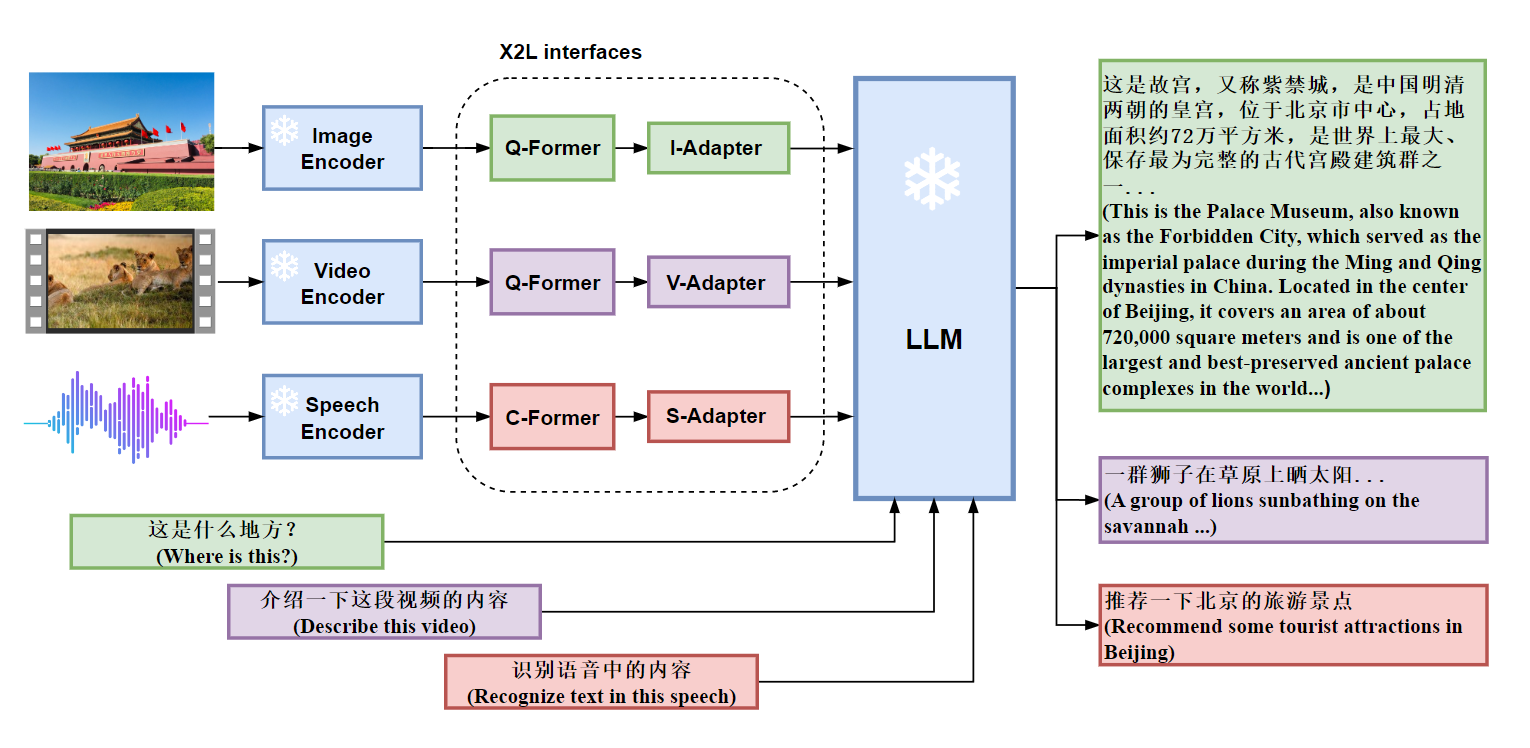
- 模态输入与编码:图像、视频、语音分别通过 Image Encoder、Video Encoder、Speech Encoder 进行特征提取;
- 特征转换:编码后的特征分别经过对应的 Q-Former(图像、视频)或 C-Former(语音),再通过 I-Adapter、V-Adapter、S-Adapter(统称 X2L interfaces ),将多模态特征转化为适合大语言模型(LLM)处理的形式;
- 模型处理与输出:LLM 接收处理后的多模态信息和文本输入,生成相应文本输出,如对图像、视频、语音内容的描述、问答回复等;
-
创新理念:将多模态(图像、视频、语音)当作 “外语”,通过特定接口转化处理,借助大语言模型实现多模态信息理解与交互,拓展大语言模型的应用范围和能力;
-
X - LLM 模型不同模态接口的训练数据及相关信息:
-
图像 interface 训练数据:下面列出多个数据集,如 CC3M、MSCOCO 等,数据形式为 Data Json ,语言均为中文(ZH) ,用于训练图像相关的接口,帮助模型理解图像内容;
Dataset Data Lang. CC3M Data Json ZH MSCOCO Data Json ZH Visual Genome Data Json ZH Flickr30k Data Json ZH SBU Data Json ZH AI Challenger Data Json ZH Wukong captions Data Json ZH -
语音 interface 训练数据:包含 AISHELL - 2、VSDial - CN 等数据集,数据形式是 Data Json ,语言为中文(ZH) ,用于训练语音相关接口,使模型能处理语音信息;
Dataset Data Lang. AISHELL-2 Data Json ZH VSDial-CN Data Json ZH -
视频 interface 训练数据:涉及 MSRVTT、ActivityNet 等数据集,通过 Video Url 获取视频,Data Json 提供相关数据,用于训练视频相关接口,提升模型对视频模态的处理能力;
Dataset Video Data MSRVTT Video Url Data Json ActivityNet Video Url Data Json
