







文章目录
前言
上一篇文章介绍了如何启动和关闭多进程,其中使用了 multiprocessing的event来传递关闭信号,我们今天继续使用举例的方式,介绍它的使用。没有看过上一篇文章的朋友请查看上一篇文章。
看langchain代码之前必备知识之 - Python 多进程: multiprocessing (2)
我们这篇文章的代码是基于上一篇文章来修改的
一、使用multiprocessing的event实现进程的有序启动
在实际的程序里,我们通常需要控制程序的启动顺序,例如langchain-chatchat里是先启动模型,再启动api,然后再启动web-ui的,这样可以保证我们看到web界面后能直接使用,而不会出现模型还没准备好等等之类的影响使用体验的
二、实现步骤
1.修改task,添加start_event参数
代码如下:
def task(name, start_need_time, start_event: mp.Event = None, stop_event: mp.Event = None):
print(name + ' 正在启动, 启动需要' + str(start_need_time) + '秒')
sleep(start_need_time)
print(name + ' 启动完成')
start_event.set()
while not stop_event.is_set():
current_time = str(time.strftime('%H:%M:%S', time.localtime()))
print(name + ' running ' + current_time)
sleep(2)
print(name + ' end')
2.修改启动程序
给每一个job生成一个 start event ,传递到子进程里。
使用 job1_start_event.wait() 的方式阻塞程序,直到job启动完成。
代码如下:
if cmd == 'start':
stop_event.clear()
if 'Job1' not in process_list or process_list['Job1'].is_alive() is False:
job1_start_event = mp.Event()
process_list['Job1'] = Process(target=task, args=('Job1', 5, job1_start_event, stop_event))
process_list['Job1'].start()
job1_start_event.wait()
else:
print('任务已经在运行')
if 'Job2' not in process_list or process_list['Job2'].is_alive() is False:
job2_start_event = mp.Event()
process_list['Job2'] = Process(target=task, args=('Job2', 2, job2_start_event, stop_event))
process_list['Job2'].start()
job2_start_event.wait()
else:
print('任务已经在运行')
三、效果
1. 启动
python test5.py
2.浏览器访问
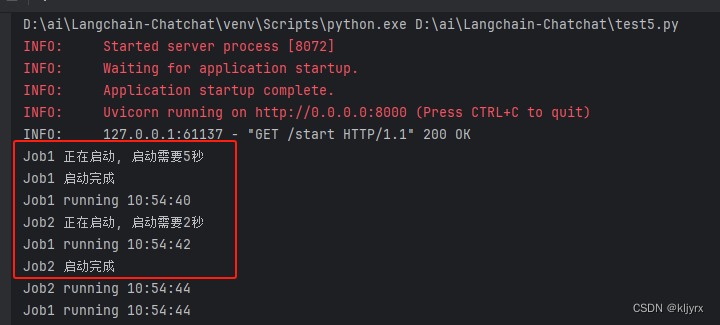
在浏览器里访问http://localhost:8000/start之后,可以看到虽然job1的启动时间比job2长,但是依然是job1先启动,然后再启动job2
四、对应langchain-chatchat的部分
大家看完本文,可以去翻看如下的代码
总结
1. multiprocessing.Event 的四个主要方法
下面是 multiprocessing.Event 的四个主要方法及其用法的总结:
- wait():
功能:阻塞当前进程,直到事件被设置。
用法:event.wait()
- set():
功能:设置事件,将事件的内部标志位设置为 True。
用法:event.set()
- clear():
功能:重置事件,将事件的内部标志位重置为 False。
用法:event.clear()
- is_set():
功能:返回事件的当前状态,如果事件被设置为 True,则返回 True,否则返回 False。
用法:event.is_set()
这些方法允许你在多进程之间进行同步,控制进程的执行顺序,以及共享状态。通过使用这些方法,你可以更加灵活地控制多进程程序的行为,实现更复杂的并发逻辑。
2. 代码分享
由此,我们就实现了进程的有序启动。代码如下,需要的朋友可以参考
import time
from multiprocessing import Process
from time import sleep
import multiprocessing as mp
import uvicorn
from fastapi import FastAPI
import asyncio
# 从队列中获取命令
def get_cmd(from_queue):
if not from_queue.empty():
return from_queue.get()
else:
return ""
# 执行任务的函数
def task(name, start_need_time, start_event: mp.Event = None, stop_event: mp.Event = None):
# 打印任务开始信息
print(name + ' 正在启动, 启动需要' + str(start_need_time) + '秒')
sleep(start_need_time)
# 打印任务完成信息
print(name + ' 启动完成')
# 设置启动事件
start_event.set()
while not stop_event.is_set():
# 打印任务运行信息
current_time = str(time.strftime('%H:%M:%S', time.localtime()))
print(name + ' running ' + current_time)
sleep(2)
# 打印任务结束信息
print(name + ' end')
# Web 服务
def web_service(task_queue):
app = FastAPI()
@app.get("/start")
async def start_task():
# 将 start 命令放入队列
task_queue.put('start')
return "start!"
@app.get("/stop")
async def stop_task():
# 将 stop 命令放入队列
task_queue.put('stop')
return "stop!"
# 运行 FastAPI 服务
uvicorn.run(app, host="0.0.0.0", port=8000)
# 任务管理器
async def task_manager(task_queue):
# 创建并启动 Web 服务进程
w = Process(target=web_service, args=(queue,))
w.start()
# 创建停止事件和进程列表
stop_event = mp.Event()
process_list = {}
while True:
# 获取命令
cmd = get_cmd(task_queue)
if cmd == 'start':
# 清除停止事件
stop_event.clear()
# 如果任务不存在或者任务已经停止,则启动任务
if 'Job1' not in process_list or process_list['Job1'].is_alive() is False:
job1_start_event = mp.Event()
process_list['Job1'] = Process(target=task, args=('Job1', 5, job1_start_event, stop_event))
process_list['Job1'].start()
job1_start_event.wait()
else:
print('任务已经在运行')
if 'Job2' not in process_list or process_list['Job2'].is_alive() is False:
job2_start_event = mp.Event()
process_list['Job2'] = Process(target=task, args=('Job2', 2, job2_start_event, stop_event))
process_list['Job2'].start()
job2_start_event.wait()
else:
print('任务已经在运行')
elif cmd == 'stop':
# 设置停止事件
stop_event.set()
# 给10秒的时间,如果还不停下来,那就强制停止子进程了
sleep(10)
process_list['Job1'].terminate()
process_list['Job2'].terminate()
process_list['Job1'].join()
process_list['Job2'].join()
stop_event.clear()
if __name__ == '__main__':
# 创建共享队列
manager = mp.Manager()
queue = manager.Queue()
# 运行任务管理器
loop = asyncio.get_event_loop()
loop.run_until_complete(task_manager(queue))

















 1994
1994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









