







 超级会员免费看
超级会员免费看
 本文介绍了Hadoop MapReduce中的键值对处理,包括MapReduce如何生成键值对,Map输入输出,Reduce输入输出的键值对定义,以及通过具体例子展示了键值对的生成过程。
本文介绍了Hadoop MapReduce中的键值对处理,包括MapReduce如何生成键值对,Map输入输出,Reduce输入输出的键值对定义,以及通过具体例子展示了键值对的生成过程。
MapReduce 键值对
Apache Hadoop 主要用于数据分析,我们利用数据分析里面的统计和逻辑技术来描述,说明和评估数据。Hadoop 可以用来处理机构化,非结构化和半结构化数据。在使用 Hadoop 的时候,当模式是静态的时候,我们可以直接使用模式的列,如果模式是非静态的,就不能用列的,因为没有列的概念了,只能使用键和值来处理数据。键和值并非是数据的固有属性,它只是在对数据做分析时人为选择的一种策略。
MapReduce 是 Hadoop 的核心组件,主要用于数据处理。Hadoop MapReduce 是一种软件框架,利用这个框架很容易就能开发出处理存储在 HDFS 的大数据量的应用程序。MapReduce 把处理过程分成两个阶段:Map 阶段和 Reduce 阶段。每个阶段的输入数据和输出数据都是以键值对的形式出现。
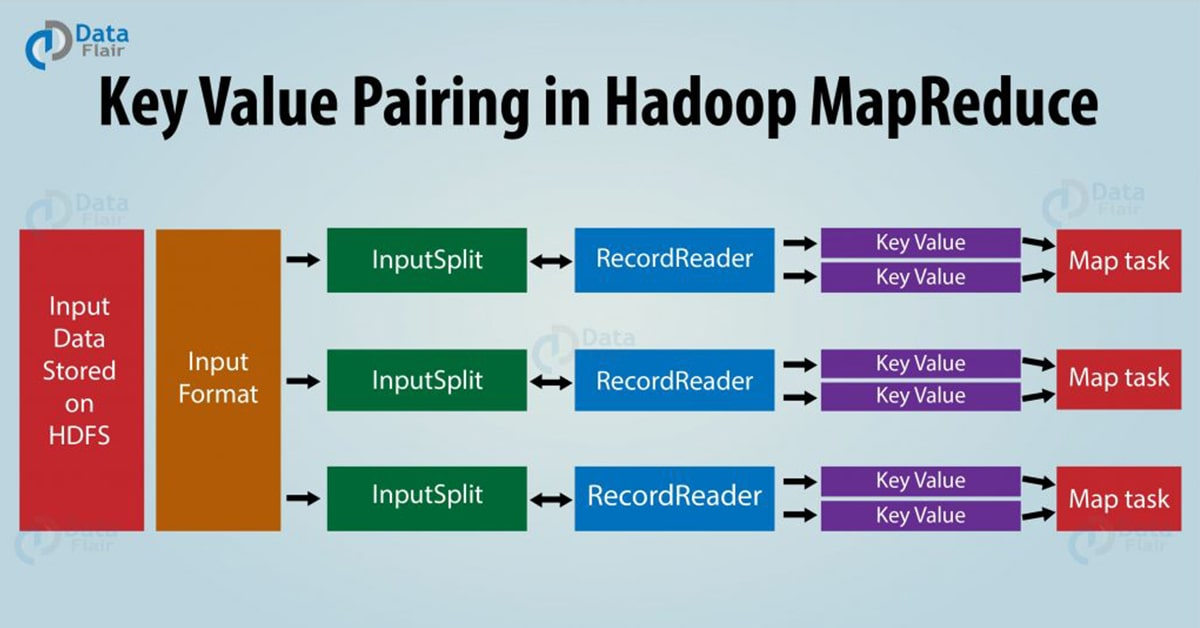
MapReduce 键值对的生成
让我们来了解一下 MapReduce 框架是怎么生成键值对的。MapReduce 过程中,在数据传输给 mapper 之前,数据首先被转换成键值对,因为 mapper 只能处理键值对形

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











