



 本文介绍了SARSA模型在强化学习中的应用。通过一个简单的地图环境,解释了无模型概念,并逐步阐述了SARSA算法的实现过程,包括定义状态、动作、Q矩阵、更新函数以及在线学习训练。在训练过程中,虽然没有达到最优路径,但依然展示了无模型强化学习规划路径的能力。
本文介绍了SARSA模型在强化学习中的应用。通过一个简单的地图环境,解释了无模型概念,并逐步阐述了SARSA算法的实现过程,包括定义状态、动作、Q矩阵、更新函数以及在线学习训练。在训练过程中,虽然没有达到最优路径,但依然展示了无模型强化学习规划路径的能力。
第三节我们主要讲一下SARSA模型
有模型的概念:简单理解,上节课我讲的就是有模型,就是可以开上帝视角,知道全局地图
无模型的概念: 打CS,但是看不到地图的情况,全凭自己探索

今天的讲解环境还是和上节课一样,如下图:
假如我有一个人物(不是勇者),在一个地图上奔跑为了得到最终的奖杯,因为不是勇者所以看到哥布林打手就会被揍死,所以必须要走没有哥布林的格子才能拿到奖杯
现在再给点附加条件玩家初始只有100分,每经过一个格子会扣1分,要求通过强化学习生成一个模型, 从起点到拿到奖杯,分数保留越高越好
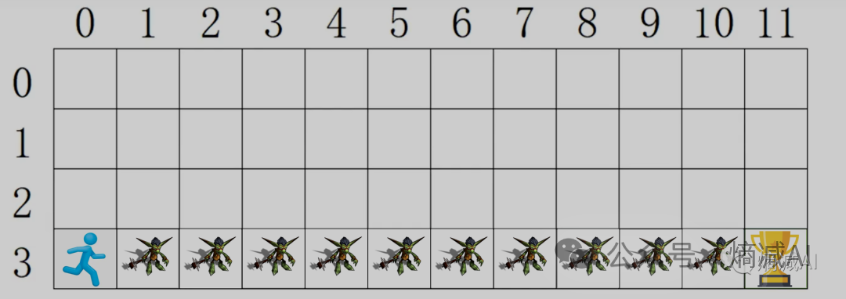
我们还是把上面的环境绘制出来
-
0-3是行
-
0-11是列
一共48个格子
