




 本文介绍了Linux内核对分区块存储的支持,特别是针对文件系统的集成。文章详细讲解了zonefs、f2fs、Btrfs等文件系统如何处理分区存储,包括磁盘元数据、区域类型、IO错误处理和挂载选项。zonefs是一个简单的文件系统,直接支持分区块设备,而f2fs和Btrfs通过优化设计适应顺序写入约束。文章还探讨了这些文件系统在主机管理的SMR HDD和NVMe ZNS SSD上的应用实例。
本文介绍了Linux内核对分区块存储的支持,特别是针对文件系统的集成。文章详细讲解了zonefs、f2fs、Btrfs等文件系统如何处理分区存储,包括磁盘元数据、区域类型、IO错误处理和挂载选项。zonefs是一个简单的文件系统,直接支持分区块设备,而f2fs和Btrfs通过优化设计适应顺序写入约束。文章还探讨了这些文件系统在主机管理的SMR HDD和NVMe ZNS SSD上的应用实例。
Zoned Storage-Linux Kernel Support之文件系统
文件系统
dm-zoned device-mapper 目标可以使用任何带有主机管理的分区块设备的文件系统。 它通过隐藏设备的顺序写入约束来做到这一点。 这个解决方案很简单,并且可以使用文件系统,但它在基于块的区域回收过程中潜在的高开销意味着这不是最有效的解决方案。
其实现直接支持分区块设备的文件系统具有更有效的zone-reclamation区域回收处理。 这是因为直接支持分区块设备的文件系统具有元数据和文件抽象,与采用基于 dm-zoned-block 的方法的文件系统相比,它们提供了有关存储块的使用和有效性的更多信息。
一些文件系统的设计方式使其能够很好地适应主机管理的分区块设备的顺序写入约束。 日志结构文件系统(例如 f2fs)和写时复制 (CoW) 文件系统(例如 Btrfs)就是这种情况。
zonefs
zonefs 是一个非常简单的文件系统,它将zoned块设备的每个zone公开为一个file。 zonefs 自 5.6.0 版以来已包含在Linux 内核中。
zonefs 不会向用户隐藏zoned块设备的顺序写入约束。 在这方面,它不同于具有本地zoned块设备支持(例如 f2fs)的常规 POSIX 兼容文件系统。 表示设备上顺序写入区域的文件必须从文件末尾开始顺序写入(这些是“append only”写入)。
因此 zonefs 更类似于原始块设备访问接口,而不是功能齐全的 POSIX 文件系统。 zonefs 的目标是简化应用程序中zoned块设备支持的实现,它旨在通过用更丰富的常规文件 API 替换原始块设备文件访问来做到这一点(避免依赖可能更晦涩和对开发人员不友好的 直接块设备文件 ioctls)。 这种方法的一个例子是在zoned块设备上实现 LSM(日志结构化合并)树结构(例如在 RocksDB 和 LevelDB 中使用):SSTables 以类似于常规的方式存储在一个zone文件中 , 文件系统不是作为整个磁盘的一些扇区工作的。 引入更高级别的构造“one file is one zone”可以减少应用程序所需的更改次数,并且还引入了对不同应用程序编程语言的支持。
代表区域的文件按区域类型分组,这些区域类型本身由子目录表示。 此文件结构完全使用设备提供的zone信息构建,因此不需要任何复杂的磁盘元数据结构。
磁盘元数据
zonefs 磁盘元数据仅由一个immutable不可变的超级块组成,该块永久存储一个magic数和可选的功能标志和值。 在挂载时,zonefs 使用块层 API 函数 blkdev_report_zones() 来获取设备区域配置,并使用仅基于此信息的静态文件树填充挂载点。 文件大小来自设备zone类型和写指针位置,两者都由设备本身管理。 zonefs 仅根据来自设备的信息运行。 zonefs 没有任何自己的元数据。
