




7 RAG(知识库 ChatPDF)
-
由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题:
- 知识数据比较落后,往往是几个月之前的;
- 不包含太过专业领域或者企业私有的数据;
-
为了解决这些问题,就需要用到RAG了。
7.1 RAG原理
- 要解决大模型的知识限制问题,其实并不复杂;
- 解决的思路就是给大模型外挂一个知识库,可以是专业领域知识,也可以是企业私有的数据;
- 不过,知识库不能简单的直接拼接在提示词中;
- 因为通常知识库数据量都是非常大的,而大模型的上下文是有大小限制的,早期的GPT上下文不能超过2000token,现在也不到200k token,因此知识库不能直接写在提示词中;
- 怎么办?
- 思路很简单,庞大的知识库中与用户问题相关的其实并不多;
- 所以,只要想办法从庞大的知识库中找到与用户问题相关的一小部分,组装成提示词,发送给大模型就可以了;
- 那么问题来了,该如何从知识库中找到与用户问题相关的内容呢?
- 全文检索?但是在这里是不合适的,因为全文检索是文字匹配,而这里要求的是内容上的相似度;
- 而要从内容相似度来判断,这就不得不提到向量模型的知识了。
7.1.1 向量模型
-
向量是空间中有方向和长度的量,空间可以是二维,也可以是多维;
-
向量既然是在空间中,那么两个向量之间就一定能计算距离;
-
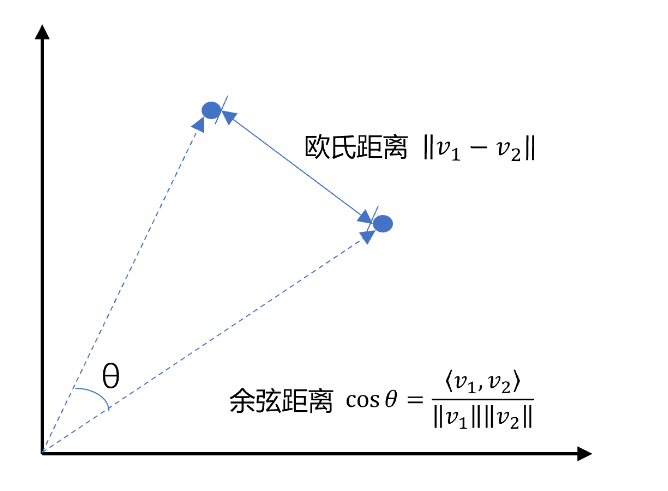
以二维向量为例,向量之间的距离有两种计算方法:
-
通常,两个向量之间欧式距离越近,就认为两个向量的相似度越高(余弦距离相反,越大相似度越高);
-
所以,如果能把文本转为向量,就可以通过向量距离来判断文本的相似度了;
-
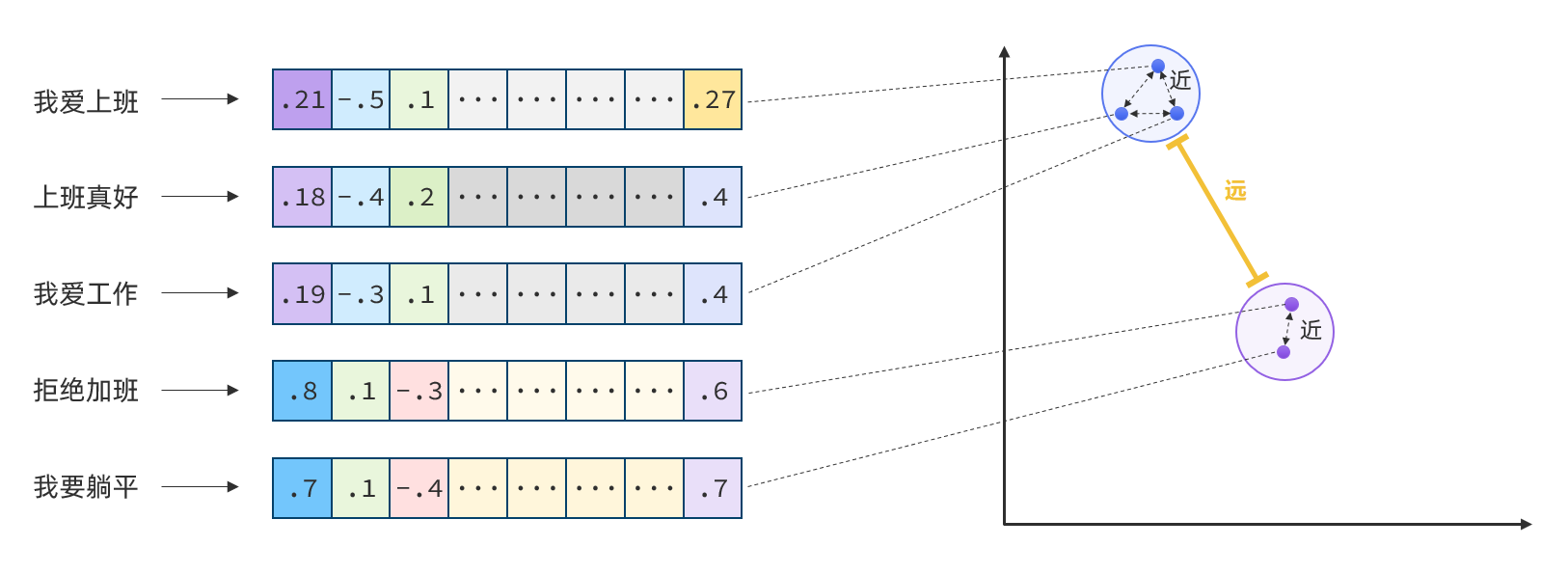
现在有不少的专门的向量模型,就可以实现将文本向量化。一个好的向量模型,就是要尽可能让文本含义相似的向量,在空间中距离更近:
-
阿里云百炼平台就提供了这样的模型,用于将文本向量化:
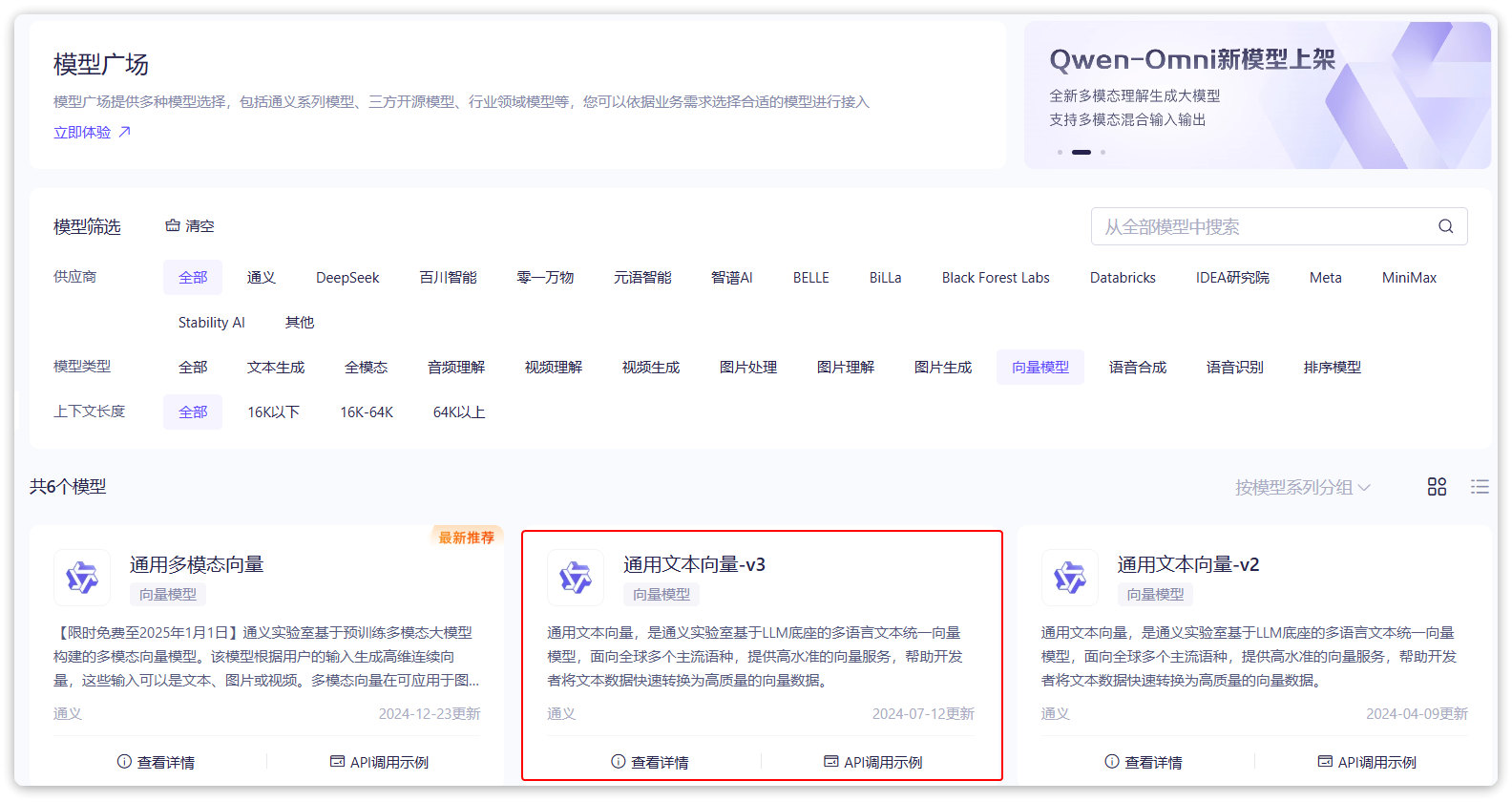
- 这里选择
通用文本向量-v3,这个模型兼容OpenAI,所以我们依然采用OpenAI的配置;
- 这里选择
-
修改
application.yaml,添加向量模型配置:spring: application: name: chart-robot ai: ollama: # Ollama服务地址 base-url: http://localhost:11434 chat: # 模型名称,可更改 model: deepseek-r1:14b options: # 模型温度,值越大,输出结果越随机 temperature: 0.8 openai: base-url: https://dashscope.aliyuncs.com/compatible-mode api-key: ${ OPENAI_API_KEY} chat: options: # 可选择的模型列表 https://help.aliyun.com/zh/model-studio/getting-started/models model: qwen-max-latest embedding: options: model: text-embedding-v3 dimensions: 1024
