






2019.10.18学习进度
今天是第20天参与STAR Pro,今天主要开始学习了 第三周 *超参数调试、Batch 正则化和程序框架3.1-3.3的内容。*
我了解到了一些选择超参数的策略


2019.10.19学习进度
今天是第21天参与STAR Pro,今天主要继学习了第三周 超参数调试、Batch 正则化和程序框架3.4-3.8batch归一化(BN)的相关内容,知道了它的大概原理以及优点。它不仅可以加快模型的收敛速度么日期一定程度上缓解了深层网络中的“梯度弥散”问题,从而使得训练深层网络模型更加容易和稳定。
靠近输出层的hidden layer 梯度大,参数更新快,所以很快就会收敛;
而靠近输入层的hidden layer 梯度小,参数更新慢,几乎就和初始状态一样,随机分布。
在上面的四层隐藏层网络结构中,第一层比第四层慢了接近100倍!!
这种现象就是梯度弥散(vanishing gradient
problem)。而在另一种情况中,前面layer的梯度通过训练变大,而后面layer的梯度指数级增大,这种现象又叫做梯度爆炸(exploding
gradient problem)。总的来说,就是在这个深度网络中,梯度相当不稳定(unstable)。 直观说明





2019.10.20学习进度
今天是第22天参与STAR Pro,今天主要完成了第三周 超参数调试、Batch 正则化和程序框架剩余内容的学习,至此,我已经学习完了《改善深层神经网络:超参数调试、正则化以及优化》的理论部分
了解了什么是softmax分类器以及它与一般二分类的区别,还知道了如何训练一个softmax分类器,最后简单了解了深度学习框架TensorFlow




2019.10.21学习进度
今天是第23天参与STAR Pro,今天主要在csdn上查找了和了解了gradient checking(梯度检测)的代码实现还有Mini-bantch梯度下降的代码实现。还复习了本周学习的内容。
1.梯度检测