超级块总是写入磁盘的第 0 扇区。存储超级块的设备的第一个zone永远不会被 zonefs 公开为 zone file。 如果包含超级块的区域是顺序区域,则 mkzonefs 格式工具始终“FINISH”该区域(即,它将区域转换为完整状态以使其只读,防止任何数据写入)。
区域类型子目录
代表相同类型区域的文件被组合在同一个子目录下,该子目录在挂载时自动创建。
对于常规区域,使用子目录“cnv”。 仅当设备具有可用的常规区域时才会创建此目录。 如果设备在扇区 0 只有一个常规区域,则该区域不会作为文件公开(因为它将用于存储 zonefs 超级块)。 对于此类设备,不会创建“cnv”子目录。
对于顺序写入区域,使用子目录“seq”。
这两个目录是 zonefs 中唯一存在的目录。 用户不能创建其他目录,也不能重命名或删除“cnv”和“seq”子目录。
目录的大小表示目录下存在的文件数。 此大小由 struct stat 的 st_size 字段指示,该字段是通过 stat() 或 fstat() 系统调用获得的。
区域文件
区域文件使用它们在特定类型的区域集中表示的区域编号来命名。 “cnv”和“seq”目录都包含名为“0”、“1”、“2”、…的文件。文件编号也代表设备上增加的区域起始扇区。
不允许对区域文件进行超出文件最大大小(即超出区域大小)的读写操作。 任何超过区域大小的访问都会失败并出现 -EFBIG 错误。
不允许创建、删除、重命名和修改文件的任何属性。
stat() 和 fstat() 报告的文件块数表示文件zone的大小(即最大文件大小)。
-
常规区域文件
常规区域文件的大小固定为它们所代表的区域的大小。 不能截断常规区域文件。可以使用任何类型的 I/O 操作随机读取和写入这些文件:缓冲 I/O、直接 I/O、内存映射 I/O (mmap) 等。这些文件除了 上面提到的文件大小限制。
-
顺序区域文件
分组在“seq”子目录中的顺序区域文件的大小表示文件的区域写入指针相对于区域起始扇区的位置。顺序区域文件只能顺序写入,从文件末尾开始(即写入操作只能是“追加写入”)。 zonefs 不会尝试接受随机写入,并且将失败任何具有与文件末尾不对应的开始偏移量的写入请求,或者与发出的最后一次写入的末尾不对应并且仍在进行中(对于异步 I/O 操作)。
因为页面缓存的脏页写回不能保证顺序写入模式,所以 zonefs 会阻止缓冲写入和顺序文件上的可写共享映射。 这些文件只接受直接 I/O 写入。 zonefs 依赖于将写入 I/O 请求顺序传递到由块层电梯实现的设备(请参阅写入命令排序)。
对于顺序区域文件中用于读取操作的 I/O 类型没有限制。 缓冲 I/O、直接 I/O 和共享读取映射都被接受。
仅允许截断顺序区域文件到 0,在这种情况下,区域被重置以将文件区域写入指针位置倒回到区域的开头,或者直到区域大小,在这种情况下,文件的区域将转换为 FULL 状态(完成区域操作)。
格式选项
zonefs 的几个可选功能可以在格式化时启用。
- 常规区域聚合:连续的常规区域范围可以聚合到一个更大的文件中,而不是默认的“每个区域一个文件”。
- 文件所有者:默认情况下,区域文件的所有者 UID 和 GID 为 0(根),但可以更改为任何有效的 UID/GID。
- 文件访问权限:可以更改默认访问权限(640)。
IO错误处理
分区块设备可能会导致 I/O 请求失败,原因类似于常规块设备失败 I/O 请求的原因,例如 如果有坏扇区。 但管理分区块设备行为的标准还定义了可能导致 I/O 错误的其他条件(除了这些已知的 I/O 故障模式)。
