




活动地址:优快云21天学习挑战赛
作者简介:大家好我是Apathfinder,目前是一名在校大学生,软件工程专业,记录学习路上的点点滴滴。
个人主页:Apathfinder本文专栏:Python学习
前言:本文涉及到的内容是与正则表达式有关,在文中我们将不用正则表达式和用正则表达式作对比,以此来突出正则表达式的便捷。
目录
正文
一.不用正则表达式来查找文本模式
1.问题分析
在这里,我们以在字符串中查找电话号码为例,假设电话号码形式为3个数字(区号)+1条短横线+3个数字+1条短横线+4个数字,我们需要写一个函数来实现查找功能 ,函数最先要检查字符串是否为有效,无效则返回FALSE然后检查前三位区号,短横线,数字,短横线,依次检查过来,返回TRUE。
2.代码实现
首先我们写一个最基本的判断短字符串是否为有效电话号,
def isphonenumber(text):
if len(text) == 12:
for i in range(0, 3):
if text[i].isdecimal():
if text[3] == '-':
for i in range(4, 7):
if text[i].isdecimal():
if text[7] == '-':
for i in range(8, 12):
if text[i].isdecimal():
return True
return False
while(True):
stp = input("please input the text:")
if isphonenumber(stp):
print(stp + ' ' + 'is a phonenumber!')
else:
print(stp + ' ' + 'is not a phonenumber!')
我们来看运行结果
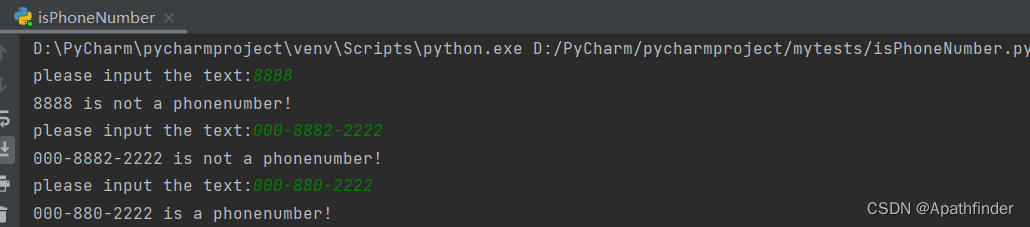
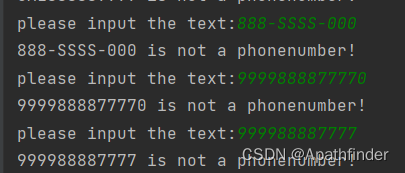
可以看到虽然能成功判断出是否为有效电话号,但代码十分繁琐
假设我们要在一篇长文本中找到所蕴含的电话号该怎么做呢?
我们可以加一个以12位长度来判断电话号的的循环
def isphonenumber(text):
if len(text) != 12:
return False
for i in range(0, 3):
if not text[i].isdecimal():
return False
if text[3] != '-':
return False
for i in range(4, 7):
if not text[i].isdecimal():
return False
if text[7] != '-':
return False
for i in range(8, 12):
if not text[i].isdecimal():
return False
return True
while(True):
stp = input("please input the text:")
for i in range(len(stp)):
ctext = stp[i:i+12]
if isphonenumber(ctext):
print(ctext + ' ' + 'is a phonenumber!')
# else:
# print(ctext + ' ' + 'is not a phonenumber!')
运行结果

二.用正则表达式查找文本模式
1.问题分析
上文的电话号码查找程序虽然能正常工作,但是代码篇幅过长,效率不够高,而且上文只能处理一种电话格式(444-444-4444),如(419)-222-4224这样的格式并不能处理。在这里我们选择使用正则表达式(regex)来处理。
2.Python正则表达式
1.正则表达式简介
正则表达式是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。 正则表达式是繁琐的,但它是强大的,学会后会让你提高效率。
2.re模块
Python中所有正则表达式的函数都在re模块中,导入模块如下
import re3.re.match
语法:re.match(pattern, string, flags=0)
参数解释:pattern指的是匹配的正则表达式,string指的是要匹配的字符串,flags是标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
re.match 尝试从字符串的起始位置匹配一个模式,匹配成功re.match方法返回一个匹配的对象,如果不是起始位置匹配成功的话,match()就返回none。
import re
print(re.match('hello', 'hello,world!'))
print(re.match('hello', 'hello,world!').span()) #返回匹配字符串的索引片段
print(re.match('hello', 'hello,world!').start()) #返回匹配字符串的索引起始
print(re.match('hello', 'hello,world!').end()) #返回匹配字符串的索引结束
print(re.match('hello', 'hello,world!').group()) #返回匹配字符串
print(re.match('hello', 'hello,world!').groups()) #返回一个包含所有小组字符串的元组
print(re.match('world', 'hello,world!')) #返回None 
4.re.search
语法: re.search(pattern, string, flags=0)
re.search 扫描整个字符串并返回第一个成功的匹配。
import re
print(re.search('world', 'hello,world!'))
print(re.search('hello', 'hello,world!')) 
3.代码实现
在我们对电话格式处理之后,那么代码量是不是大大减少了呢?
import re
while(True):
phonumregex = re.compile(r'(\d{3}-\d{3}-\d{4})')
stp = input("please input the text:")
ctext =re.findall(r'(\d{3}-\d{3}-\d{4})', stp)
for i in range(len(ctext)):
print(ctext[i]+' '+'is a phonenumber!') 
写在最后
今天的文章就到这里,如果你觉得写的不错,可以动动小手给博主一个免费的关注和点赞👍;如果你觉得存在问题的话,欢迎在下方评论区指出和讨论。
谢谢观看,你的支持就是我前进的动力!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