-
-
其他关键信息:
- Instruction Tuning 阶段的数据未公开;
- Q - former(见
5.5 Q-former结构)初始化自 BLIP - 2,C - former 初始化自 ASR 模型; - 训练过程分两个阶段:一是 Adapter 特征映射矩阵训练,二是 Instruction tuning 训练 ,逐步优化模型多模态处理性能。
5.5 Q-former结构
- Q-former 即 Querying Transformer,是连接图像编码器(Image Encoder)和大语言模型(LLM)的关键组件 ,在多模态模型中起到特征转换与融合的作用。
5.6 BLIP - 2 模型
-
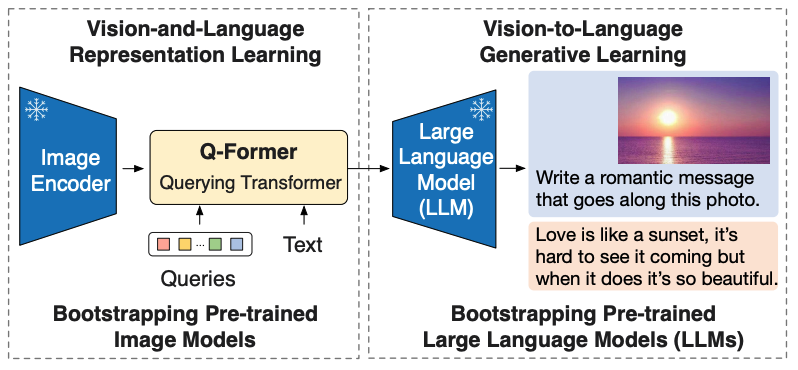
训练阶段:
- 视觉与语言表征学习(Vision-and-Language Representation Learning ):利用预训练图像模型,图像经 Image Encoder 提取特征,再通过 Q-former 结合文本 Queries 进行处理,实现视觉与语言特征融合;
- 视觉到语言生成学习(Vision-to-Language Generative Learning ):借助预训练大语言模型,将 Q-former 处理后的特征输入 LLM,进行文本生成任务;
-
应用示例:输入一张海边日落图片,模型被要求写一条浪漫文案,生成如 “Love is like a sunset, it’s hard to see it coming but when it does it’s so beautiful.” 这样的文本;
5.7 VITA
-
VITA,一个开源的交互式全模态大语言模型;
-
模型组件及功能:
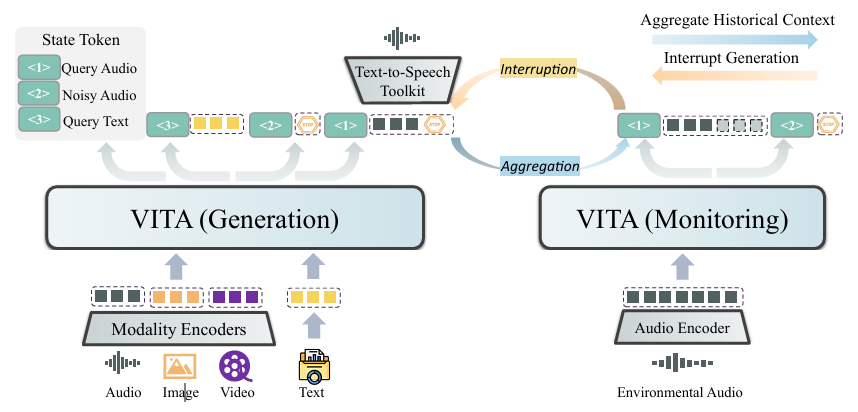
- VITA (Generation):接收来自音频、图像、视频、文本等模态编码器(Modality Encoders)的输入,利用状态标记(State Token ,如 Query Audio、Noisy Audio、Query Text )处理多模态信息,进行内容生成;