- 一个区域可能会转变为只读状态:虽然已经写入该区域的数据仍然可读,但该区域不能再被写入。 对区域的任何用户操作(区域管理命令或读/写访问)都不能将区域条件更改回正常的读/写状态。 虽然标准没有定义设备将区域转换为只读状态的原因,但这种转换的典型原因是 HDD 上的写入磁头有缺陷(此磁头下的所有区域都更改为只读)
- 一个区域可能会转变为离线状态:一个离线区域既不能被读取也不能被写入。 任何用户操作都不能将脱机区域转换回可操作的“良好状态”。 与区域只读转换类似,驱动器将区域转换为离线状态的原因是不确定的。 一个典型的原因是(例如)HDD 上有缺陷的读写头,导致损坏的磁头下方的盘片上的所有区域都无法访问。
- 未对齐的写入错误:这些错误是由于设备接收到的写入请求的起始扇区与目标区域的写入指针位置不对应。 尽管 zonefs 对顺序区域强制执行顺序文件写入,但在拆分为多个 BIO/请求或异步 I/O 操作的非常大的直接 I/O 操作部分失败的情况下,仍然可能发生未对齐的写入错误。 如果向设备发出的一组顺序写入请求中的一个写入请求失败,则在它之后排队的所有写入请求将变得未对齐并失败。
- 延迟写入错误:与常规块设备一样,如果启用了设备端写入缓存,则在刷新设备写入缓存时,可能会在先前完成的写入范围内发生写入错误,例如 在 fsync() 上。 与立即未对齐写入错误的情况一样,延迟写入错误可以通过区域的缓存顺序数据流传播,这可能导致导致错误的扇区之后的所有数据被丢弃。
zonefs 检测到的所有 I/O 错误都会报告给用户,并为触发或检测到错误的系统调用返回一个错误代码。 zonefs 为响应 I/O 错误而采取的恢复操作取决于 I/O 类型(读取与写入)和错误原因(坏扇区、未对齐写入或区域条件更改)。
- 对于读取 I/O 错误,仅当文件区域仍处于良好状态并且文件 inode 大小与其区域写入指针位置之间没有不一致时,zonefs 才会采取恢复操作。 如果检测到问题,则执行 I/O 错误恢复(见下表)。
- 对于写 I/O 错误,总是执行 zonefs I/O 错误恢复。
- 区域条件更改为“只读”或“离线”也总是会触发 zonefs I/O 错误恢复。
zonefs 最小 I/O 错误恢复可以更改文件的大小及其文件访问权限。
- 文件大小更改:顺序区域文件中的即时或延迟写入错误会导致文件 inode 大小与成功写入文件区域的数据量不一致。 例如,multi-BIO 大写操作的部分失败将导致区域写指针部分前进,即使整个写操作向用户报告为失败。 在这种情况下,文件 inode 大小必须提前以反映区域写入指针的变化,并最终允许用户在文件末尾重新开始写入。 文件大小也可以减小以反映在 fsync() 上检测到的延迟写入错误:在这种情况下,有效写入区域的数据量可能小于文件 inode 大小最初指示的数据量。 在任何此类 I/O 错误之后,zonefs 总是修复文件 inode 大小以反映持久存储在文件区域中的数据量。
- 访问权限更改:文件访问权限的更改指示区域条件更改为只读,从而使文件变为只读。 这将禁用对文件属性的更改和数据修改。 对于离线区域,文件的所有权限(读取和写入)都被禁用。
用户可以使用“errors=xxx”挂载选项控制 zonefs I/O 错误恢复采取的进一步操作。 下图总结了 zonefs I/O 错误处理的结果,具体取决于挂载选项和区域条件。
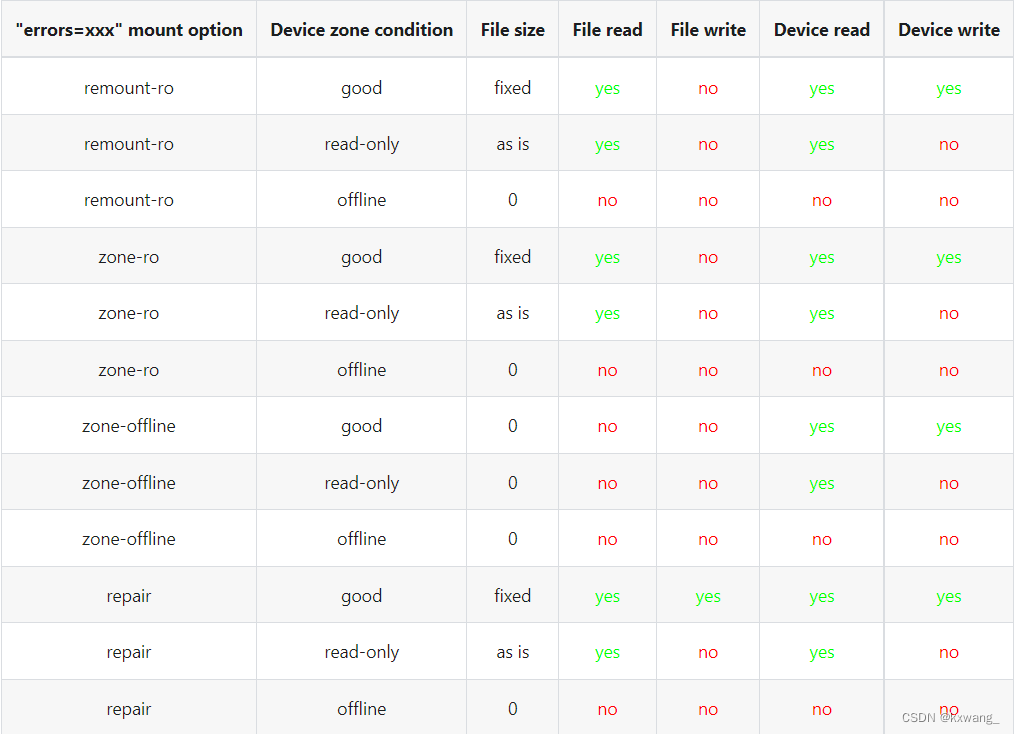
- 如果未指定错误挂载选项,则“errors=remount-ro”挂载选项是 zonefs I/O 错误处理的默认行为。
