









#ifndef LV_PUSHBUTTON_T_H
#define LV_PUSHBUTTON_T_H
#include "lvgl/lvgl.h"
#include <string>
typedef struct
{
lv_obj_t obj;
lv_style_t style;
bool pressed;
lv_color_t backgroundColor;
std::string text;
}lv_pushbutton_t;
extern const lv_obj_class_t lv_pushbutton_class;
lv_obj_t * lv_pushbutton_create(lv_obj_t * parent);
void lv_pushbutton_set_text(lv_obj_t * obj,const char * text);
#endif // LV_PUSHBUTTON_T_H#include "lv_pushbutton_t.h"
#define MY_CLASS &lv_pushbutton_class
static void lv_pushbutton_constructor(const lv_obj_class_t * class_p, lv_obj_t * obj);
static void lv_pushbutton_destructor(const lv_obj_class_t * class_p, lv_obj_t * obj);
static void lv_pushbutton_event(const lv_obj_class_t * class_p, lv_event_t * e);
LV_FONT_DECLARE(lv_font_siyuanheiti16) //注册字体
const lv_obj_class_t lv_pushbutton_class =
{
.base_class = &lv_obj_class,
.constructor_cb = lv_pushbutton_constructor,
.destructor_cb = lv_pushbutton_destructor,
.event_cb = lv_pushbutton_event,
.width_def = LV_SIZE_CONTENT,
.height_def = LV_SIZE_CONTENT,
.group_def = LV_OBJ_CLASS_GROUP_DEF_TRUE,
.instance_size = sizeof(lv_pushbutton_t)
};
lv_obj_t * lv_pushbutton_create(lv_obj_t * parent)
{
LV_LOG_INFO("begin");
lv_obj_t * obj = lv_obj_class_create_obj(MY_CLASS, parent);
lv_obj_class_init_obj(obj);
lv_pushbutton_t * btn = (lv_pushbutton_t*)obj;
btn->pressed = false;
btn->text = "确定";
auto & style = btn->style;
lv_style_init(&style);
