







TL;DR
- WACV 2024 弗罗茨瓦夫大学的数字人工作,实际是 2023 年 1 月挂出来的,早期用 diffusion 做 talking head 的工作之一。
Paper name
Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation
Paper Reading Note
Paper URL: https://openaccess.thecvf.com/content/WACV2024/papers/Stypulkowski_Diffused_Heads_Diffusion_Models_Beat_GANs_on_Talking-Face_Generation_WACV_2024_paper.pdf
Project URL: https://mstypulkowski.github.io/diffusedheads/
Code URL: https://github.com/MStypulkowski/diffused-heads
Introduction
背景
- 生成逼真的会说话的面孔一直是计算机视觉和图形学中的一个挑战。以往的方法在没有额外参考视频的指导下,很难产生自然的头部运动和面部表情。
- 近年来,基于扩散的生成模型在图像和视频生成方面取得了令人瞩目的进展,其性能已经超越了其他生成模型。
本文方案
- 提出 Diffused Heads,只需要一个身份图像和音频序列就能生成一个逼真的会说话的头部视频。
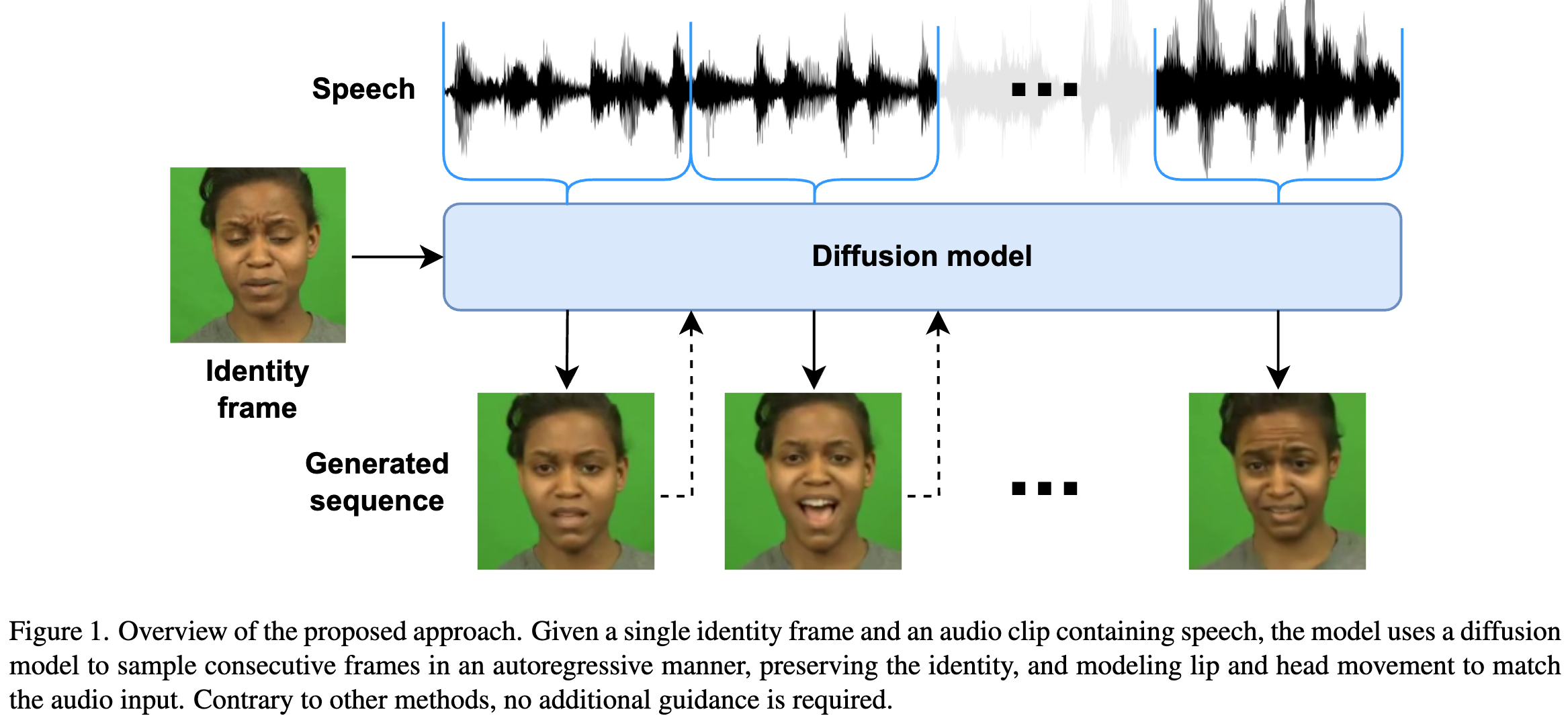
Methods
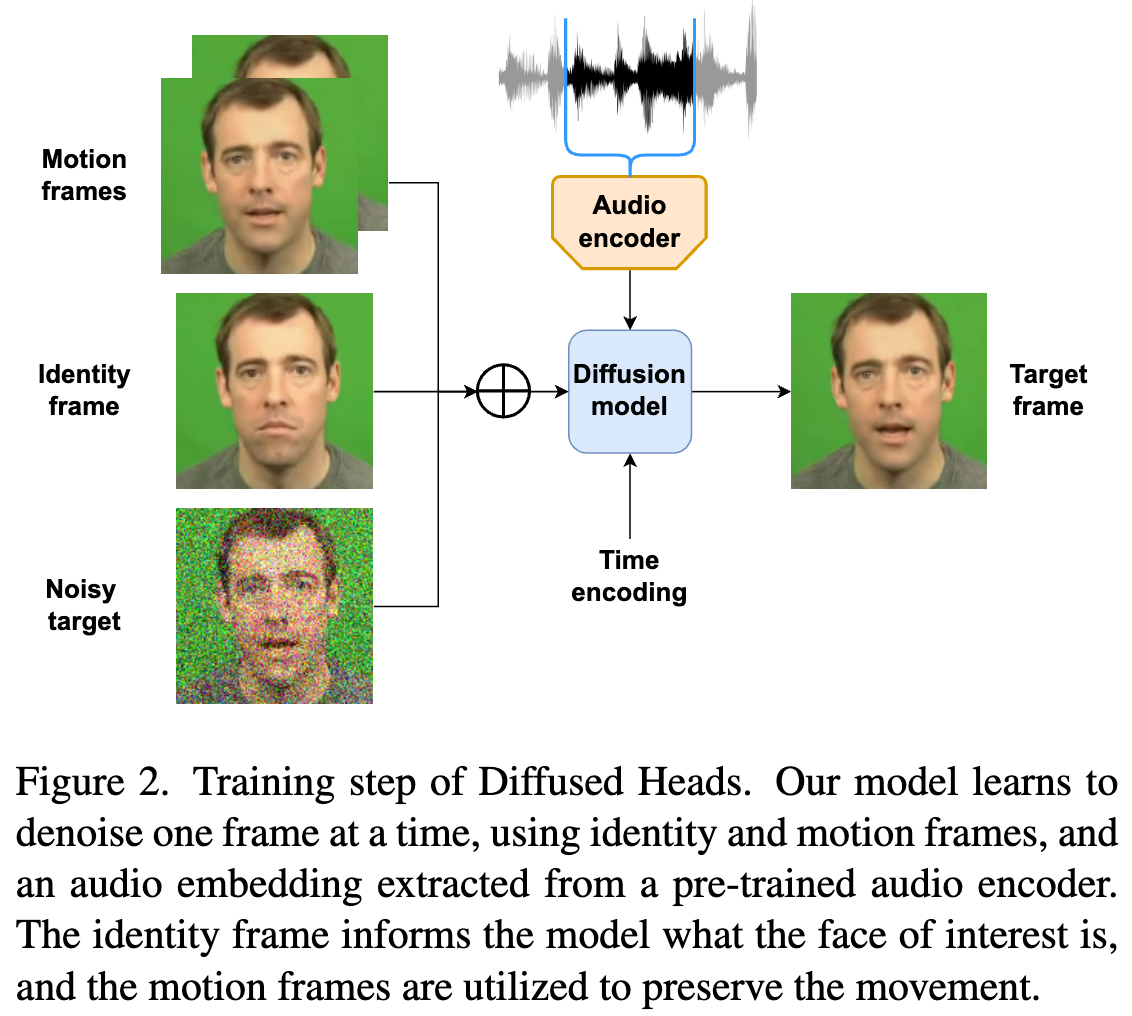
模型架构与训练流程