- 使用“errors=remount-ro”挂载选项,将文件访问权限更改为“只读”适用于所有文件。 文件系统以只读方式重新挂载。
- 由设备将区域转换为离线状态导致的访问权限和文件大小更改是永久性的。 使用 mkfs.zonefs (mkzonefs) 重新安装或重新格式化设备不会将离线区域文件更改回良好状态。
- 由于设备将区域转换为只读条件而导致的所有文件访问权限更改为只读的都是永久性的。 重新安装或重新格式化设备不会重新启用文件写入访问。
- “remount-ro”、“zone-ro”和“zone-offline”挂载选项隐含的文件访问权限更改对于处于良好状态的区域是临时的。 卸载和重新安装文件系统会恢复对受影响文件的先前默认(格式化时间值)访问权限。
- 修复装载选项仅触发最小的 I/O 错误恢复操作集(即,对处于良好状态的区域进行文件大小修复)。 被设备指示为“只读”或“离线”的区域仍然意味着对区域文件访问权限的更改,如上表所述。
挂载选项
zonefs 定义了“errors=behavior”挂载选项,以允许用户指定 zonefs 行为以响应 I/O 错误、inode 大小不一致或区域条件更改。 定义的行为如下。
- remount-ro (default)
- zone-ro
- zone-offline
- repair
为每个行为定义的运行时 I/O 错误操作在 IO 错误处理中有详细说明。 挂载时 I/O 错误会导致挂载操作失败。
只读区域在挂载时的处理方式与运行时不同。 如果在挂载时发现只读区域,则始终以与脱机区域相同的方式处理该区域(即禁用所有访问并将区域文件大小设置为 0)。 这是必要的,因为只读区域的写指针被 ZBC 和 ZAC 标准定义为无效(这使得无法发现已写入区域的数据量)。 对于在运行时发现的只读区域,如 IO 错误处理中所示,区域文件的大小与其上次更新的值保持不变。
Zonefs 用户空间工具
mkzonefs 工具用于格式化分区块设备以与 zonefs 一起使用。 该工具在 GitHub 上可用。
zonefs-tools 还包括一个可以针对任何分区块设备运行的测试套件,包括使用分区模式创建的 nullblk 块设备。
例子
以下命令列表格式化具有 256 MB 区域的 15TB 主机管理的 SMR HDD(启用了常规区域聚合功能):
# mkzonefs -o aggr_cnv /dev/sdX
# mount -t zonefs /dev/sdX /mnt
# ls -l /mnt/
total 0
dr-xr-xr-x 2 root root 1 Nov 25 13:23 cnv
dr-xr-xr-x 2 root root 55356 Nov 25 13:23 seq
区域文件子目录的大小表示每种区域存在的文件数量。 在此示例中,只有一个常规区域文件(所有常规区域都聚合在一个文件下):
# ls -l /mnt/cnv 总计 137101312 -rw-r----- 1 root root 140391743488 Nov 25 13:23 0
这个聚合的常规区域文件可以用作常规文件:
# mkfs.ext4 /mnt/cnv/0
# mount -o loop /mnt/cnv/0 /data
“seq”子目录为顺序写入区域分组文件,在此示例中具有 55356 个区域:
# ls -lv /mnt/seq 总计 14511243264 -rw-r----- 1 root root 0 Nov 25 13:23 0 -rw-r----- 1 root root 0 Nov 25 13:23 1 -rw -r----- 1 根根 0 Nov 25 13:23 2 ...