- VITA (Monitoring):通过音频编码器(Audio Encoder)接收环境音频输入,聚合历史上下文(Aggregate Historical Context ),监控生成过程,可实现中断生成(Interrupt Generation )操作,还能处理文本转语音工具包(Text - to - Speech Toolkit )相关功能;
-
交互机制:
- 聚合(Aggregation):VITA (Monitoring) 与 VITA (Generation) 之间存在信息聚合,用于综合处理和反馈;
- 中断(Interruption):VITA (Monitoring) 可根据环境音频等信息触发中断,调整 VITA (Generation) 的生成过程,实现更智能的交互。
5.8 NExT-GPT
-
NExT - GPT,一个支持多模态输入输出的大语言模型;
-
模型架构:
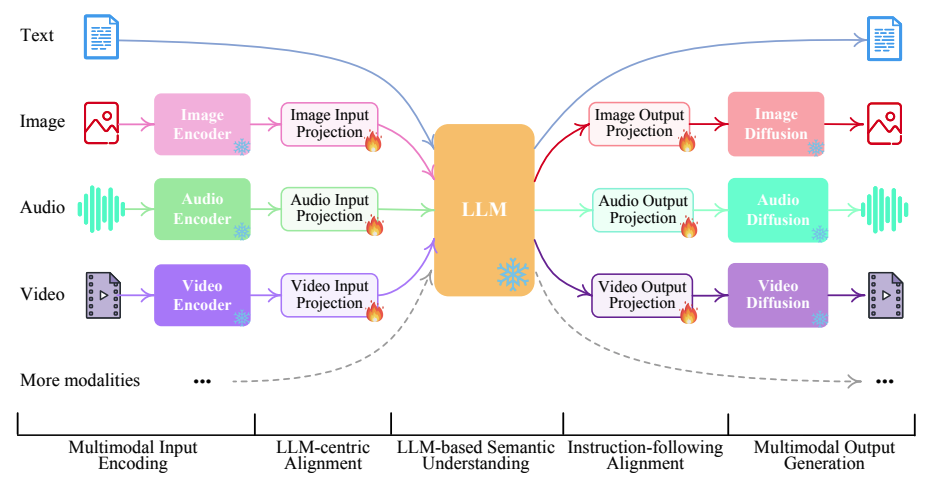
- 输入:文本、图像、音频、视频等多模态数据分别经对应的编码器(Text Encoder、Image Encoder、Audio Encoder、Video Encoder )处理,再通过输入投影层(Input Projection )将特征映射到合适空间,输入到大语言模型(LLM );
- 核心处理:LLM 对多模态特征进行理解和处理;
- 输出:处理后的信息经输出投影层(Output Projection ),再通过扩散模型(Diffusion ,如图像的 Stable Diffusion、音频的 AudioLDM、视频的 Zeroscope )生成对应模态输出;
-
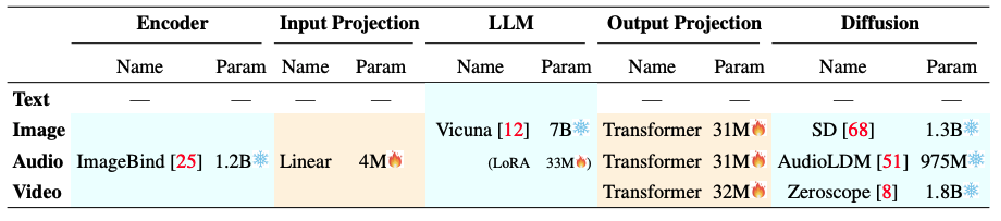
网络结构配置:
- 明确各模态在 Encoder、Input Projection、LLM、Output Projection、Diffusion 环节使用的模型及参数量;
- 如音频 Encoder 用 ImageBind(1.2B 参数 ) ,LLM 基于 Vicuna(7B 参数 ,LoRA 33M 参数 )等;
-
三阶段训练过程:
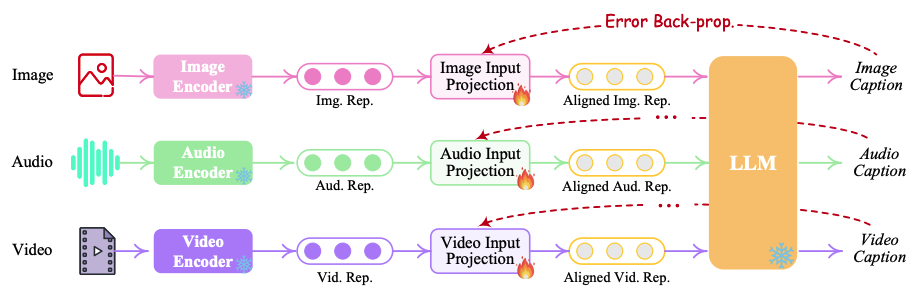
-
阶段一:以 LLM 为中心进行 Encoder 特征对齐,仅更新 input projection layer,让多模态编码器输出与 LLM 适配;
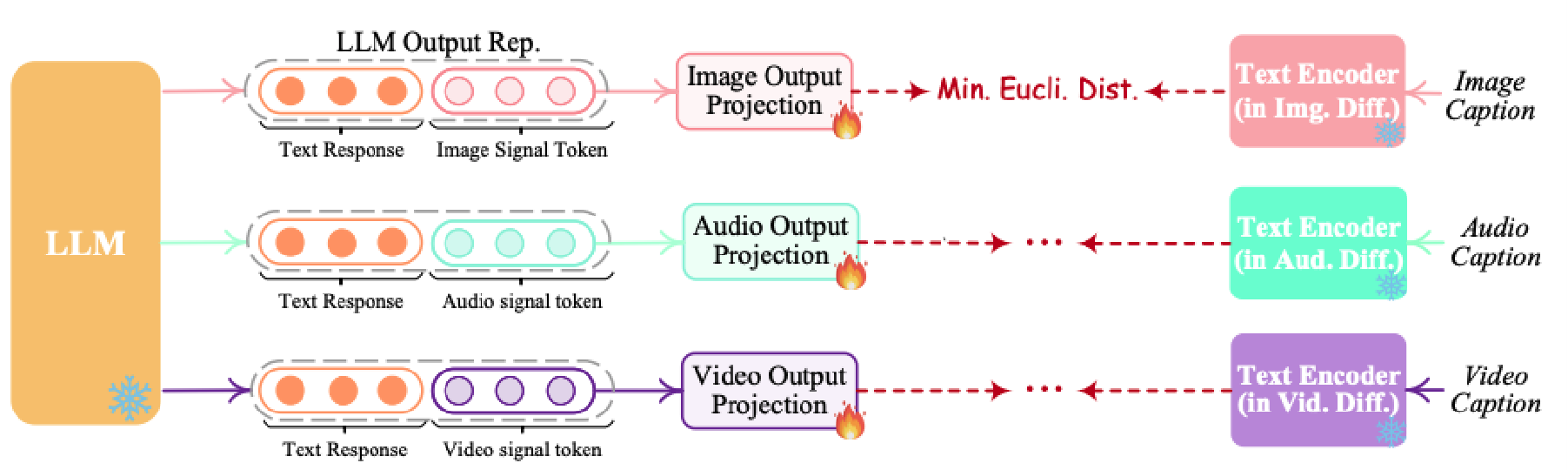
-
