



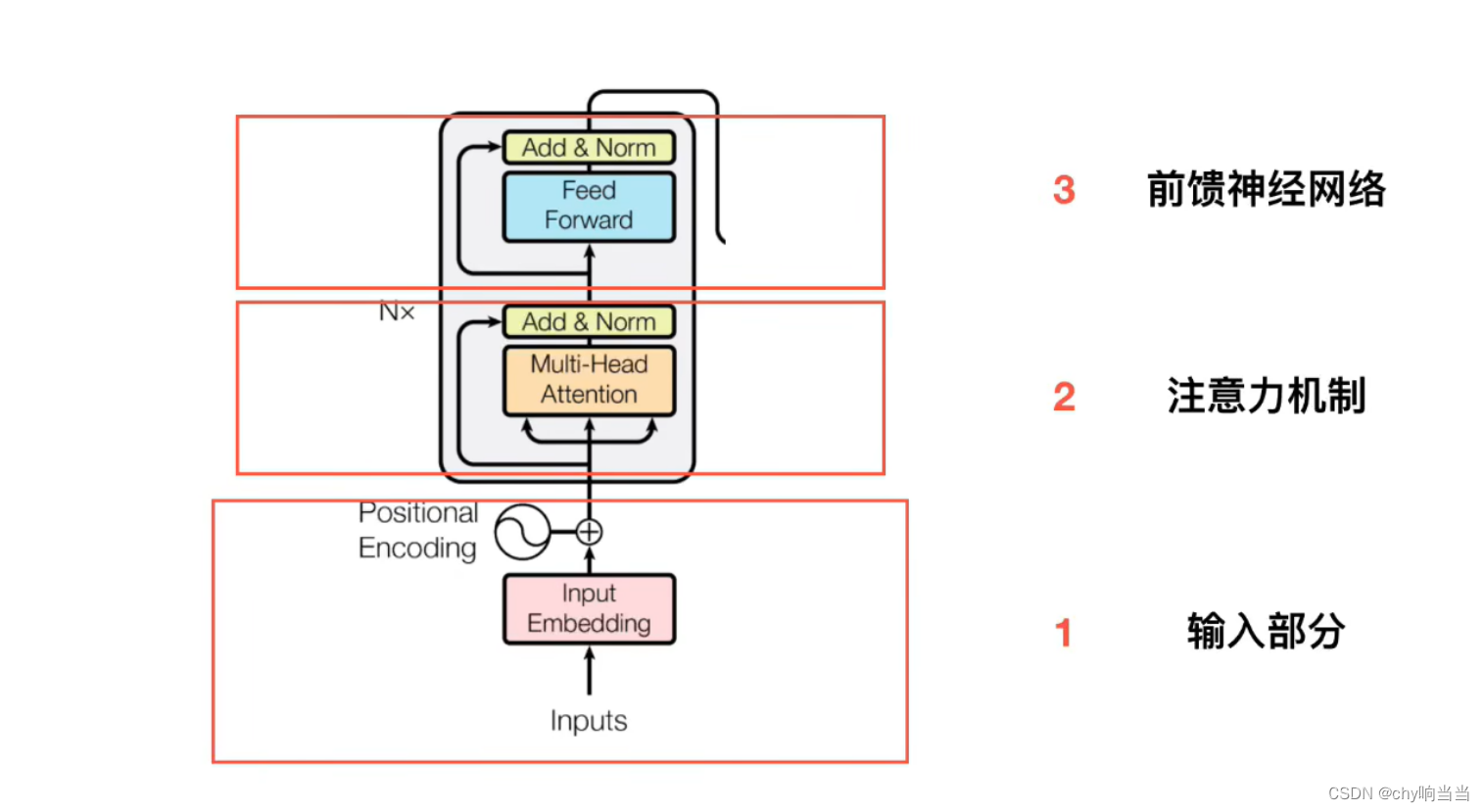
 文章介绍了Transformer模型的架构,包括编码器和解码器的使用,以及如何通过位置编码处理序列数据。模型利用注意力机制解决RNN的梯度消失问题,采用多头注意力进行信息处理,并利用残差连接和LayerNorm增强网络深度和稳定性。此外,解码器中的掩码机制用于防止未来信息泄露,确保序列生成的正确顺序。
文章介绍了Transformer模型的架构,包括编码器和解码器的使用,以及如何通过位置编码处理序列数据。模型利用注意力机制解决RNN的梯度消失问题,采用多头注意力进行信息处理,并利用残差连接和LayerNorm增强网络深度和稳定性。此外,解码器中的掩码机制用于防止未来信息泄露,确保序列生成的正确顺序。
仅仅用于个人学习
 一个输入通过黑盒操作得到输出。
一个输入通过黑盒操作得到输出。
处理分为编码解码结构。
