







场景:单表 500 万以上 数据在处理关联查询时,效率就会降低
拆分规则
垂直拆分
- 根据业务的不同来进行拆分(类似于微服务,将不同的业务拆分成 不同的服务)
- 一般用于分库
- 拆表也可以,将常用字段和不常用字段分开
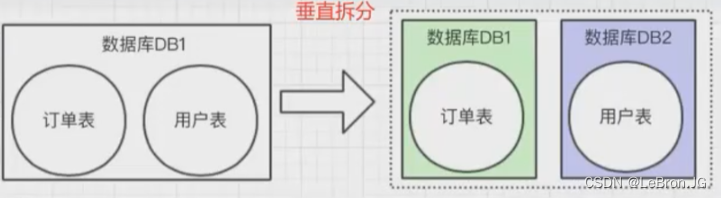
水平拆分
- 相同的业务,因为数据量大,所以将表进行拆分成多个
- 一般用于分表
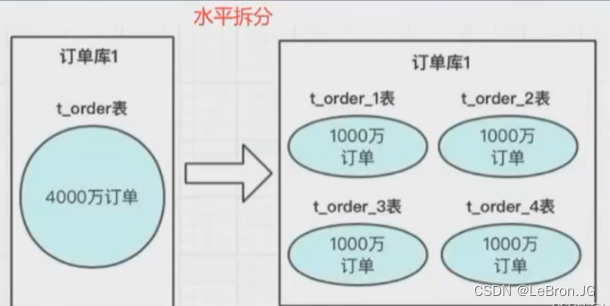
分表规则
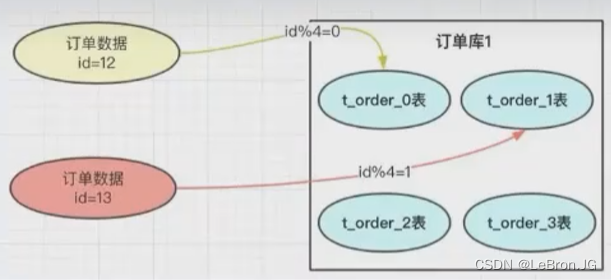
hash取模分表
- 不推荐,hash 是取模 处理,需要知道总计多少张表,这样造成的问题就是 很难扩容
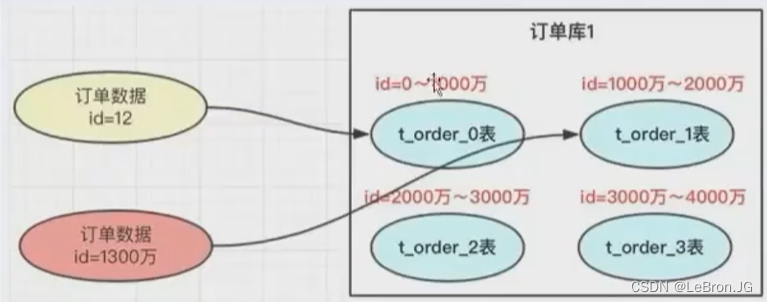
range范围分表
- 固定id范围分表,将不同范围的表,分到不同的表
- 会有热点问题,可能同一范围的数据都是热点数据,并发压力较大
为什么要使用分库分表
分库分表可以提升系统的稳定性跟负载能力,不存在单库/单表大数据。没有高并发的性能瓶颈,增加系统可用性。缺点是分库表无法join,只能通过接口方式解决,提高了系统复杂度。
shardingsphere 数据库中间件
- ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成。
- 他们均提供标准化的数据分片、读写分离、多数据副本、数据加密、影子库压测、分布式事务和数据库治理等功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
- Sharding-JDBC最早是当当网内部使用的一款分库分表框架,到2017年的时候才开始对外开源,这几年在大量社区贡献者的不断迭代下,功能也逐渐完善,现已更名为ShardingSphere,
- 2020年4月16日正式成为Apache软件基金会的顶级项目,同时兼容多种数据库,通过可插拔架构,理想情况下,可以做到对业务代码无感知。
分库分表举例
根据日期时间进行分表,将不同时间的表后缀改为 日期,
比如: order_202401,order_202402,


















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









