 分布式训练调试与初始化方法
分布式训练调试与初始化方法





 博客内容涉及在多GPU环境中使用PyTorch进行分布式训练的调试问题。主要问题是57服务器资源被占用导致无法调试,以及185服务器上出现的错误。作者对比了自己的代码和测试代码,发现在`init_method`中未定义,已将其设置为`tcp://localhost:9999`。通过检查每个函数的定义,尝试解决问题。最终发现删除`pdb`调试语句即可解决问题,并建议添加打印输出辅助调试。
博客内容涉及在多GPU环境中使用PyTorch进行分布式训练的调试问题。主要问题是57服务器资源被占用导致无法调试,以及185服务器上出现的错误。作者对比了自己的代码和测试代码,发现在`init_method`中未定义,已将其设置为`tcp://localhost:9999`。通过检查每个函数的定义,尝试解决问题。最终发现删除`pdb`调试语句即可解决问题,并建议添加打印输出辅助调试。
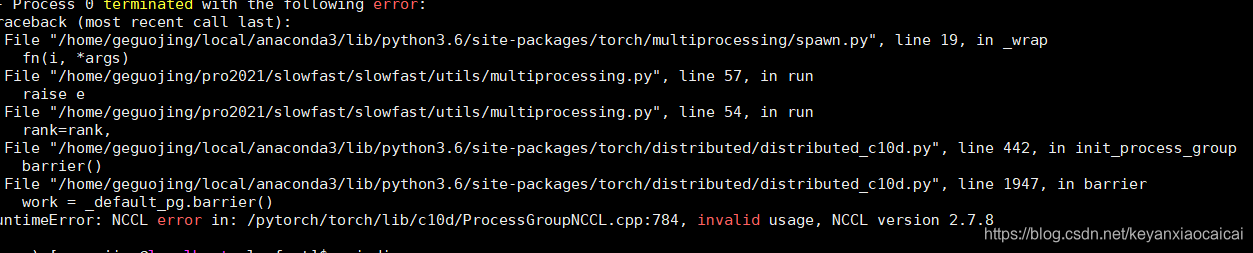
问题描述:
在57 服务器上跑:
python tools/run_net.py --cfg configs/Kinetics/X3D_XS.yaml NUM_GPUS 4 TRAIN.BATCH_SIZE 8 SOLVER.BASE_LR 0.0125 DATA.PATH_TO_DATA_DIR /mnt/data/geguojing/Heart_data/annotations20201112
目前这个问题没有解决,57 的服务器一直在被占用。调试不了
185 上的出现的错误是:
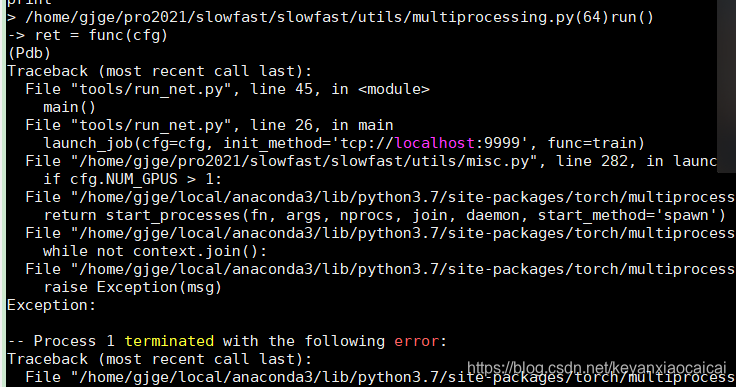
对比了自己的代码和测试代码:
import torch
import utils.distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data.sampler import RandomSampler
from torch.utils.data._utils.collate import default_collate
import pdb
def manu_collate(batch):
inputs, bbox = zip(*batch)
inputs = default_collate(inputs)
collate_bbox = [i[0] for i in bbox]
return inputs, collate_bbox
class AVA_DATA(torch.utils.data.DataLoader):
def __init__(self):
print('heihei')
pass
def __getitem__(self, index):
return torch.ones(3,224,224)*index, [index]
# return torch.ones(3,224,224)*indx
def __len__(self):
return 16
class AVA_MODEL(torch.nn.Module):
def __init__(self):
super(AVA_MODEL, self).__init__()
self.conv1 = torch.nn.Conv2d(3,64,3,1)
self.tmp = None
# for i in range(20):
# self.tmp[i]=0
def forward(self,x,bbox,tmp):
# print(x.device.index)
self.tmp.append(1)
if x.device.index==0:
print(self.tmp)
# tmp.append(1)
# print(tmp)
# # if 1:
# print('***start***')
# print(self.tmp)
# for j in bbox:
# self.tmp[j]=j
# print('***end***')
# print(bbox, self.tmp)
# self.tmp.append(1)
# print(self.tmp)
# tmp.append(1)
# print(tmp)
# print(len(bbox))
res = self.conv1(x)
return res
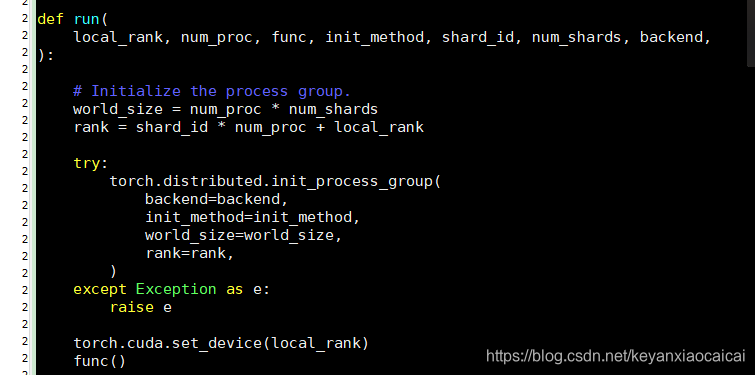
def run(
local_rank, num_proc, func, init_method, shard_id, num_shards, backend,
):