-rw-r----- 1 根根 0 Nov 25 13:23 55354 -rw-r----- 1 根根 0 Nov 25 13:23 55355
对于顺序写入区域文件,文件大小会随着文件末尾附加数据而改变。 这类似于任何常规文件系统的行为:
# dd if=/dev/zero of=/mnt/seq/0 bs=4096 count=1 conv=notrunc oflag=direct
1+0 records in
1+0 records out
4096 bytes (4.1 kB, 4.0 KiB) copied, 0.00044121 s, 9.3 MB/s
# ls -l /mnt/seq/0
-rw-r----- 1 root root 4096 Nov 25 13:23 /mnt/seq/0
写入的文件可以被截断为区域大小,从而防止任何进一步的写入操作:
# truncate -s 268435456 /mnt/seq/0
# ls -l /mnt/seq/0
-rw-r----- 1 root root 268435456 Nov 25 13:49 /mnt/seq/0
截断为 0 大小允许释放文件区域存储空间并重新启动对文件的追加写入:
# truncate -s 0 /mnt/seq/0
# ls -l /mnt/seq/0
-rw-r----- 1 root root 0 Nov 25 13:49 /mnt/seq/0
由于文件静态映射到磁盘上的区域,因此 stat() 和 fstat() 报告的文件块数表示文件区域的大小:
# stat /mnt/seq/0
File: /mnt/seq/0
Size: 0 Blocks: 524288 IO Block: 4096 regular empty file
Device: 870h/2160d Inode: 50431 Links: 1
Access: (0640/-rw-r-----) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-11-25 13:23:57.048971997 +0900
Modify: 2019-11-25 13:52:25.553805765 +0900
Change: 2019-11-25 13:52:25.553805765 +0900
Birth: -
以 512B 块为单位的文件块数(“块”)给出了最大文件大小 524288 * 512 B = 256 MB,这对应于本示例中的设备区域大小。 请注意,“IO 块”字段始终指示写入的最小 I/O 大小,并且它对应于设备的物理扇区大小。
f2fs
Flash 友好文件系统 (f2fs) 是在日志结构文件系统方法的基础上设计的,但经过修改以避免传统日志结构方法的经典问题(例如“流浪树”的雪球效应和 高“清洁开销”)。
f2fs 支持各种参数,不仅用于配置磁盘布局,还用于选择分配和清理算法。
分区块设备支持
分区块设备支持已添加到内核 4.10 的 f2fs。 由于 f2fs 使用具有固定块位置的磁盘元数据块格式,因此仅支持包含常规区域的分区块设备。 完全由顺序区域组成的分区设备不能与 f2fs 一起用作独立设备,并且它们需要多设备设置才能将元数据块放置在随机可写存储上。 f2fs 支持多设备设置,其中多个块设备地址空间线性连接以形成逻辑上更大的块设备。 dm-linear 设备映射器目标还可用于创建一个逻辑设备,该设备由适用于 f2fs 的常规区域和顺序区域组成。
f2fs 分区块设备支持是使用以下原则实现的:
- Section Alignment 在 f2fs 中,section是一组固定大小的segments (2 MB)。 一个section中的segment数被确定为与分区的设备区域大小相匹配。 例如:对于 256 MB 的区域大小,一个section包含 128 个 2MB 的segment
- Forced LFS mode 默认情况下,f2fs 尝试通过允许segemenyt内的一些随机写入来优化块分配(以避免过多的追加写入)。 LFS 模式强制对segment进行顺序写入,并强制在segment内顺序使用段,从而完全符合分区块设备的写入约束。
- Zone reset as discard operation 过去,块discard(或trim)向设备指示不再使用块或块范围。 当一个部分的所有段的所有块都空闲时,这已被“区域写入指针重置”命令的执行所取代。 这允许该部分被重用。
与使用 dm-zoned 设备映射器目标的解决方案相比,f2fs 在分区设备上的性能不会受到“区域回收开销”的影响,因为写入始终是顺序的,并且不需要磁盘上的临时缓冲。 f2fs 垃圾收集(段清理)仅对频繁删除文件或修改文件数据的工作负载产生开销
区域容量支持
NVMe ZNS SSD 的每个区域容量capacity可以小于区域大小size。 为了支持 ZNS 设备,f2fs 确保块分配和记帐仅考虑区域中在区域容量内的块。 这种对 NVMe ZNS 区域容量的支持自从在 Linux 内核版本 5.10 中引入以来一直可用。
