









在现代企业级应用中,数据库连接池是提升系统性能和稳定性的关键技术之一。Druid 是阿里巴巴开源的一款高性能数据库连接池,广泛应用于各种 Java 项目中。本文将结合代码示例,深入探讨 Druid 连接池的原理、配置、使用场景以及企业级应用中的最佳实践。
1. Druid 连接池简介
1.1 什么是 Druid?
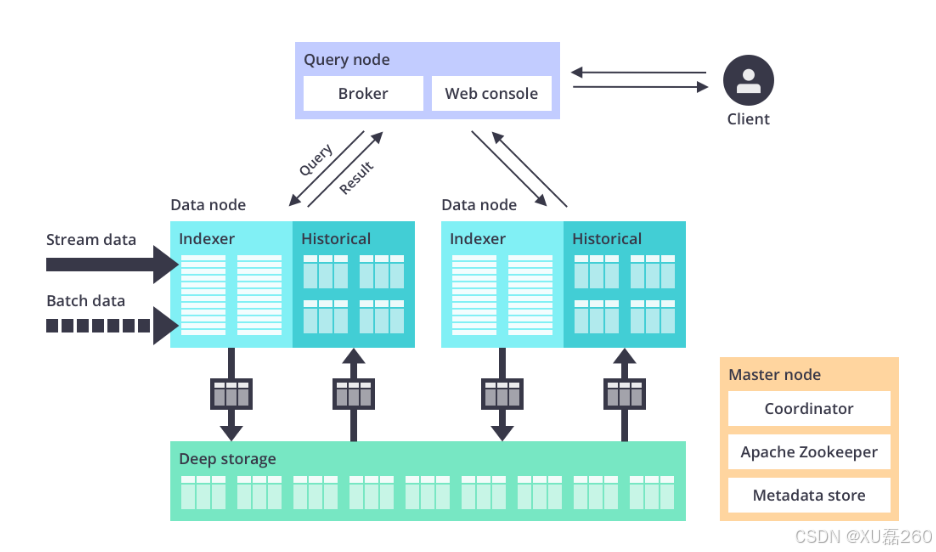
Druid 是阿里巴巴开源的一款高性能数据库连接池,支持监控、SQL 执行日志、防火墙等功能。它不仅提供了高效的连接池管理,还具备强大的监控和诊断能力,是企业级应用的首选。
1.2 为什么选择 Druid?
-
高性能:Druid 在连接池的管理和 SQL 执行性能上表现优异。
-
监控功能:内置监控功能,可以实时查看连接池状态和 SQL 执行情况。
-
扩展性强:支持自定义插件,方便集成到现有系统中。
-
安全性高:提供 SQL 防火墙功能,防止 SQL 注入攻击。
2. Druid 连接池的基本使用
首先下载jar包并导入为库项目:
下载连接:
https://repo1.maven.org/maven2/com/alibaba/druid/ 可以选择最新版1.90:
![]()
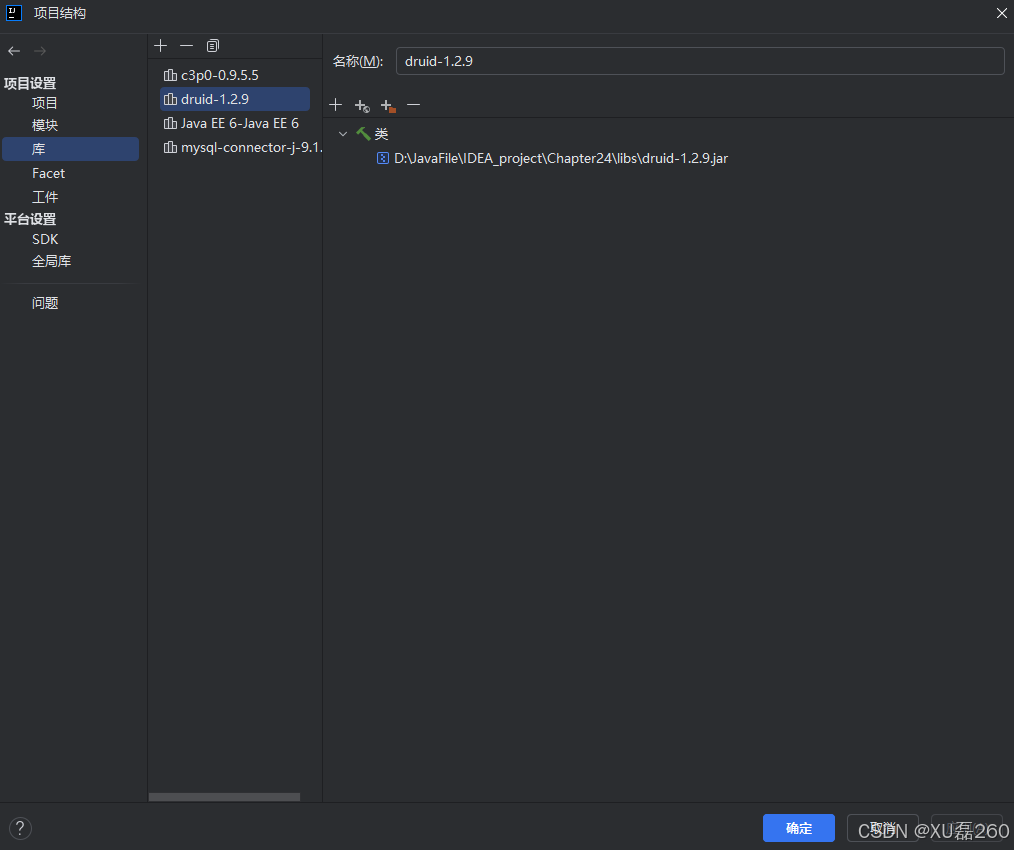
下载后,导入项目,编译器能够找到该jar包:
2.1 引入依赖
在 Maven 项目中,可以通过以下方式引入 Druid 依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>2.2 配置文件
Druid 的配置通常通过 druid.properties 文件进行管理。以下是一个典型的配置文件示例:
# 数据库连接信息
url=jdbc:mysql://localhost:3306/test
username=root
