 Hadoop集群搭建
Hadoop集群搭建





 本文详细介绍了一个包含两个节点的Hadoop集群搭建过程,包括修改配置文件、免密登录设置、格式化命令执行等关键步骤。
本文详细介绍了一个包含两个节点的Hadoop集群搭建过程,包括修改配置文件、免密登录设置、格式化命令执行等关键步骤。
和单机环境相比,集群环境有一些不同,这里以两个节点为例
master:10.1.108.64
slave1:10.1.108.63
namenode:master
datanode:master,slave1
resourcenode:master
1./etc/hosts如下
[root@master hadoop-2.8.0]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.1.108.64 master
10.1.108.63 slave1
2.hdfs-site.xml中replication,单节点的时候是1,这里要改成2
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
3.修改etc/hadoop/slaves,如下:
[root@master hadoop-2.8.0]# cat etc/hadoop/slaves
master
slave1
4.修改etc/hadoop/allnodes,如下:
[root@master hadoop-2.8.0]# cat etc/hadoop/allnodes
master
5.将master的所有配置文件复制到slave1,注意slave1的文件路径必须和master一样
6.在slave1上,修改hdfs-site-xml,如下,并创建对应目录,后续增加其他slave,也不能使用之前别人用的目录,需要新增
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/hdfs/data/slave1</value>
</property>
7.设置master可以免密登陆slave1,如下
scp /root/.ssh/authorized_keys root@10.1.108.63:/root/.ssh
8.slave1上也需要执行格式化命令,效果和master一样,如下
./bin/hdfs namenode -format
9.在master上,先停止服务,再启动服务,命令如下:
./sbin/stop-all.sh
./sbin/start-all.sh
10.在master上查看节点,如下:
[root@master hadoop-2.8.0]# jps
9506 NodeManager
9045 DataNode
9237 SecondaryNameNode
9401 ResourceManager
8939 NameNode
9871 Jps
[root@master hadoop-2.8.0]#
在slave1上查看节点,如下:
[root@slave1 hdfs]# jps
2529 NodeManager
2683 Jps
2415 DataNode
[root@slave1 hdfs]#
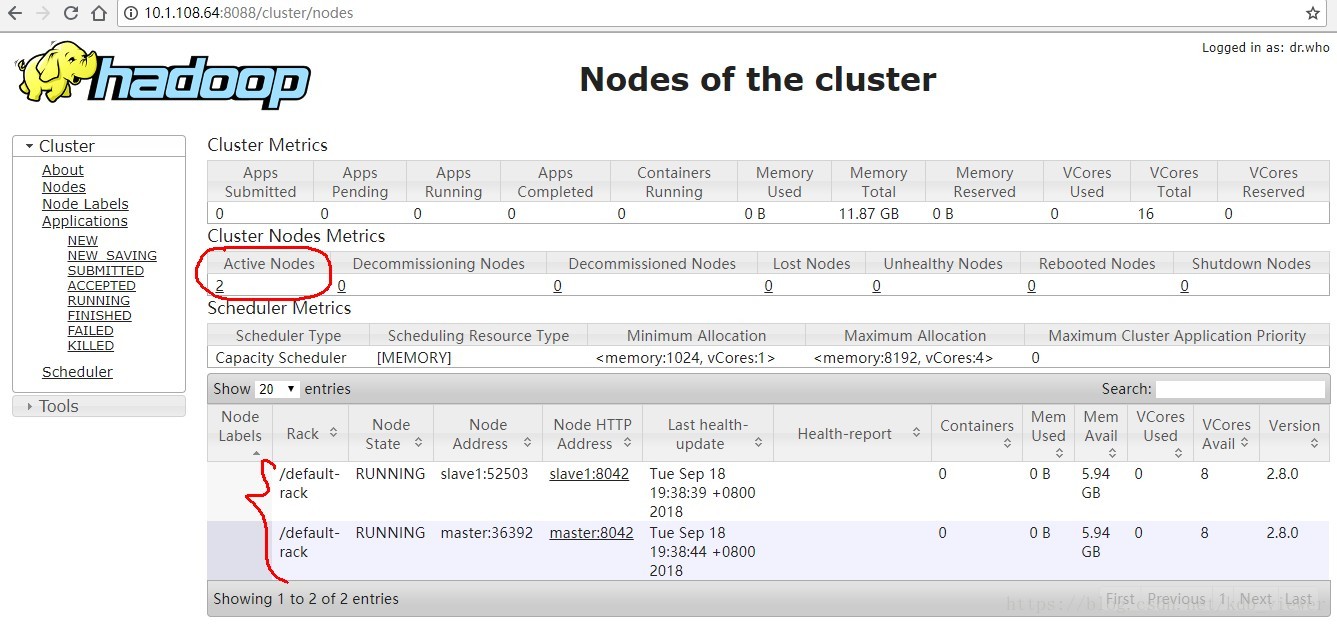
11.在网页端查看节点,如下,显示为主和备:
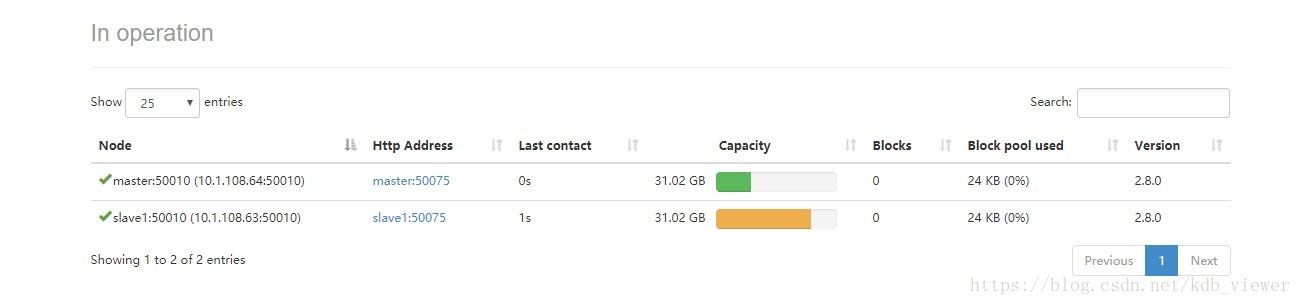
12.在50070下查看datanode,如下:

















 2982
2982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