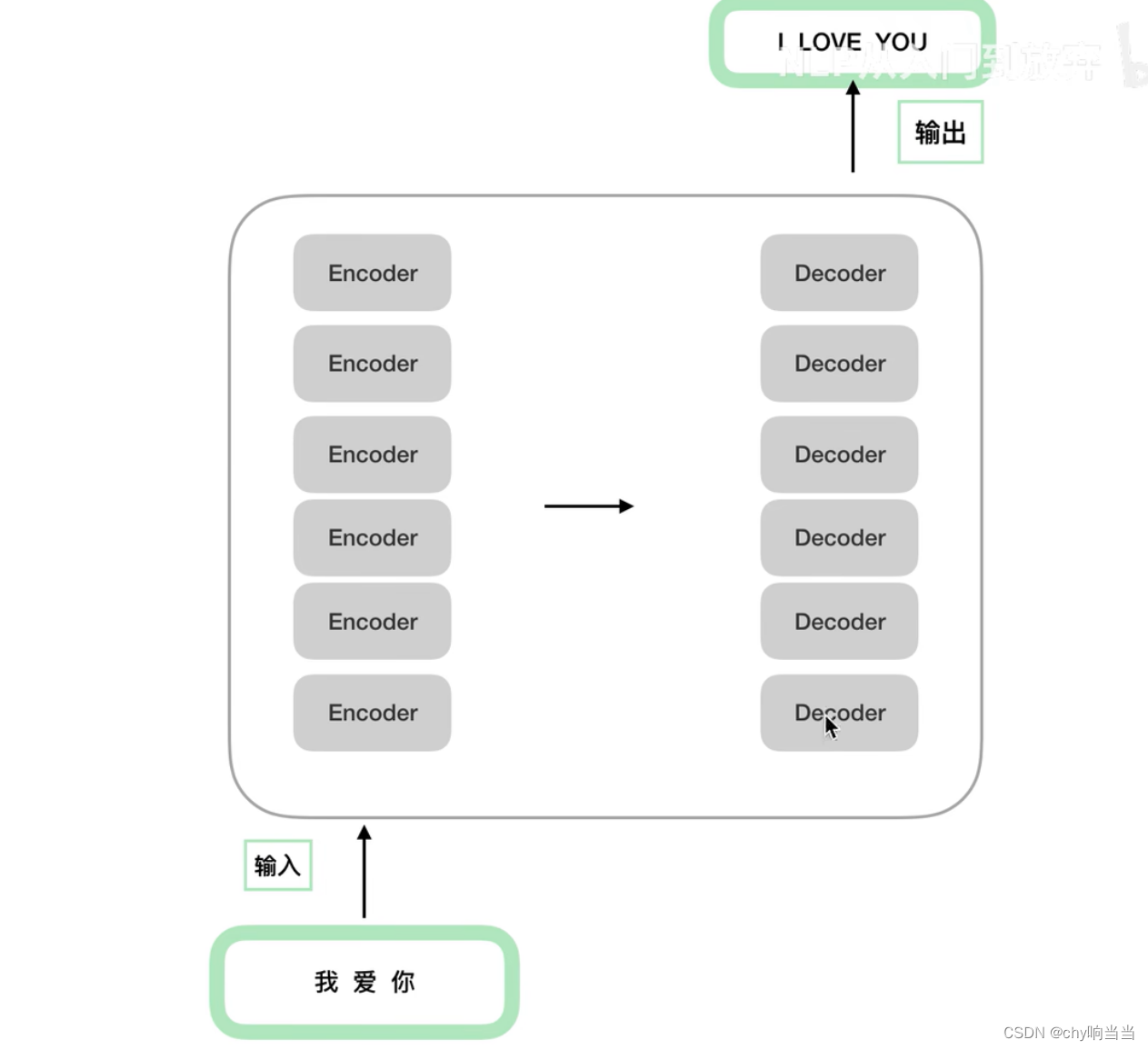
成n的结构,encoder之间结构相同(但是参数上训练上不一样),decoder之间也是。
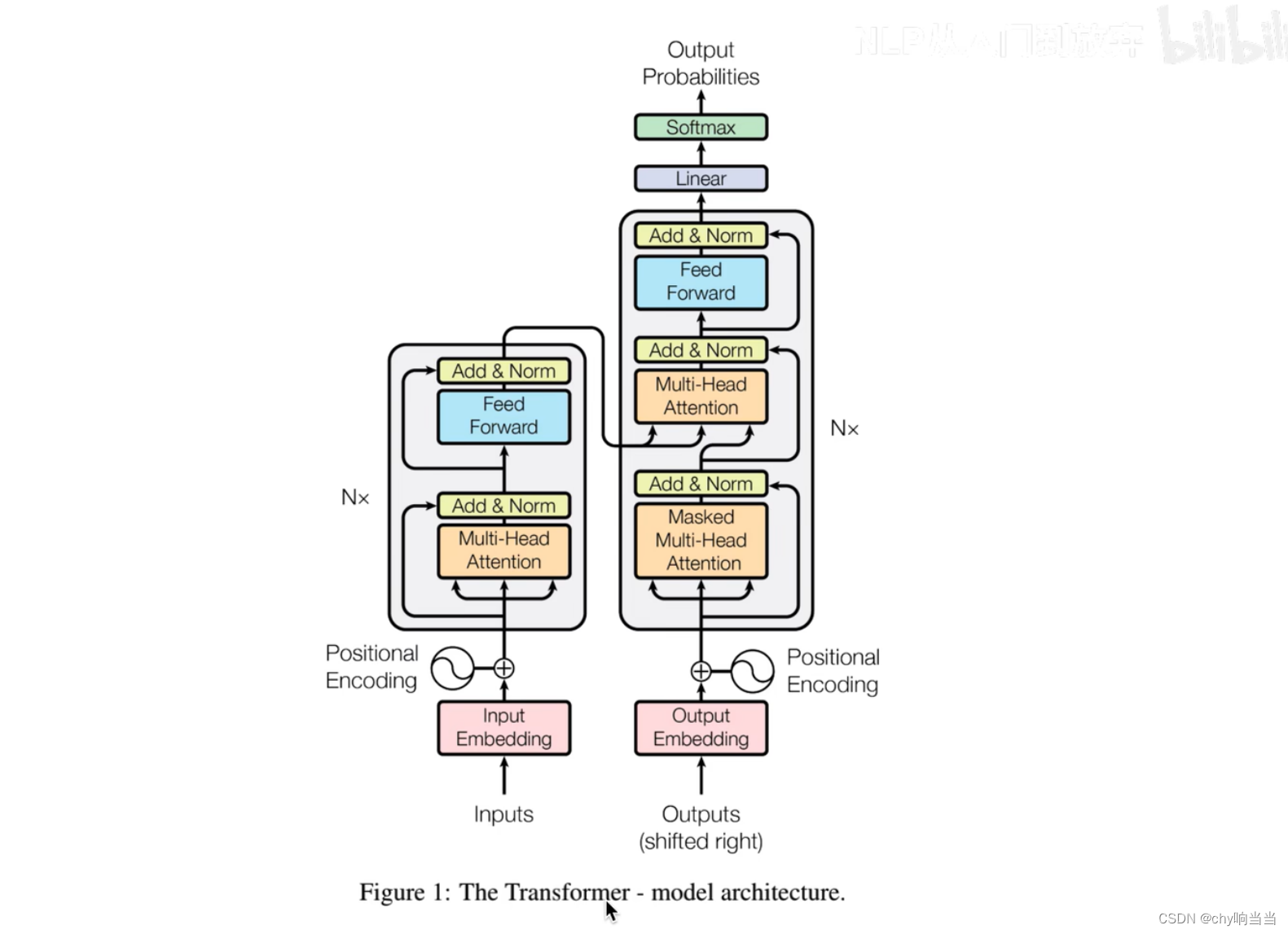
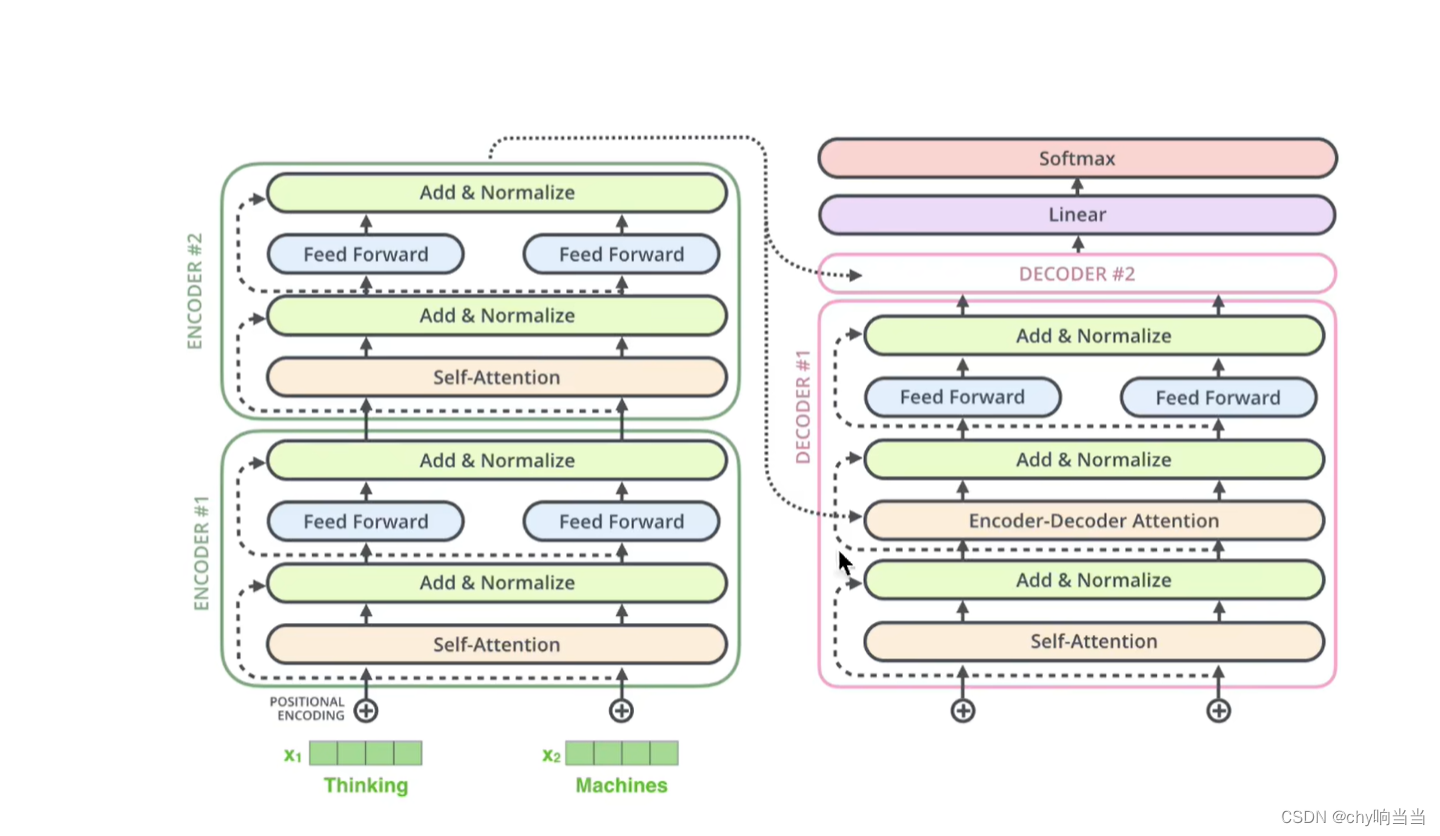
这是原论文结构图,左边是encoders,右边是decoders,原论文n=6
下面先看左边的encoder

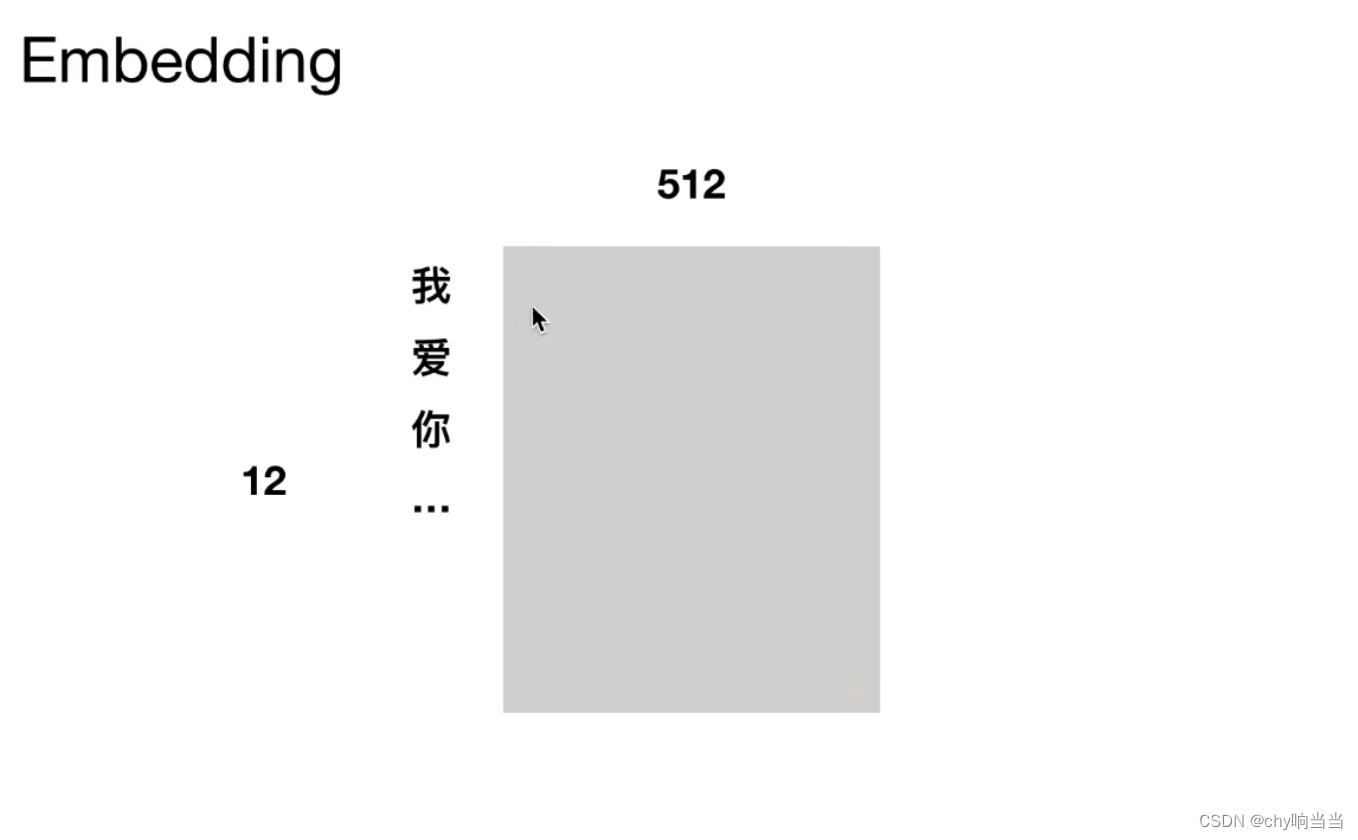
输入12字,然后按字切分,每个字切为长度512字节的词向量。
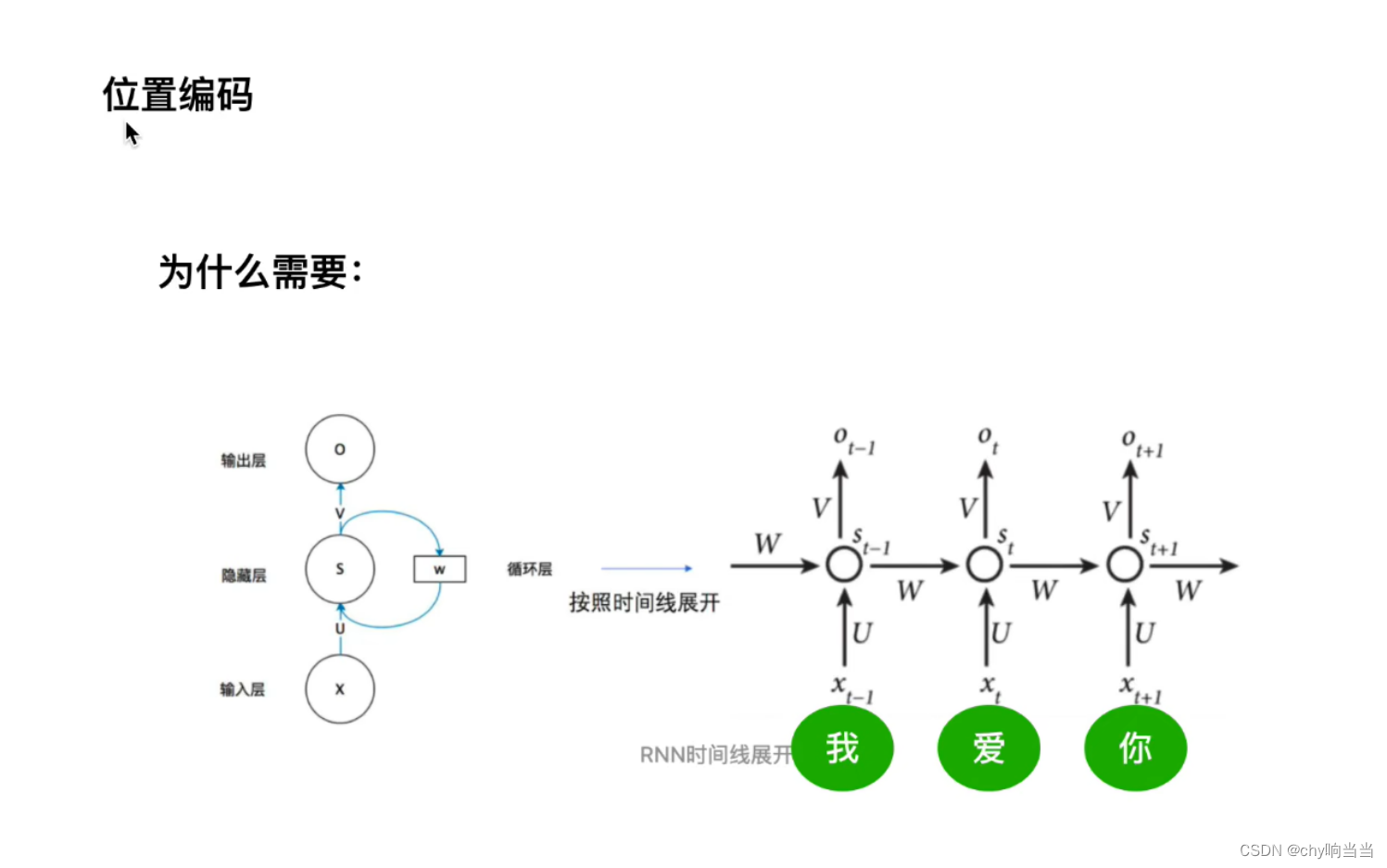
因为RNN循环时其实都是共享一套参数,某种意义上就是单层训练。然后右图可以显示其梯度消失的含义:被近距离梯度阻挡被远距离梯度忽略。有序列关系,RNN必须先处理我再处理爱...