password=123456
driverClassName=com.mysql.cj.jdbc.Driver
# 连接池配置
initialSize=5
maxActive=20
minIdle=5
maxWait=600002.3 初始化连接池
通过 DruidDataSourceFactory 可以创建一个 Druid 连接池实例:
Properties properties = new Properties();
properties.load(new FileInputStream("src\\myDruid.properties"));
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);2.4 获取连接
从连接池中获取连接并执行 SQL 操作:
Connection connection = dataSource.getConnection();
PreparedStatement statement = connection.prepareStatement("SELECT * FROM users");
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString("username"));
}
connection.close();3. Druid 连接池的企业级应用
3.1 性能优化
-
连接池大小:根据系统负载调整
initialSize和maxActive参数,避免连接池过大或过小。 -
超时设置:通过
maxWait设置获取连接的最大等待时间,防止线程长时间阻塞。
3.2 监控与诊断
Druid 提供了丰富的监控功能,可以通过以下方式启用:
-
Web 监控:配置
DruidStatViewServlet,通过浏览器访问监控页面。 -
日志监控:启用 SQL 执行日志,记录每条 SQL 的执行情况。
3.3 SQL 防火墙
Druid 内置 SQL 防火墙功能,可以防止 SQL 注入攻击。通过配置 wall 插件,可以拦截恶意 SQL 语句:
filters=wall3.4 多数据源支持
在企业级应用中,通常需要支持多个数据源。Druid 提供了多数据源配置的支持:
DataSource dataSource1 = DruidDataSourceFactory.createDataSource(properties1);
DataSource dataSource2 = DruidDataSourceFactory.createDataSource(properties2);4. 代码示例
以下是一个完整的 Druid 连接池使用示例:
package JDBD_resource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import org.junit.Test;
import untils.DruidUtils_;
import untils.JDBCutils;
import javax.sql.DataSource;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;
import java.io.FileInputStream;
import java.sql.Connection;
import java.util.Scanner;
public class Druid_ {
public static void main(String[] args) throws Exception {
//1. 加入 Druid jar 包
//2. 加入 配置文件 druid.properties , 将该文件拷贝项目的src目录
//3. 创建Properties 对象, 读取配置文件
Properties properties = new Properties();