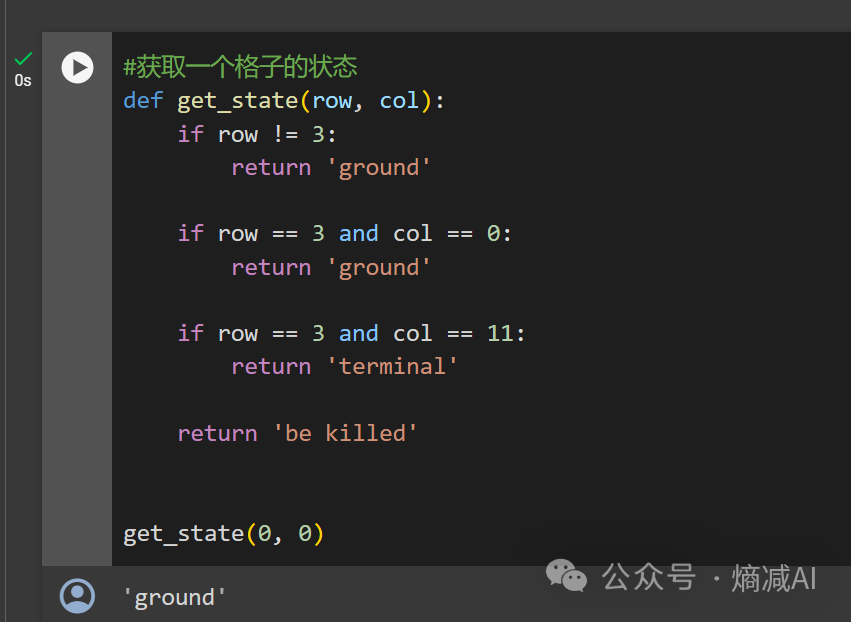
第一步:首先我们定义格子函数的不同状态 get_state,以横纵坐标为单位(row,col),然后分别定义出ground(可以走),terminal(奖杯处),be killed(哥布林处)的格子
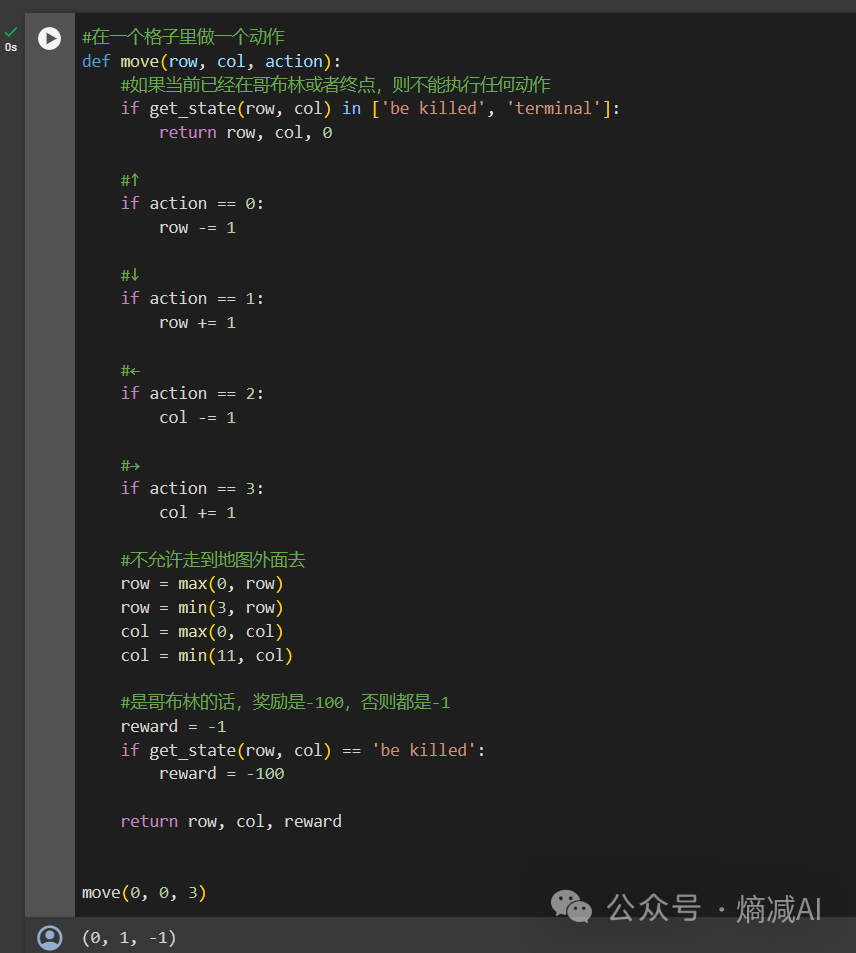
第二步:定义Move函数,和上节课也一样
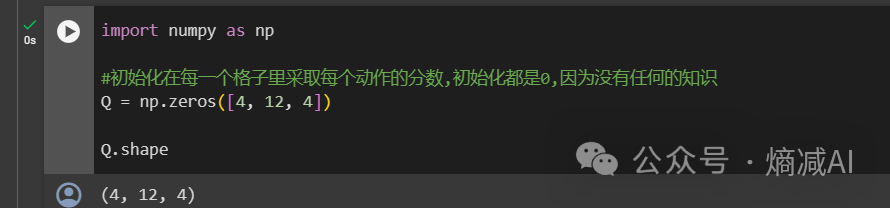
第三步:绘制地图Q(Q矩阵),4*12个格子,4个方向的action,用于评估每个动作的价值,我目前没有任何先验的知识,大脑一片空白,所以就用全0来初始化了
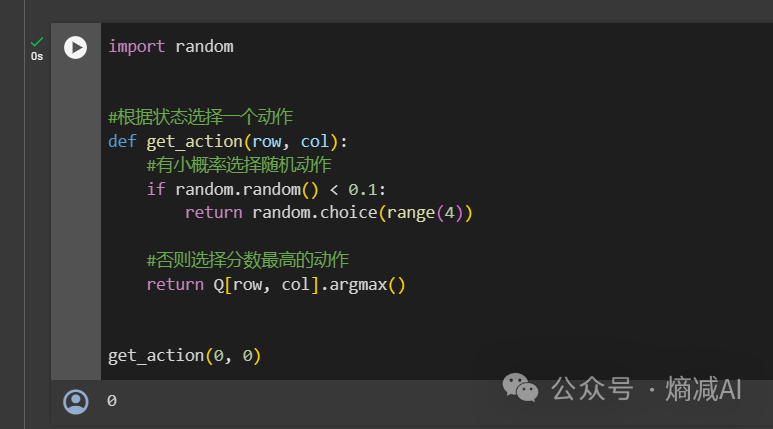
第四步:定义action的行为是啥样的,也就是我们的动作函数,这块就跟上节课不一样了,因为我不是有模型的,属于无模型的,就是我没办法有全局上帝视角,比较像第一章我讲的多臂老虎机问题 ,就是一个普通的贪婪算法,所以它也有了探索和利用两部分的action
第五步,定义我们的get_update的函数,这里面我们其实定义的传参,包括:
-
本时刻的row,col 的坐标也就是本时刻的state S
-
本时刻的action A
-
reward R
-
下一个时刻的next_row,next_col的坐标,也就是下一时刻的next_state S