7.1.2 向量模型测试
-
前面说过,文本向量化以后,可以通过向量之间的距离来判断文本相似度;
-
接下来,就来测试下阿里百炼提供的向量大模型;
-
在项目中写一个工具类,用以计算向量之间的欧氏距离和**余弦距离。**新建一个
com.shisan.ai.util包,在其中新建一个VectorDistanceUtils类:package com.shisan.ai.util; public class VectorDistanceUtils { // 防止实例化 private VectorDistanceUtils() { } // 浮点数计算精度阈值 private static final double EPSILON = 1e-12; /** * 计算欧氏距离 * @param vectorA 向量A(非空且与B等长) * @param vectorB 向量B(非空且与A等长) * @return 欧氏距离 * @throws IllegalArgumentException 参数不合法时抛出 */ public static double euclideanDistance(float[] vectorA, float[] vectorB) { validateVectors(vectorA, vectorB); double sum = 0.0; for (int i = 0; i < vectorA.length; i++) { double diff = vectorA[i] - vectorB[i]; sum += diff * diff; } return Math.sqrt(sum); } /** * 计算余弦距离 * @param vectorA 向量A(非空且与B等长) * @param vectorB 向量B(非空且与A等长) * @return 余弦距离,范围[0, 2] * @throws IllegalArgumentException 参数不合法或零向量时抛出 */ public static double cosineDistance(float[] vectorA, float[] vectorB) { validateVectors(vectorA, vectorB); double dotProduct = 0.0; double normA = 0.0; double normB = 0.0; for (int i = 0; i < vectorA.length; i++) { dotProduct += vectorA[i] * vectorB[i]; normA += vectorA[i] * vectorA[i]; normB += vectorB[i] * vectorB[i]; } normA = Math.sqrt(normA); normB = Math.sqrt(normB); // 处理零向量情况 if (normA < EPSILON || normB < EPSILON) { throw new IllegalArgumentException("Vectors cannot be zero vectors"); } // 处理浮点误差,确保结果在[-1,1]范围内 double