properties.load(new FileInputStream("src\\myDruid.properties"));
//4. 创建一个指定参数的数据库连接池,Druid连接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
long start = System.currentTimeMillis();
for (int i = 0; i < 500000; i++) {
Connection connection = dataSource.getConnection();
System.out.println(connection.getClass());
//System.out.println("连接成功!");
connection.close();
}
long end = System.currentTimeMillis();
//druid 连接池 操作5000 耗时=1057ms
System.out.println("druid 连接池 操作 500000 耗时=" + (end- start));//539
} 简单测试性能:druid 连接池 操作 500000 耗时=6581ms
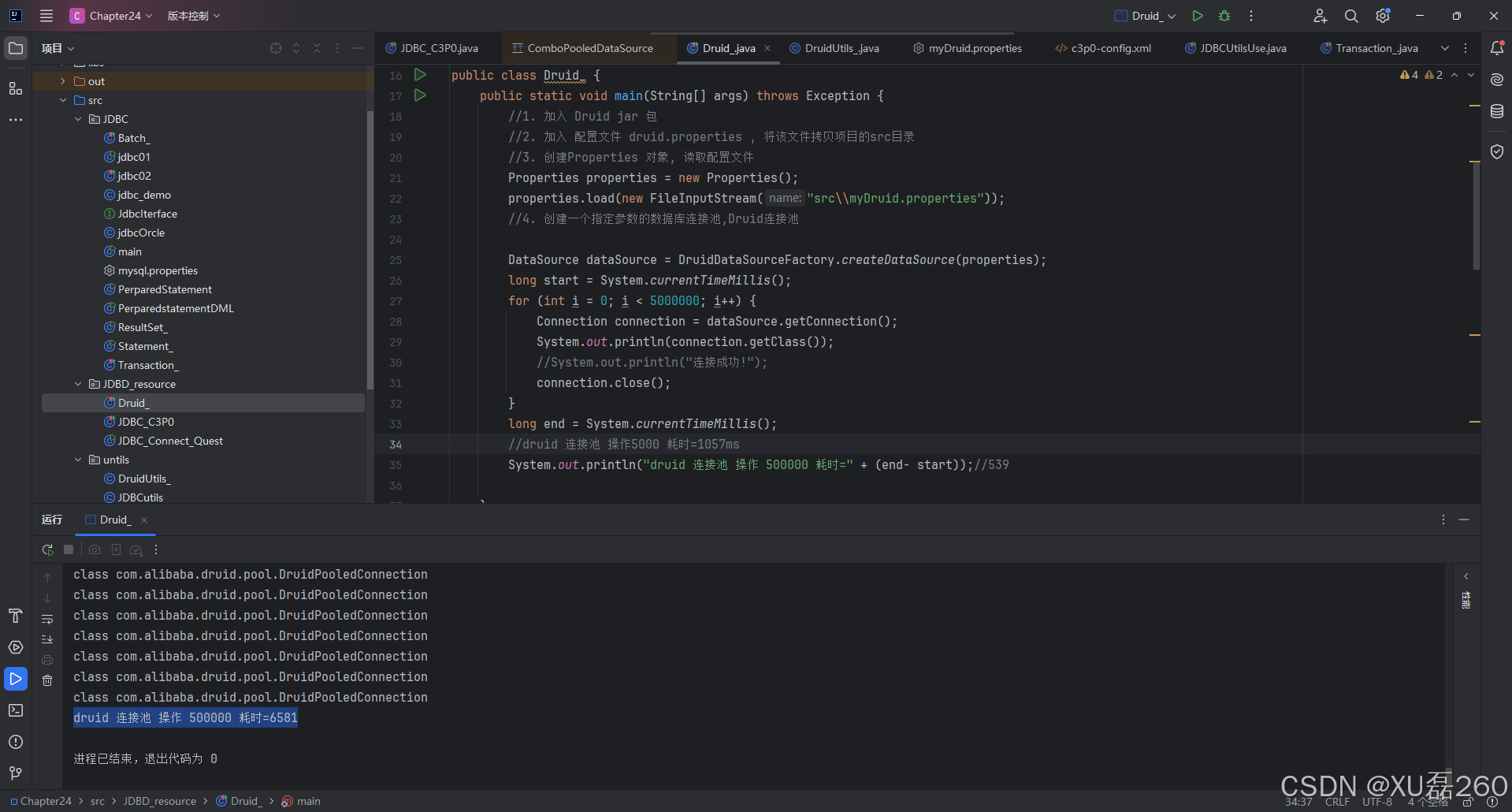
对比C3P0 耗时=1021:
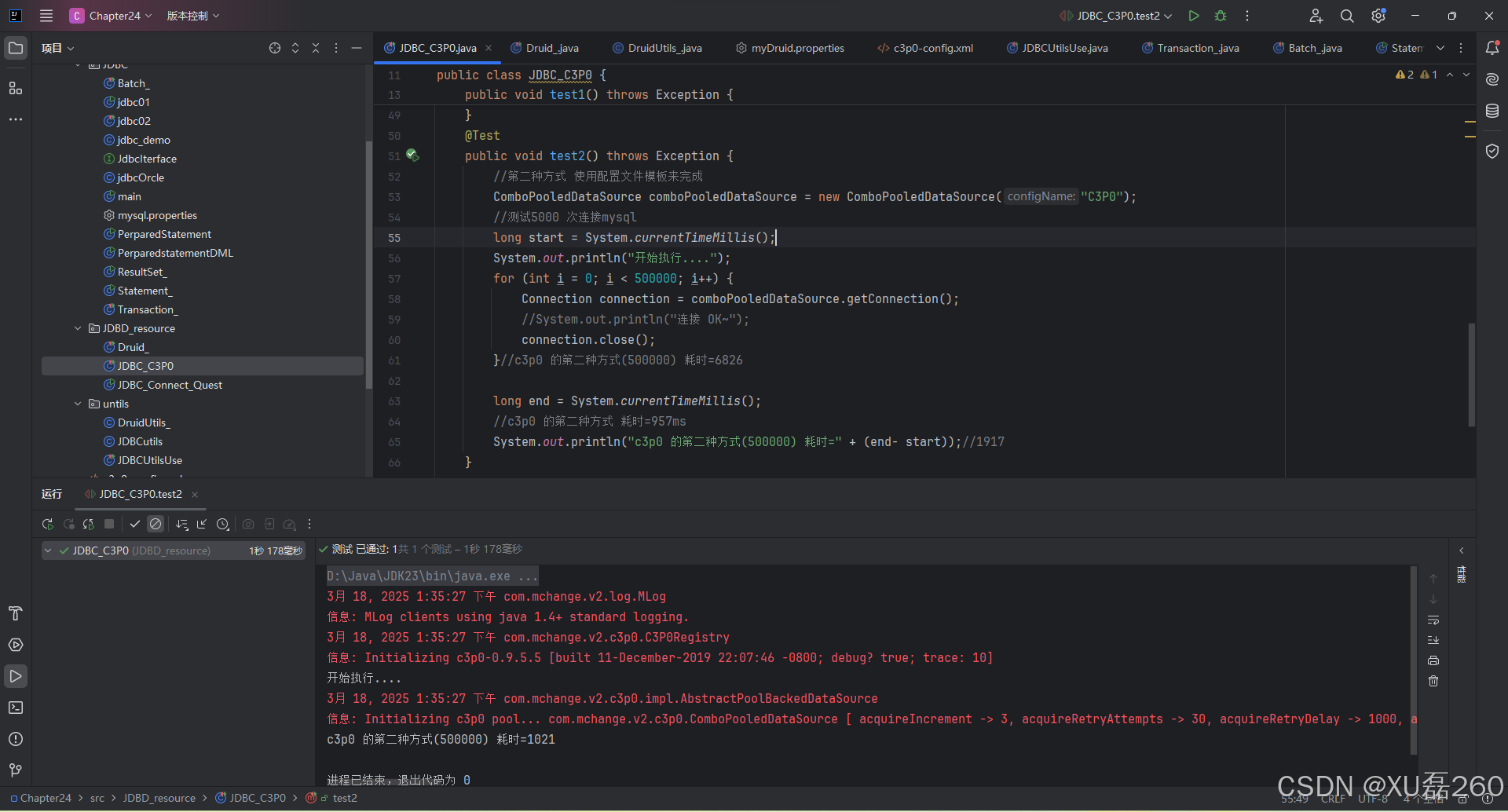
5. 总结
Druid 连接池凭借其高性能、强大的监控功能和丰富的扩展性,成为企业级应用中的首选数据库连接池。通过合理的配置和优化,可以显著提升系统的性能和稳定性。希望本文的内容能帮助您更好地理解和使用 Druid 连接池。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