-
下一时刻的action,next_action A
这5个字母连起来就是sarsa,这也就是sarsa算法的由来
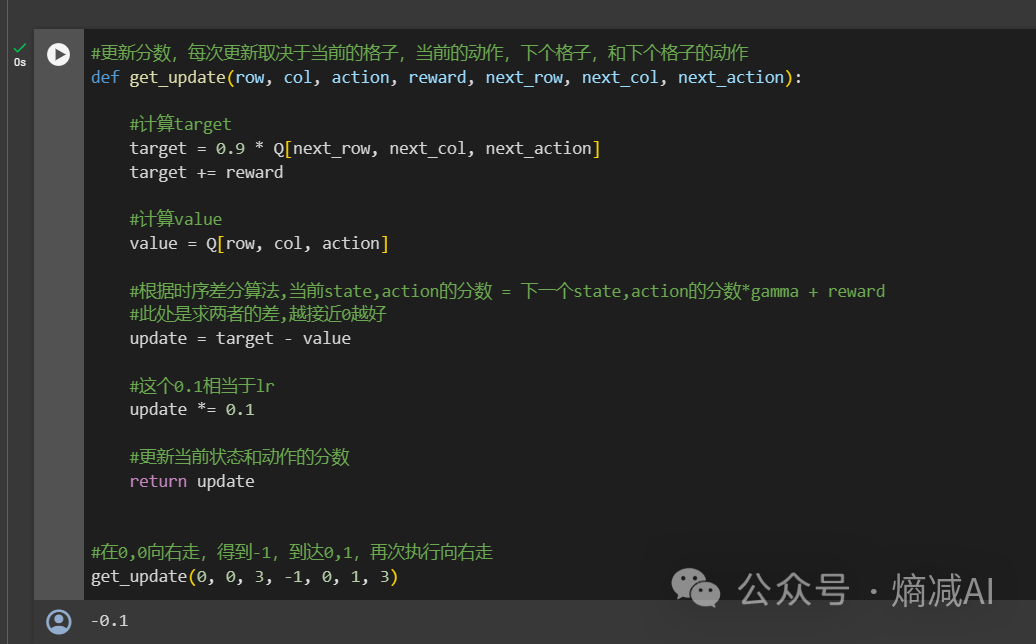
通过传参,我们拿到了这些信息:
-
通过本时刻的state和action,我能知道我当前时刻的reward
-
我还想知道我得到这个reward以后,我下一个状态和动作是否足够好,所以我引入了target,就是把下一个时刻的state和action也算出来一个reward——"target"(通过Q矩阵来计算),因为是下一个动作,所以我给了个系数gamma0.9,描述未来不确认的概念
根据时序差分算法:
当前state,action的分数 = 下一个state,action的分数*gamma + reward
那么:
等式左边就等于现在的value=Q[row, col, action]
等式右边就等于target+=reward
这两个式子应该是相等的,但是默认在模型没收敛之前肯定是不相等的,因为value和target都是评估出来的,肯定有误差,所以我们把这个不相等的数字叫做函数update,我们希望它能最后收敛为接近于0
update = target - value
update *= 0.1#这个0.1相当于学习率了
然后就不断地更新update的值就可以了