similarity = dotProduct / (normA * normB); similarity = Math.max(Math.min(similarity, 1.0), -1.0); return similarity; } // 参数校验统一方法 private static void validateVectors(float[] a, float[] b) { if (a == null || b == null) { throw new IllegalArgumentException("Vectors cannot be null"); } if (a.length != b.length) { throw new IllegalArgumentException("Vectors must have same dimension"); } if (a.length == 0) { throw new IllegalArgumentException("Vectors cannot be empty"); } } }- 由于SpringBoot的自动装配能力,刚才配置的向量模型可以直接使用;
-
编写测试类:
package com.shisan.ai; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; import com.shisan.ai.util.VectorDistanceUtils; import org.springframework.ai.openai.OpenAiEmbeddingModel; import org.springframework.beans.factory.annotation.Autowired; import java.util.Arrays; import java.util.List; @SpringBootTest class ChatRobotApplicationTests { // 自动注入向量模型 @Autowired private OpenAiEmbeddingModel embeddingModel; @Test public void testEmbedding() { // 1.测试数据 // 1.1.用来查询的文本,国际冲突 String query = "global conflicts"; // 1.2.用来做比较的文本 String[] texts = new String[]{ "哈马斯称加沙下阶段停火谈判仍在进行 以方尚未做出承诺", "土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判", "日本航空基地水井中检测出有机氟化物超标", "国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营", "我国首次在空间站开展舱外辐射生物学暴露实验", }; // 2.向量化 // 2.1.先将查询文本向量化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2139
2139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