- pipeline 流程:每次迭代基于 diffusion model 生成一张图片。
- 输入:
- Noisy target:目标帧的加噪
- Identity frame:从视频序列中随机选取的一帧,直接 channel-wise concat 到 Noisy target 上作为 condition
- moiton frames:历史生成的帧,本文选取的历史 2 帧,也是 channel-wise concat 到 Noisy target 作为 condition
- 在初期没有足够的历史帧时,使用 Identity frame 作为历史帧,而不是视频的第一帧 x0,因为第一帧如果是张嘴状态然后没有语音的情况下可能对训练不利
- Audio:使用在 LRW 数据集上训练的 audio encoder 提取特征
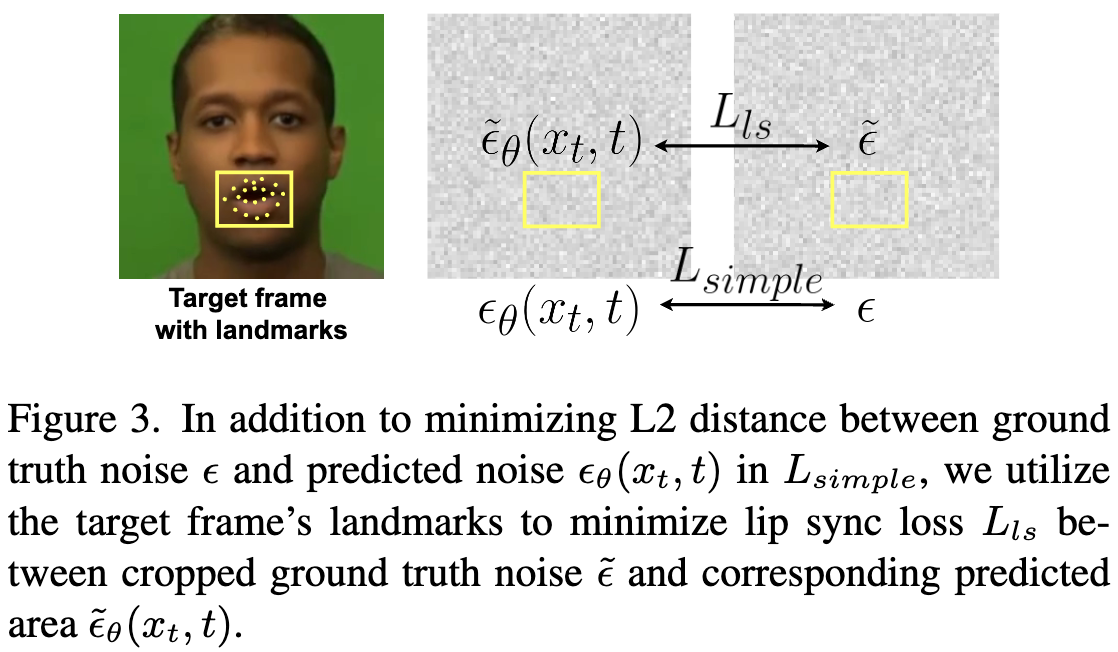
