String==汇总(jdk1.7及以上版本)
点击这里直接通往测试代码地址
String s1 = "abc";
String s2 = new String("abc");
String s1 = new String("ab") + new String("c");
String s1 = new String("ab") + new String("c");
s1.intern();
String s2="abc";
System.out.println(s1==s2);
String s1 = new String("ab") + new String("c");
String s2="abc";
s1.intern();
System.out.println(s1==s2);
String s1 = "a" + "b";
final String s1 = "a";
final String s2 = "b";
String s3 = s1 + s2;
String s4 = "ab";
System.out.println(s3 == s4);
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = "ab";
System.out.println(s3 == s4);
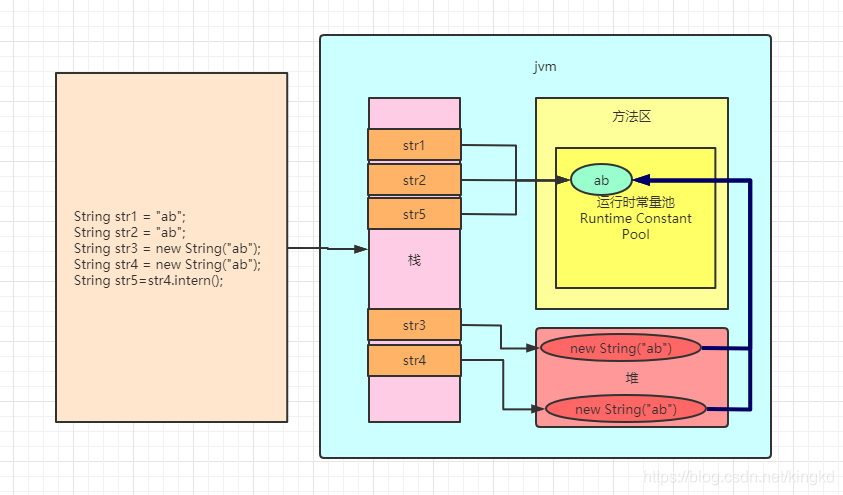





 本文深入探讨了Java中String对象的创建方式,包括直接赋值与使用new关键字的区别,以及intern方法如何影响String对象在常量池中的存储。通过具体代码示例,解析了不同场景下String对象的内存分配与引用指向,为理解Java内存管理和优化提供了关键洞见。
本文深入探讨了Java中String对象的创建方式,包括直接赋值与使用new关键字的区别,以及intern方法如何影响String对象在常量池中的存储。通过具体代码示例,解析了不同场景下String对象的内存分配与引用指向,为理解Java内存管理和优化提供了关键洞见。

















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