但是transformer可以同时处理,可这样就没有顺序了,那怎么办呢?就需要用位置编码了。
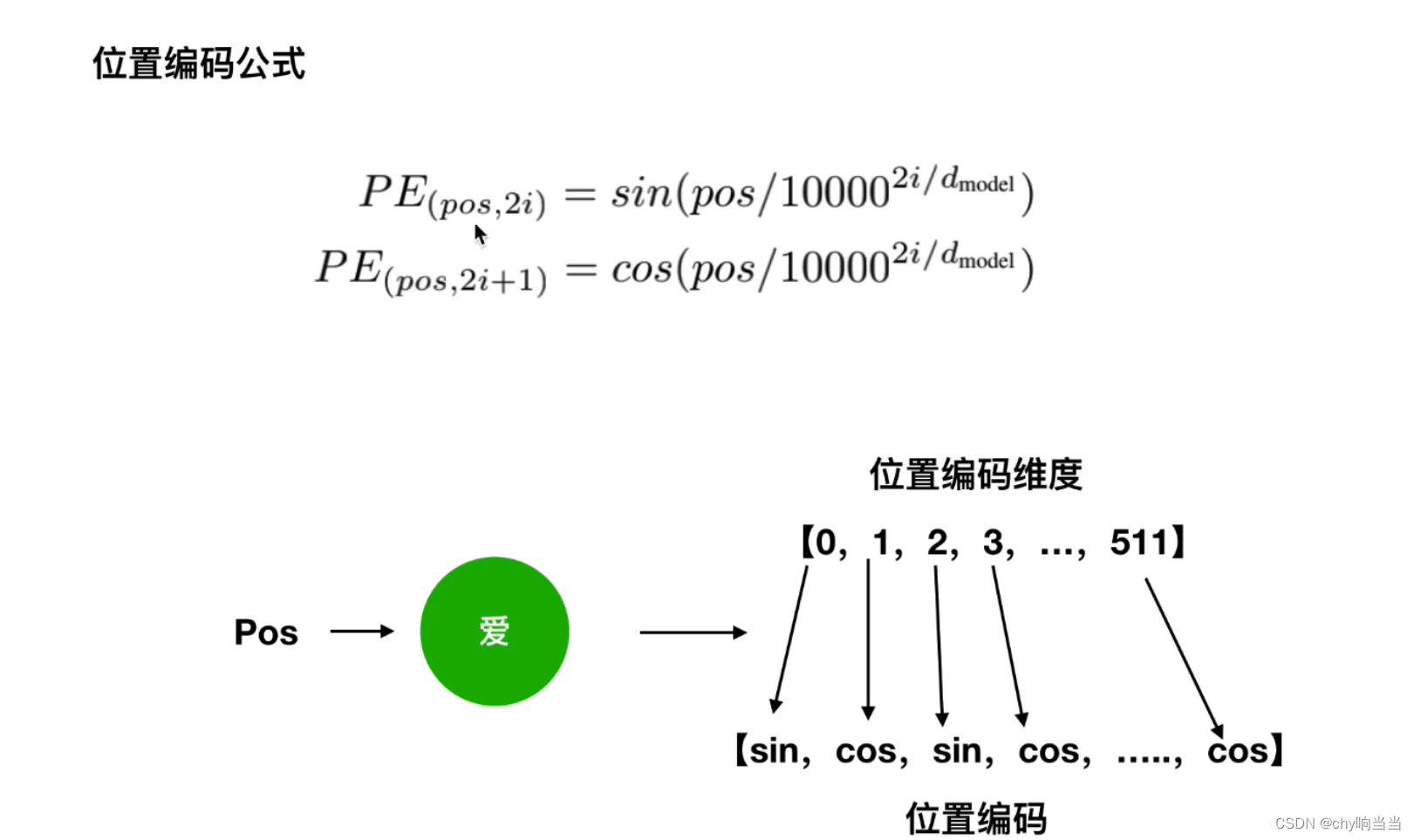
然后把位置向量512维度和词向量512维度相加
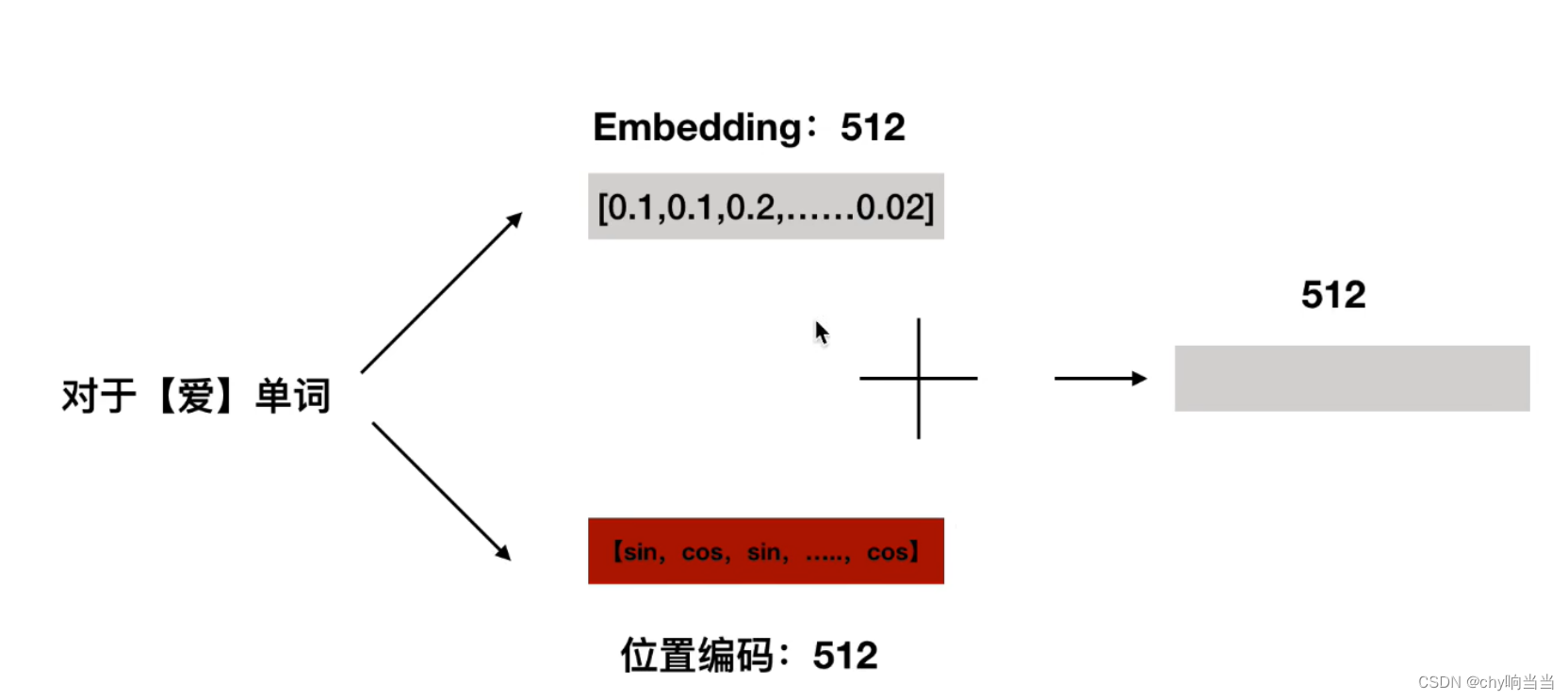
得到最终的512维度的向量作为transformer模型输入

比如pos+k是你,pos是我,k是爱,这样绝对位置中又有相对位置信息

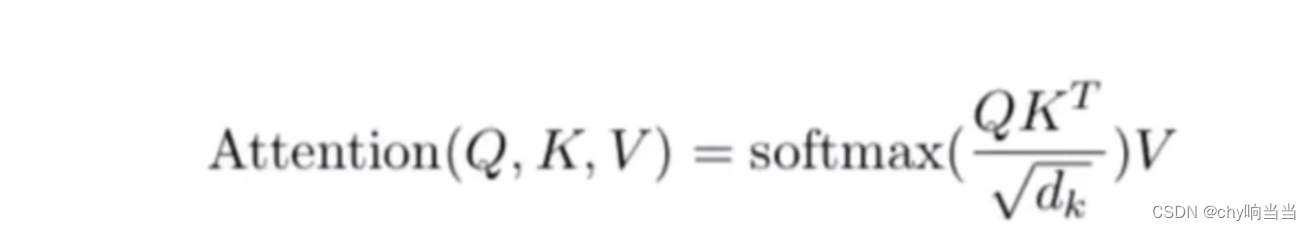
下面一个经典例子,研究婴儿在干什么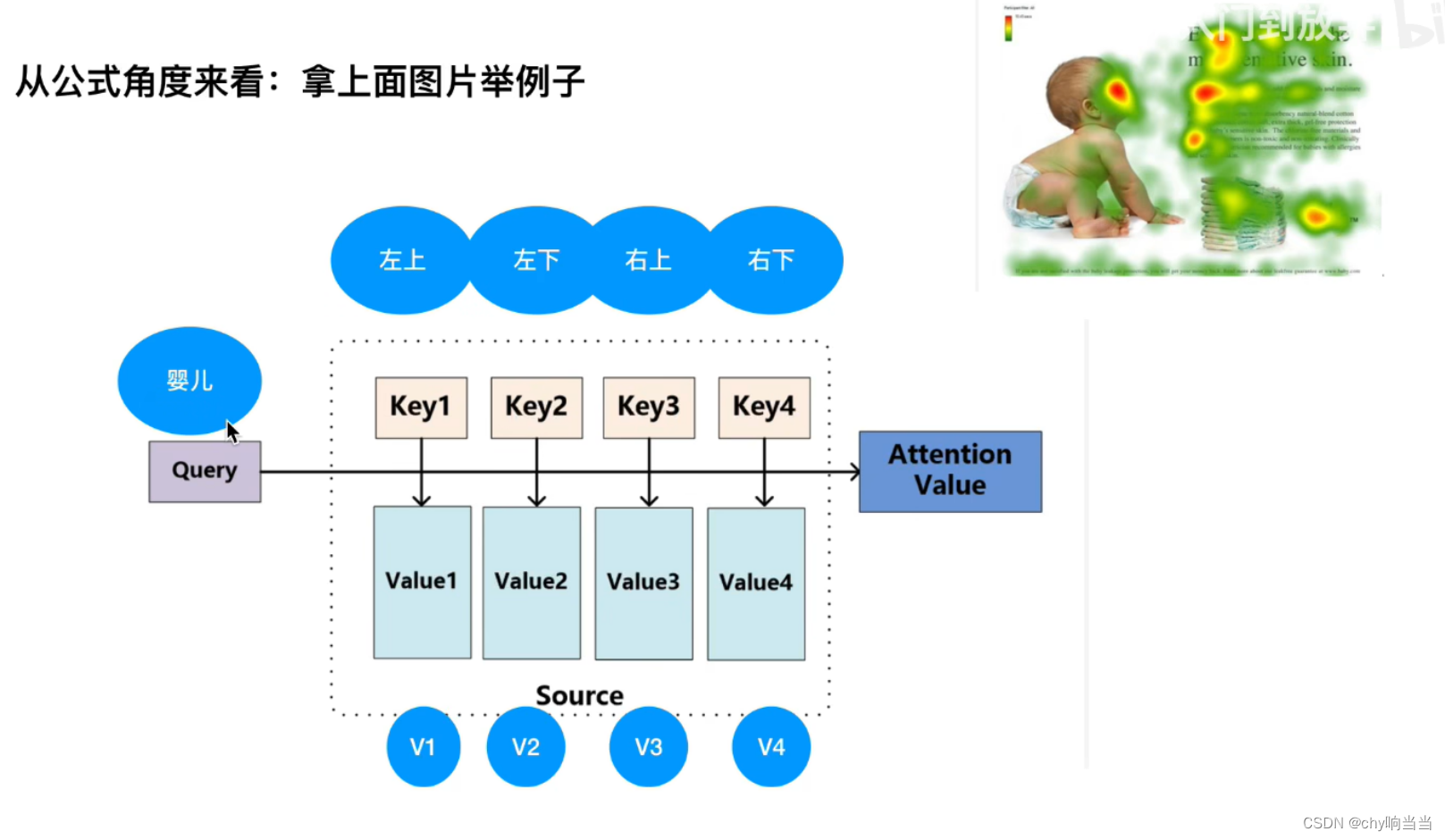
需要QKV三个矩阵,Q是婴儿对应单词的某种向量(矩阵)
