






REUSE AND DIFFUSE: ITERATIVE DENOISING FORTEXT-TO-VIDEO GENERATION)学习笔记

motivation:
由于计算和内存资源的限制,将LDM用于t2v任务挑战性较大
单个LDM通常只能生成非常有限的视频帧数,且需要额外的训练成本和帧级抖动
contribution:
Reuse and Diffuse(重用和扩散),根据LDM已经生成的帧生成更多的帧(以具有少量帧的初始视频片段为条件,通过重用原始潜在特征并遵循先前的扩散过程来迭代生成额外的帧。)
对autoencoder插入时间层进行finetuning实现时间一致性
还提出了一套策略,用于组合视频文本数据
method
stable diffusion在t2i任务中表现较好,视频合成任务会加载预训练的LDM(Variational Auto-Encoder (VAE)和U-Net)
通过注入图中虚线框标记的temporal layer(时间层)来适应原始的U-Net,进行图像扩散到视频合成的转变。
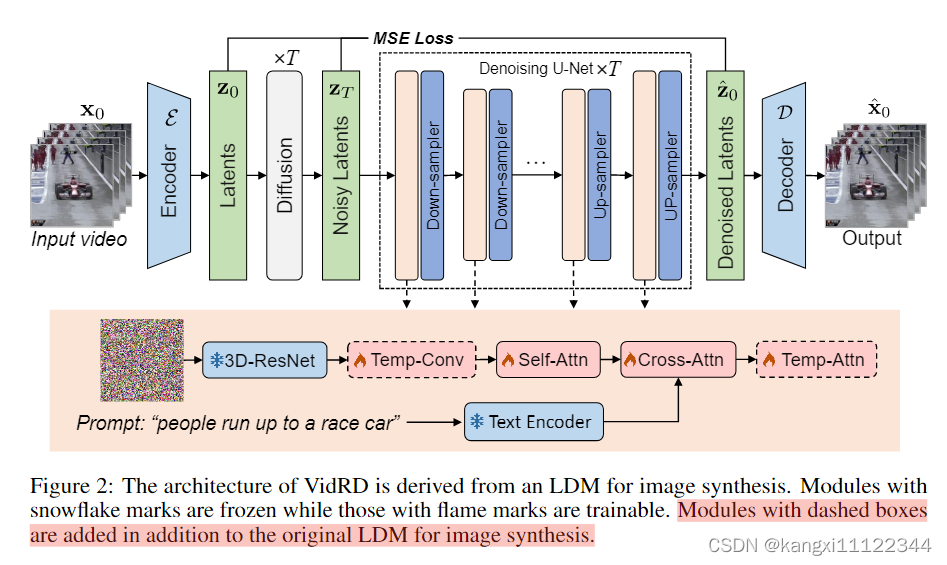
temporal layer分为Temp-Conv(3D卷积层)、Temp-Attn(temporal attention layers)
除了这两个层,其他大多数网络层都使用stable diffusion的预训练模型权重进行初始化
Temp-Conv 和 Temp-Attn 的参数随机初始化
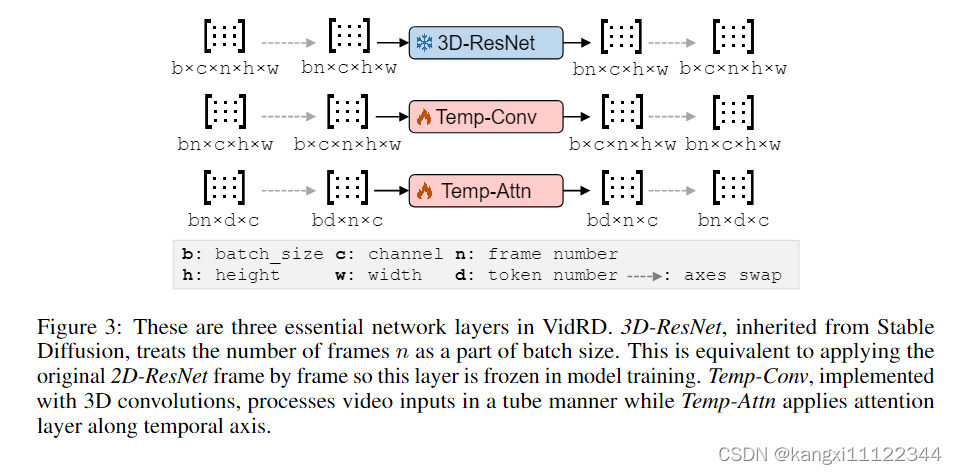
2D ResNet膨胀为3D ResNet
网络层中只有一部分是可训练的,以实现有效的训练,之前的工作,使用图像数据分别微调空间层和视频数据来训练时间层
本工作,以端到端的方式使用纯视频数据进行训练,因为图像数据被转换为伪视频,显示出与原始视频数据相似的时间一致性