f2fs 卷需要一些可随机写入的存储空间,以便为卷存储和更新就地元数据块。 由于 NVMe 分区命名空间没有常规区域,因此 f2fs 卷不能自包含在单个 NVMe 分区命名空间中。 要使用 NVMe 分区命名空间格式化 f2fs 卷,必须使用多设备卷格式,以便提供额外的常规块设备来存储卷元数据块。 这个额外的常规块设备可以是同一 NVMe 设备上的常规命名空间,也可以是另一个 NVMe 设备上的常规命名空间。
限制
f2fs 使用 32 位块编号,块大小为 4 KB。 这导致最大卷大小为 16 TB。 总容量大于 16 TB 的任何设备或设备组合(对于多设备卷)都不能与 f2fs 一起使用。
为了克服这个限制,dm-linear 设备映射器目标可用于将分区块设备划分为可服务的更小的逻辑设备。 此配置必须确保为创建的每个逻辑设备分配足够数量的常规区域来存储 f2fs 固定位置元数据块。
主机管理的 SMR HDD 的使用示例
以 512B 块为单位的文件块数(“块”)给出了最大文件大小 524288 * 512 B = 256 MB,这对应于本示例中的设备区域大小。 请注意,“IO 块”字段始终指示写入的最小 I/O 大小,并且它对应于设备的物理扇区大小。
# mkfs.f2fs -m /dev/sdb
f2fs-tools: mkfs.f2fs Ver: 1.12.0 (2018-11-12)
Info: Disable heap-based policy
Info: Debug level = 0
Info: Trim is enabled
Info: [/dev/sdb] Disk Model: HGST HSH721415AL
Info: Host-managed zoned block device:
55880 zones, 524 randomly writeable zones
65536 blocks per zone
Info: Segments per section = 128
Info: Sections per zone = 1
Info: sector size = 4096
Info: total sectors = 3662151680 (14305280 MB)
Info: zone aligned segment0 blkaddr: 65536
Info: format version with
"Linux version 5.0.16-300.fc30.x86_64 (mockbuild@bkernel03.phx2.fedoraproject.org) (gcc version 9.1.1 20190503 (Red Hat 9.1.1-1) (GCC)) #1 SMP Tue May 14 19:33:09 UTC 2019"
Info: [/dev/sdb] Discarding device
Info: Discarded 14305280 MB
Info: Overprovision ratio = 0.600%
Info: Overprovision segments = 86254 (GC reserved = 43690)
Info: format successful
现在可以直接挂载格式化的分区块设备。 无需进一步设置:
# mount /dev/sdb /mnt
NVMe ZNS SSD 的使用示例
与 SMR 硬盘不同,默认情况下,内核不会为代表 NVMe 分区命名空间的块设备选择 mq-deadline block-IO 调度程序。 为确保 f2fs 使用的常规写入操作按顺序传递到设备,必须将 NVMe 分区命名空间块设备的 IO 调度程序设置为 mq-deadline。 这是通过以下命令完成的:
# echo mq-deadline > /sys/block/nvme1n1/queue/scheduler
在上述命令中,/dev/nvme1n1 是将用于 f2fs 卷的分区命名空间的块设备文件。 使用此命名空间,可以使用 mkfs.f2fs 的 -c 选项格式化使用附加常规块设备(以下示例中的 /dev/nvme0n1)的多设备 f2fs 卷,如下例所示:
# mkfs.f2fs -f -m -c /dev/nvme1n1 /dev/nvme0n1
F2FS-tools: mkfs.f2fs Ver: 1.14.0 (2021-06-23)
Info: Disable heap-based policy
Info: Debug level = 0
Info: Trim is enabled
Info: Host-managed zoned block device:
2048 zones, 0 randomly writeable zones
524288 blocks per zone
Info: Segments per section = 1024
Info: Sections per zone = 1