- 因为本文的方案是单帧生成,所以不能用 pre-trained lipreading models 来算 perceptual loss。用嘴巴区域的 landmark 提取嘴巴区域,加大嘴巴区域的 loss 权重
Experiments
实验细节
- 128x128 分辨率视频训练
- Unet 架构的 Diffusion 模型
定性实验结果
- 分别是 CREMA 和 LRW 数据集,diffusion 生成视频和真实视频接近

- 泛化能力验证:使用非训练集数据进行验证

定量实验结果
- 大部分指标是当时的 SOTA
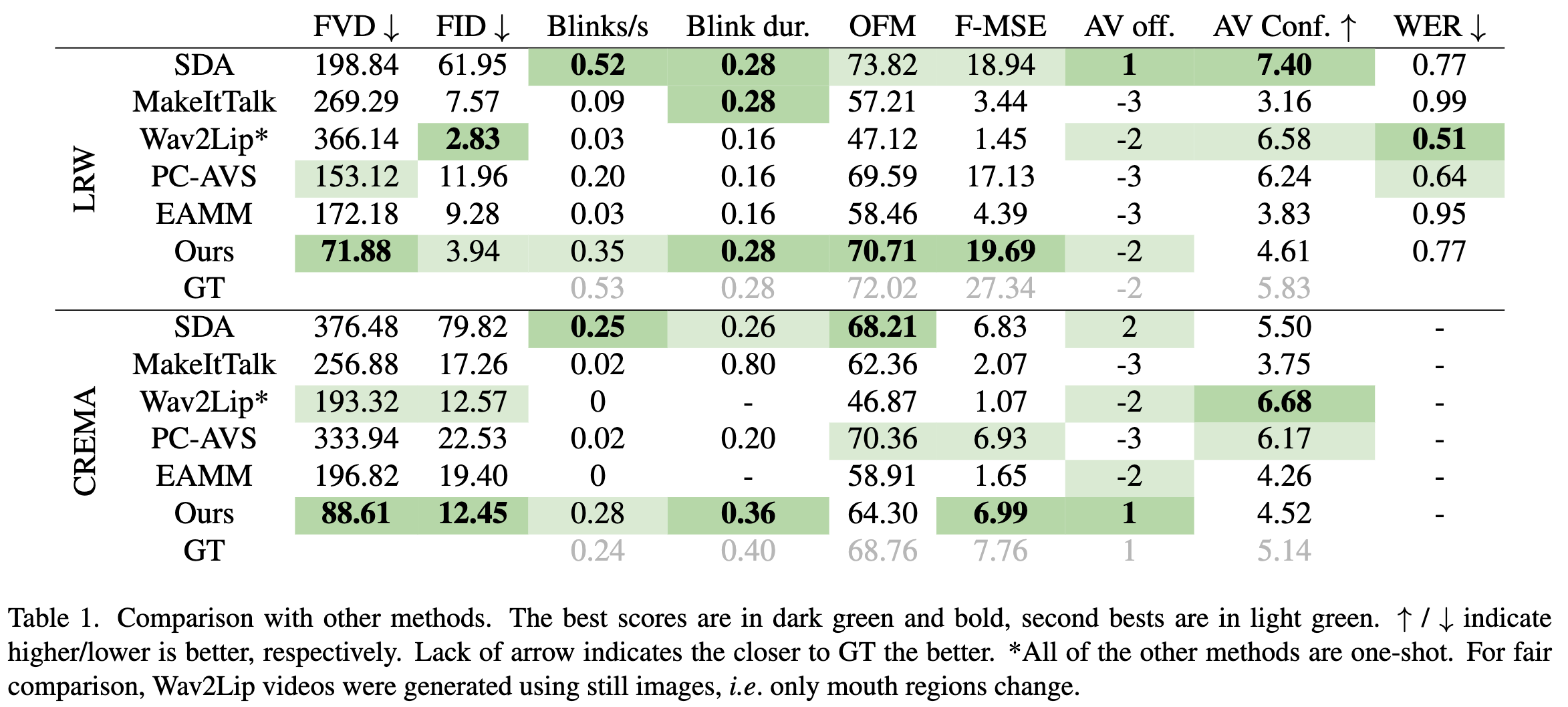
- 人工标注结果也是和真实视频分数接近

消融实验
- motion frames 影响:使用 motion frames 能让连续帧之间的运动更平滑,体现在光流的热力图上就是热度值更低