k1-k4是左上-右下4个区域代表的4个向量,v1-v4是左上-右下4个区域对应某种值向量
首先婴儿先和左上-左下分别点乘得到某个值(为什么做点乘,做相似度计算时有点乘、cos相似性,多层网络),越相似点乘越大,判断婴儿和哪个区域点乘结果越大,那就说明距离越靠近就越相似,就要越关注。
最后和V矩阵相乘
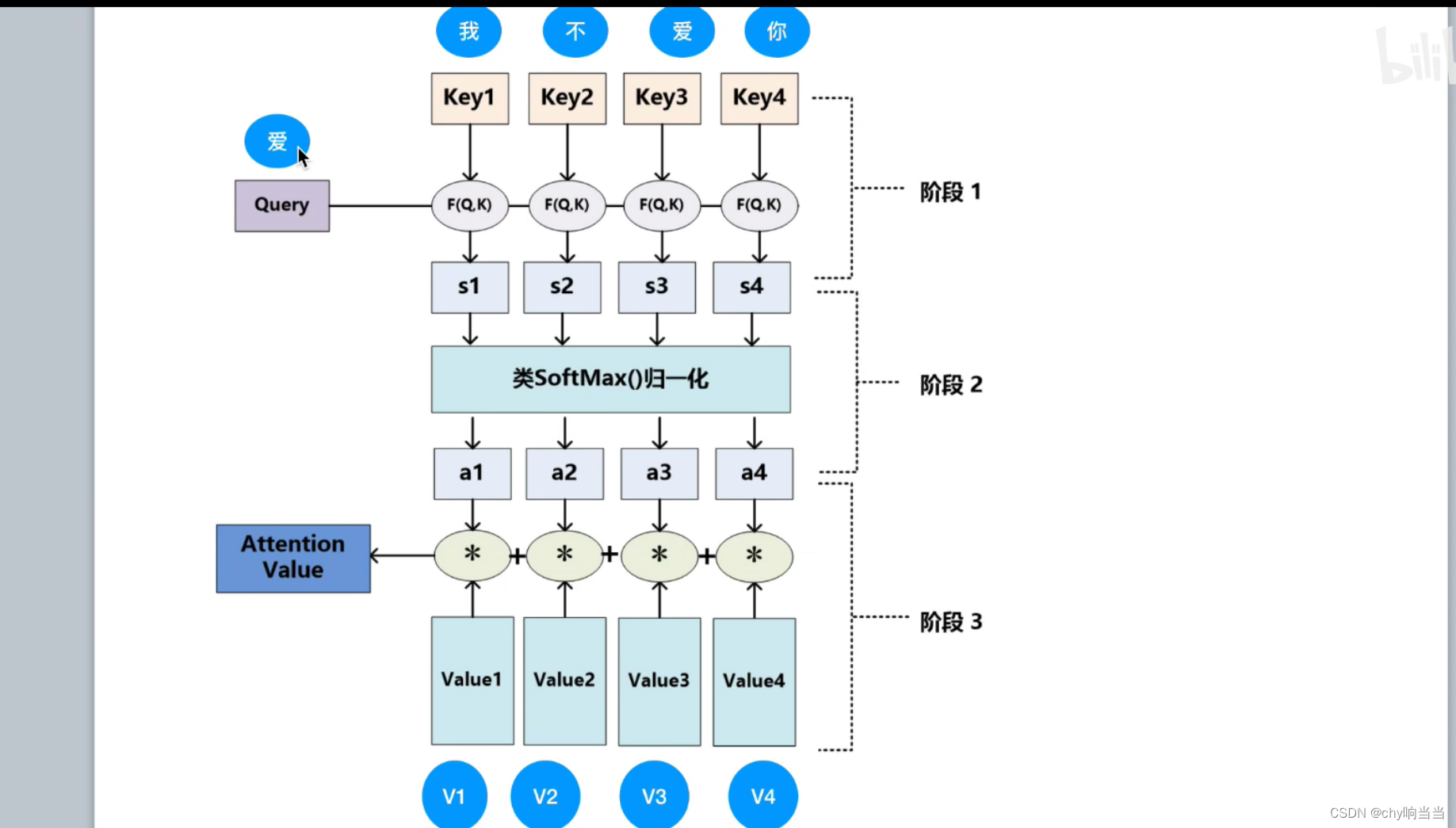
再举个栗子
那怎么获取QKV呢
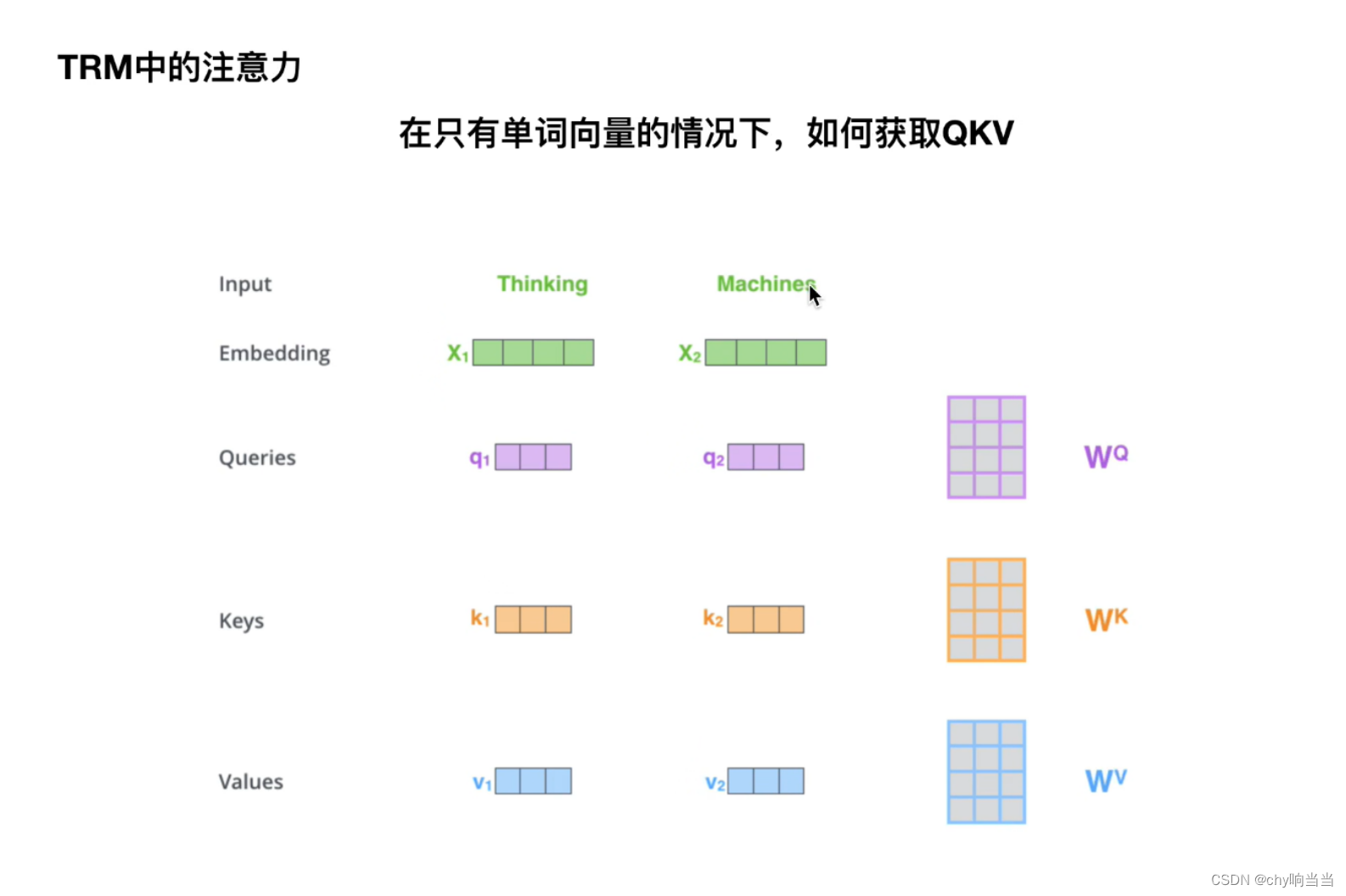
比如现在只有4维度的2个词向量,分别乘以矩阵参数WQ WK WV得到QKV
然后计算attentionValue
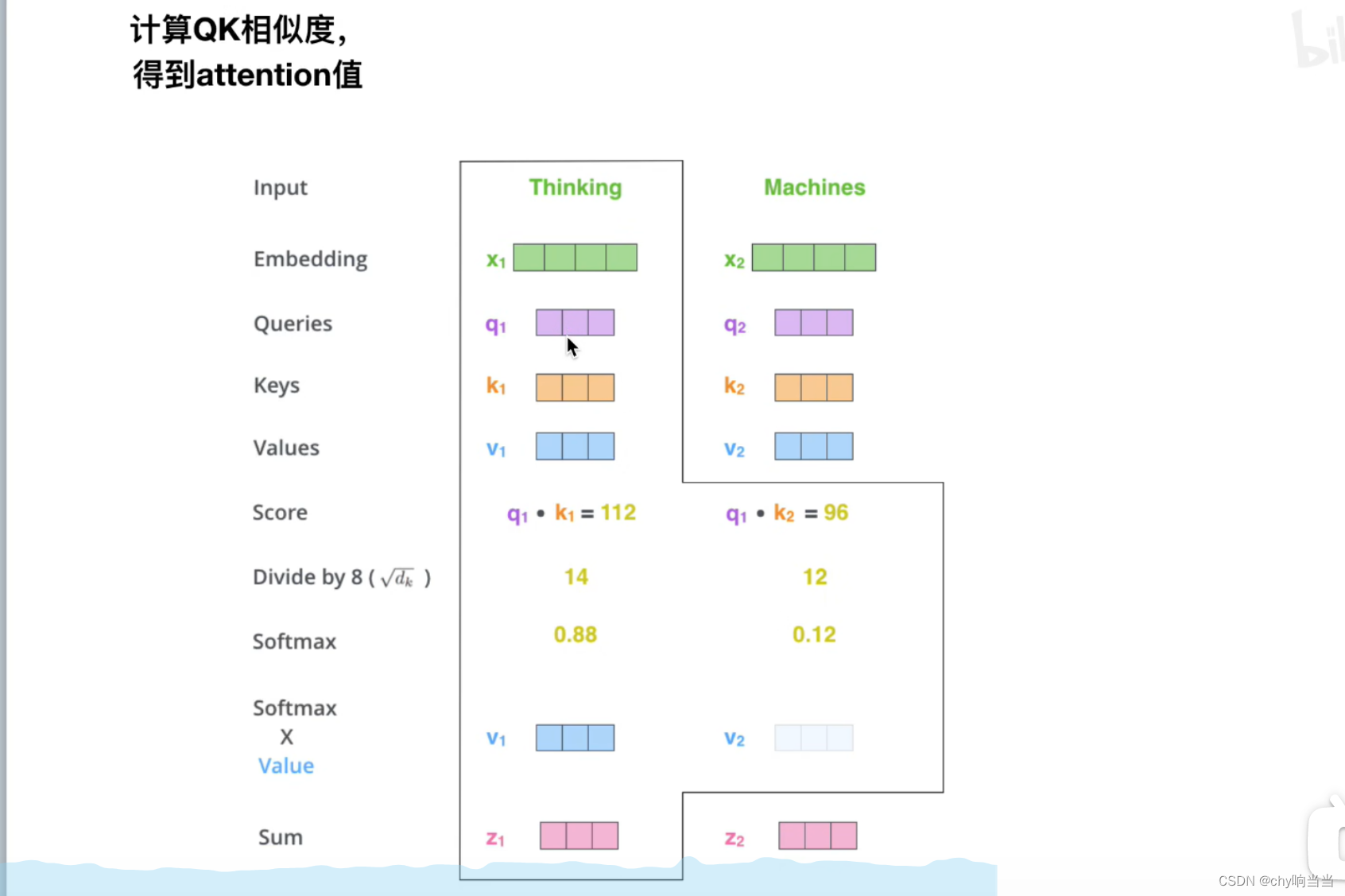