lv_style_set_bg_opa(&style, LV_OPA_COVER);//必不可少,否则默认控件背景不可见
lv_style_set_bg_color(&style,lv_color_hex(0xe8e8e8));
lv_style_set_text_font(&style,&lv_font_siyuanheiti16);
lv_style_set_radius(&style, 12);
lv_style_set_border_width(&style,10);
lv_style_set_border_color(&style,lv_color_hex(0x33dd33));
lv_style_set_border_opa(&style,LV_OPA_50);
lv_obj_add_style(obj, &style, LV_PART_MAIN);
return obj;
}
static void lv_pushbutton_constructor(const lv_obj_class_t * class_p, lv_obj_t * obj)
{
LV_UNUSED(class_p);
LV_TRACE_OBJ_CREATE("begin");
LV_TRACE_OBJ_CREATE("finished");
}
static void lv_pushbutton_destructor(const lv_obj_class_t * class_p, lv_obj_t * obj)
{
LV_UNUSED(class_p);
LV_TRACE_OBJ_CREATE("begin");
LV_TRACE_OBJ_CREATE("finished");
}
static void lv_pushbutton_event(const lv_obj_class_t * class_p, lv_event_t * e)
{
LV_UNUSED(class_p);
lv_res_t res = lv_obj_event_base(MY_CLASS, e);
if(res != LV_RES_OK)
return;
lv_event_code_t code = lv_event_get_code(e);
lv_obj_t * obj = lv_event_get_target(e);
if(code == LV_EVENT_REFR_EXT_DRAW_SIZE) {
lv_coord_t * s = (lv_coord_t *)lv_event_get_param(e);
*s = LV_MAX(*s, 20);
}
else if(code == LV_EVENT_DRAW_MAIN)
{
lv_pushbutton_t * btn = (lv_pushbutton_t*)obj;
lv_draw_rect_dsc_t rect_dsc;
lv_draw_rect_dsc_init(&rect_dsc);
lv_obj_init_draw_rect_dsc(obj, LV_PART_MAIN, &rect_dsc);//用obj的 LV_PART_MAIN 样式属性初始化 rect_dsc
if(btn->pressed)
{
rect_dsc.bg_color = lv_color_mix(rect_dsc.bg_color, lv_color_black(), 200);