阶段二:使 Decoder 段输出结果与指令对齐,只更新 output projection layer,确保输出符合预期指令;
-
阶段三:进行指令微调,更新 LLM 的 LoRA 参数以及 input 和 output projection layers,提升模型对指令的执行能力。
-
5.9 AnyGPT
- AnyGPT,一个采用离散序列建模的统一多模态大语言模型;
AnyGPT
-
模型输入:语音、文本、图像、音乐等多模态数据,分别通过各自的 tokenizer(语音 tokenizer、文本本身、图像 tokenizer、音乐 tokenizer )转化为对应的 tokens 序列,如 Speech tokens、Text tokens、Image tokens、Music tokens ,并添加起始和结束标记(如、 等) ;
-
模型处理:将处理后的多模态 tokens 序列输入到 AnyGPT 模型中,模型对这些混合的多模态信息进行统一处理和建模;
-
模型输出:经 AnyGPT 处理后,输出同样是包含多模态信息的 tokens 序列,可再通过对应的 de - tokenizer(语音 de - tokenizer、图像 de - tokenizer、音乐 de - tokenizer )将其转化为人类可理解的语音、图像、音乐等输出形式。
5.10 VideoPoet
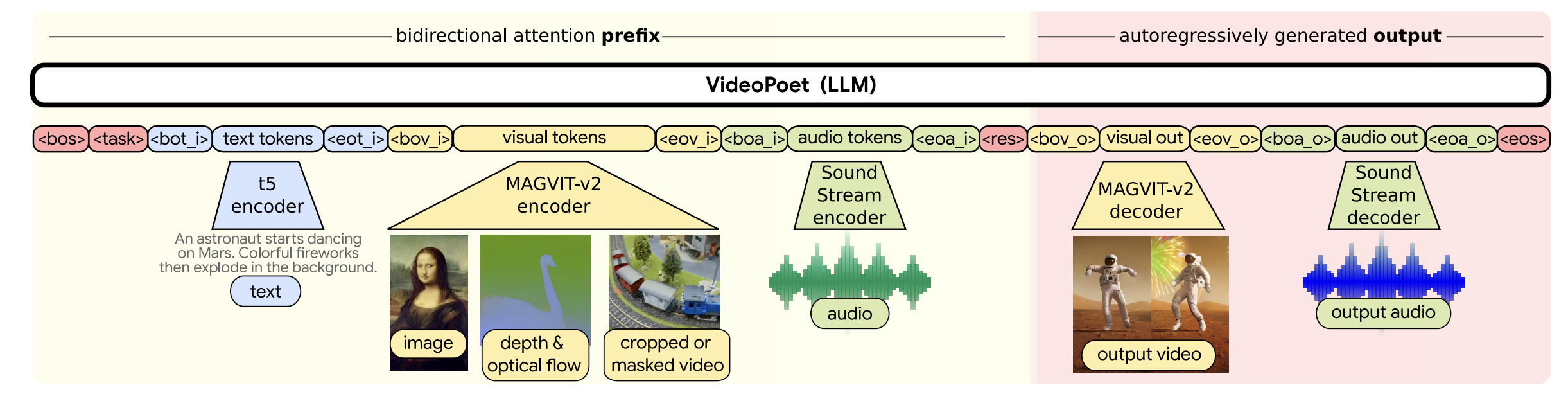
-
VideoPoet:一个用于零样本视频生成的大语言模型;
-
模型输入:
- 文本输入:通过 t5 encoder 将文本(如 “An astronaut starts dancing on Mars. Colorful fireworks then explode in the background.” )转化为 text tokens 。
- 视觉输入:图像、深度与光流信息、裁剪或掩蔽视频等,经 MAGVIT - v2 encoder 转化为 visual tokens 。
- 音频输入:音频数据由 Sound Stream encoder 处理成 audio tokens 。
-
模型核心:VideoPoet(LLM)利用双向注意力前缀(bidirectional attention prefix )处理输入的各类 tokens,再自回归生成输出(autoregressively generated output );