除以dk是为了防止score很大,然后导致softmax后面梯度很小然后消失,为什么除这个值呢,就是为了保证方差为1
实际操作上会用矩阵也就是一起输入,比如X是两个单词
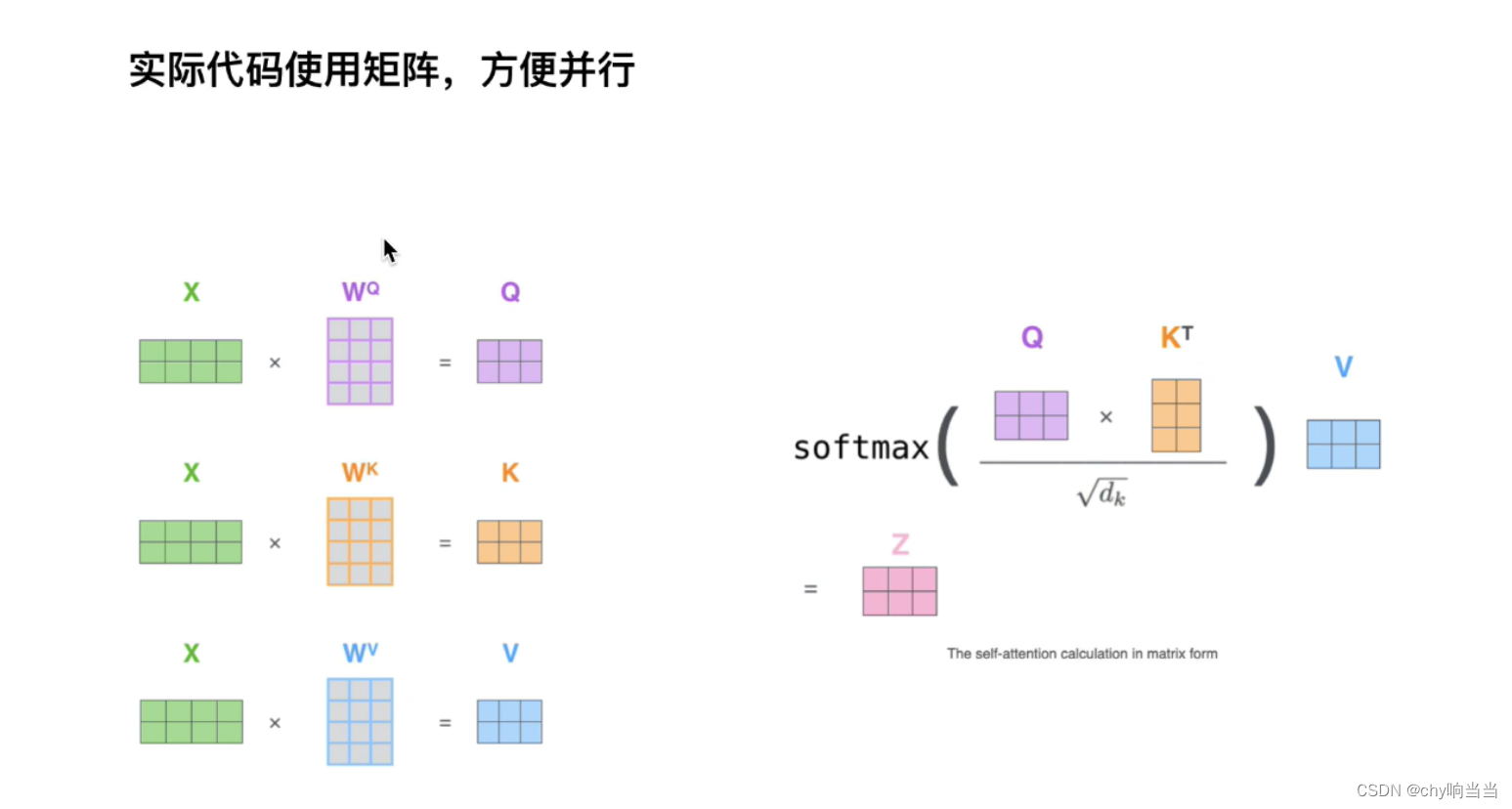
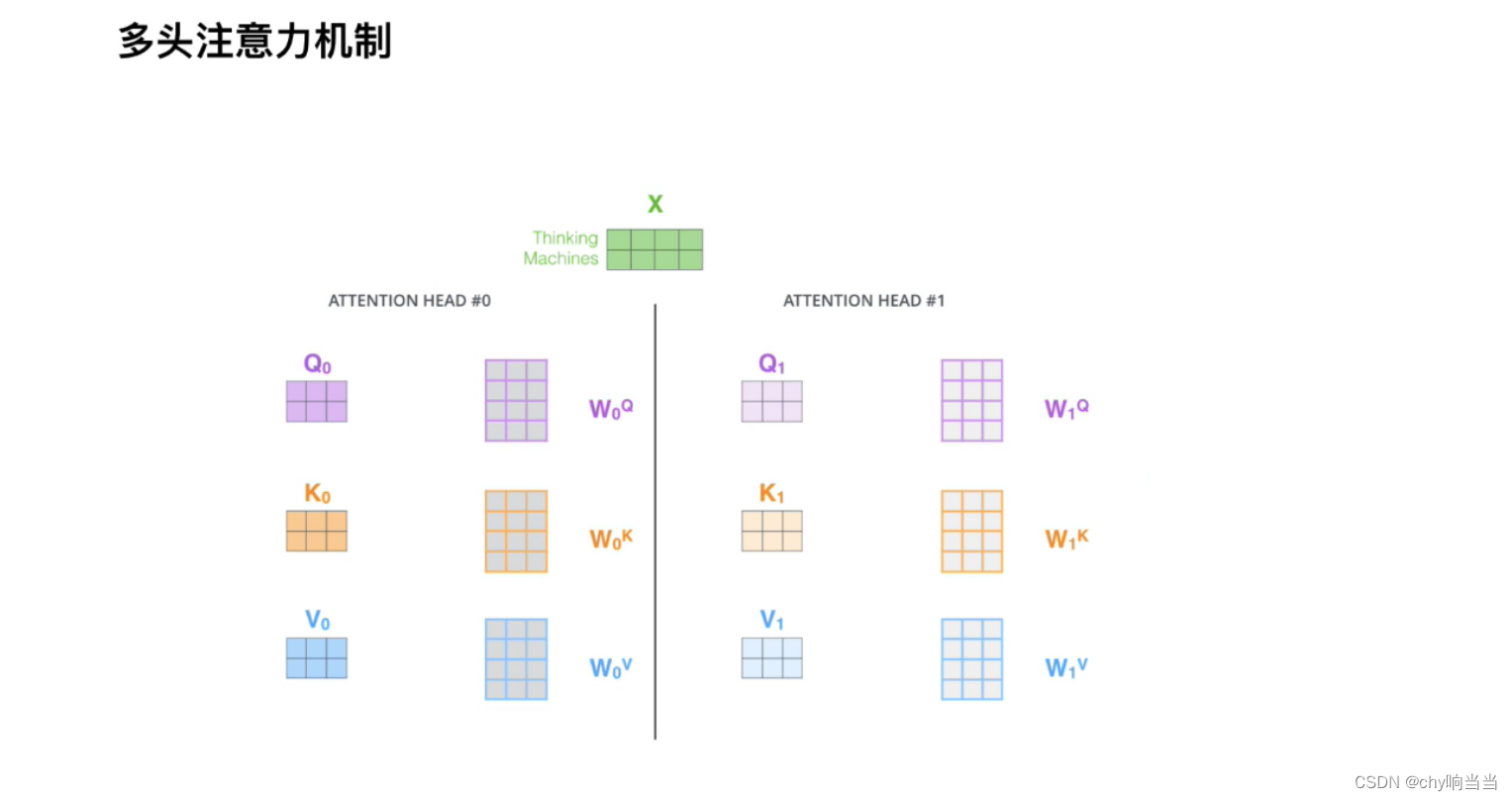
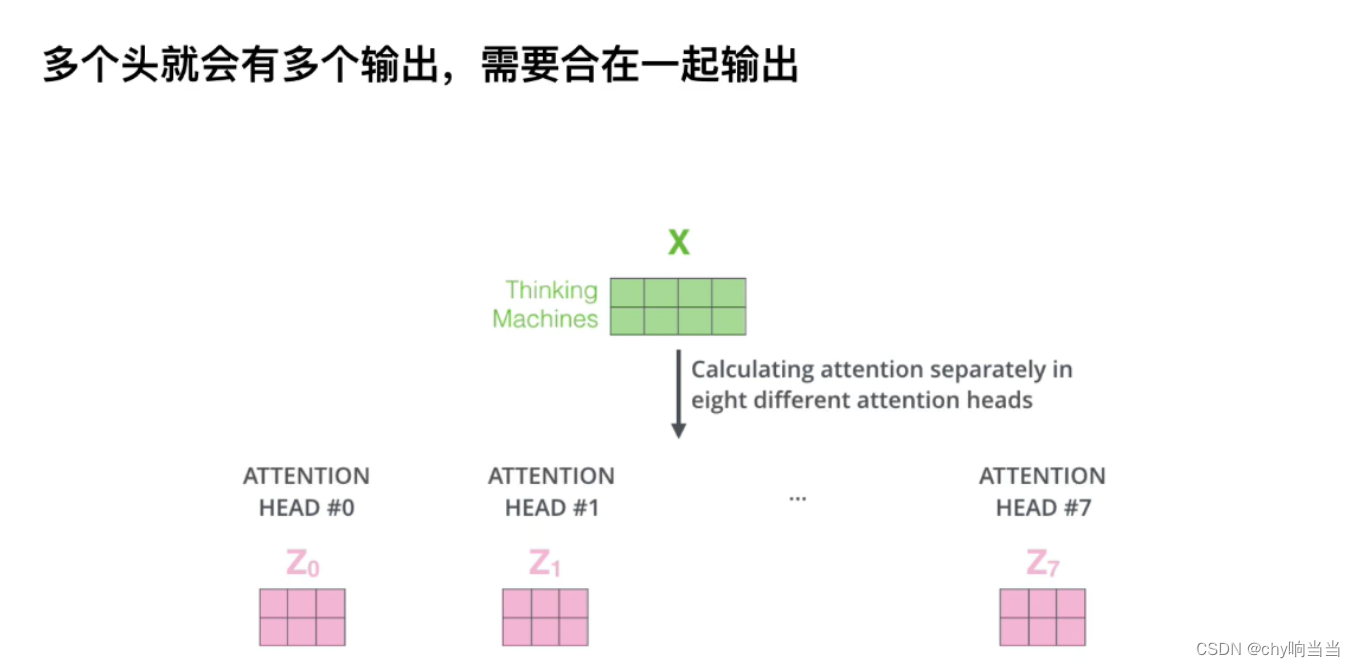
而且这里WQWKWV是只有一套参数,实际中会有多套参数,这样效果会好一点,多头后把原始信息打到不同空间了
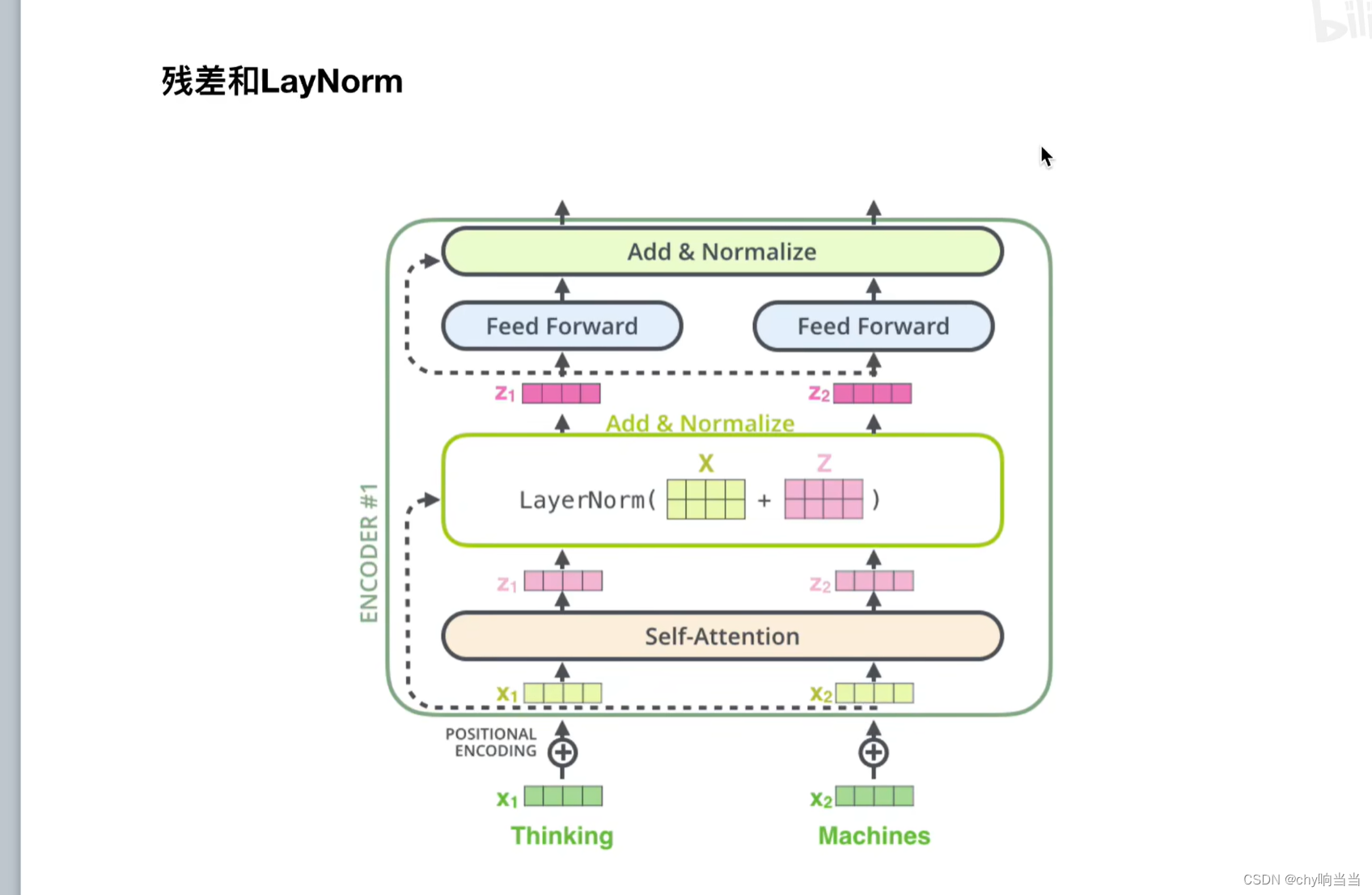
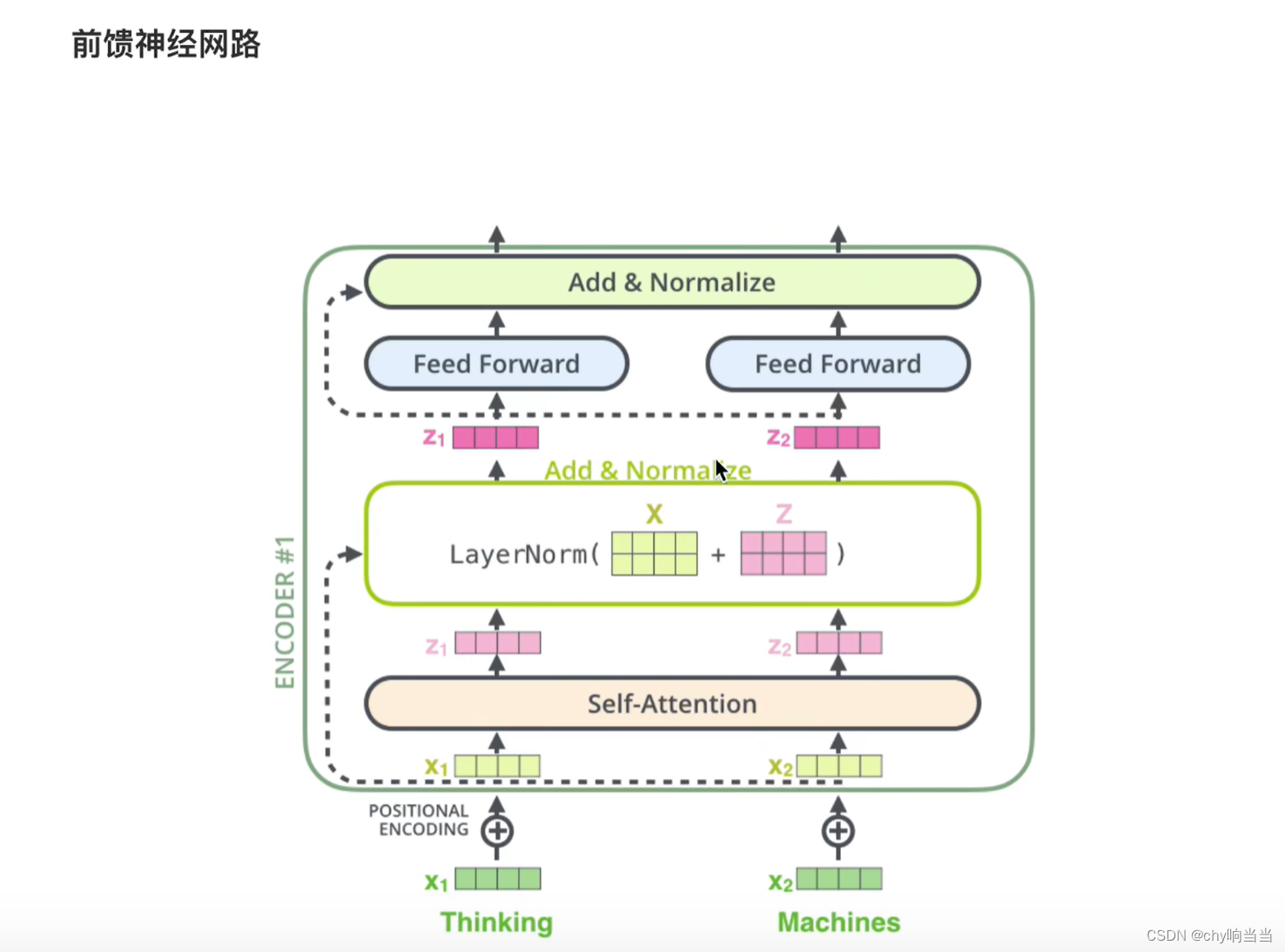