# Initialize the process group.
world_size = num_proc * num_shards
rank = shard_id * num_proc + local_rank
try:
torch.distributed.init_process_group(
backend=backend,
init_method=init_method,
world_size=world_size,
rank=rank,
)
except Exception as e:
raise e
torch.cuda.set_device(local_rank)
func()
def launch_job(func, init_method='tcp://localhost:9999', daemon=False, dis=True):
"""
Run 'func' on one or more GPUs, specified in cfg
Args:
cfg (CfgNode): configs. Details can be found in
slowfast/config/defaults.py
init_method (str): initialization method to launch the job with multiple
devices.
func (function): job to run on GPU(s)
daemon (bool): The spawned processes’ daemon flag. If set to True,
daemonic processes will be created
"""
if dis:
torch.multiprocessing.spawn(
run,
nprocs=4,
args=(
4,
func,
init_method,
0,
1,
'nccl',
),
daemon=daemon,
)
else:
func()
def train():
model = AVA_MODEL()
cur_device = torch.cuda.current_device()
model = model.cuda(device=cur_device)
# model = torch.nn.DataParallel(model).cuda()
model = torch.nn.parallel.DistributedDataParallel(
module=model, device_ids=[cur_device], output_device=cur_device)
dataset = AVA_DATA()
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=DistributedSampler(dataset),
# sampler=None,
num_workers=8,
pin_memory=True,
drop_last=True,
collate_fn=manu_collate,
# worker_init_fn=None,
)
tmp = []
model.train()
for i in range(200000000):
shuffle_dataset(dataloader,i)
for iter, (inputs,bbox) in enumerate(dataloader):
# print(i,iter)
# inputs = inputs.cuda(non_blocking=True)
# res = model(inputs,bbox,tmp)
for j in bbox:
tmp.append(j)
dist.synchronize()
tmp = dist.all_gather_unaligned(tmp)
if dist.get_rank()==0:
print(iter,tmp)
break
model.module.tmp = tmp
for i in range(2):
for iter, (inputs,bbox) in enumerate(dataloader):
# print(i,iter)
inputs = inputs.cuda(non_blocking=True)
res = model(inputs,bbox,tmp)
# tmp.append(1)
def shuffle_dataset(loader, cur_epoch):
""""
Shuffles the data.
Args:
loader (loader): data loader to perform shuffle.
cur_epoch (int): number of the current epoch.
"""
# sampler = (
# loader.batch_sampler.sampler
# if isinstance(loader.batch_sampler, ShortCycleBatchSampler)
# else loader.sampler
# )
# assert isinstance(
# sampler, (RandomSampler, DistributedSampler)
# ), "Sampler type '{}' not supported".format(type(sampler))
# # RandomSampler handles shuffling automatically
sampler = loader.sampler
if isinstance(sampler, DistributedSampler):
# DistributedSampler shuffles data based on epoch
sampler.set_epoch(cur_epoch)
if __name__ == "__main__":
tmp = dict()
pdb.set_trace()
for i in range(20):
tmp[i]=0
pdb.set_trace()
launch_job(train)
# train(tmp)
发现init_method 程序里面没有定义
给init_method 一个定义:tcp://localhost:9999
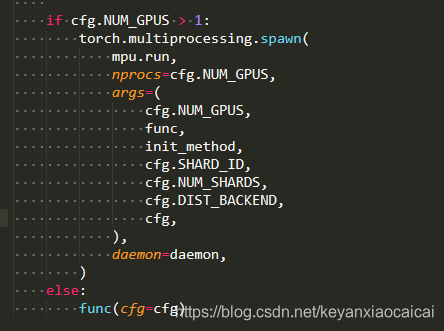
查看每一个函数定义与测试代码的异同点
cfg.SHRAD_ID 0
cfg.NUM_SHARDS 1
cfg.DIST_BACKEND 为nccl
57上的nccl 的问题 不知道修改这个是不是就可以了
进到run 里面print 打印
总结下来就是:不知道改了哪里就好了
pdb去掉就好了
最好是加打印输出


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