-
模型输出:通过 MAGVIT - v2 decoder 和 Sound Stream decoder,将处理后的信息转化为输出视频(output video )和输出音频(output audio ),实现零样本视频生成;
-
示例1:
VideoPoet示例1
- 示例2:
VideoPoet示例2
6 使用多模态大语言模型完成更多任务
6.1 Multimodal Agents
-
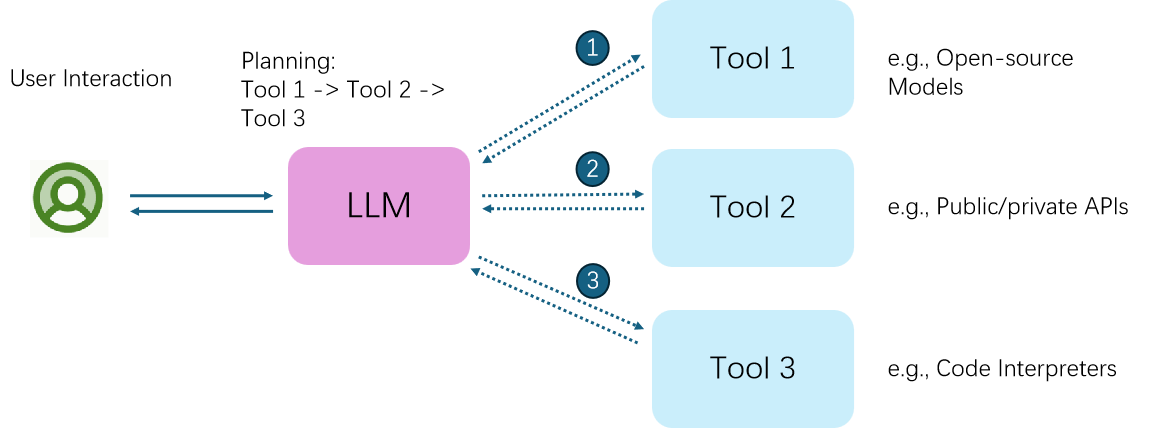
利用多模态大语言模型完成任务的 Multimodal Agents 模式;
-
交互流程
- 用户交互(User Interaction):用户与大语言模型(LLM)进行交互,提出任务需求;
- 规划阶段(Planning):LLM 根据用户需求,规划使用工具的顺序,如确定先使用 Tool 1,再使用 Tool 2,最后使用 Tool 3;
- 工具调用(Tool Invocation):LLM 依次调用不同工具,Tool 1 可以是开源模型,Tool 2 可以是公共或私有 API ,Tool 3 可以是代码解释器等 ,各工具执行相应任务并将结果反馈给 LLM;
-
实现原理:通过将多模态专家(不同功能的工具)与 LLM 链接,LLM 起到统筹规划和协调的作用,借助各类工具的能力,完成复杂的多模态任务,拓展大语言模型的应用范围和功能实现。
6.2 LLaVA - Plus
-
LLaVA - Plus:一种能即插即用并学习使用技能的大语言与视觉助手;
-
模型运行流程:
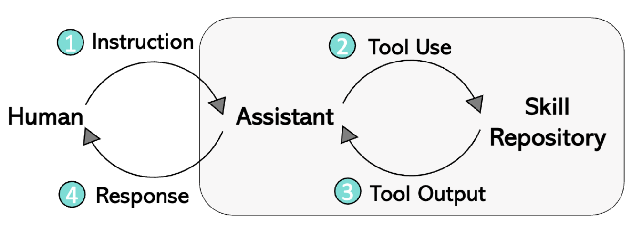
- 指令输入(Instruction):用户向助手(Assistant ,基于 LLM )提供任务文本指令及相关图片输入;
- 工具调用(Tool Use):LLM 分析指令和图像,判断是否需调用额外工具,若需调用,生成调用工具所需的 prompt,从技能库(Skill Repository )选取合适工具;
- 工具输出(Tool Output):运行所选工具,工具将输出结果返回给 LLM;
- 结果回复(Response):LLM 汇总工具输出结果,结合用户最初的文本指令和图片输入,生成最终回复反馈给用户;
-
创新点:通过这种四步流程,LLaVA - Plus 实现了结合视觉信息和文本指令,利用外部工具拓展功能,提升在多模态任务处理上的灵活性和能力。
