






 SegNet是一种用于图像语义分割的深度学习模型,采用编码器-解码器结构,通过unpooling with indices的新上采样方式,有效解决了maxpooling造成的特征信息丢失问题。与FCN相比,SegNet在精度相当的情况下,大幅提升了存储和时间效率,特别适用于道路物体的语义信息理解。
SegNet是一种用于图像语义分割的深度学习模型,采用编码器-解码器结构,通过unpooling with indices的新上采样方式,有效解决了maxpooling造成的特征信息丢失问题。与FCN相比,SegNet在精度相当的情况下,大幅提升了存储和时间效率,特别适用于道路物体的语义信息理解。
论文地址:
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
论文实现: github代码
1. 概述
1.1 解决的问题
- 图像语义分割中max pooling等Subpooling方法缩小了特征图尺寸,导致信息丢失
- 图像分割模型的主要结构(编解码)
1.2 提出新方法
- Encoder—Decoder
- 新的上采样方式unpool with indices
1.3 得到的效果
- 精度上与FCN相差不大,而且Deconv方法效果更好
- 在存储和时间效率上SegNet效果大大改善,这也对应了SegNet的初衷,道路物体语义信息理解(自动驾驶)
2.模型关键架构
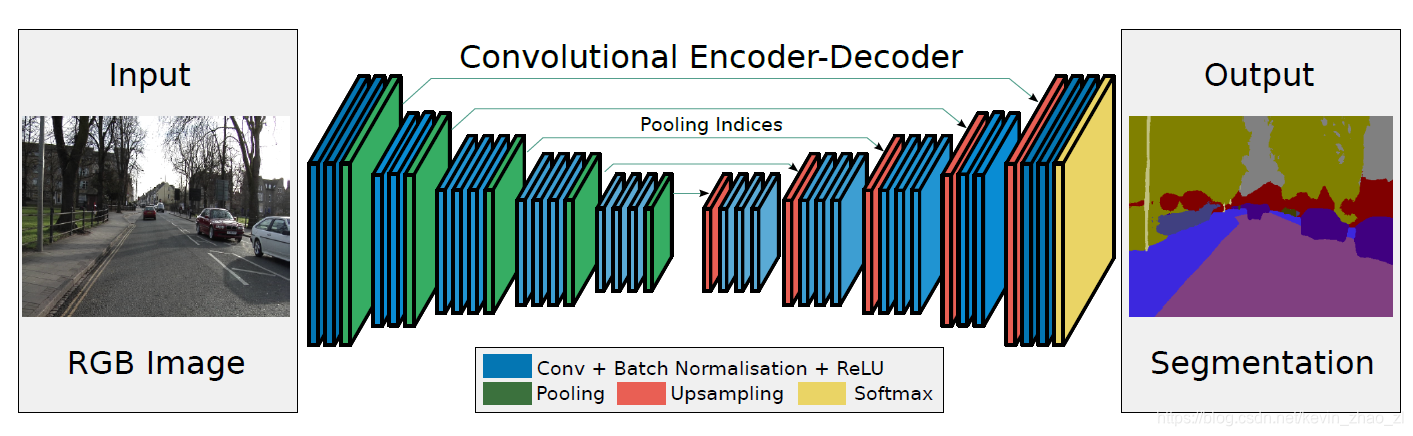
2.1 Encoder-Decoder架构
FCN语义分割网络中的编解码结构如下:
- Encoder:使用pool操作和卷积操作,特征图尺寸缩小,通道数增加 → \rightarrow → SubSample
- Decoder: 使用Deconv特征图尺寸增加
→
\rightarrow
→ UpSample
在SegNet中做了如下改进: - Encoder:VGG网络直接去掉三层全连接层,模型参数大幅度减小,模型规模大幅下降。每一次卷积后加依次Batch Normalization。
- Decoder:每一个Encoder对应一个Decoder并提出新的upSample方式,unpool with indices
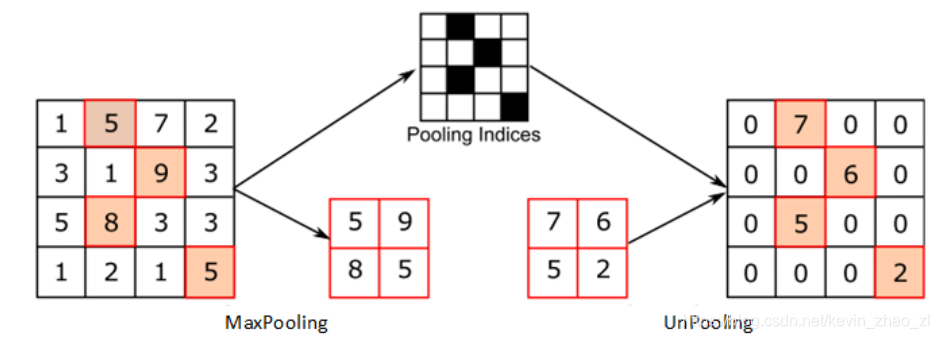
2.2 Unpool 反池化上采样方式
记录下maxPooling在对应Kerner的坐标,反池化过程中,将一个元素根据Kernerl放大,其他位置元素补0,如下图所示:

















 2476
2476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