视频数据
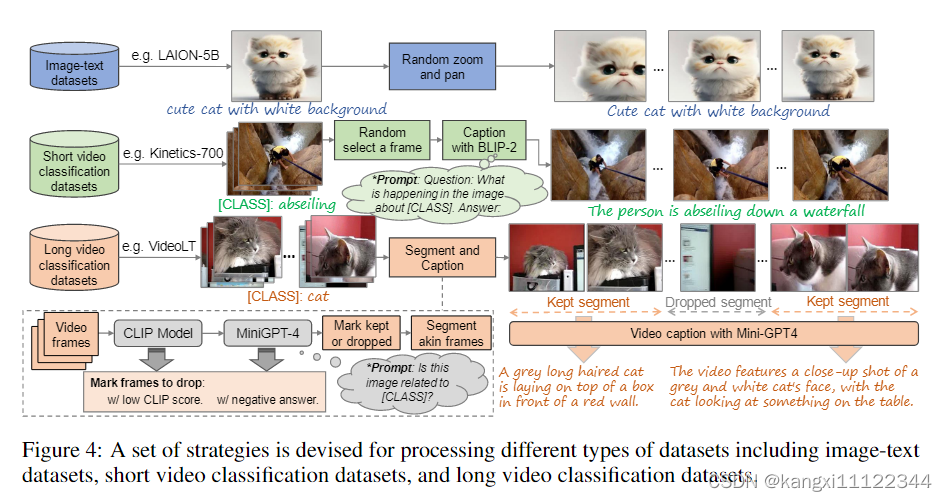
图像-文本数据通过随机缩放和平移来生成多个图像,并进一步组合成伪视频。
短视频的数据集(Kinetics-700),根据每个视频的分类标签给出合适的文本caption。
包含多个场景的长视频(VideoLT),segment-then-caption strategy,先分段在加字幕(Mini-GPT4)。
长视频生成
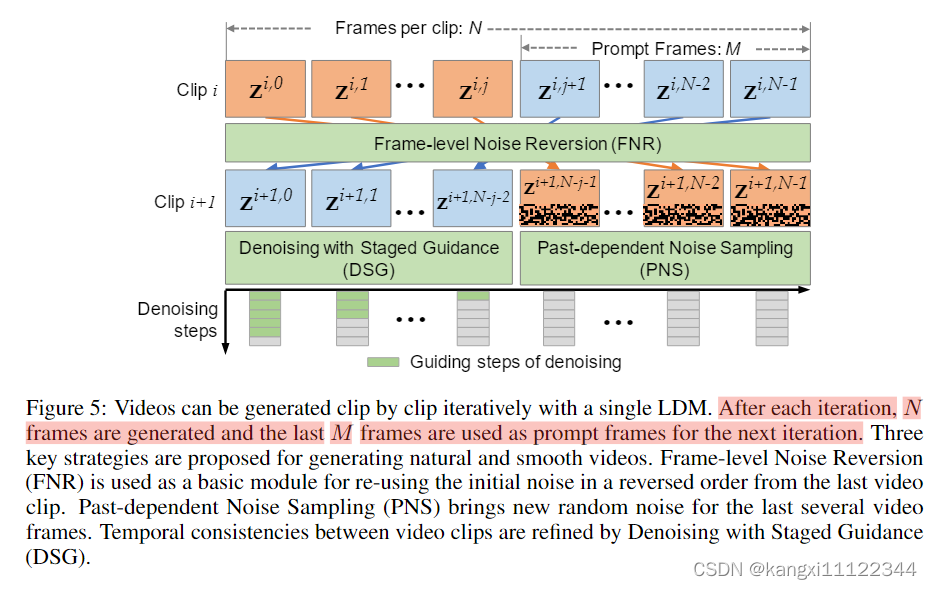
FNR:为了生成平滑的视频,迭代地重用初始噪声,但每次以相反的顺序。
PNS:为了减轻视频内容循环程度,
z
T
i
,
j
=
{
z
T
i
−
1
,
N
−
j
−
1
if
j
<
M
α
1
+
α
2
z
T
i
−
1
,
N
−
j
−
1
+
ϵ
i
,
j
otherwise
,
ϵ
i
,
j
∼
N
(
0
,
1
1
+
α
2
I
)
,
α
≥
0
\mathbf{z}_T^{i,j}=\begin{cases}\mathbf{z}_T^{i-1,N-j-1}&\text{if}\text{ }j<M\\\frac{\alpha}{\sqrt{1+\alpha^2}}\mathbf{z}_T^{i-1,N-j-1}+\epsilon^{i,j}&\text{otherwise}\end{cases},\epsilon^{i,j}\sim\mathcal{N}(0,\frac{1}{1+\alpha^2}\mathbf{I}),\alpha\geq0
zTi,j={zTi−1,N−j−11+α2αzTi−1,N−j−1+ϵi,jif j<Motherwise,ϵi,j∼N(0,1+α21I),α≥0
M帧为参考帧,在参考帧之外加额外的随机噪声,
α
\alpha
α越小,随机噪声占的比率越大