Info: sector size = 4096
Info: total sectors = 1107296256 (4325376 MB)
Info: zone aligned segment0 blkaddr: 524288
Info: format version with
"Linux version 5.13.0-rc6+ (user1@brahmaputra) (gcc (Ubuntu 10.3.0-1ubuntu1) 10.3.0, GNU ld (GNU Binutils for Ubuntu) 2.36.1) #2 SMP Fri Jun 18 16:45:29 IST 2021"
Info: [/dev/nvme0n1] Discarding device
Info: This device doesn't support BLKSECDISCARD
Info: This device doesn't support BLKDISCARD
Info: [/dev/nvme1n1] Discarding device
Info: Discarded 4194304 MB
Info: Overprovision ratio = 3.090%
Info: Overprovision segments = 74918 (GC reserved = 40216)
Info: format successful
要挂载使用上述命令格式化的卷,必须指定常规块设备:
# mount -t f2fs /dev/nvme0n1 /mnt/f2fs/
Btrfs
Btrfs 是基于写时复制 (CoW) 原则的文件系统。 这个原则的结果是没有块更新可以就地写入。 Btrfs 当前支持分区块设备,但该支持是实验性的。
Zoned Block Device Support
分区块设备支持已添加到内核 5.12 的 btrfs。 因为超级块是唯一在 btrfs 中具有固定位置的磁盘数据结构,所以分区块设备支持引入了日志结构超级块的概念,以消除固定超级块位置的就地更新(覆盖)。 分区模式保留两个连续的区域来保存 btrfs 中的每个超级块(主超级块和备份超级块)。 当一个新的超级块被写入时,它被附加到其各自的超级块区域。 在第一个超级块区域被填满后,下一个超级块被写入第二个超级块区域,并且第一个被重置。 在挂载时,btrfs 可以通过查看超级块区域的区域写入指针的位置来找到超级块的最新版本。 最新且有效的超级块始终是写指针位置之前存储的最后一个块。
Block Allocation Changes
Btrfs 块管理依赖于将块分组到块组中。 每个块组由一个或多个设备范围组成。 块组的设备范围可能属于不同的设备(例如,在 RAID 卷的情况下)。 ZBD 支持将设备范围的大小从其默认大小更改为设备区域的大小。 这可确保所有设备范围始终与区域对齐。
块组内的块分配被改变,以便分配总是从块组的开始是连续的。 为此,将分配指针添加到块组并用作分配提示。 这些更改确保在分配指针下方释放的块被忽略,这导致每个组内的顺序块分配,而不管块组的使用情况。
I/O Management
虽然分配指针的引入确保了块在组内按顺序分配(因此在区域内按顺序分配),但写出新分配的块的 I/O 操作可能会乱序发出,这可能会在写入顺序区域时导致错误 . 这个问题是通过向每个块组引入“写 I/O 请求暂存列表”来解决的。 该列表用于延迟给定块组内未对齐的写入请求的执行。
仅当块组空闲时(即,当块组中的所有块都未使用时)才重置块组的区域以允许重写。
在处理由多个磁盘组成的 btrfs 卷时,会添加限制以确保所有磁盘具有相同的区域模型(对于分区块设备,区域大小相同)。 这与现有的 btrfs 约束相匹配,该约束指示块组中的所有设备范围必须具有相同的大小。
所有对数据块组的写入都使用 Zone Append 写入,这样可以在不违反设备区域的顺序写入约束的情况下保持较高的队列深度。 对专用元数据块组的每次写入都使用文件系统全局分区元数据 I/O 锁进行序列化。
区域容量支持
NVMe ZNS SSD 的每个区域容量可以小于区域大小。 为了支持 ZNS 设备,btrfs 确保块分配和记帐仅考虑区域中在区域容量内的块。 这种对 NVMe ZNS 区域容量的支持从 Linux 内核版本 5.16 开始提供。 此外,从内核 5.16 开始,btrfs 会跟踪设备上活动区域的数量,并根据需要发出“区域完成”命令。
限制
文件系统的当前分区模式并非支持 btrfs 中当前可用的所有功能。
这些不可用的功能包括:
- RAID Support
- NOCOW Support
- Support for fallocate(2)
- Mixed data and meta-data block groups
系统要求
为了在分区块设备上使用 btrfs,必须满足以下最低系统要求:
- Linux kernel 5.12 (for SMR) or 5.16 (for NVMe ZNS)
- btrfs-progs 5.12 (for SMR) or 5.15 (for NVMe ZNS)