}
const lv_area_t * clip_area = (const lv_area_t *)lv_event_get_param(e);
const auto & area = obj->coords;
lv_obj_draw_part_dsc_t part_draw_dsc;
lv_obj_draw_dsc_init(&part_draw_dsc, clip_area);
part_draw_dsc.class_p = &lv_obj_class;
part_draw_dsc.rect_dsc = &rect_dsc;
part_draw_dsc.part = LV_PART_MAIN;
lv_draw_rect(&area, clip_area, &rect_dsc);
const char * text = btn->text.c_str();
lv_point_t txt_size;
lv_txt_get_size(&txt_size, text,
lv_obj_get_style_text_font(obj, LV_PART_MAIN),
lv_obj_get_style_text_letter_space(obj, LV_PART_MAIN),
0,
LV_COORD_MAX, LV_TEXT_FLAG_NONE);
lv_area_t txt_coords;
txt_coords.x1 = area.x1 + (area.x2 - area.x1 - txt_size.x) / 2;
txt_coords.y1 = area.y1 + (area.y2 - area.y1 - txt_size.y) / 2;
txt_coords.x2 = txt_coords.x1 + txt_size.x;
txt_coords.y2 = txt_coords.y1 + txt_size.y;
lv_draw_label_dsc_t label_dsc;
lv_draw_label_dsc_init(&label_dsc);
lv_obj_init_draw_label_dsc(obj, LV_PART_MAIN, &label_dsc);
lv_draw_label(&txt_coords, clip_area, &label_dsc, text, NULL);
}
else if(code == LV_EVENT_PRESSED)
{
lv_pushbutton_t * btn = (lv_pushbutton_t*)obj;
btn->pressed = true;
lv_obj_invalidate(obj);
}
else if(code == LV_EVENT_RELEASED)
{
lv_pushbutton_t * btn = (lv_pushbutton_t*)obj;
btn->pressed = false;
lv_obj_invalidate(obj);
}
}
void lv_pushbutton_set_text(lv_obj_t *obj, const char *text)
{
LV_ASSERT_OBJ(obj, MY_CLASS);
lv_pushbutton_t * btn = (lv_pushbutton_t*)obj;
btn->text = text;
}使用:
