




 探讨了在SQL中使用count(*)与count(distinct)的区别,尤其是在处理空值时的统计差异,帮助理解如何根据需求选择合适的计数方法。
探讨了在SQL中使用count(*)与count(distinct)的区别,尤其是在处理空值时的统计差异,帮助理解如何根据需求选择合适的计数方法。
遇到了一个很有意思的问题,在用count统计数量时,distinct和group by的结果竟然不同,
select count(*) from (select 1 from tt group by id,name) a;
select count(distinct id,name) from tt;
在有空值时,这两个语句得到的结果是不同的,distinct在count时会排除空值字段,所以可能会发生统计不准确的情况。
count with group by:
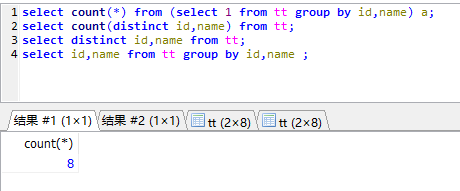
count with distinct:
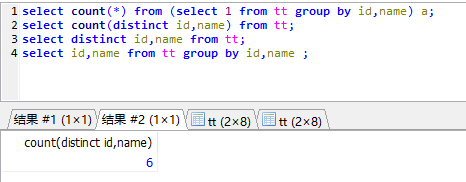
但是如果将二者的数据都打印出来,会发现两个的结果是一样的
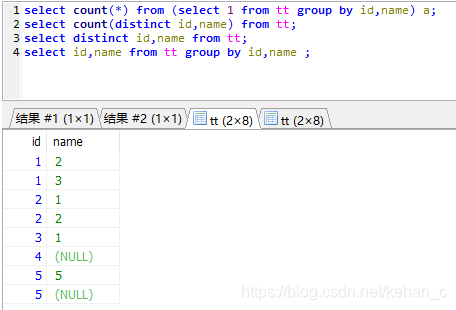
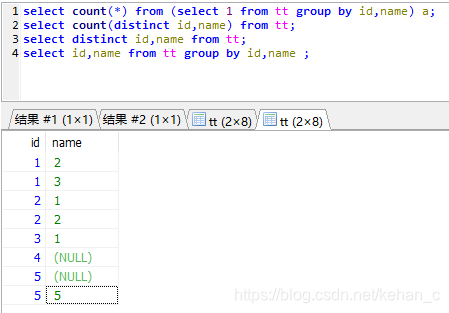
因此,在做去重统计时,如果字段存在空值,根据自己的需求选择count (distinct xx,xx)或count(1) from xxx group by xx,xx ,否则可能会统计不准确

















 5702
5702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









