 MCP常见安全问题与测试项解析
MCP常见安全问题与测试项解析





目录
公众号来源:猕猴桃实验室 => 转载请注明“转载于公众号:猕猴桃实验室”

公众号:猕猴桃实验室
微信公众号:猕猴桃实验室
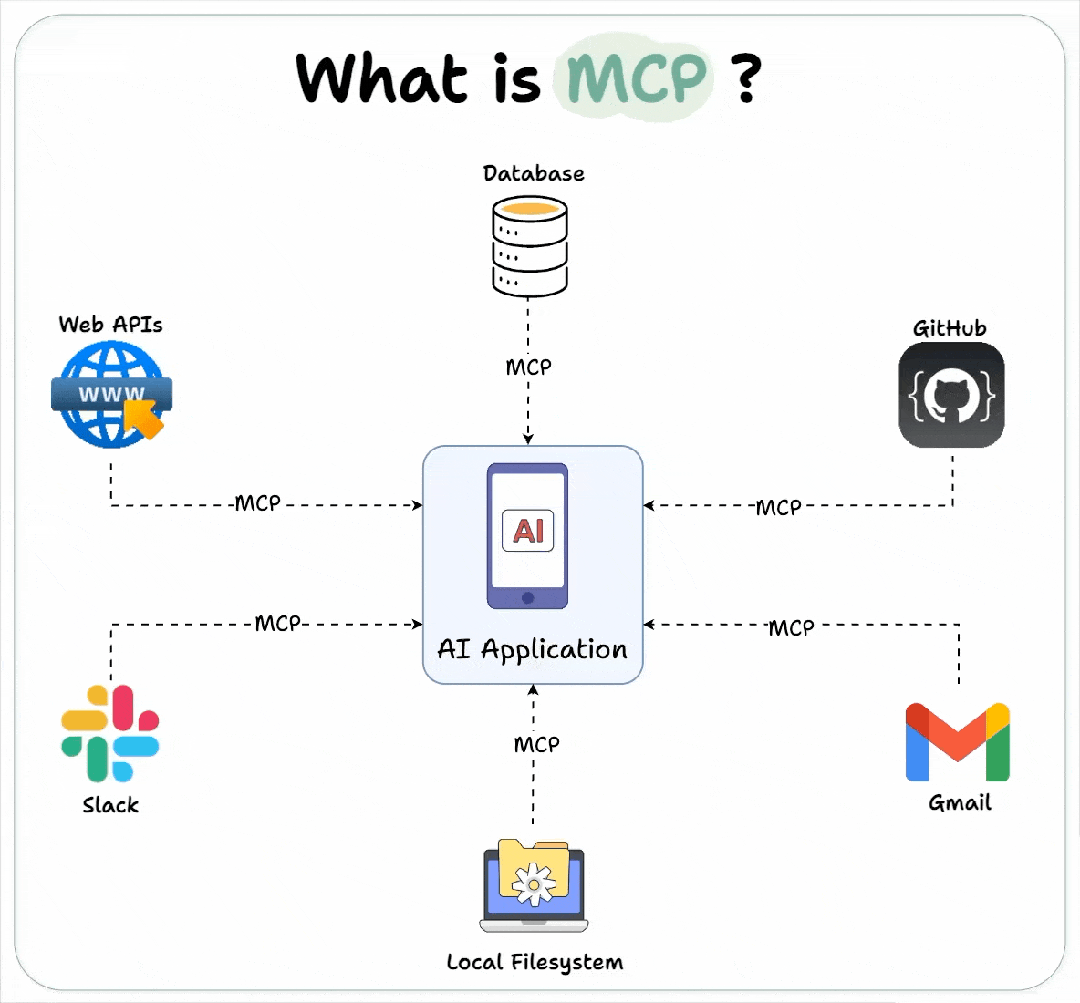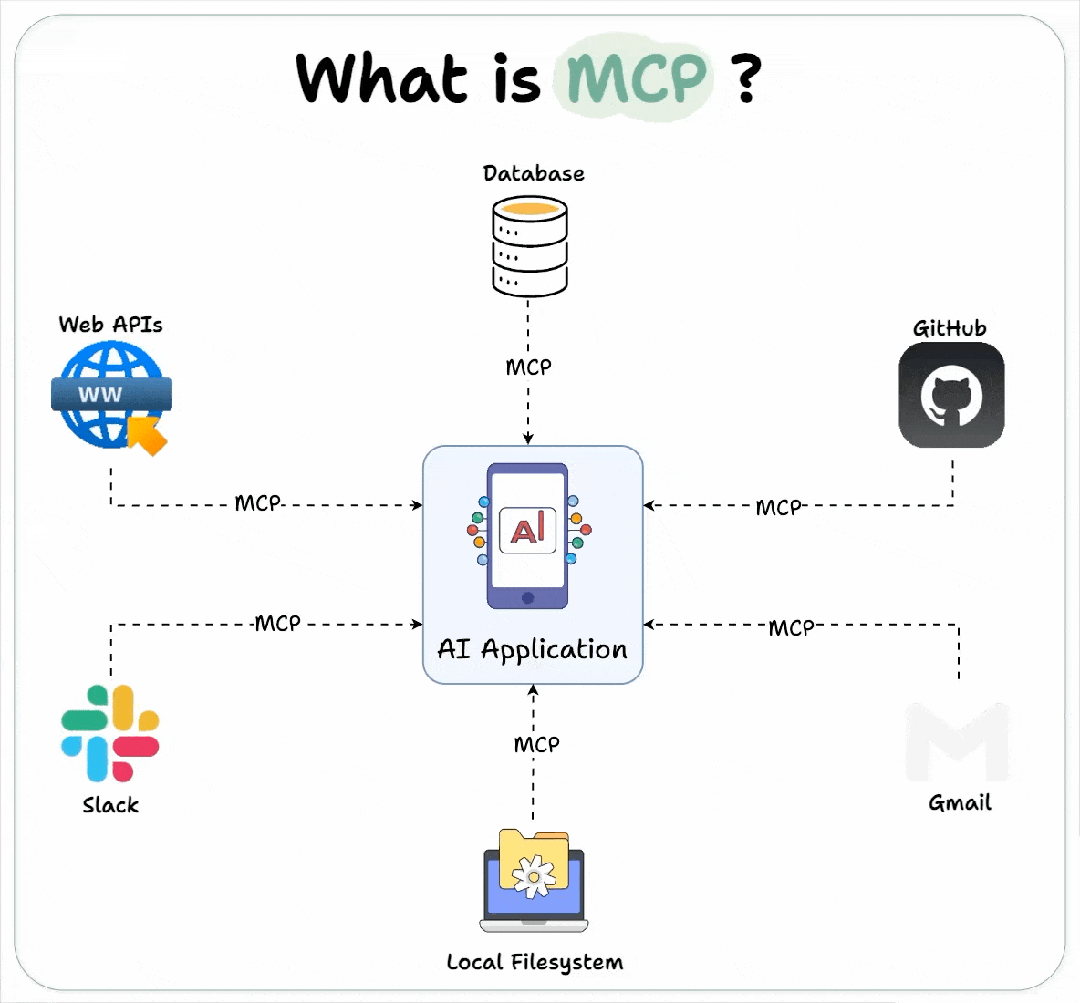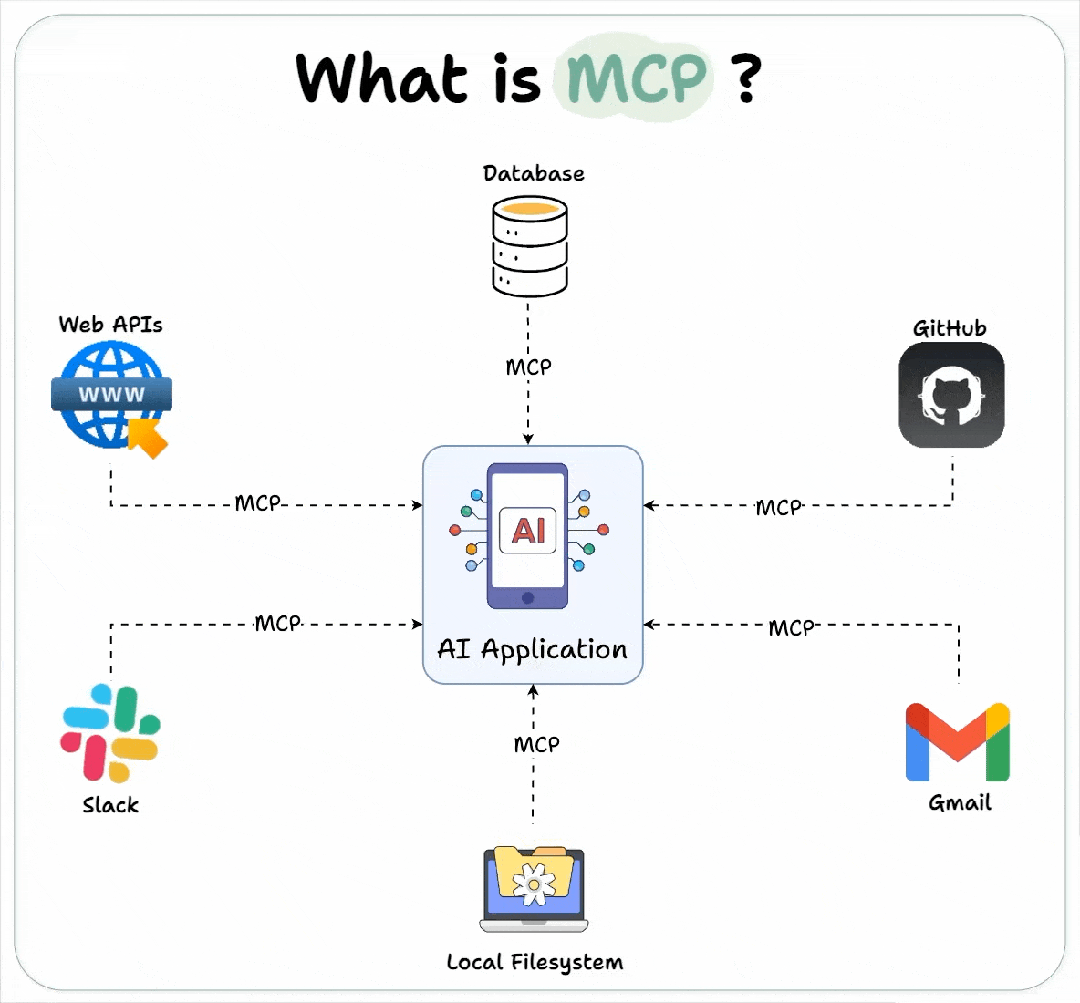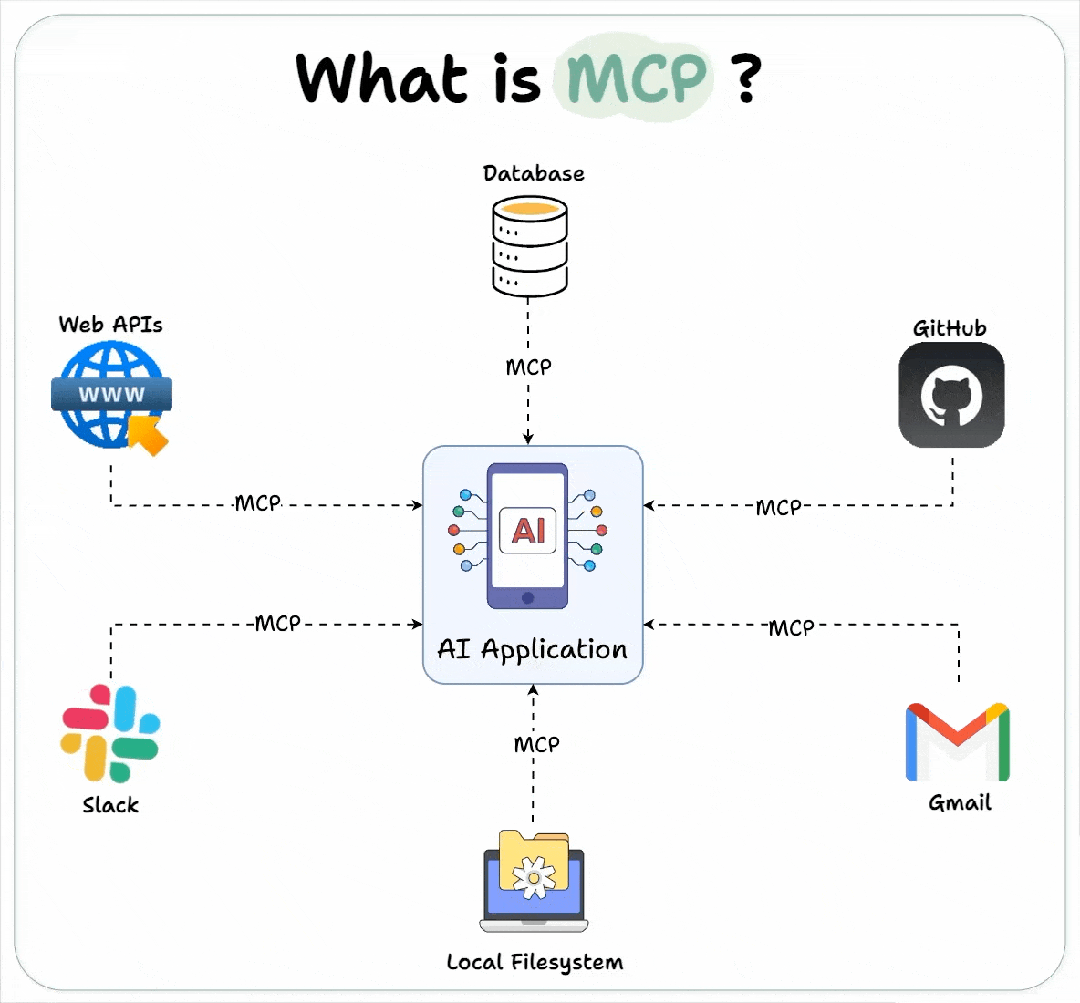
Model Context Protocol(MCP)是近年来AI系统中一个至关重要的协议,它帮助智能模型和外部工具之间实现无缝的上下文共享与交互。