




 本文介绍了李沐《动手学深度学习》中的数据操作技巧,包括numpy和torch之间的转换、广播机制,以及如何创建和处理CSV文件。内容涵盖了数据缺失值填充、数据类型转换以及数据集的读取与预处理。
本文介绍了李沐《动手学深度学习》中的数据操作技巧,包括numpy和torch之间的转换、广播机制,以及如何创建和处理CSV文件。内容涵盖了数据缺失值填充、数据类型转换以及数据集的读取与预处理。
李沐动手学深度学习-CH04
数据操作的实现
这边的内容感觉不太需要记录,所以就没有写了,忘记了就查找一下嘛。只是简单记录
值得注意的是如果向量形状不一样,他会有一个广播机制,当然这个广播机制的使用也是有一定条件的(可扩展)
A = X.numpy() # 转换成Numpy张量
B = torch.tensor(A) # 重新转换为torch
创建CSV文件
通过python的os库我们可以创建对应的CSV文件,f.write里面的会分割每一个值,放置到不同的单元格中去
import torch
import os
import pandas as pd
if __name__ == '__main__':
# 这里创建了data文件夹,如果要到上一级目录里面去可以‘..’,exist_ok表示如果存在也没关系
# 例如os.makedirs(os.path.join(‘..', 'data'),exist_ok=True)
os.makedirs(os.path.join('data'),exist_ok=True)
data_file = os.path.join('data', 'test.csv')
with open(data_file, 'w') as f:
f.write('NumRoons,Alley,Price\n')
f.write('NA,Pave,127500\n')
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
从CSV文件中加载数据集并处理
读取csv文件我们使用pandas库,是比较方便的。
data_file = os.path.join('data', 'test.csv')
data = pd.read_csv(data_file)
print(data)
print出来会看到一些NaN的数据缺失,所以我们需要对数据继续一个简单的处理
data_file = os.path.join('data', 'test.csv')
data = pd.read_csv(data_file)
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] # 这里就是选取指定的行列,如果出现越界情况的话看一下csv文件的行列,数据类型<class 'pandas.core.frame.DataFrame'>
inputs = inputs.fillna(inputs.mean()) # 这里是把NA值,填称不是NA值的平均值,仅仅针对数值,左边
inputs = pd.get_dummies(inputs, dummy_na=True) # 这就对字符串的那种单元格进行了处理。具体看截图,右边
x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print(x,y)
数值处理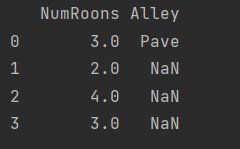
字符处理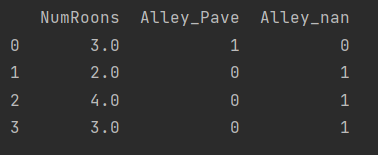 值得注意的是,python数据类型默认是float64,但是以后为了能够更快的完成运算一般都会使用float32
值得注意的是,python数据类型默认是float64,但是以后为了能够更快的完成运算一般都会使用float32

















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









