







1. 从C语言执行效率方面,简述C语言采取了哪些措施提高执行效率。
① 使⽤指针:有些程序⽤其他语言也可以实现,但C能够更有效地实现;有些程序⽆法⽤其它语言实现,如直接访问硬件,但C却可以。正因为指针可以拥有类似于汇编的寻址方式,所以可以使程序更高效。
② 使⽤宏函数:宏函数仅仅作为预先写好的代码嵌⼊到当前程序,不会产生函数调⽤,所以仅仅是占⽤了空间,而使程序可以高效运行。在频繁调⽤同⼀个宏函数的时候,该现象尤其突出。函数和宏函数的区别就在于,宏函数占用了大量的空间,而函数占用了时间。
宏函数的例⼦:
#include<stdio.h>
#define SWAP(a, b, t) { t=a; a=b; b=t; }
#define MAX(a, b) (a > b ? a : b)
/*
宏函数,要保证运算的完整性
宏函数,在一定程度上比普通函数效率高,普通函数会有入栈和出栈时间上的开销
通常将一些比较频繁、短小的函数封装为宏函数
优点:以空间换时间
宏函数会原样替换
*/
int main(){
int maxNum = MAX(5, 6);
printf("The max num is : %d\n", maxNum);
return 0;
}
③ 使⽤位操作:位操作可以减少除法和取模的运算。在计算机程序中数据的位是可以操作的最⼩数据单位,理论上可以用"位运算"来完成所有的运算和操作。灵活的位操作可以有效地提高程序运行的效率。
④ 长内短外嵌套循环:循环嵌套中将较长循环设为内置循环,较短循环设为外置循环,以减少CPU跨切循环层的次数,提高程序的运行效率。(操作系统页⾯置换相关,减少页⾯置换次数)
⑤ 使用汇编指令:将汇编指令嵌⼊到C语言程序中,汇编语言是效率最高的计算机语言,因此为了获得程序的高效率,可以在C语言程序中嵌⼊汇编,从而充分利⽤高级语言和汇编语言各⾃的特点。
⑥ 调用系统API :在C语言程序中可以调⽤系统API,接近底层,从而提高程序的运行效率。
⑦ 条件编译 :⼀般情况下,C语言源程序中的每⼀行代码都要参加编译。但有时候出于对程序代码优化的考虑,希望只对其中⼀部分内容进行编译。此时就需要在程序中加上条件,让编译器只对满足条件的代码进行编译,将不满足条件的代码舍弃,这就是条件编译。
⑧使用寄存器变量
⑨不检查数组下标
2. 请简述C语言的隐式类型转换发生的四种情况,并说明每种情况如何转换。
(注:这⾥⾯还有个⼩题,float如何四舍五⼊转化成int)
int floatToInt(float f){ int i = 0; if(f>0) //正数 i = (f*10 + 5)/10; else if(f<0) //负数 i = (f*10 - 5)/10; else i = 0; return i; }
- 低转高:算术运算式中,低类型能够转换为高类型。
- 右转左:赋值表达式中,右边表达式的值⾃动隐式转换为左边变量的类型,并赋值给它。
- 实转形:函数调⽤中参数传递时,系统隐式地将实参转换为形参的类型后,赋给形参。
- 调转返:函数有返回值时,系统将隐式地将返回表达式类型转换为返回值类型,赋给调⽤函数。
如:
注:void指针使用规范void add(int a, int b){ return a + b; //返回值类型为int,函数返回值被隐式转换为int }int *p_int; void *p_void; p_void = p_int; // 不能p_int = p_void; // 可以p_int = (int *)p_void;
3. 数组越界会产生什么后果?
- 越界访问有可能把数据放到已经存储了重要数据的内存单元,也就是改写了本来不许改写的数据
- 重则崩溃:如果这个数据是系统的重要内容,有可能导致系统运行紊乱甚⾄是崩溃。
- 轻则影响不大:当然如果这个数据并不重要,那么越界访问的后果就不明显或者是没有影响。避免的办法是对数组的下标严格检测,判断数组下标是否越界。
- ⽤指针访问数组时要注意判断指针的指向是否已超过数组下标的最⼤值。
4. 值传递和地址传递
- 值传递过程中,被调函数的形参作为被调函数的局部变量处理,即在内存的堆栈中开辟空间以存放由主调函数放进来的实参的值,从而成为了实参的⼀个拷贝。值传递的特点是被调函数对形参的任何操作都是作为局部变量进行,不会影响主调函数的实参变量的值。
- 而在地址传递过程中,被调函数的形参虽然也作为局部变量在堆栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址,即通过堆栈中存放的地址访问主调函数中的实参变量。正因为如此,被调函数对形参做的任何操作都影响了主调函数中的实参变量。
5. C语言中,常量存储在哪里?局部变量和全局变量、静态局部变量和静态全局变量存储在哪里?
| 变量类型 | 存储区域 |
|---|---|
| 常量 | 常量区 |
| 局部变量 | 栈区 |
| 全局变量 | 静态区(全局区)的常量区 |
| 静态局部变量 | 静态区(全局区) |
| 静态全局变量 | 静态区(全局区) |

栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。
堆,就是那些由
new分配的内存块,他们的释放编译器不去管,由应用程序控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。自由存储区,就是那些由
malloc分配的内存块,它和堆十分相似,不过它是用free来结束自己的生命。全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分,它们共同占用一块内存区。
常量存储区,这是一块比较特殊的存储区,它们存放的是常量,不允许被修改。
5.1 全局变量与静态全局变量的区别:
5.1.1 作用域
- 全部变量的作用域是整个源程序,当一个源程序由多个源文件组成时,非静态的全局变量在各个源文件中都是有效的。
- 而静态全局变量则限制了其作用域,即只在定义该变量的源文件内有效, 在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域局限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其它源文件中引起错误。
5.1.2 初始化
静态全局变量只初始化一次,防止在其它文件单元中被引用。
注: 静态局部变量与普通局部变量的区别——静态局部变量只被初始化一次,下一次依据上一次的结果值。
6. 代码的显式控制结构
-
代码
for (int i = 1; i < n; i++) S;是什么结构?该代码如何使用显式结构表示?
该代码是循环判断选择结构,其显式结构如下:int i = 1; FOR: if (i < n) goto S0; goto S1; //这里不用else S0: S; i = i + 1; goto FOR; //i的判断交给FOR S1: ... -
如下代码所示,E代表常量表达式,N代表常量,S代表执行语句。
switch(E){ case N1: S1; break; case N2: S2; break; default S3; }问:对应的显示控制结构是什么?请使用伪代码形式(通过跳转指令)表达。
答:t = E; m: if t == N1 goto m + 2 m + 1: goto n + 1 m + 2: ... S1对应的代码 n: goto S.next n + 1: if t == N2 goto n + 3 n + 2: goto k + 1 n + 3: ... S2对应的代码 k: goto S.next k + 1: ... S3对应的代码 S.next
7. C语言中,除了关键字,还有哪些单词类型(C的语法符号)?C的存储类型关键字有哪四个?
- 语法符号:运算符、标识符、常量、分隔符、关键字
- 存储类型关键字:
auto、extern、register、static

8. Union
- union中可以定义多个成员,union的大小由最大的成员的大小决定。
- union成员共享同一块大小的内存,一次只能使用其中的一个成员。
- 对某一个成员赋值,会覆盖其他成员的值。
- 对于
union里的struct,只有struct中的第一个成员的值能够决定覆盖其它成员的值;反过来说,其它成员变量的值不影响第一个变量的值。 - 对于
union里既有成员变量又有struct的情况,struct的第一个成员变量的值与union的其它成员变量值互相影响。

注: 这里注意一下
struct的内存对齐问题,参考文章《初学者对于结构体内存对齐与补齐的理解》
9. 利用快速排序找第 k 小元素
int find_k(int a[], int n, int k) {
int t = a[low];
int i = low;
int j = high;
k--; //数组下标从0开始,第k小即排序后数组中的第 k - 1 个元素
//一趟快速排序
while(low < high)
{
while(low < high && a[high] >= t)
--high;
a[low] = a[high];
while(low < high && a[low] <= t)
++low;
a[high] = a[low];
}
a[low] = t;
// 折半查找
if(low == k)
return a[low]);
else if(low > k)
return find_k(a, i, low - 1 ,k);
else
return find_k(a, low + 1, j, k - low);
}
10. 你是产品经理,如果你的产品马上要交付,你会怎么安排测试才能交付给用户使用?
交付测试的目标是保证用户对所交付的系统的满意。交付测试主要的参与者应该是目标客户。客户参与越多越好。交付测试的内容一般包括前面提到的安装测试、可用性测试、 alpha 测试、 beta 测试。
安装测试的主要任务是测试软件系统能否在模拟环境下或实际现场由目标用户顺利完成在目标机器上的安装;
可用性测试的主要任务是测试软件系统在完成安装以后能否完成用户的模拟任务或现场任务;
alpha 测试采用的形式一般是由一个用户在开发环境下对软件系统进行类似于黑盒的测试,测试的目的是从用户的角度评价软件产品的功能、可使用性、可靠性、性能和支持,尤其注重产品的界面和特色;
beta 测试采用的形式一般是先由软件的多个用户在实际使用环境下使用 beta 版软件系统一段时间,然后把使用中出现的各类故障或缺陷反馈给 beta 测试负责人员,再由测试负责人员移交给软件开发者,由开发人员负责修正并完善软件系统。 Beta 测试的目的是确保软件产品交付给全体用户之前能部分或全面地修正其在实际应用中可能出现的各类缺陷或不足。
11. 用C语言做网络编程,你将使用 http 还是 TCP/IP 协议来进行网络连接,为什么?
答:
- 选用TCP/IP协议。C语言可以做底层开发。TCP/IP协议是传输层协议,主要解决数据如何在网络中传输。
- 而HTTP是应用层协议 超文本传输协议,主要解决如何包装数据,多用于浏览器。
12. 如何不使用第三个变量,将两个变量的值进行交换?
采用位运算的异或
#include<stdio.h>
void main() {
int a = 2, b = 3;
a = a ^ b;
b = a ^ b;
a = a ^ b;
printf("a = %d, b = %d\n", a, b);
}
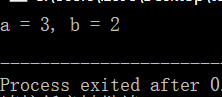
13. 堆排序:在1亿个数中选出前100个最大值
首先使用一个大小为100的数组,读入前100个数,建立小根堆。随后依次读入余下的数,若小于堆顶则舍弃,否则用该数取代堆顶并重新调整堆,待数据读取完毕,堆中剩余的100个数即为所求。
注:使用小顶堆的原因是,随着遍历的进行,依次替换掉堆中最小的元素。替换完毕,则留下较大者。而大顶堆的堆顶本身就是最大,在筛选过程中不可能比较出前100个最大值。


















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











