




多线程threading介绍
Python内置线程库 threading 基于 thread (是底层的模块) 实现. threading 对Thread做了一些封装.
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
- 程序的运行速度可能加快
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
Python的多线程也有一些不足(算不上缺点), Python多线程不能利用CPU多核, 一直是一个问题. 二者有和Python的GIL(Global interpreter Lock)全局解释器锁有关了, 详细可见 https://mp.youkuaiyun.com/postedit/84330341
线程在执行过程中与进程还是有区别的。每个独立的进程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断)。
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) -- 这就是线程的退让。
线程模块:
threading模块提供的方法:
threading.currentThread() # 返回当前线程变量
thrading.enumerate() # 返回一个包含正在运行的线程的列表 ( list ),不包括未启动线程和已结束线程
threading.activeCount() # 返回正在运行的线程数量, 与 len(threading.enumerate())效果等同
Thread类:
run() # 表示线程活动的方法
start() # 启动线程
join(t[]imeout]) # 等待至线程结束,或者阻塞调用线程直至join被调用,或者<timeout=sec>超时条件 被触发
isAlive() # 判断线程是否活动,返回True 或 False
getName() # 返回 线程名
setName() # 设置线程名
daemon() #设置守护线程,参数为 True 或 False.
单线程执行:
# coding:utf-8
import time
def sayhello():
time.sleep(1)
print("Hello")
if __name__ == "__main__":
start_time = time.time() # 获取程序开始时当前的啥时间戳
for i in range(5): # 利用循环开启 5个 线程
sayhello()
end_time = time.time() # 获取程序运行到此时的时间戳
cost_time = end_time - start_time # 时间单位为 秒
print("花费时间:{}".format(cost_time))执行结果:
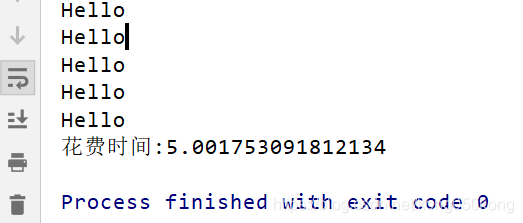
多线程执行:
# coding:utf-8
import threading
import time
def sayhello():
time.sleep(1)
print("Hello")
if __name__ == "__main__":
# 获取程序开始时当前的啥时间戳
start_time = time.time()
# 利用循环开启 5个 线程
for i in range(5):
t = threading.Thread(target=sayhello)
t.start()
t.join() # 等待线程结束
end_time = time.time() # 获取程序运行到此时的时间戳
cost_time = end_time - start_time # 时间单位为 秒
print("花费时间:{}".format(cost_time))执行结果:
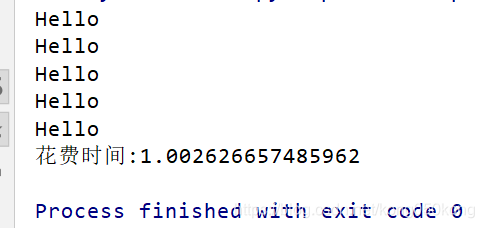
结论: 相比于单线程多线程的程序效率要高得多

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