-
LLaVA - Plus 在视觉任务上的应用能力:
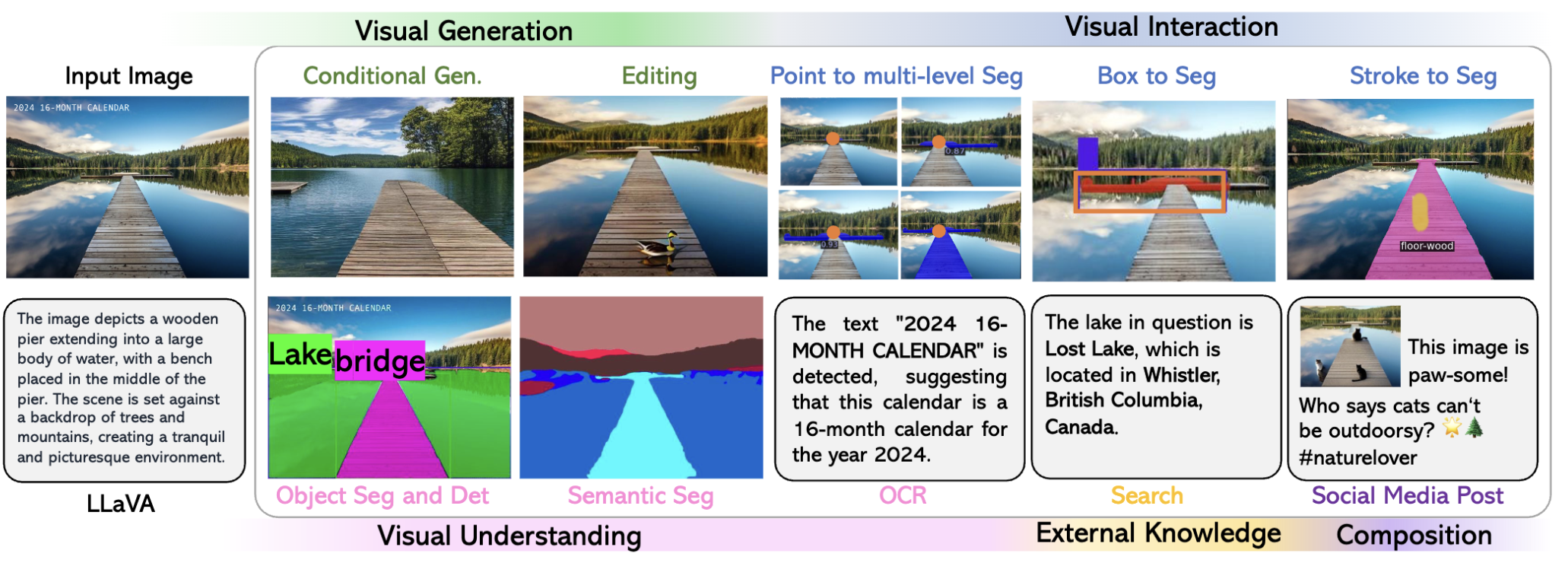
- 视觉生成(Visual Generation):包括条件生成(Conditional Gen.)和编辑(Editing),可基于输入图像生成新视觉内容或对图像进行编辑修改;
- 视觉交互(Visual Interaction):如 Point to multi - level Seg(点选实现多级分割)、Box to Seg(框选分割)、Stroke to Seg(笔触分割) ,实现人机视觉交互操作;
- 视觉理解(Visual Understanding):涵盖目标分割与检测(Object Seg and Det)、语义分割(Semantic Seg) ,帮助模型理解图像语义;
- 外部知识与创作(External Knowledge & Composition):通过 OCR(光学字符识别)获取文本信息,利用外部知识(如搜索得知湖泊位置),还能进行社交媒体文案创作;
-
LLaVA - Plus 的训练样本及处理流程:

- 用户提问:用户要求分割图像中的女孩和手推车并描述关系,图像来自 COCO 数据集;
- 助手思考与行动:助手(基于 LLaVA - Plus )思考后决定调用 grounding_dino 和 SAM 模型,使用特定 API 参数执行工具;
- 工具执行结果:grounding_dino + sam 模型输出女孩和手推车的边界框坐标等信息;
- 助手回复:助手依据工具输出结果,详细描述女孩和手推车在图像中的位置及互动关系,完成任务回复。 训练样本通过规范 “Thought(思考)”“Action(行动)”“Value(价值 / 结果)” 流程,提升模型任务处理能力。
6.3 多模态Agent模型 CogAgent
-
模型能力:
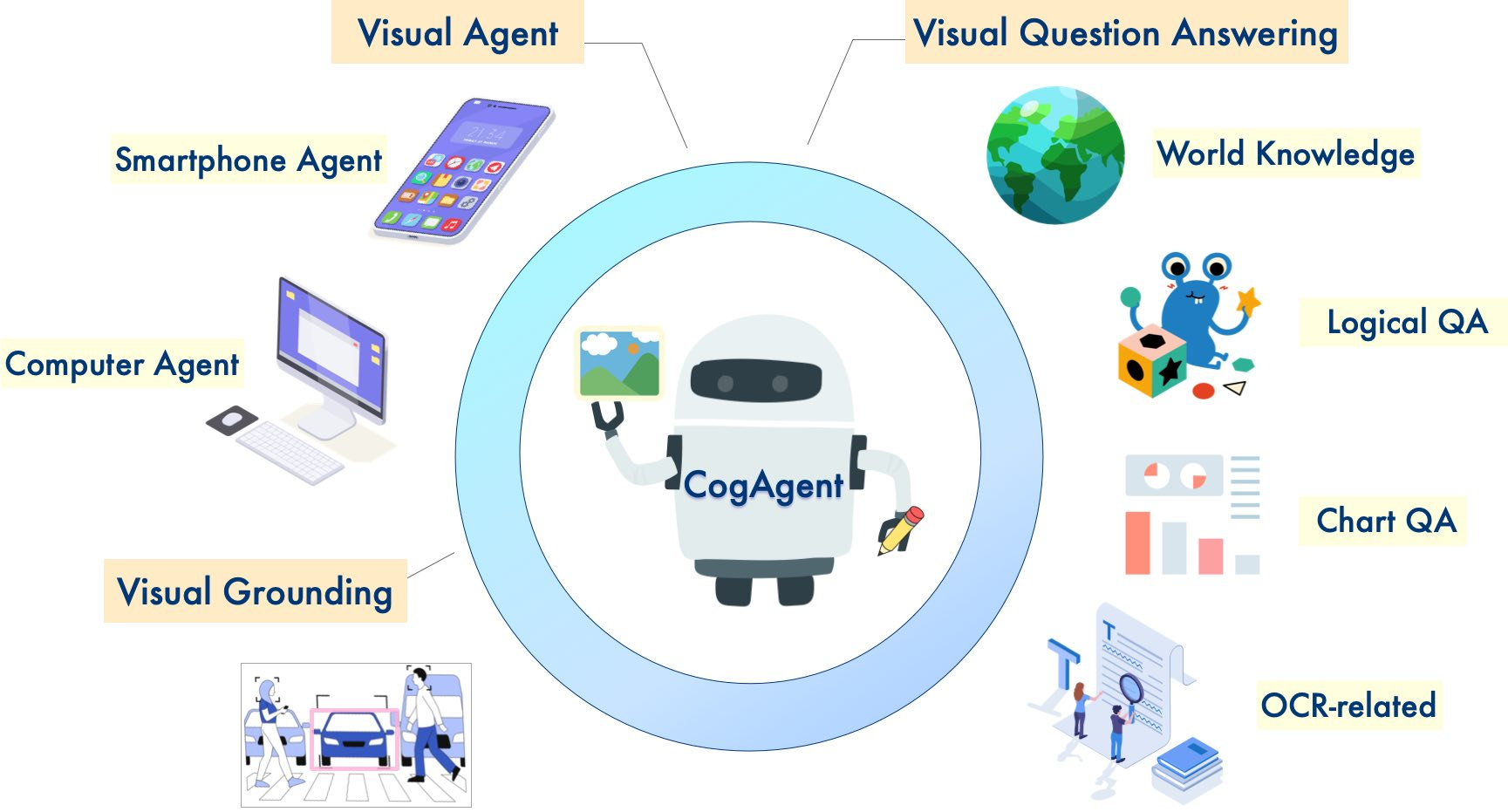
- 多模态交互:具备 Visual Agent(视觉代理) 、Smartphone Agent(智能手机代理)、Computer Agent(计算机代理)等多种代理功能,可进行视觉问答(Visual Question Answering )、视觉定位(Visual Grounding )等任务,还涉及世界知识、逻辑问答(Logical QA)、图表问答(Chart QA) 、OCR 相关任务;