这个返回值update其实就是针对Q表格执行了动作的更新
第六步:开始训练

SARSA算法是在线学习算法,可以简单理解为,走一步算一步,一直有反馈,反馈的就是我们定义的那个reward_sum,这个值越大越好,证明我游戏玩的成功
在没有碰到哥布林和到达终点之前,我用while,让这它不断地学习,不断地try,反复更新本时刻的状态,action和下一个时刻的状态action以及reward,然后代入get_update函数,更新函数update
这个代码里,我训练了1500次,每150次做一次打印。可能是学习率的问题吧,过了750反而开始抖动,也有可能是小概率探索却没有达到比利用更好的得分,倒无所谓,也不用深究,反正就是给大家一个演示
第七步和第八步就是打印测试和结果了,和第二篇里的一样,在这就不赘述了
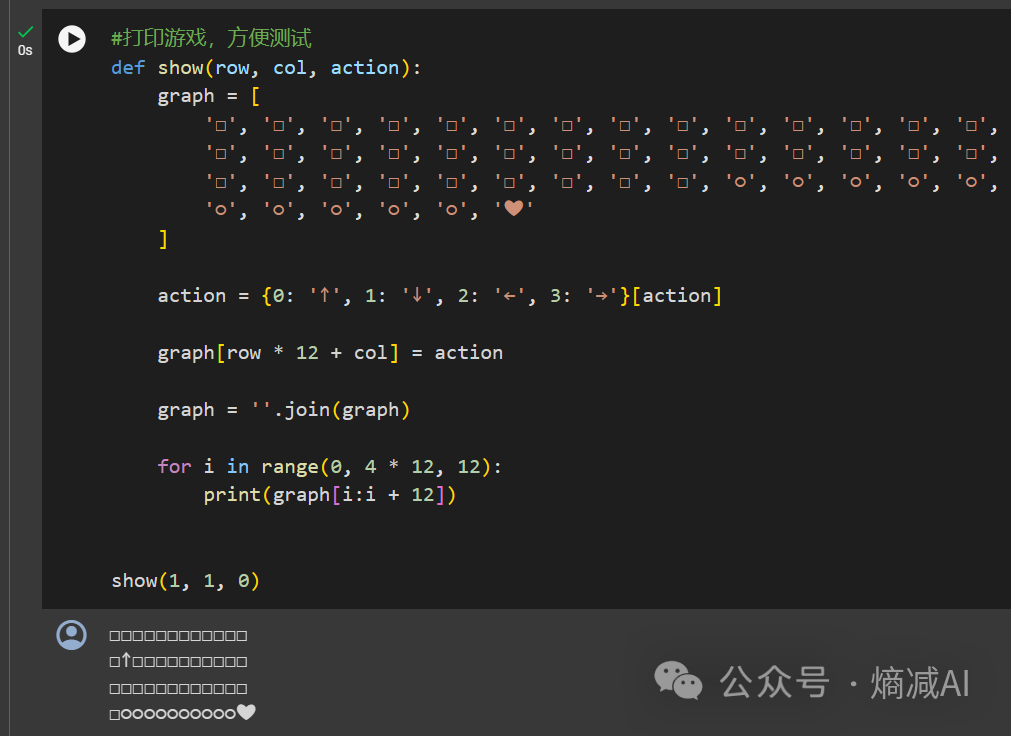
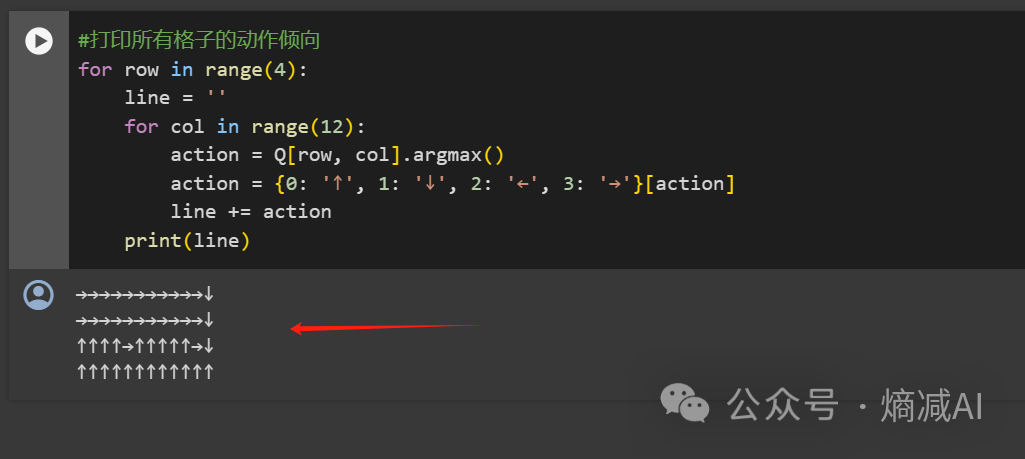
可以看到这个打印的路径没有之前的policy based动态规划算法好,主要是因为我们是无模型的方式来做的,没开天眼,这个也正常,但是总之经过训练它还是会顺利的规划路径到达终点的
本节完



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









