



本文主要是对最近的两篇transfomer 进行分析
1. inductive bias 归纳偏置
谷歌的MLP-Mixer告诉我们一点,大量的数据是可以战胜inductive bias的,但是显然一点是,数据量小的情况下和ViT是一致的,显得力不从心,存在过拟合的情况。
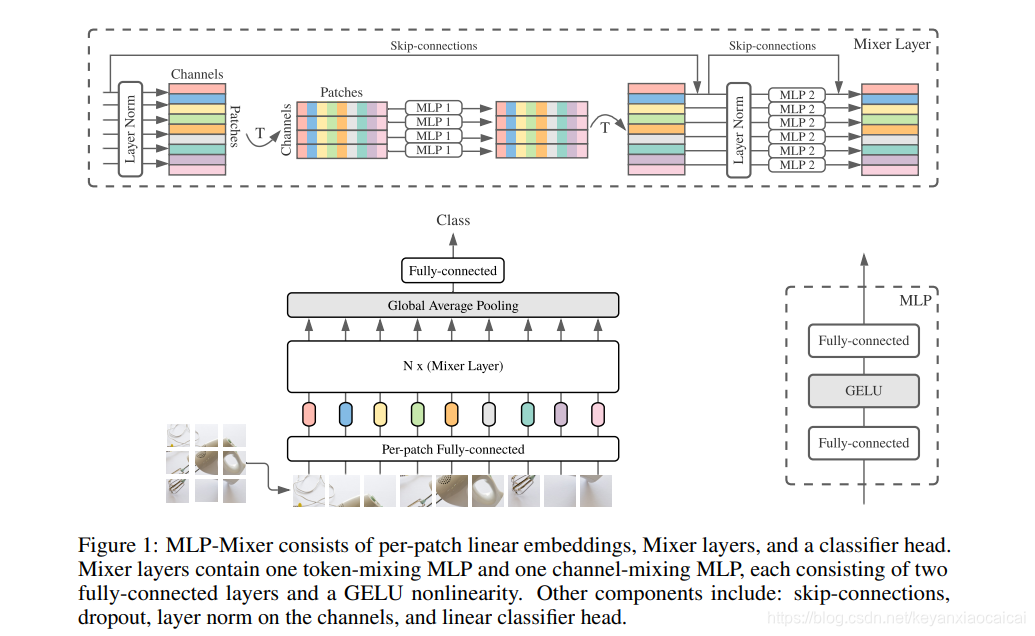
https://zhuanlan.zhihu.com/p/361686988--动画比较形象的描述了前向推理的过程
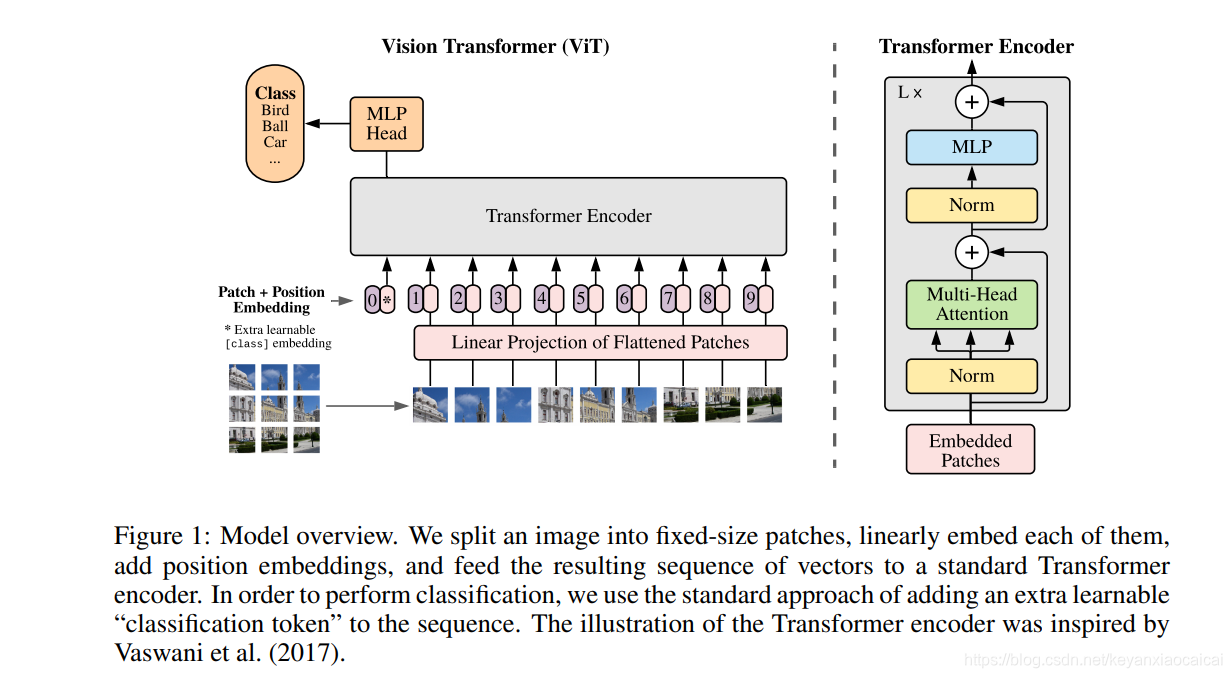
 本文探讨了Transformer模型在小数据场景下与ViT的差异,强调了归纳偏置在数据量不足时的作用,并引用MLP-Mixer的发现来说明大量数据的重要性。通过动画解释,揭示了模型在过拟合问题上的动态表现。
本文探讨了Transformer模型在小数据场景下与ViT的差异,强调了归纳偏置在数据量不足时的作用,并引用MLP-Mixer的发现来说明大量数据的重要性。通过动画解释,揭示了模型在过拟合问题上的动态表现。
本文主要是对最近的两篇transfomer 进行分析
1. inductive bias 归纳偏置
谷歌的MLP-Mixer告诉我们一点,大量的数据是可以战胜inductive bias的,但是显然一点是,数据量小的情况下和ViT是一致的,显得力不从心,存在过拟合的情况。
https://zhuanlan.zhihu.com/p/361686988--动画比较形象的描述了前向推理的过程
 808
8618
738
808
8618
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