- 图像输入:支持高分辨率图像输入(1120x1120 ) ,能处理更清晰丰富的视觉信息;
- GUI 能力:强化 Visual Agent 在计划(Plan)和下一步行动(next action)方面的能力,提升对 GUI 内容的解析和目标定位能力;
-
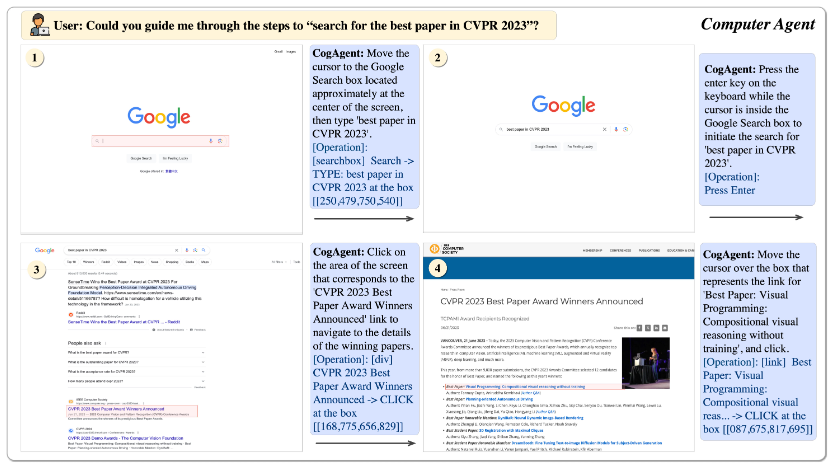
示例1:针对 “Could you guide me through the steps to ‘search for the best paper in CVPR 2023’?” ,CogAgent 引导在谷歌搜索相关论文步骤;
-
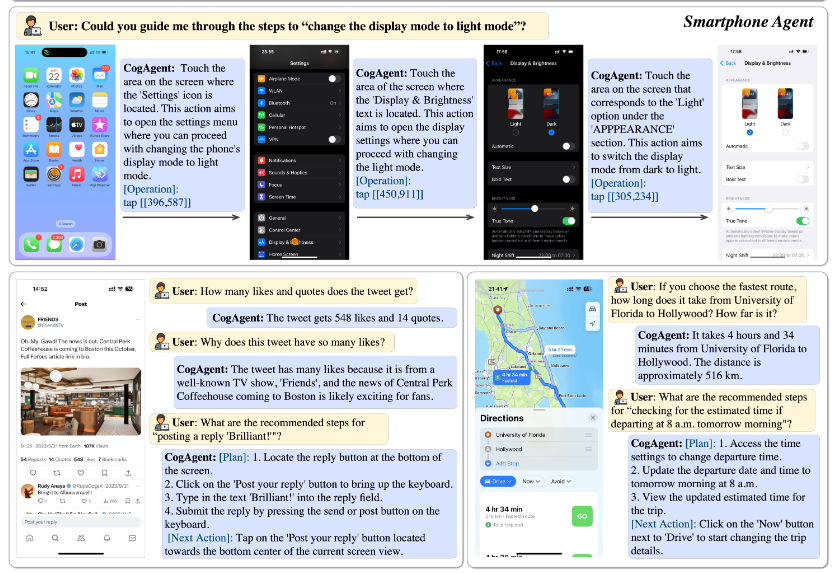
示例2:对于 “Could you guide me through the steps to ‘change the display mode to light mode’?” ,CogAgent 指导在手机和电脑上切换显示模式为亮色模式的操作;
6.4 多模态学习一般范式
-
以视觉、文本、音频三种模态为例:
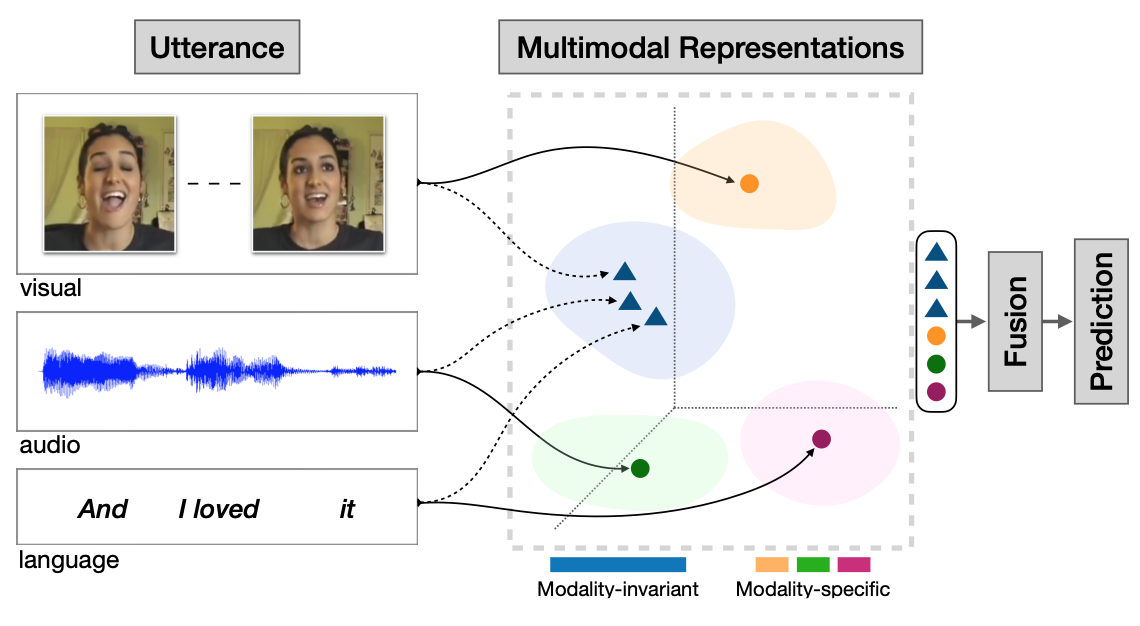
- 输入阶段:视觉(如人物表情图像)、音频(语音波形)、语言(文本语句 “And I loved it” )作为输入;
- 表征阶段:
- 不同模态数据分别生成模态特异性(Modality - specific)和模态不变性(Modality - invariant)表征;
- 模态特异性表征体现各模态独特信息,模态不变性表征提取跨模态共性信息;
- 融合与预测阶段:将不同模态表征融合,基于融合结果进行预测,得到最终输出。
6.5 多模态大语言模型学习一般范式
-
以视觉、文本、音频三种模态为例:
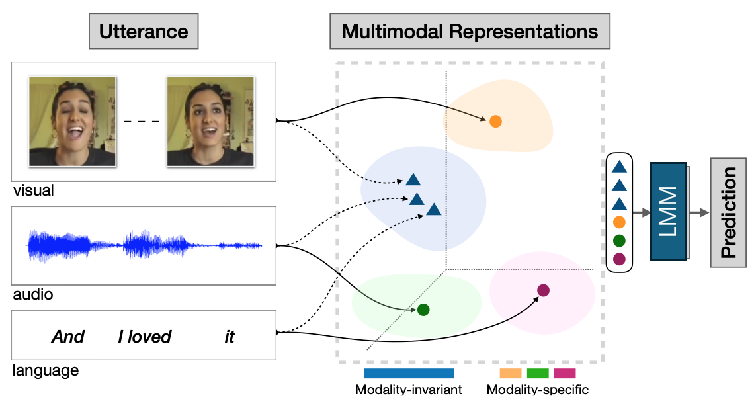
- 输入与表征:与多模态学习一般范式类似,视觉、音频、语言模态数据输入后生成相应表征;
- 核心处理:引入大语言模型(LMM),将融合后的多模态表征输入大语言模型,利用其强大语言理解和生成能力,对多模态信息综合处理;
- 预测输出:大语言模型处理后输出预测结果。相比一般多模态学习,多模态大语言模型借助大语言模型优势,增强对多模态语义理解和生成能力。