#include "lv_pushbutton_t.h"
int main(int argc, char **argv)
{
lv_init();
hal_init();
lv_log_register_print_cb(esp32_log_cb);
{
lv_obj_t * obj = lv_pushbutton_create(lv_scr_act());
lv_obj_set_size(obj, 200, 100);
lv_obj_center(obj);
lv_pushbutton_set_text(obj,"一个按钮");
}
while (1)
{
lv_timer_handler();
usleep(5 * 1000);
}
return 0;
}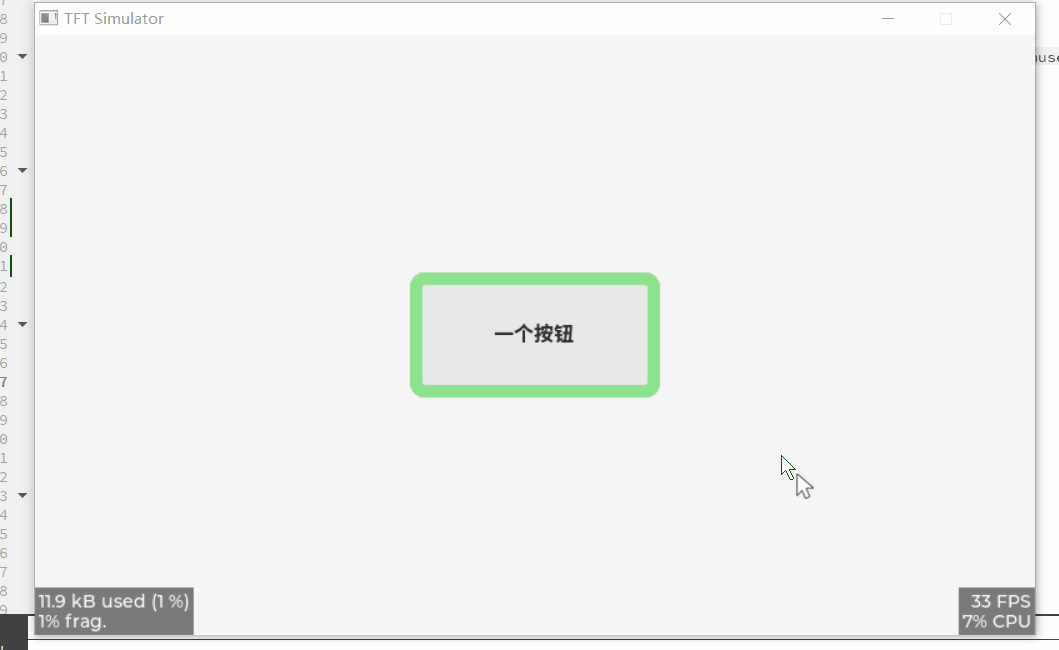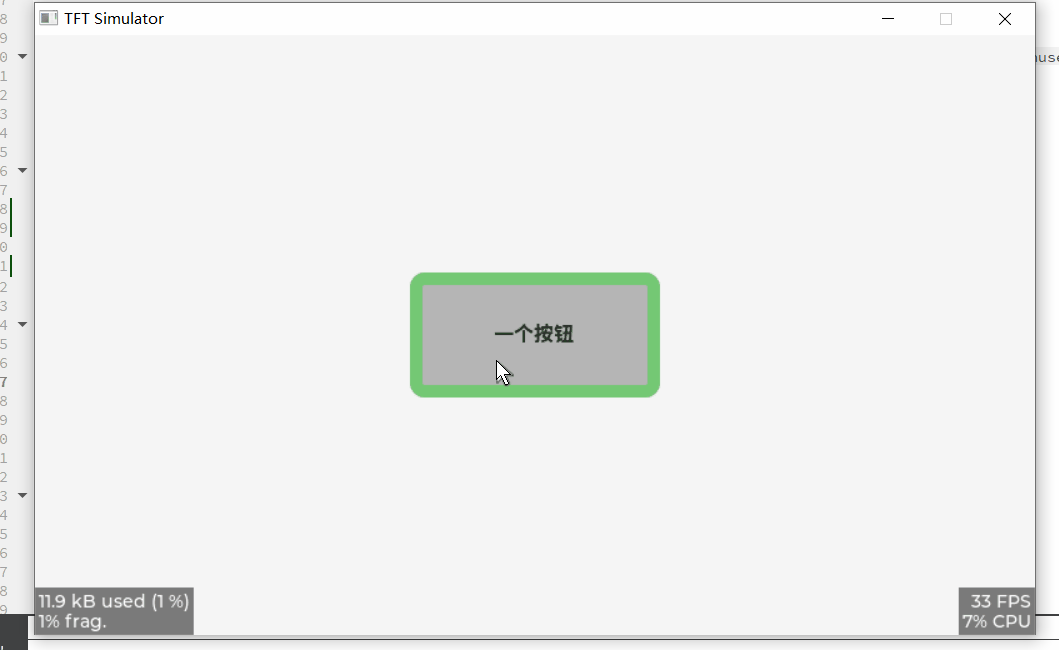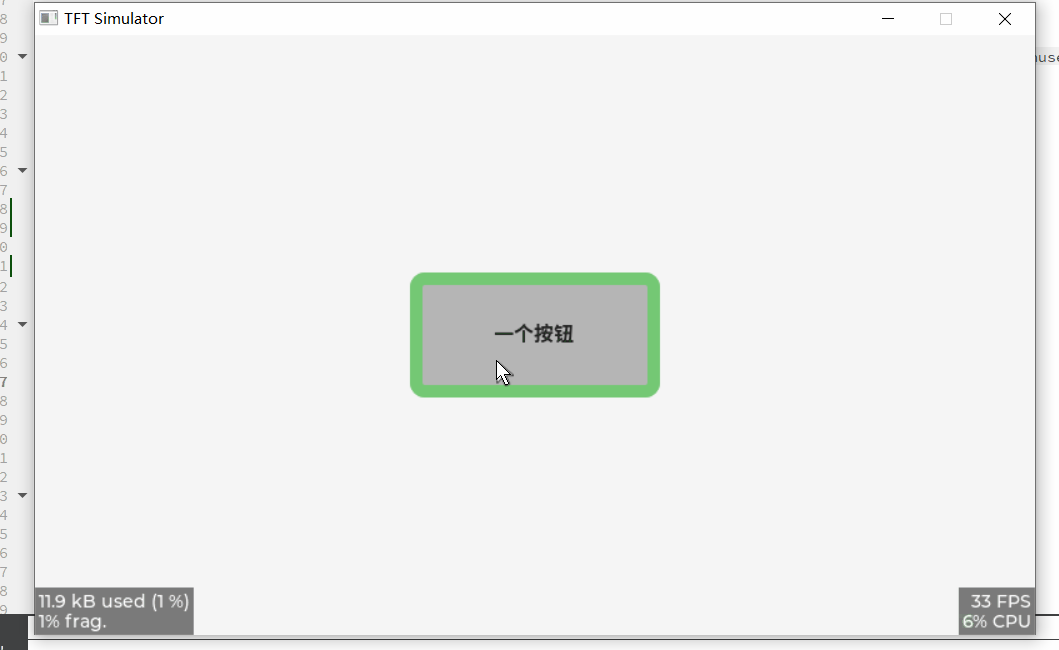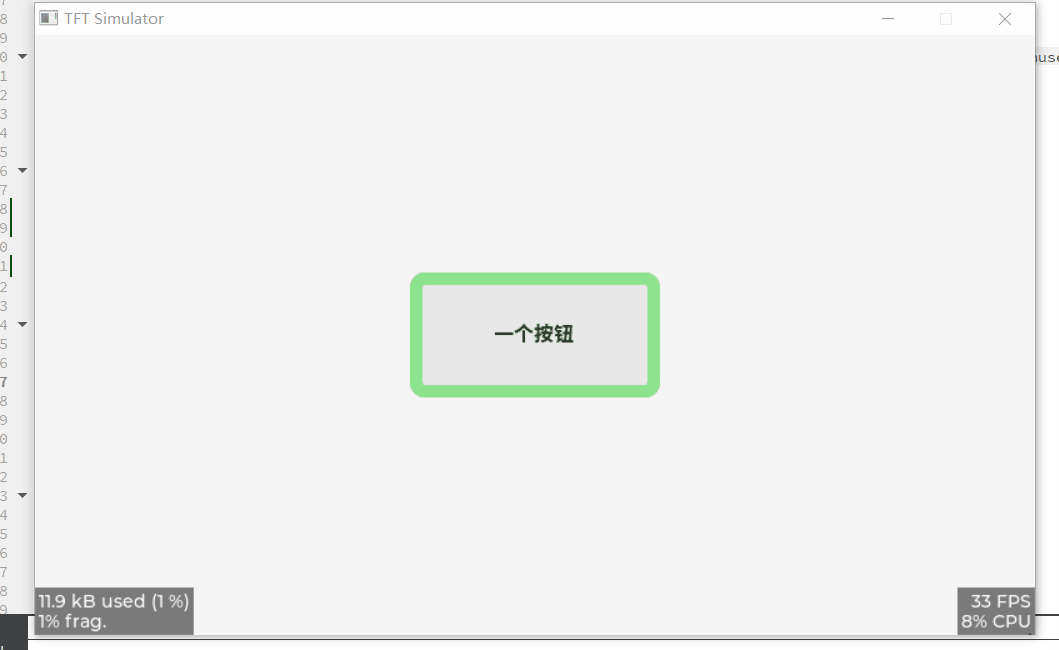
这仍可以使用样式配置:
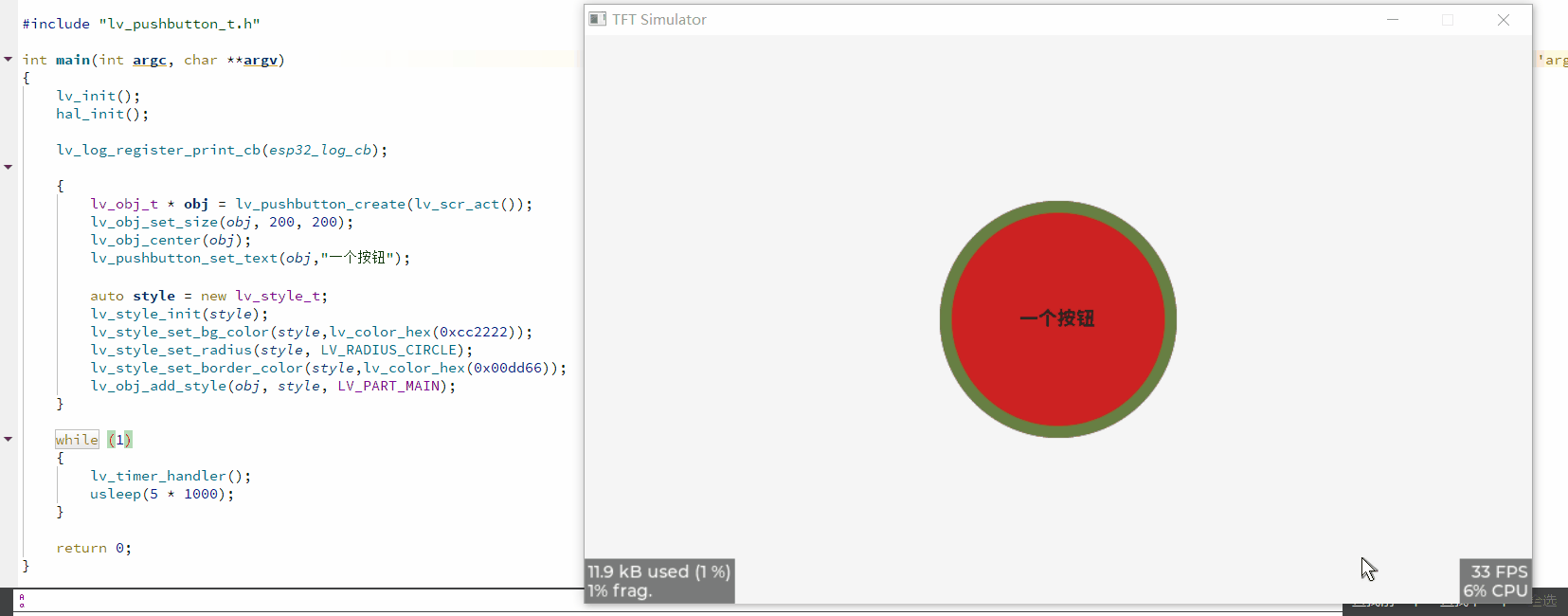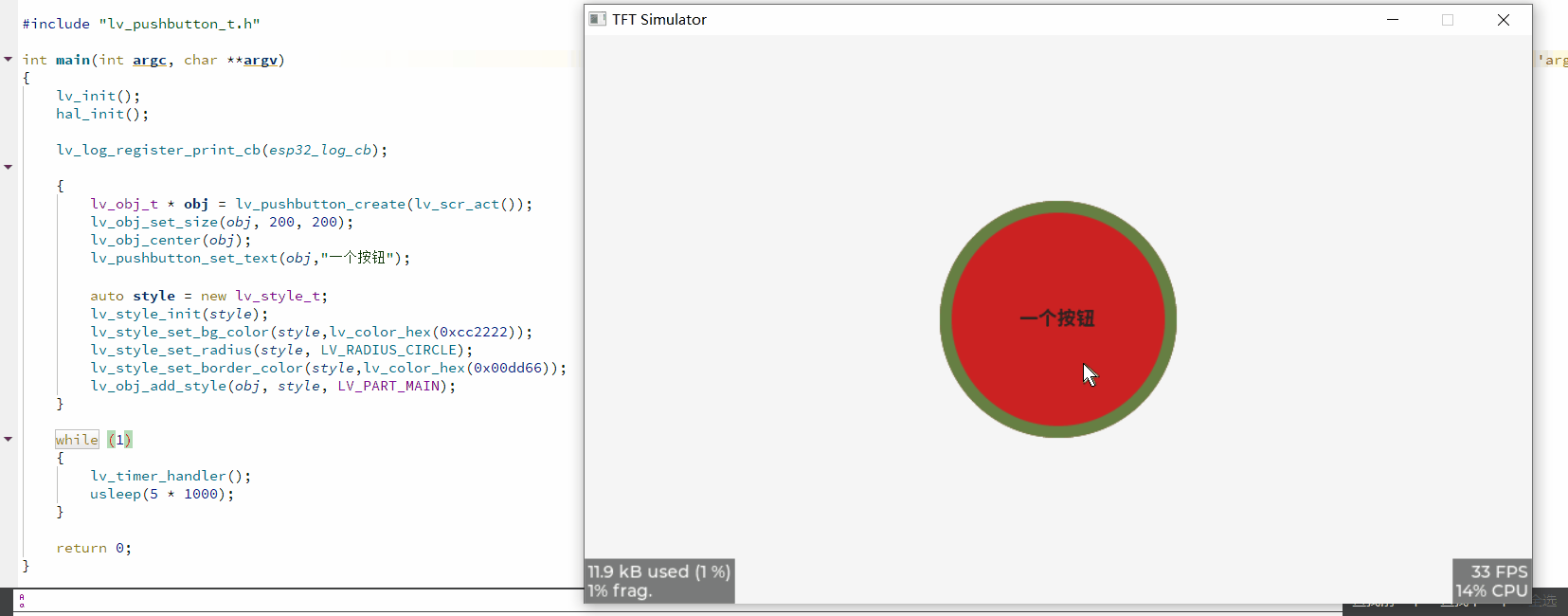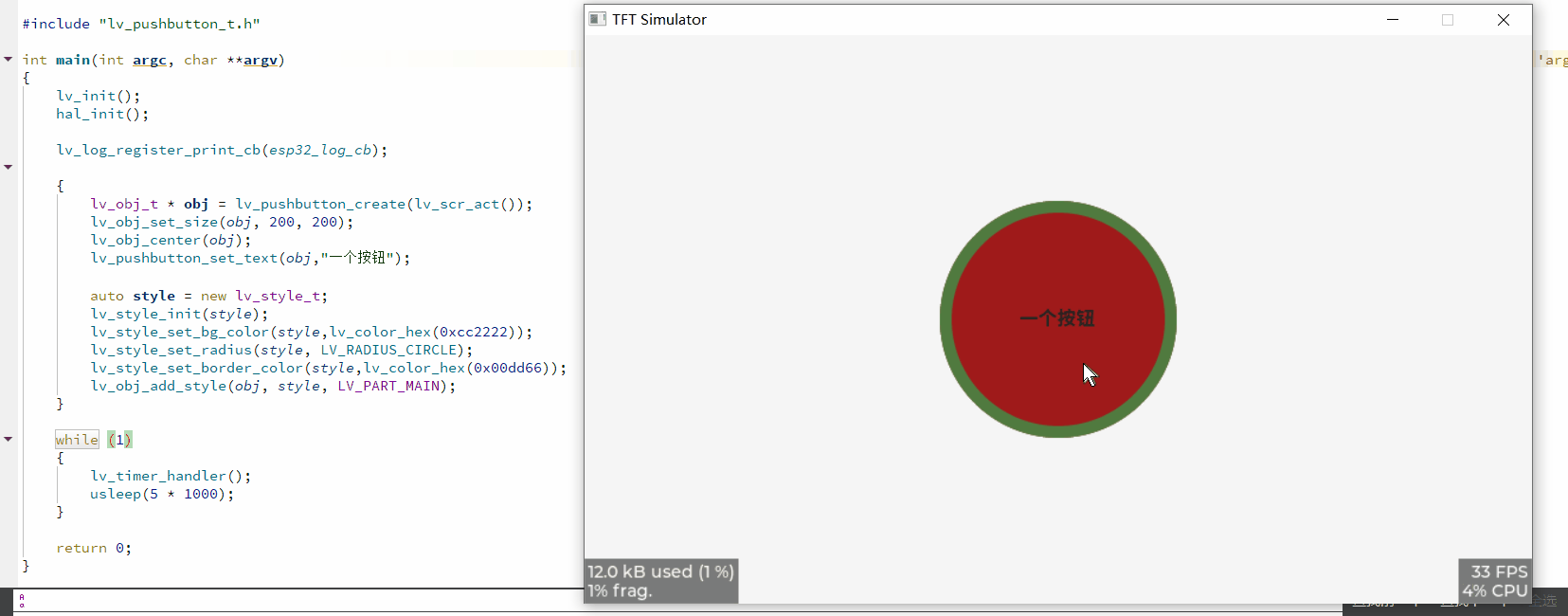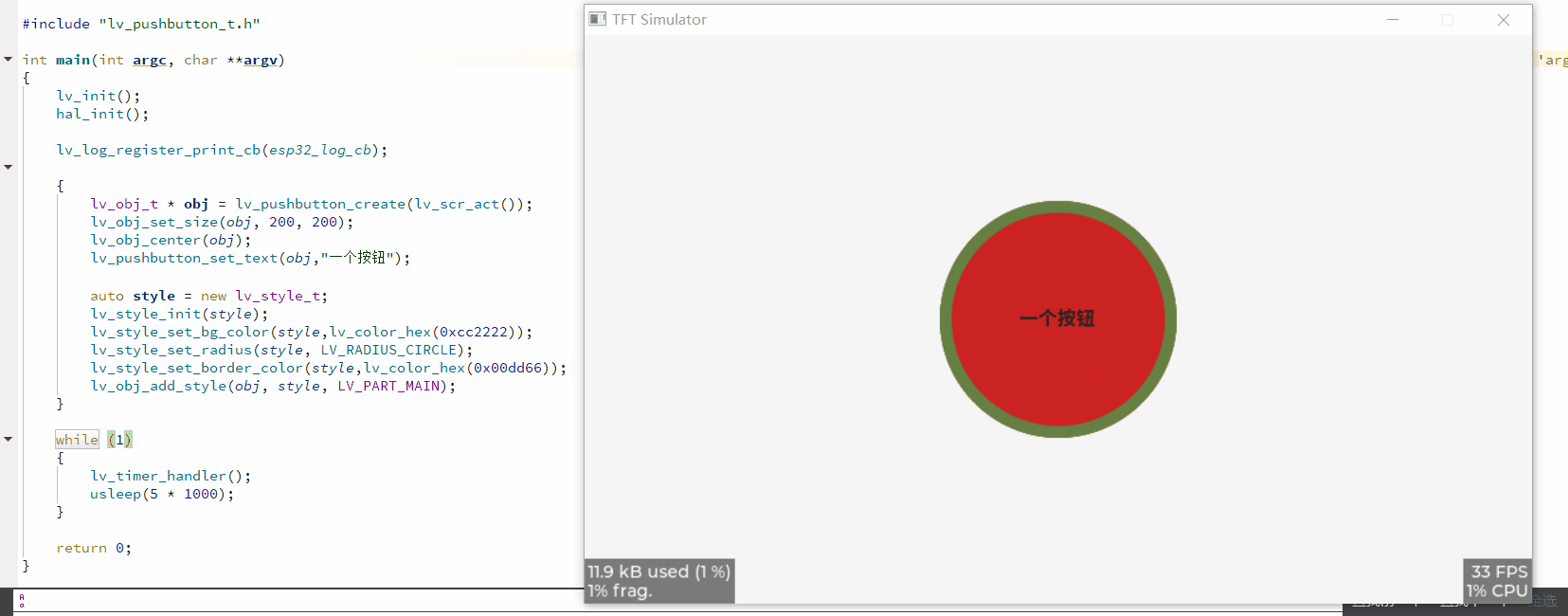

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









