




 本文介绍了并行训练基分类器的方法——Bagging和随机森林。Bagging基于自助采样法,训练出多个基学习器,分类任务使用投票法,回归任务用简单平均法。随机森林则在Bagging基础上增加了特征随机选择,增强基分类器多样性,性能随基分类器数量增加而提升。
本文介绍了并行训练基分类器的方法——Bagging和随机森林。Bagging基于自助采样法,训练出多个基学习器,分类任务使用投票法,回归任务用简单平均法。随机森林则在Bagging基础上增加了特征随机选择,增强基分类器多样性,性能随基分类器数量增加而提升。
上一篇博文中我们介绍了串行训练基分类器的方法--Boosting以及它的代表性算法AdaBoost,接下来我们一起了解一下并行训练基分类器的方法---Bagging,这种方式中基分类器并没有依赖关系。
Bagging
Bagging是并行式集成方式最著名的代表,它直接基于自助采样法。给定包含m个样本的数据集,我们使用有放回的采样方式进行m次采样,每次采样一个样本,这样经过m次我们还是得到了m个样本的数据集,初始训练集中有的样本在采样集中多次出现,有的从来没有出现,可以计算出有多少样本在m次采样中从来没有出现过:
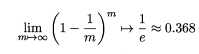
上面这个式子应该不难理解,一次采样中,被采到的概率是1/m,没有被采到的概率是1-1/m,那么如果m次都没有采到,这样的概率就是上面的计算结果。
照这样,我们可以采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合,这就是Bagging的基本流程。在对预测结果进行结合时,Bagging通常对分类任务使用简单的投票法,对于回归任务使用简单平均法。如果分类任务中出现两个类收到同样票数的情况,最简单的做法就是随机选择一个。
Bagging中训练基分类器的好而不同体现在哪里?? 首先好体现在训练基分类器都是基于误差率最小的情况,不同体现在徇烂基分类器的样本不同,每含有m个样本都是进过随机采样的,这样得到的T个含m个样本的训练集肯定不一样。
上面说到自助采样的过程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