从下往上看,词向量X和位置编码对位相加得X'作为输入,再经过注意力层得到输出结果Z,然后把X'和Z对位相加,作为一个残差的结果,然后在LayerNormalize计算后作为输出
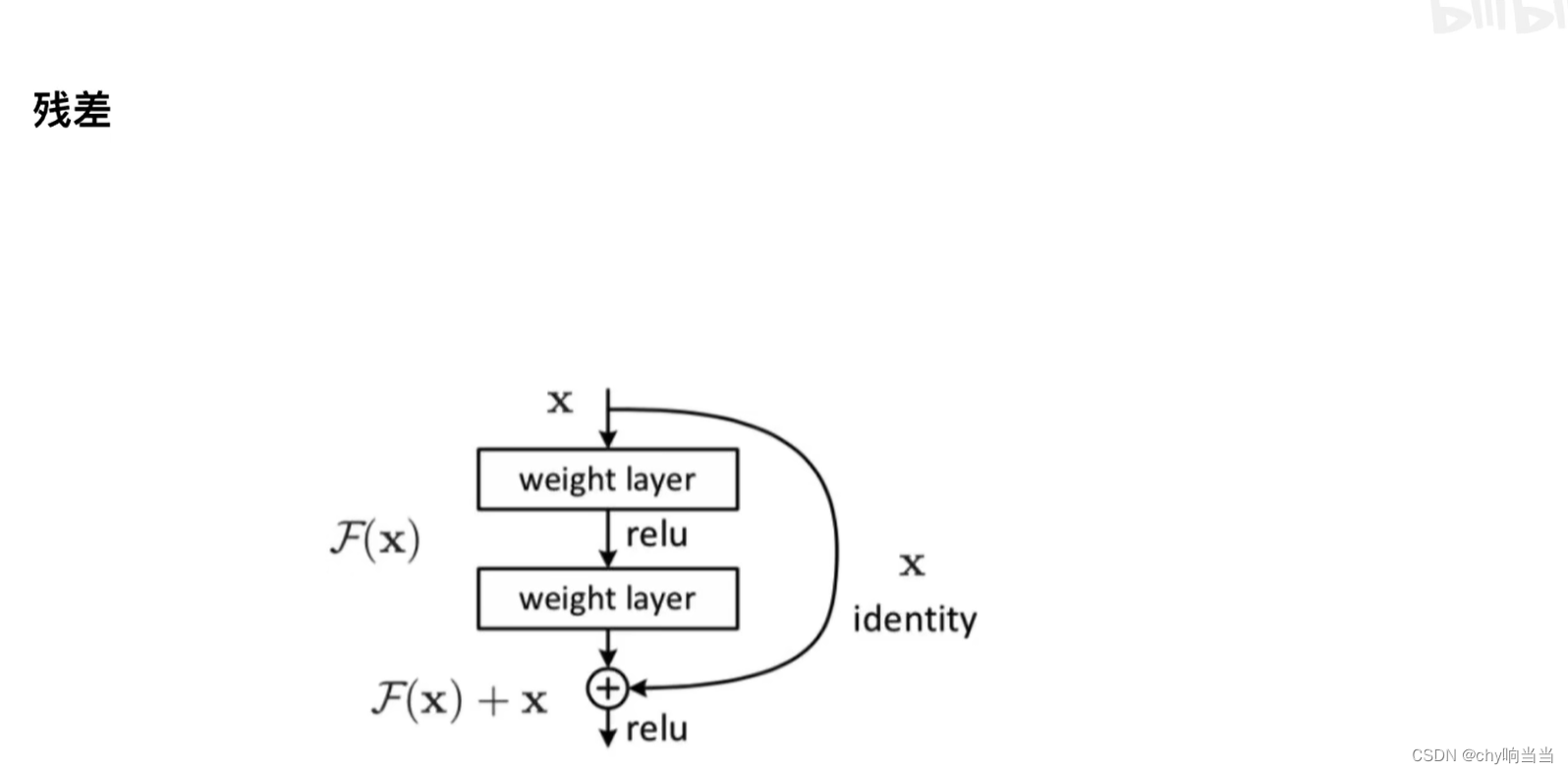
X作为输入,然后经过两层网络(作为函数F(X)),有残差就再和X相加
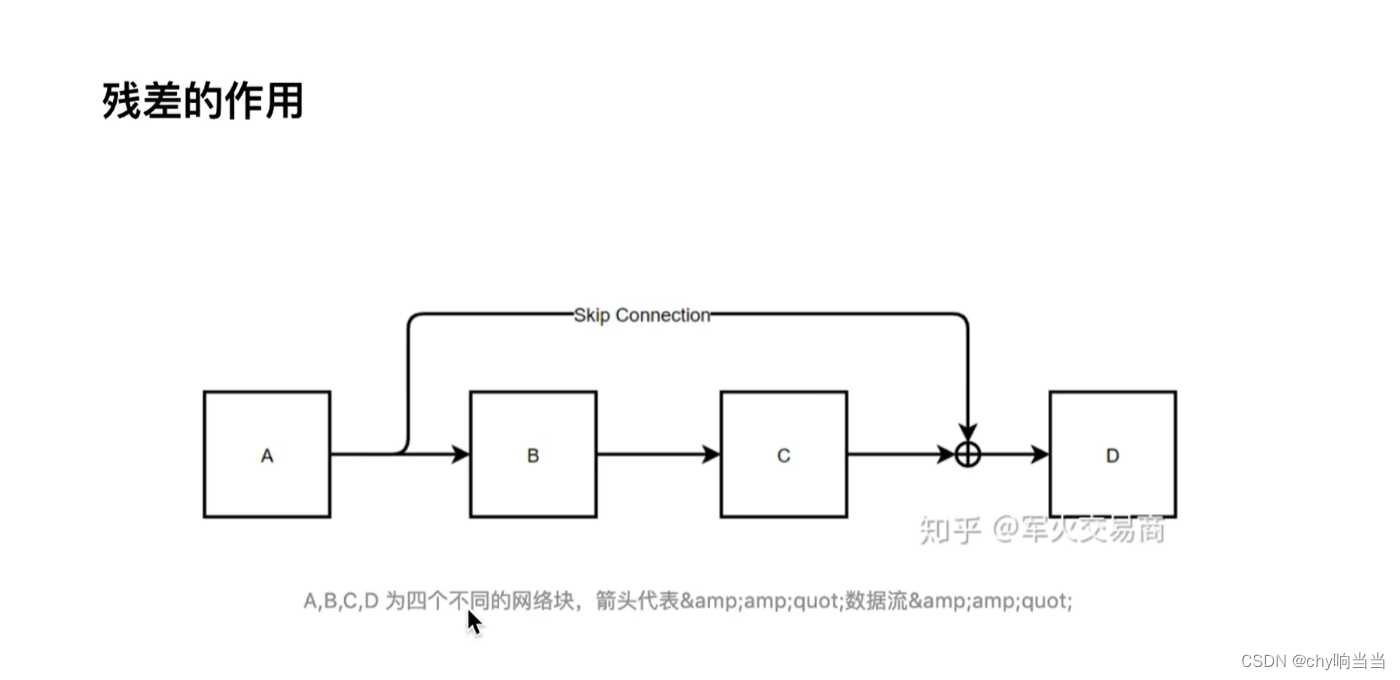
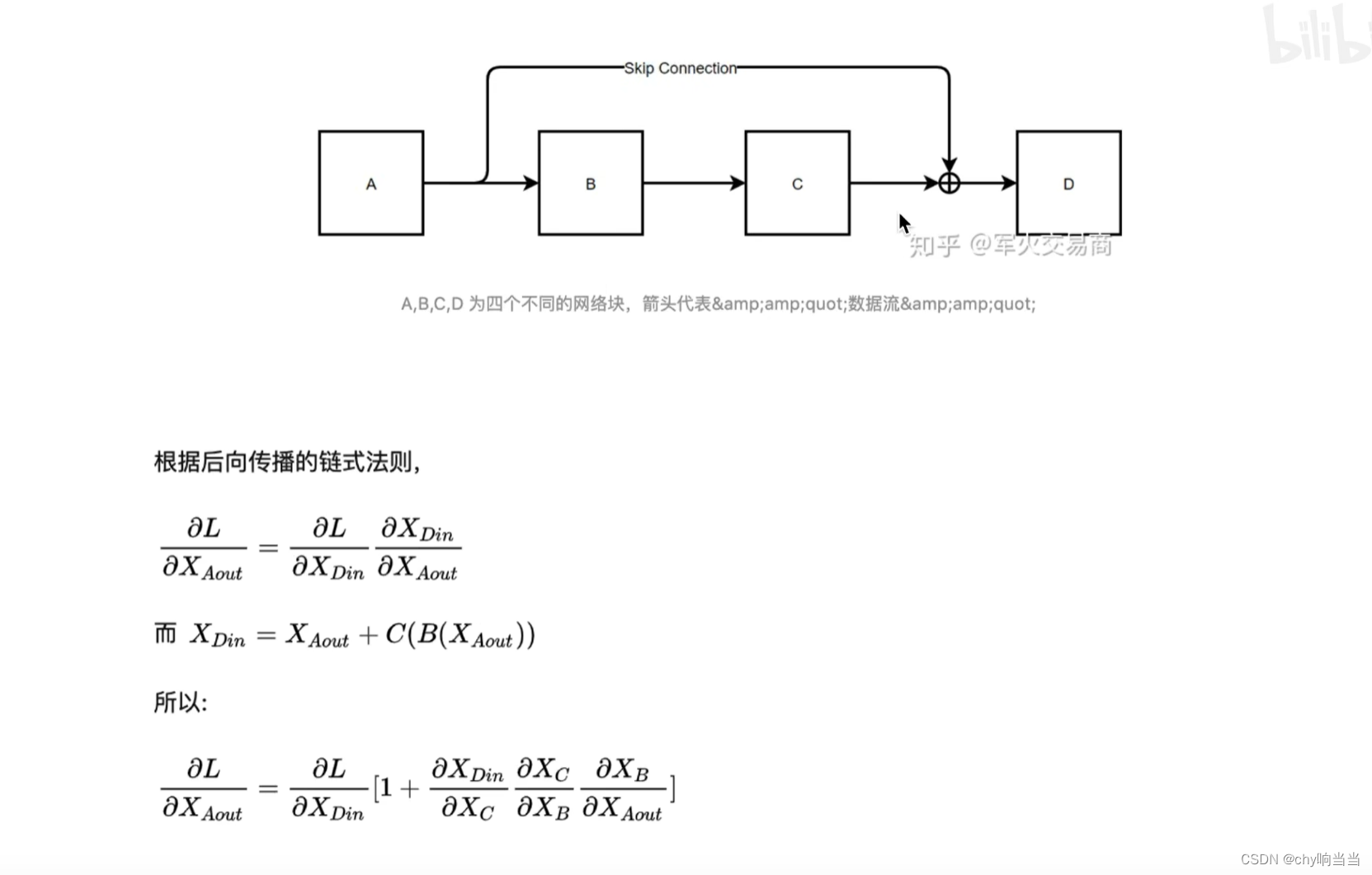
这样最后(1+...)后面连乘即使为0,那也有一个1在那里,确保了梯度不会为0,缓解了梯度消失,这样网络层就能多一些了 ,深度能大一些
那为什么用LayerNormalize(LN)而不用BN(batchnorm)?
