






 本文介绍了如何利用深度优先搜索和固定层级策略设计数据结构,以解决LeetCode中的211题——添加与搜索单词,包括处理带有通配符的单词匹配问题。通过树状结构实现高效查找,并分享了代码优化过程和关键技巧。
本文介绍了如何利用深度优先搜索和固定层级策略设计数据结构,以解决LeetCode中的211题——添加与搜索单词,包括处理带有通配符的单词匹配问题。通过树状结构实现高效查找,并分享了代码优化过程和关键技巧。
人就是一阵一阵的动物 :) 最近又恢复迷上了LeetCode算法挑战。
今天随机一题211,添加与搜索单词
请你设计一个数据结构,支持 添加新单词 和 查找字符串是否与任何先前添加的字符串匹配 。
实现词典类 WordDictionary :
WordDictionary() 初始化词典对象
void addWord(word) 将 word 添加到数据结构中,之后可以对它进行匹配
bool search(word) 如果数据结构中存在字符串与 word 匹配,则返回 true ;否则,返回 false 。word 中可能包含一些 '.' ,每个 . 都可以表示任何一个字母。示例:
输入: ["WordDictionary","addWord","addWord","addWord","search","search","search","search"] [[],["bad"],["dad"],["mad"],["pad"],["bad"],[".ad"],["b.."]] 输出: [null,null,null,null,false,true,true,true] 解释: WordDictionary wordDictionary = new WordDictionary(); wordDictionary.addWord("bad"); wordDictionary.addWord("dad"); wordDictionary.addWord("mad"); wordDictionary.search("pad"); // return False wordDictionary.search("bad"); // return True wordDictionary.search(".ad"); // return True wordDictionary.search("b.."); // return True提示:
1 <= word.length <= 500
addWord 中的 word 由小写英文字母组成
search 中的 word 由 '.' 或小写英文字母组成
最多调用 50000 次 addWord 和 search来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/design-add-and-search-words-data-structure
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
其实添加搜索单词挺容易,这道题难就难在点号通配符。如果没有通配符,做一个list,contains就可以了,再高效一点的就是做一个有序列表快速查询。但加了通配符后,这个就行不通了。
还没开始做,看到通配符的要求后,我第一反应就是树结构,加上深度优先搜索。暂时没有想到更好的办法。先按照这个思路实现,然后UT用500个字符word和5000个add和search测试一下性能就好。
1. 所有单词分解成树形结构;
2. 深度优先搜索;
仔细想了后,发现单词的分解有一些问题,会出现重复和冲突现象,所以再增加一个条件,固定层级。第一个字符是第一层,第二个字符是第二层,固定层级。
1. 所有单词分解成树形结构;按照字母的层级组织。假设3个字符串,abc,acb和bac,则结构如下
2. 深度优先搜索;start
|- a
| |- b
| |- c
| |- c
| |- b
|- b
|- a
|- c
这样就满足要求了,就这么办,开撸代码
然后顺利撸了代码,中间发现一个小坑,a被ab截胡了,于是耍了个小聪明,给所有字符串增加了一个'\0'结尾,这样就不会被截胡了。
public class WordDictionary
{
TreeNode headNode;
public WordDictionary()
{
headNode = new TreeNode('-');
}
public void AddWord(string word)
{
word = word + '\0';
var node = headNode;
foreach(var c in word)
{
var isContains = false;
TreeNode nextNode = null;
foreach (var n in node.nexts)
{
if(n.c == c)
{
isContains = true;
nextNode = n;
break;
}
}
if (!isContains)
{
nextNode = new TreeNode(c);
node.nexts.Add(nextNode);
}
node = nextNode;
}
}
public bool Search(string word)
{
return Search(word+'\0', headNode, 0);
}
public bool Search(string word, TreeNode node, int index)
{
if(index == word.Length)
{
return true;
}
var c = word[index];
var isContains = false;
foreach (var n in node.nexts)
{
if (c == n.c || c == '.')
{
if (!Search(word, n, index + 1))
{
continue;
}
else
{
isContains = true;
break;
}
}
}
if (!isContains)
{
return false;
}
return true;
}
}
public class TreeNode
{
public char c;
public List<TreeNode> nexts;
public TreeNode(char c)
{
this.c = c;
nexts = new List<TreeNode>();
}
}
别着急。。。撸完提交,发现速度不快啊。
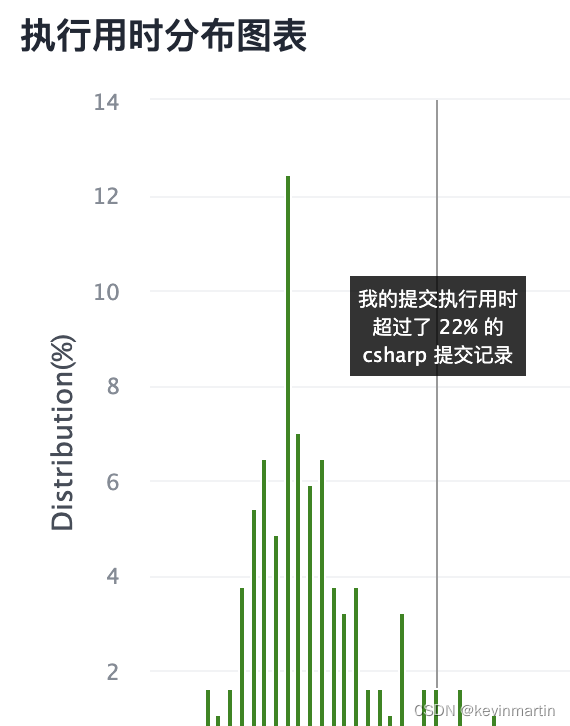
这个不符合我严谨的态度啊,怎么能才击败22%呢,至少达到平均数是吧。现在280ms,最高点230ms,还有20%的空间,继续撸。
其他优化暂时看不到了,尝试一下几个小的点,用for代替foreach,据说for更快。结果然并卵。。。
//foreach (var n in node.nexts)
for(var j=0; j<node.nexts.Count; j++)
{
var n = node.nexts[j];
.....
突然想起来,整个程序用的是深度优先搜索,用的是递归,据说循环比递归快,能不能改成循环呢?这是个大问题,勇于尝试一下。不过现在没时间了,晚点再更新。
===========
略作修改,用dictionary代替了list,不用循环,可以直接用nexts[c]定位,成功快了一点点。提升到260ms :),还需要继续努力啊
public class TreeNode
{
public char c;
public Dictionary<char, TreeNode> nexts;
public TreeNode(char c)
{
this.c = c;
nexts = new Dictionary<char, TreeNode>();
}
public TreeNode AddNode(char c)
{
var node = new TreeNode(c);
if (!nexts.ContainsKey(c))
{
nexts.Add(c, node);
}
return node;
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