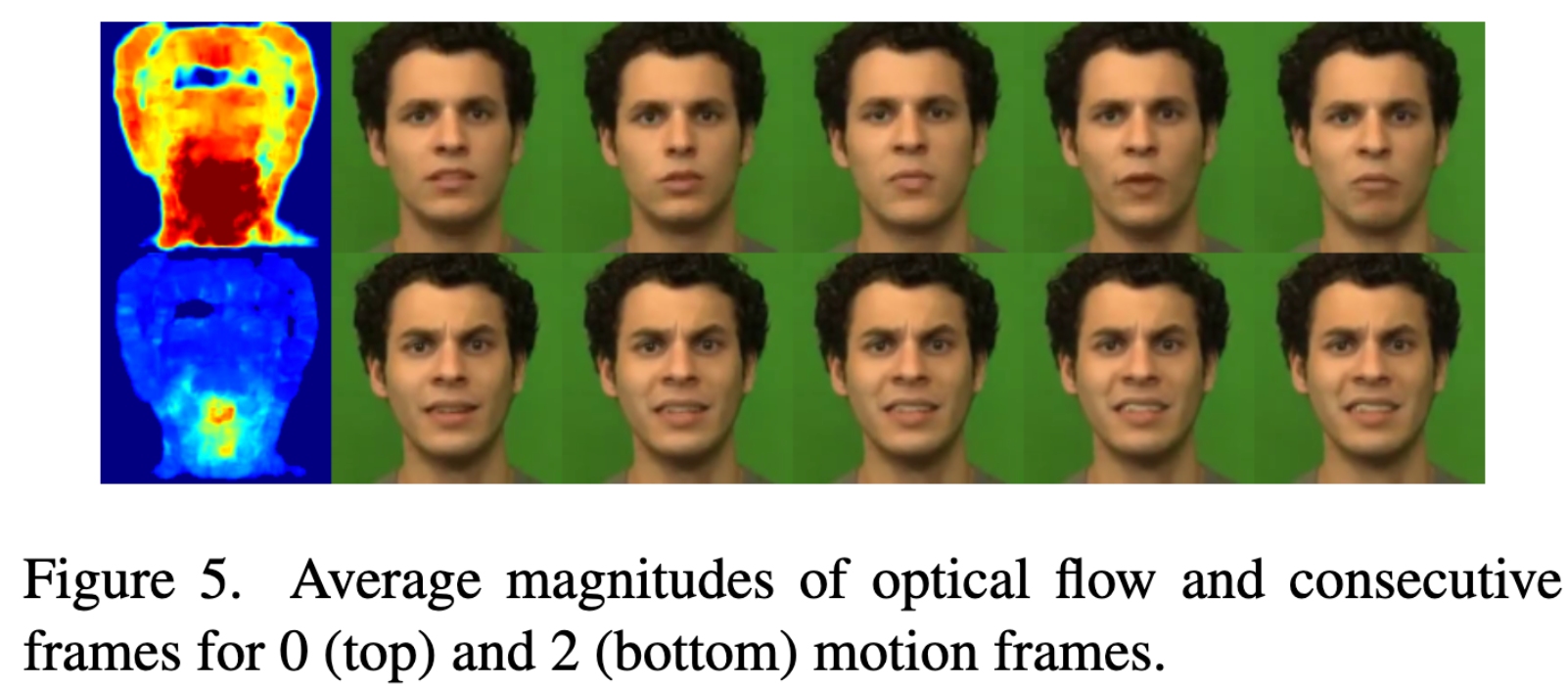
Conclusion
- 验证了 diffusion 在 talking head 任务上的可行性,没有太多雕花的细节,后续很多 diffusion talking head 工作(EMO)和本文方案类似
- 目前方案的缺陷
- 尽管 Diffused Heads 方法达到了比较高的指标,但它仍然存在一些局限性。主要挑战在于生成视频的长度。由于未提供任何额外的姿态输入或头部运动的视觉引导,并且模型是通过自回归方式生成帧,因此对于长度超过 8-9 秒的序列,无法维持初始的高质量
- 扩散模型在生成时间上较长。暂时无法用于实时场景



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









