



能,怎么就不能呢?Ginie不也是一样的吗
你要的是一个预测动作带来的state的改变,又不是要画面

其实我也比较倾向于世界模型应该能感知真实物理世界的一些定理,比如牛顿三大定律啥的,后来一想牛顿三大定律也是在一定场景的有效解释而已,也不是真正的“天理”,所以我对世界模型的定义也就释怀了,只要能解释清楚就行。
我以前玩过MS 得Muse,这俩玩意严格来说一样的

简单说就是拿之前的帧和你输入给游戏的动作指令,来预测这个指令实施以后后面帧的图像
我们就把这个mineworld叫矿世界就算了

矿世界(MineWorld)通过以下核心技术和创新点在Minecraft中实现了实时交互式世界模型:
基于视觉-动作自回归Transformer的模型架构
矿世界的核心是一个由视觉-动作自回归Transformer驱动的模型,这和GPT4o一样也是纯自回归啊,也没用diffusion,但是这玩意到也好解释,游戏画面就那么几样,它也没啥可泛化的,用AR完全没毛病。该模型通过将游戏场景(视觉状态)和用户的动作作为配对的输入,并生成随后的新游戏场景。
离散Token表示
为了让Transformer能够处理视觉和动作信息,矿世界采用了不同的Tokenizer将它们转换为离散的Token ID。
-
- 视觉Tokenizer
使用经过微调的VQ-VAE(向量量化变分自编码器)作为视觉Tokenizer,将每个游戏状态(视频帧)独立地压缩成一系列离散的Token。该Tokenizer实现了16×的空间压缩率。
- 动作Tokenizer
将Minecraft中的动作分解为离散的Token。连续的鼠标移动(控制视角)被量化为离散的bin。离散的动作(如前进、攻击)被分类为7个互斥的类别,每个类别用一个唯一的Token表示,也就是所有的操作,被组合成7个互斥的action,此外,还使用了特殊的起始和结束Token来标记动作序列的边界。每个动作最终被表示为一个包含11个Token的序列。
-
游戏状态和动作的Token被交错拼接作为Transformer模型的输入。
- 视觉Tokenizer
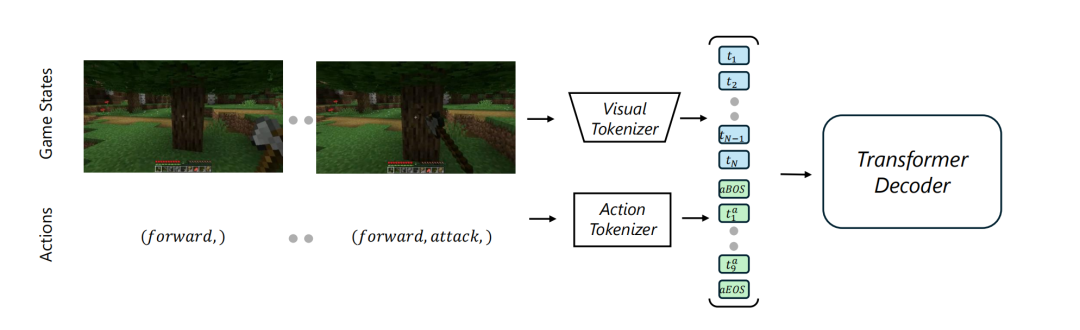
自回归训练目标
模型采用传统的自回归解码器进行训练,通过预测序列中的下一个Token来学习游戏状态的丰富表示以及状态和动作之间的条件关系。模型同时学习了作为策略模型(预测动作)和世界模型(预测未来状态)的能力,这个世界模型就是这么来的,所以我也叫它包括muse,还有ginie甚至李飞飞的那个,都叫做有限世界模型。
新颖的并行解码算法
-
为了实现实时交互,矿世界开发了一种并行的解码算法。与标准的自回归解码逐个预测Token不同,该方法利用空间相邻Token之间的依赖性,同时预测同一帧中空间冗余的Token组。
-
-
这种方法显著加速了Transformer的自回归生成过程,实现了比标准自回归解码超过3倍的加速,AR不是慢吗,difussion快能并行,但是这个AR一次吐好多个token,所以页能客观上快一点。
-
配备该解码算法,矿世界能够生成每秒4到7帧,使得与游戏玩家的实时交互成为可能。矿世界将“实时”定义为能够跟上业余玩家(>2 FPS,约150 APM)甚至专业玩家(>5 FPS,约250-300 APM)的动作速度。
-
为了解决并行解码可能带来的性能下降问题,矿世界还对自回归预训练模型进行了微调,将标准的因果注意力机制替换为与并行解码算法对齐的Mask。实验表明,微调后模型在保持生成质量的同时,实现了实时交互的频率。
新的评估指标
-
为了评估世界模型的性能,矿世界提出了新的评估指标,这些指标不仅评估视觉质量(如FVD、PSNR、LPIPS、SSIM),还特别关注动作跟随能力(Controllability)。
-
为了评估Controllability,矿世界利用一个逆动力学模型(IDM),该模型从连续生成的帧中预测执行的动作。
-
通过比较IDM预测的动作和作为条件输入的真实动作之间的准确率,来反映生成模型对控制信号的遵循程度。
-
针对离散动作,矿世界将动作分组为不同的分类任务(三元分类和二元分类),并使用精确率(Precision)、召回率(Recall)和F1分数等分类指标来评估Controllability。实验表明,这些基于分类的评估指标与人类的评估结果具有显著的正相关性。
-
对于摄像机移动,则计算预测的和真实摄像机角度bin之间的L1损失。
-
说来说去,Mineworld这个模型就会死通过将游戏状态和动作Token化、利用Transformer模型学习其联合表示、引入并行解码算法以加速生成,并设计新的评估指标来衡量Controllability,在Minecraft中构建了一个实时、高效且可控的交互式世界模型,但是还是和muse一样的,你可以交互,但是不是玩游戏,而是基于你的输入来预测后面的帧
有兄弟说,这什么破玩意啊,我用你预测后面的帧啊,我页玩不了?
你young 了,也很naive
你现在看这它预测的是帧,其实它最后是玩,能理解你的动作,也就是
说,后面的打法就是用这个来玩RL,能深刻理解你action带来的reward,总不能乱跑吧,所以说来说去做后还是玩RL去了。。。
例如,它可以作为强化学习系统中的规划器。Agent可以在 MineWorld 这样的模型中进行安全探索,预测不同行动的后果,从而学习更优的策略,然后再将学到的策略应用到真实环境中。
或者咱们延展一点,如果这东西画面够好一点,比如极品飞车,通过 这么玩,研究人员可以设计和测试不同的规划算法,而无需在真实的 自驾场景进行耗时且可能危险的实验(但是这个的前提就是要有我说的对真实世界物理引擎的理解了,或者我们说仿真,否则,走任何trajectory都是无意义的MDP)


















 194
194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









