







 本文详细介绍了MPS文件规则,通过实例展示如何构造一个数学规划问题的MPS文件,并使用pysmps库解析该文件,展示了目标函数、约束条件和变量边界等关键信息。
本文详细介绍了MPS文件规则,通过实例展示如何构造一个数学规划问题的MPS文件,并使用pysmps库解析该文件,展示了目标函数、约束条件和变量边界等关键信息。
1. mps文件规则
通过一个例子来认识:
max x1 + 2 x2 + 3 x3 + x4
s.t. − x1 + x2 + x3 + 10 x4 ≤ 20
x1 − 3 x2 + x3 ≤ 30
x2 - 3.5 x4 = 0
0 ≤ x1 ≤ 40,x2 ≥ 0,x3 ≥ 0,2 ≤ x4 ≤3
对应的mps文件为:
NAME MindOptExample #NAME表示这个优化模型的名字,可不写内容
ROWS #ROWS定义各行名字,包括目标函数与约束条件
N obj #N表示自由行,obj是对目标函数的命名,可任意取名
L c1 #L表示该行小于等于, c1是对该行的命名,可任意取名
L c2
E c3 #E表示该行等于
COLUMNS #COLUMS定义各列名字
x1 obj -1 c1 -1
x1 c2 1
x2 obj -2 c1 1
x2 c2 -3 c3 1
x3 obj -3 c1 1
x3 c2 1
MARK0000 'MARKER' 'INTORG'
x4 obj -1 c1 10
x4 c3 -3.5
MARK0001 'MARKER' 'INTEND'
RHS #RHS定义约束条件等号右边的值
rhs c1 20 c2 30
BOUNDS #BOUNDS定义决策变量的上界或下界
UP bnd x1 40 #UP 表示上界
LO bnd x4 2 #LO 表示下界
UP bnd x4 3
ENDATA #ENDATA表示MPS文件结束
2. 文件解析
使用pysmps解析文件,例如上面的例子的结果是:
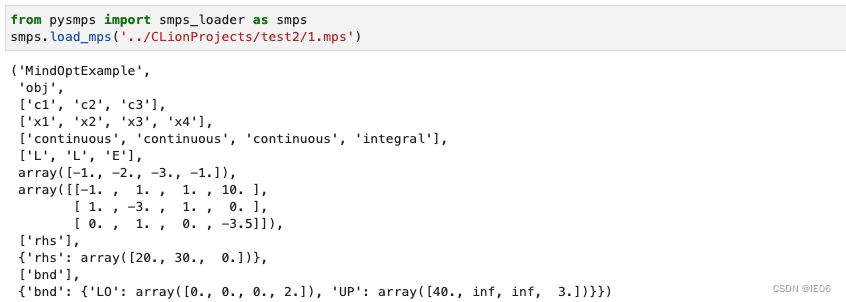
前四行是命名行,分别是:项目名、目标函数名、行名(约束条件名)、列名(变量名)
接下来两行是变量类型和约束条件类型
接下来两行是目标函数和约束条件的参数
接下来两行是rhs列表和rhs对应的值
接下来两行是bound列表和bound对应的值
解析函数为:
import re
import numpy as np
from pysmps import smps_loader as smps
def displayMps(file_path, dis_name = True, dis_bound = True, dis_integral = True):
m = smps.load_mps(file_path)
# variable names
obj_type = 'Min '
ss = []
xs = [symbols('%s_{%s}' % tuple(re.split('(\d+)', v)[:2])) for v in m[3]]
# objective
cons = m[6]
if np.all(m[6]<=0):
obj_type = 'Max '
cons = -m[6]
obj = simplify(sum(xs*cons))
ss.append(Math(latex(dis_name*('%s: '%m[1]))+latex(obj_type)+latex(obj)))
# constraints
rhs = list(m[9].values())[0]
for i in range(len(m[2])):
if m[5][i]=='L':
eq = simplify(sum(xs*m[7][i])) <= rhs[i]
elif m[5][i]=='G':
eq = simplify(sum(xs*m[7][i])) >= rhs[i]
elif m[5][i]=='E':
eq = Eq(simplify(sum(xs*m[7][i])), rhs[i])
ss.append(Math(latex(dis_name*('%s: '%m[2][i]))+latex(eq)))
# bounds
if dis_bound:
bnd_list = []
bnd=list(m[11].values())[0]
for j in range(len(m[3])):
if bnd['LO'][j]>0:
eq = xs[j] >= bnd['LO'][j]
bnd_list.append(latex(eq))
if bnd['UP'][j]!=np.inf:
eq = xs[j] <= bnd['UP'][j]
bnd_list.append(latex(eq))
ss.append(Math(','.join(bnd_list)))
# integral
if dis_integral:
ids = np.where(np.array(m[4])=='integral')[0]
if len(ids)>0:
ss.append(Math('{'+','.join([latex(v) for v in list(np.array(xs)[ids])])+'}\in Z'))
for s in ss:
display(s)
return "NAME:%s, ROWS:%d, COLUMNS:%d" % (m[0], len(m[1]),len(m[2]))
displayMps('../CLionProjects/test2/1.mps')
解析结果如下:


















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