通过MCP,AI模型不仅能在不同的任务之间保持上下文连贯性,还能通过持续学习来提升响应的准确性和个性化。然而,随着MCP的广泛应用,其潜在的安全问题也日益显现,尤其是在处理敏感数据和多方交互时。为确保MCP在应用中的安全性,必须对其进行全面的安全测试,从而保障系统的完整性、用户的数据隐私和AI模型的可靠性。
📢相关推荐:
MCP的常见安全问题
上下文泄露与数据隐私
MCP通过持久化上下文会话来增强AI模型的智能性,这意味着模型可以跨会话持续记忆用户的互动信息。然而,这种上下文的持久性带来了极大的数据泄露风险。若上下文数据没有得到适当的加密与清理,攻击者便能通过不正当手段访问存储在会话中的敏感信息,如用户名、密码、个人身份信息(PII)、加密密钥等。
例如,攻击者可通过利用MCP协议中的漏洞,窃取本应保密的API密钥或访问数据库中的敏感数据,造成严重的隐私泄露。
提示词注入攻击(Prompt Injection)
MCP系统依赖于结构化的提示来引导AI的行为,然而,这一机制容易成为攻击者实施注入攻击的靶点。攻击者可以将恶意指令嵌入MCP工具描述中,这些指令通常是用户不可见的,但对AI模型来说却是显而易见的。通过这种方式,攻击者能够操控AI模型执行未经授权的操作,如访问敏感文件、绕过安全过滤器,甚至生成恶意内容。
例如,某恶意MCP工具描述可能通过隐蔽指令引导AI模型访问用户的私钥文件,并将其传输到外部服务器,而用户在界面上看到的仅是一个简单的工具功能描述。
会话劫持与重放攻击
持久的上下文会话为AI模型提供了跨多次交互的记忆能力,但这也使得模型易受会话劫持的威胁。攻击者可以通过重放会话令牌,冒充合法用户与AI进行交互,操控模型执行恶意操作。
如果会话令牌未经过严格的加密或认证机制,攻击者便能轻松窃取用户会话,修改模型的行为或窃取敏感信息。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1896
1896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