- util-linux 2.38
btrfs-progs 的源代码托管在 GitHub 上。
如果内核在分区块设备上支持 btrfs,默认情况下会自动选择 mq_deadline 块 IO 调度程序。 这可确保分区 btrfs 卷中使用的任何 SMR 硬盘的写入顺序正确性。
与 f2fs 与 NVMe ZNS SSD 一起使用的情况一样,必须手动设置 mq-deadline 调度程序,以确保 btrfs 使用的常规写入操作按顺序传递到设备。 对于 NVMe 分区命名空间设备 /dev/nvmeXnY,这是通过以下命令完成的:
# echo mq-deadline > /sys/block/nvmeXnY/queue/scheduler
或者,可以使用以下 udev 规则为所有已使用 btrfs 格式化的分区块设备自动设置 mq-deadline 调度程序。
SUBSYSTEM!="block", GOTO="btrfs_end"
ACTION!="add|change", GOTO="btrfs_end"
ENV{ID_FS_TYPE}!="btrfs", GOTO="btrfs_end"
ATTR{queue/zoned}=="host-managed", ATTR{queue/scheduler}="mq-deadline"
LABEL="btrfs_end"
主机管理 SMR HDD 的使用示例
要使用 mkfs.btrfs 格式化分区块设备,必须指定 -m single 和 -d single 选项,因为当前不支持“single”以外的块组配置文件。
# mkfs.btrfs -m single -d single /dev/sda
btrfs-progs v5.15.1
See http://btrfs.wiki.kernel.org for more information.
Zoned: /dev/sda: host-managed device detected, setting zoned feature
Resetting device zones /dev/sda (74508 zones) ...
NOTE: several default settings have changed in version 5.15, please make sure
this does not affect your deployments:
- DUP for metadata (-m dup)
- enabled no-holes (-O no-holes)
- enabled free-space-tree (-R free-space-tree)
Label: (null)
UUID: 7ffa00fe-c6a3-4c6c-890f-858e17118c66
Node size: 16384
Sector size: 4096
Filesystem size: 18.19TiB
Block group profiles:
Data: single 256.00MiB
Metadata: single 256.00MiB
System: single 256.00MiB
SSD detected: no
Zoned device: yes
Zone size: 256.00MiB
Incompat features: extref, skinny-metadata, no-holes, zoned
Runtime features: free-space-tree
Checksum: crc32c
Number of devices: 1
Devices:
ID SIZE PATH
1 18.19TiB /dev/sda
现在可以直接挂载格式化的块设备。 无需其他设置。
# mount /dev/sda /mnt
XFS
XFS 当前不支持分区块设备。 必须使用 dm-zoned 设备映射器目标来启用带 XFS 的分区设备。
早期的设计文档讨论了使用 XFS 支持主机感知和主机托管磁盘所需的开发工作。 该设计的部分内容已经实现并包含在内核稳定版本中(例如,“每个 inode 反向块映射 b-trees”功能)。 但是,要完全支持分区块设备,还需要做更多的工作。
ext4
本文描述了通过更改文件系统日志管理来提高 ext4 性能的主机感知分区块设备的尝试。 这些变化很小,并且成功地保持了良好的性能。 但是,不提供对主机管理的分区块设备的支持,因为 ext4 设计的一些基本方面无法轻易更改以匹配主机管理的设备约束。
主机感知分区块设备的主机优化领域仍处于研究阶段,并未包含在 ext4 稳定内核版本中。 还应注意,ext4 不支持主机托管磁盘。 然而,与 XFS 一样,ext4 文件系统可以与 dm-zoned 设备映射器目标一起使用。

















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