DSG:提高帧之间的连续性,主要是视频clip之间的连续性,
z
0
i
,
N
−
1
\mathbf{z}_0^{i,N-1}
z0i,N−1和
z
0
i
+
1
,
0
\mathbf{z}_0^{i+1,0}
z0i+1,0,
z
t
−
1
i
,
j
=
{
z
t
−
1
i
−
1
,
N
−
j
−
1
if
t
>
(
1
−
β
)
T
+
β
T
j
M
DDIM
(
z
t
i
,
j
,
t
)
otherwise
,
β
∈
[
0
,
1
]
\mathbf{z}_{t-1}^{i,j}=\begin{cases}\mathbf{z}_{t-1}^{i-1,N-j-1}&\text{if}\text{ }t>(1-\beta)T+\frac{\beta Tj}{M}\\\text{DDIM}(\mathbf{z}_t^{i,j},t)&\text{otherwise}\end{cases},\quad\beta\in[0,1]
zt−1i,j={zt−1i−1,N−j−1DDIM(zti,j,t)if t>(1−β)T+MβTjotherwise,β∈[0,1]
前几帧重用上一视频clip的latent futures,
β
\beta
β越小,重用程度越小
experiment
由静态图像的随机缩放和平移产生的伪视频有助于提高时间一致性但损害视觉外观

使用伪视频微调和不使用伪视频微调
与使用静态图像仅训练空间层相比,由静态图像的随机缩放和平移产生的伪视频有助于提高时间一致性但损害视觉外观。
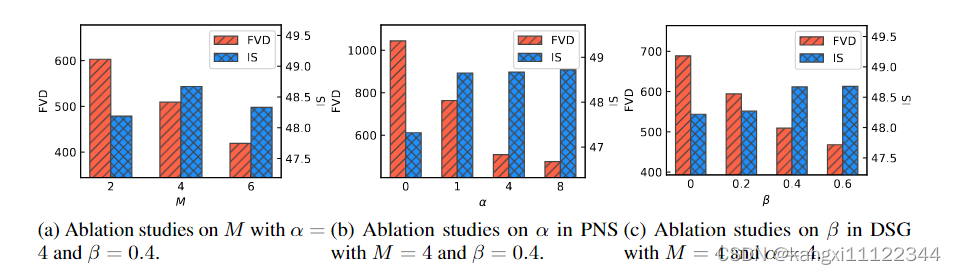
对M(参考帧数量)、
α
\alpha
α、
β
\beta
β消融实验
越大,重用的越多,量化指标较高,视频循环严重


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









