




 本文介绍了一个基于TensorFlow的手写数字识别模型。通过使用MNIST数据集进行训练,采用梯度下降法优化交叉熵损失函数,实现了多分类任务。最终模型在测试集上达到了较高的准确率。
本文介绍了一个基于TensorFlow的手写数字识别模型。通过使用MNIST数据集进行训练,采用梯度下降法优化交叉熵损失函数,实现了多分类任务。最终模型在测试集上达到了较高的准确率。
import tensorflow as tf
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True) # one_hot是一种编码方式,在MNIST中,标签为2的编码为00000010
# Parameters
learning_rate = 0.01
training_epochs = 25
batch_size = 100
display_step = 1
# tf Graph Input
x = tf.placeholder(tf.float32, [None, 784]) # mnist data image of shape 28*28=784
y = tf.placeholder(tf.float32, [None, 10]) # 0-9 digits recognition => 10 classes
# Set model weights
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# Construct model
pred = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax 多分类器
# Minimize error using cross entropy
cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), axis=1))
# Gradient Descent
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={x: batch_xs,
y: batch_ys})
# Compute average loss
avg_cost += c / total_batch
# Display logs per epoch step
if (epoch+1) % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
print("Optimization Finished!")
# Test model
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))tf.nn.softmax(
logits,
axis=None,
name=None,
dim=None #弃用参数
) softmax = tf.exp(logits) / tf.reduce_sum(tf.exp(logits), axis)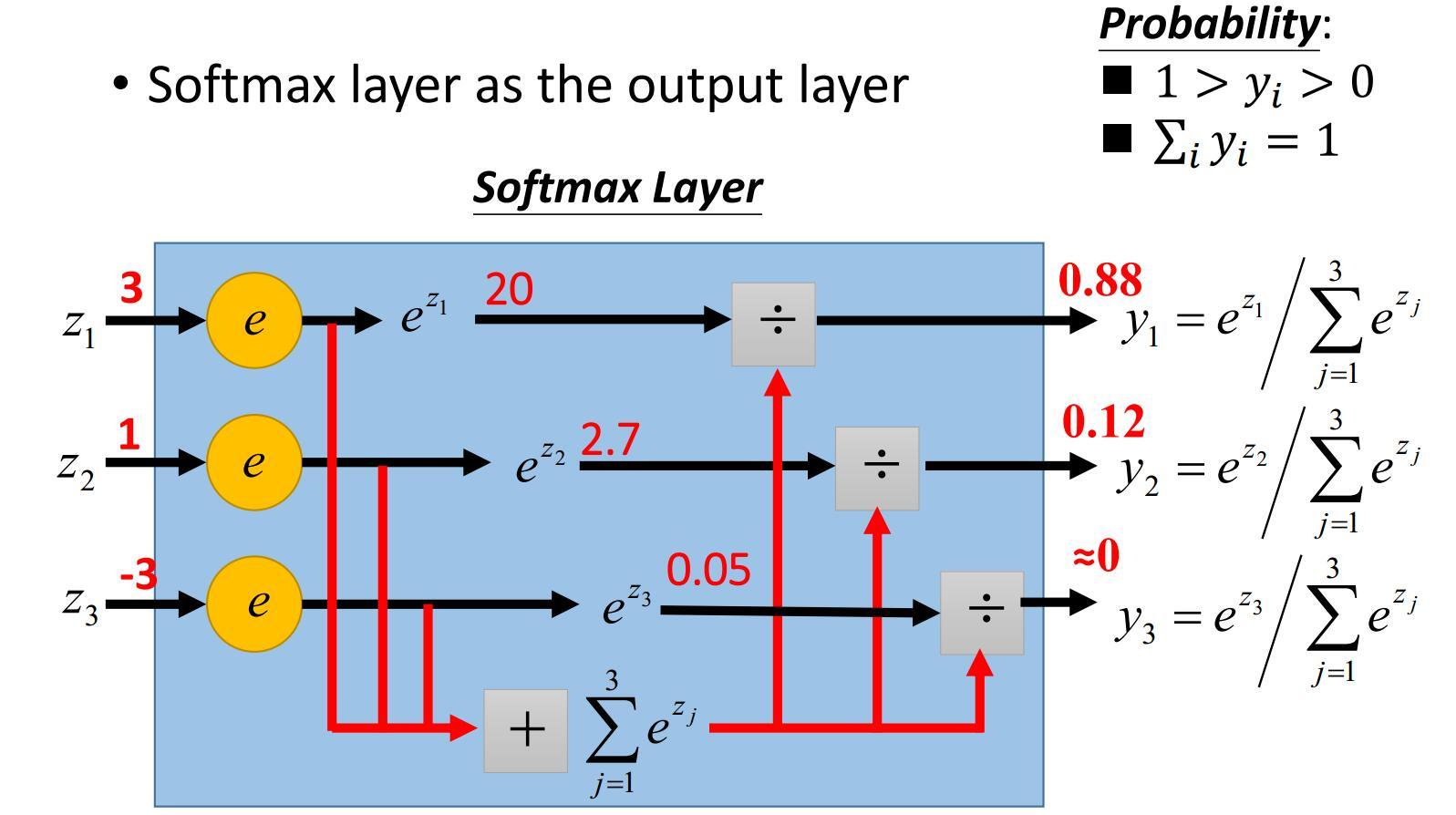
上图来自李宏毅的《一天读懂深度学习》,很好地解释了softmax如何实现多分类任务
交叉熵(cross entropy loss)公式:H(p,q)=−∑i=1np(xi)logq(xi),p, q即为实际值和预测值H(p,q)=−∑i=1np(xi)logq(xi)
tf.reduce_mean求均值,用法和tf.reduce_sum类似
tf.argmax(
input,
axis=None,
name=None,
dimension=None,
output_type=tf.int64
)# 找到沿axis轴的最大的那个数的下标并返回tf.equal(
x,
y,
name=None
)# 比较x和y的所有元素,x和y具有相同的shape,函数返回该shape的bool tensor,x和y对应位置上的元素若相等,则返回值该位置上为True,否则为Falsetf.cast(
x,
dtype,
name=None
)# 类型转换,在此做bool类型转换,转换为数值后,求均值即为准确率eval(
feed_dict=None,
session=None
)# tensor的成员函数,调用此函数会执行该tensor包含的所有图计算和操作,前提是此前必须有Session
















 1263
1263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









