




本地私有化部署deepseek+ragflow解析文档速度慢、卡顿、失败,严重影响本地私有化部署的进度。我在局域网内的服务器部署,解决方案如下:
服务器硬件配置:
cpu: 12th Gen Intel(R) Core(TM) i7-12700K(20核)
内存:32G
显卡(GPU): GA104GL [RTX A4000]
我部署的模型是:ollama run deepseek-r1:14b
批量解析文档时,经常解析失败:
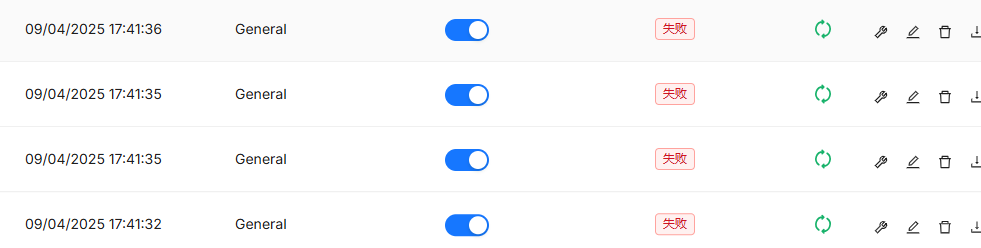
网上搜了一圈,照着改了一些参数,修改容器的运行内存为24G,ragflow路径+ragflow/docker/.evn:
MEM_LIMIT=206158430208
重新运行容器
#停止并删除容器,但是不移除与宿主机的挂载
docker-compose -f docker-compose-gpu.yml down
#启动容器
docker-compose -f docker-compose-gpu.yml up -d
解析的成功率高了一些,但是当我第二天再同步一些文档到知识库中时,解析大部分又都失败了。
我重新调整了文档解析器:
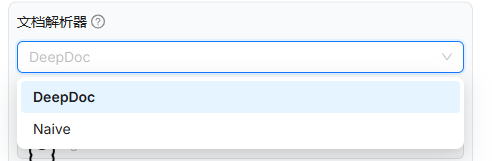
DeepDoc和Naive都分别试过,没什么改观
继续调整其他参数,去到数据集列表,把解析失败的每一文档的参数改一下
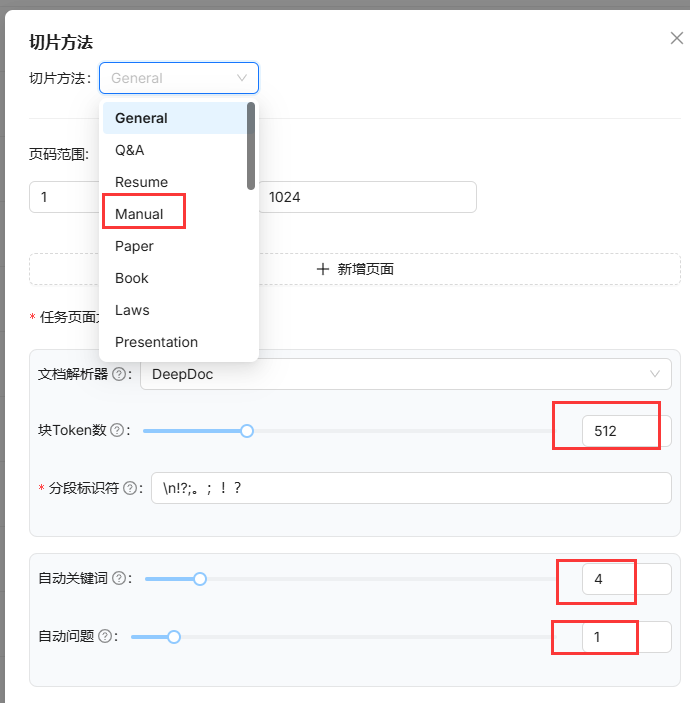
一些大的pdf,如手册类型的,解析方法改为Manual,块token根据文档大小,512或者1024,自动关键词由8改为4,自动问题由2改为1,如果还是失败,可以摆这两项都设为0,解析很快,而且我提问的时候,也能找对应的文档,但是智能体思考的过程就没有之前那么接近知识库了。



















 6804
6804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