6.6 多模态学习与多模态大语言模型的核心
-
多模态学习的核心:特征对齐
-
定义:多模态学习涉及处理不同类型的数据(如文本、图像、音频等),其核心挑战是将不同模态的数据映射到一个统一的特征空间,使它们能够相互关联和补充;
-
关键点:
- 特征对齐:通过模型学习将不同模态的数据(如“猫”的文本描述和猫的图片)在特征空间中对齐,使它们在语义上保持一致;
- 对齐方式:可以是显式的(如对比学习)或隐式的(通过多任务学习);
-
多模态大语言模型(LMM)的本质:All-to-One范式
- 定义:多模态大语言模型(如GPT-4V)以语言模型为核心,将其他模态(如图像、音频)的特征对齐到文本模态的语义空间;
- All-to-One:
- 输入:多种模态数据(如图像+文本、音频+文本)被统一编码为语言模型可理解的表示;
- 输出:以文本形式生成响应或推理结果(如描述图像内容、回答跨模态问题);
- 优势:
- 语言模型的强大生成能力成为多模态任务的“通用接口”;
- 简化了多模态交互的复杂性(如GPT-4V可直接理解图像并生成文本回答);
-
多模态大模型的发展现状
-
快速发展:
- 技术迭代速度极快,开源模型(如LLaVA、MiniGPT-4)与GPT-4V的差距小于纯文本模型中LLaMA与GPT-4的差距;
- 原因:多模态数据(如图文对)的丰富性促进了模型对齐能力的快速提升;
-
技术领先应用:
- 当前技术能力已超越实际落地场景,存在“想象空间”:
- 潜在应用:教育(多模态交互辅导)、医疗(影像报告生成)、机器人(视觉-语言-动作闭环)等;
- 挑战:如何将技术转化为可靠、安全的实际产品;
- 当前技术能力已超越实际落地场景,存在“想象空间”:
-
-
多模态大模型最全收录:BradyFU/Awesome-Multimodal-Large-Language-Models: ✨✨Latest Advances on Multimodal Large Language Models;
- 包括多模态指令微调、多模态上下文学习、多模态Agent、多模态数据集等各类信息;
-
多模态大模型榜单:BradyFU/Awesome-Multimodal-Large-Language-Models at Evaluation。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