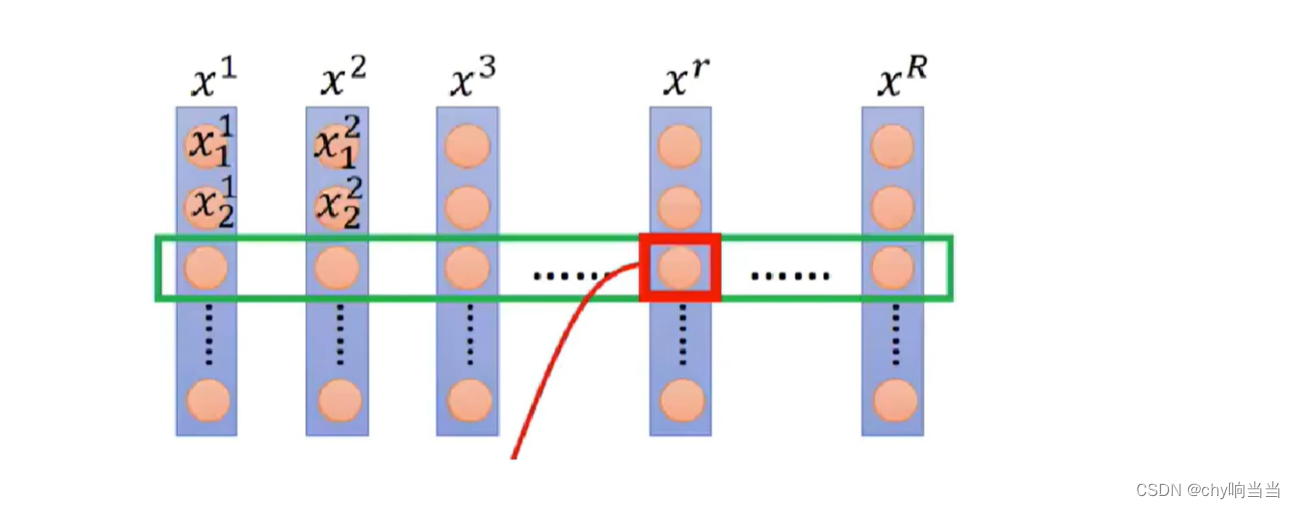
BN针对的是一组Batch样本在同一维度中的特征
比如小白,小红,小蓝,第一行体重,第二行成绩....
那BN是对一行成绩做BN

但是


比如BN用十个人的体重的均值方差来模拟全班的体重,但是若训练时只有一个小明,那就不能很好代表全班

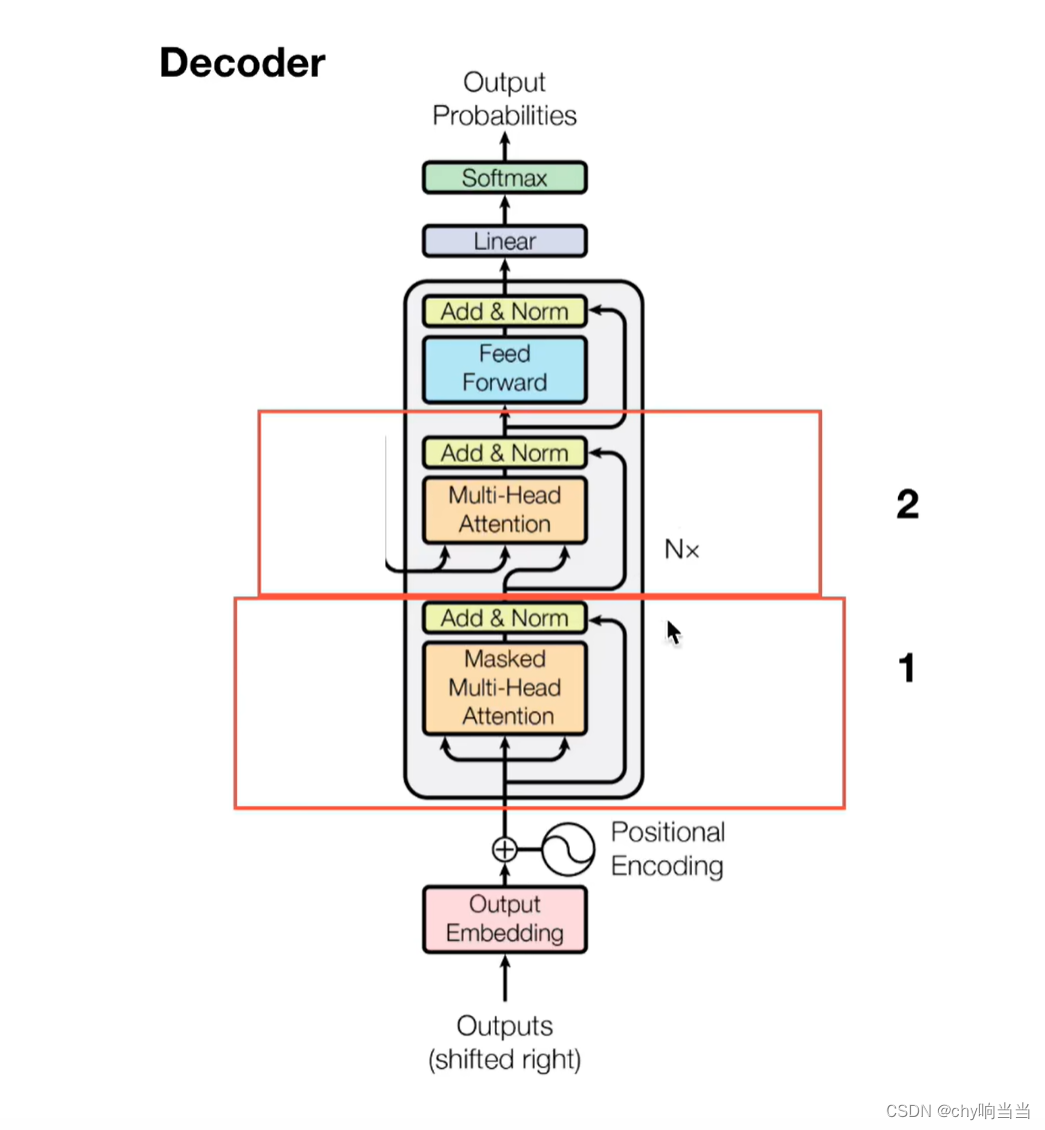
decoder多了一层mask多了一层交互层
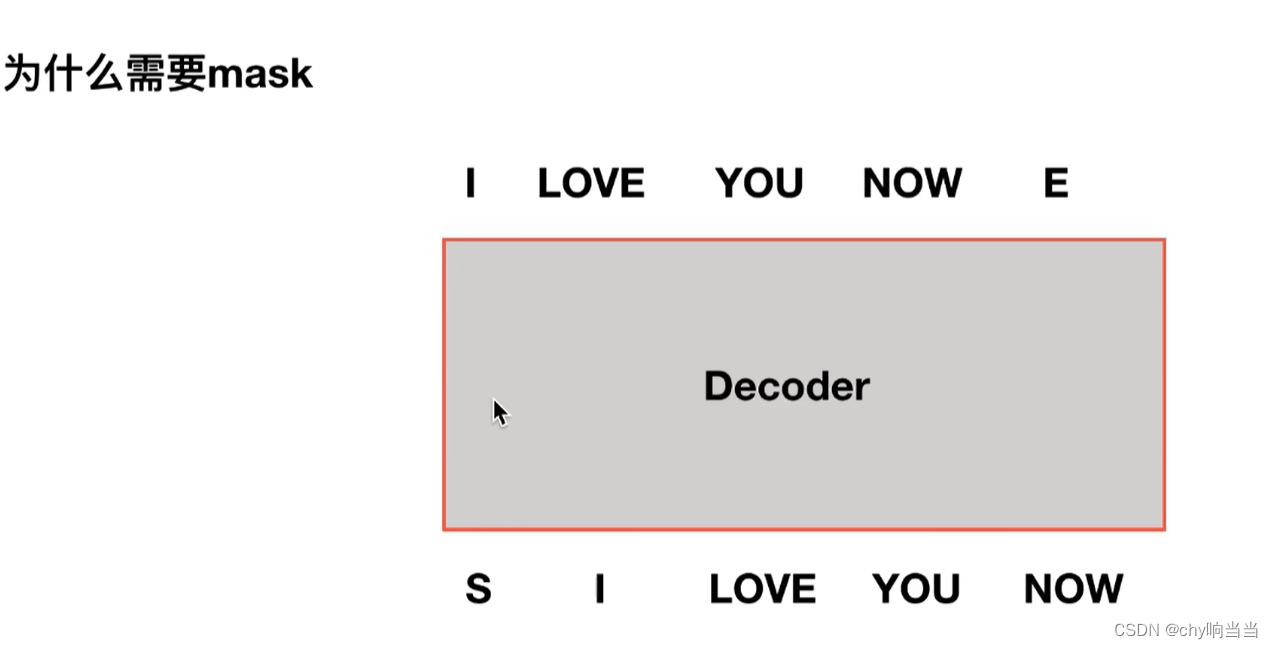
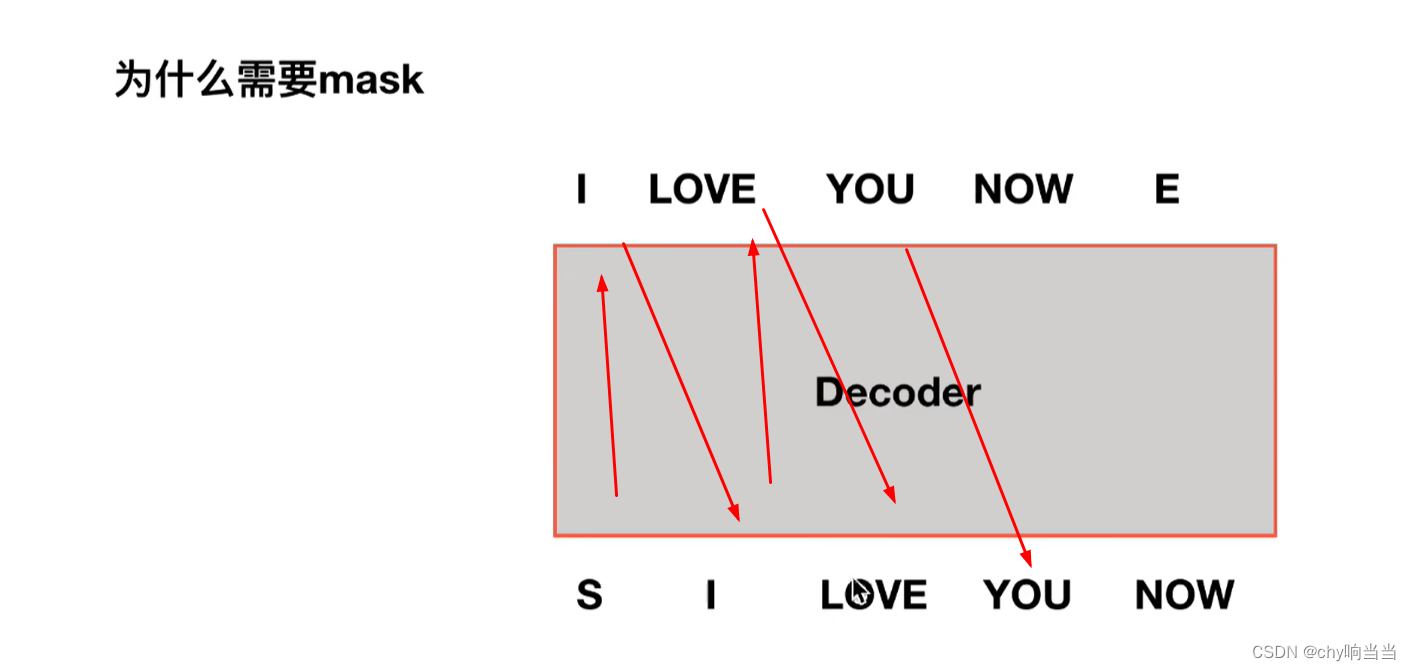
掩盖的目的就是为了不计算后边词的关联性 因为在实际场合中,decoder的输入是顺序的输出 也就是说计算you的自注意力的时候 还没有输入中的 you 和now呢 所以要掩盖
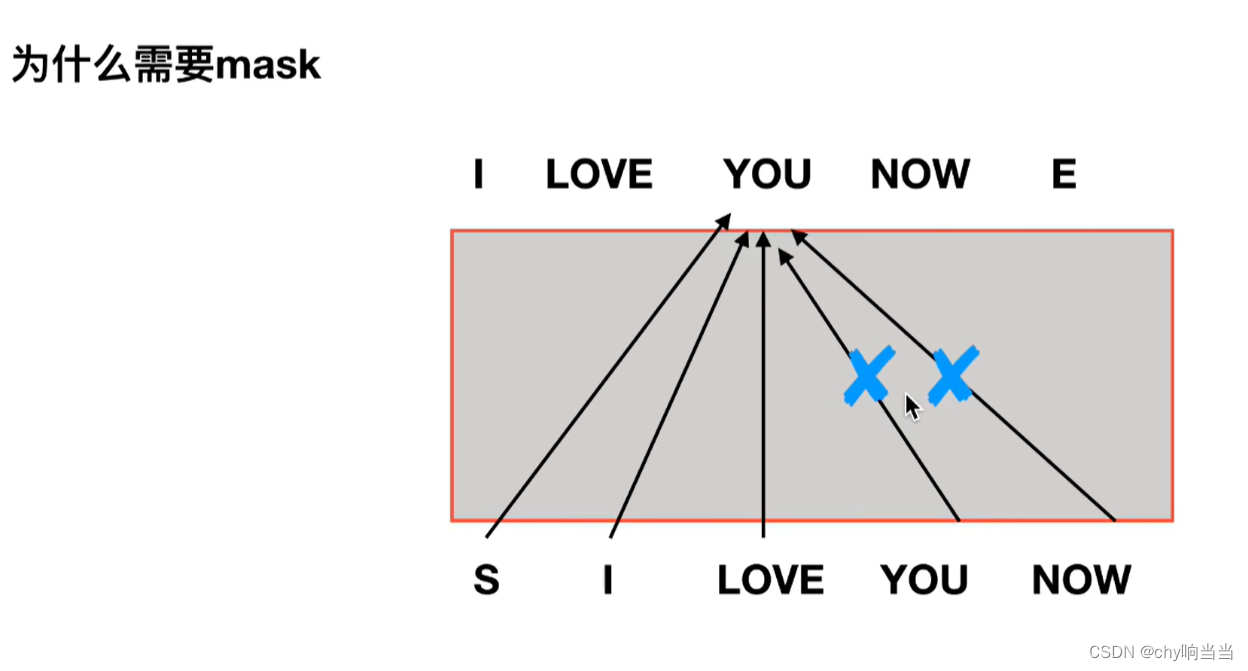
抹掉you now
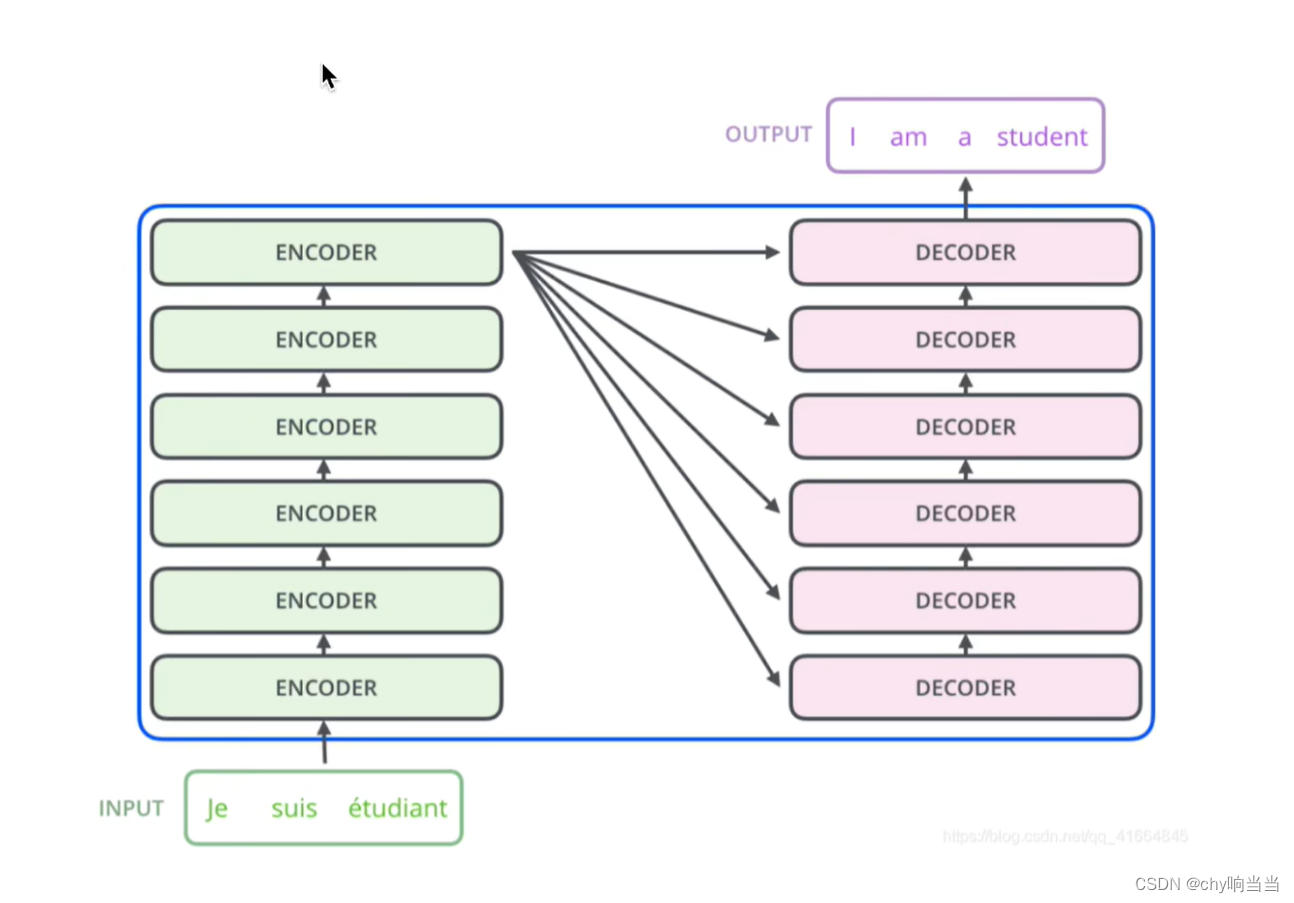
交互层,encoder的输出和每一个decoder交互
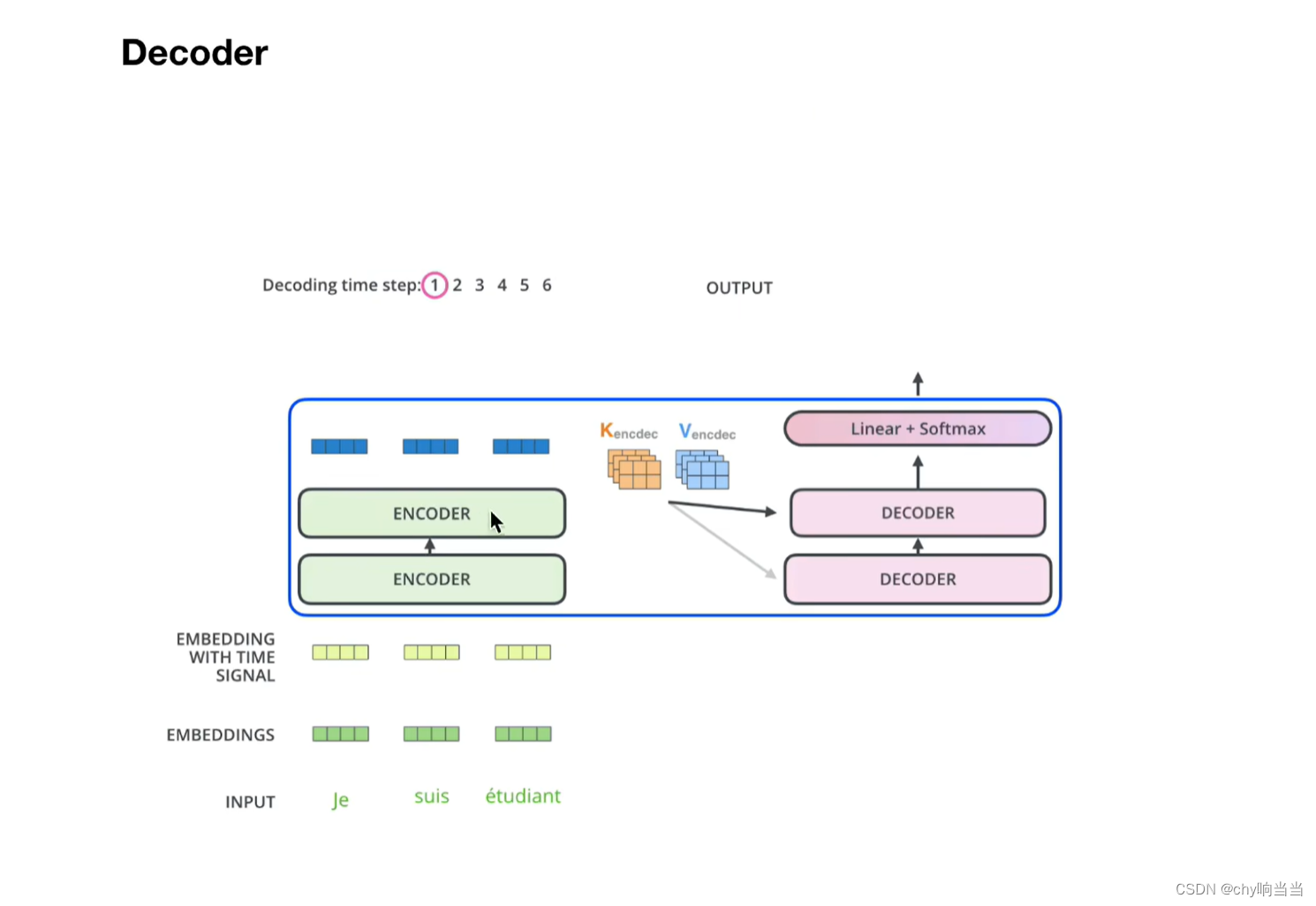 比如encoder输出的值得到KV矩阵,decoder生成的Q矩阵,用于多重注意力机制,KV来自于encoder
比如encoder输出的值得到KV矩阵,decoder生成的Q矩阵,用于多重注意力机制,KV来自于encoder

















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