1.把 W[1],b[1],…,W[L],b[L]W[1],b[1],…,W[L],b[L] 转化成向量 θθ。
#convert parameter into vector
def dictionary_to_vector(parameters):
"""
Roll all our parameters dictionary into a single vector satisfying our specific required shape.
"""
count = 0
for key in parameters:
# flatten parameter
new_vector = np.reshape(parameters[key], (-1, 1))#convert matrix into vector
if count == 0:#刚开始时新建一个向量
theta = new_vector
else:
theta = np.concatenate((theta, new_vector), axis=0)#和已有的向量合并成新向量
count = count + 1
return theta
2.把 dW[1],db[1],…,dW[L],db[L]dW[1],db[1],…,dW[L],db[L] 转化成向量 dθdθ。
注:这个地方一定要注意bp求得的gradients字典的存储顺序是{dWL,dbL,…dW2,db2,dW1,db1},因为后面要求欧式距离,所以一定要把顺序转化为[dW1,db1,…dWL,dbL]。
#convert gradients into vector
def gradients_to_vector(gradients):
"""
Roll all our parameters dictionary into a single vector satisfying our specific required shape.
"""
# 因为gradient的存储顺序是{dWL,dbL,....dW2,db2,dW1,db1},
#为了统一采用[dW1,db1,...dWL,dbL]方面后面求欧式距离(对应元素)
L = len(gradients) // 2
keys = []
for l in range(L):
keys.append("dW" + str(l + 1))
keys.append("db" + str(l + 1))
count = 0
for key in keys:
# flatten parameter
new_vector = np.reshape(gradients[key], (-1, 1))#convert matrix into vector
if count == 0:#刚开始时新建一个向量
theta = new_vector
else:
theta = np.concatenate((theta, new_vector), axis=0)#和已有的向量合并成新向量
count = count + 1
return theta
def gradient_check(parameters, gradients, X, Y, layer_dims, epsilon=1e-7):
parameters_vector = dictionary_to_vector(parameters) # parameters_values
grad = gradients_to_vector(gradients)
num_parameters = parameters_vector.shape[0]
J_plus = np.zeros((num_parameters, 1))
J_minus = np.zeros((num_parameters, 1))
gradapprox = np.zeros((num_parameters, 1))
# Compute gradapprox
for i in range(num_parameters):
thetaplus = np.copy(parameters_vector)
thetaplus[i] = thetaplus[i] + epsilon
AL, _ = forward_propagation(X, vector_to_dictionary(thetaplus,layer_dims))
J_plus[i] = compute_cost(AL,Y)
thetaminus = np.copy(parameters_vector)
thetaminus[i] = thetaminus[i] - epsilon
AL, _ = forward_propagation(X, vector_to_dictionary(thetaminus, layer_dims))
J_minus[i] = compute_cost(AL,Y)
gradapprox[i] = (J_plus[i] - J_minus[i]) / (2 * epsilon)
numerator = np.linalg.norm(grad - gradapprox)
denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox)
difference = numerator / denominator
if difference > 2e-7:
print(
"\033[93m" + "There is a mistake in the backward propagation! difference = " + str(difference) + "\033[0m")
else:
print(
"\033[92m" + "Your backward propagation works perfectly fine! difference = " + str(difference) + "\033[0m")
return difference
这里在每一次计算bp时,还要把向量转化成矩阵,具体实现如下:
#convert vector into dictionary
def vector_to_dictionary(theta, layer_dims):
"""
Unroll all our parameters dictionary from a single vector satisfying our specific required shape.
"""
parameters = {}
L = len(layer_dims) # the number of layers in the network
start = 0
end = 0
for l in range(1, L):
end += layer_dims[l]*layer_dims[l-1]
parameters["W" + str(l)] = theta[start:end].reshape((layer_dims[l],layer_dims[l-1]))
start = end
end += layer_dims[l]*1
parameters["b" + str(l)] = theta[start:end].reshape((layer_dims[l],1))
start = end
return parameters
Mini-batch梯度下降
def compute_grad_batch(beta, batch_size, x, y):
grad = [0, 0]
r = np.random.choice(range(len(x)), batch_size, replace=False)
grad[0] = 2. * np.mean(beta[0] + beta[1] * x[r] - y[r])
grad[1] = 2. * np.mean(x[r] * (beta[0] + beta[1] * x[r] - y[r]))
return np.array(grad)
# 引用模块
import pandas as pd
import numpy as np
# 导入数据
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submit = pd.read_csv('sample_submit.csv')
# 初始设置
beta = [1, 1]
alpha = 0.2
tol_L = 0.1
batch_size = 16
# 对x进行归一化
max_x = max(train['id'])
x = train['id'] / max_x
y = train['questions']
# 定义计算mini-batch随机梯度的函数
def compute_grad_batch(beta, batch_size, x, y):
grad = [0, 0]
r = np.random.choice(range(len(x)), batch_size, replace=False)
grad[0] = 2. * np.mean(beta[0] + beta[1] * x[r] - y[r])
grad[1] = 2. * np.mean(x[r] * (beta[0] + beta[1] * x[r] - y[r]))
return np.array(grad)
# 定义更新beta的函数
def update_beta(beta, alpha, grad):
new_beta = np.array(beta) - alpha * grad
return new_beta
# 定义计算RMSE的函数
def rmse(beta, x, y):
squared_err = (beta[0] + beta[1] * x - y) ** 2
res = np.sqrt(np.mean(squared_err))
return res
# 进行第一次计算
np.random.seed(10)
grad = compute_grad_batch(beta, batch_size, x, y)
loss = rmse(beta, x, y)
beta = update_beta(beta, alpha, grad)
loss_new = rmse(beta, x, y)
# 开始迭代
i = 1
while np.abs(loss_new - loss) > tol_L:
beta = update_beta(beta, alpha, grad)
grad = compute_grad_batch(beta, batch_size, x, y)
if i % 100 == 0:
loss = loss_new
loss_new = rmse(beta, x, y)
print('Round %s Diff RMSE %s'%(i, abs(loss_new - loss)))
i += 1
print('Coef: %s \nIntercept %s'%(beta[1], beta[0]))
2019.10.22学习进度
今天是第24天参与STAR Pro,今天主要完成了以下两方面:
1.卷积神经网络第一周:卷积神经网络 的学习
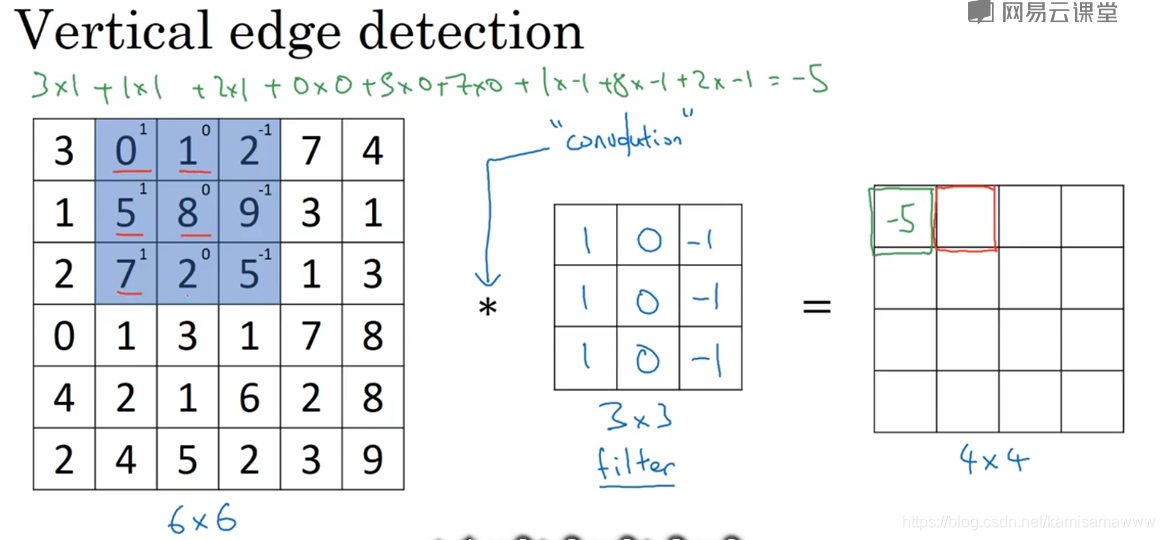
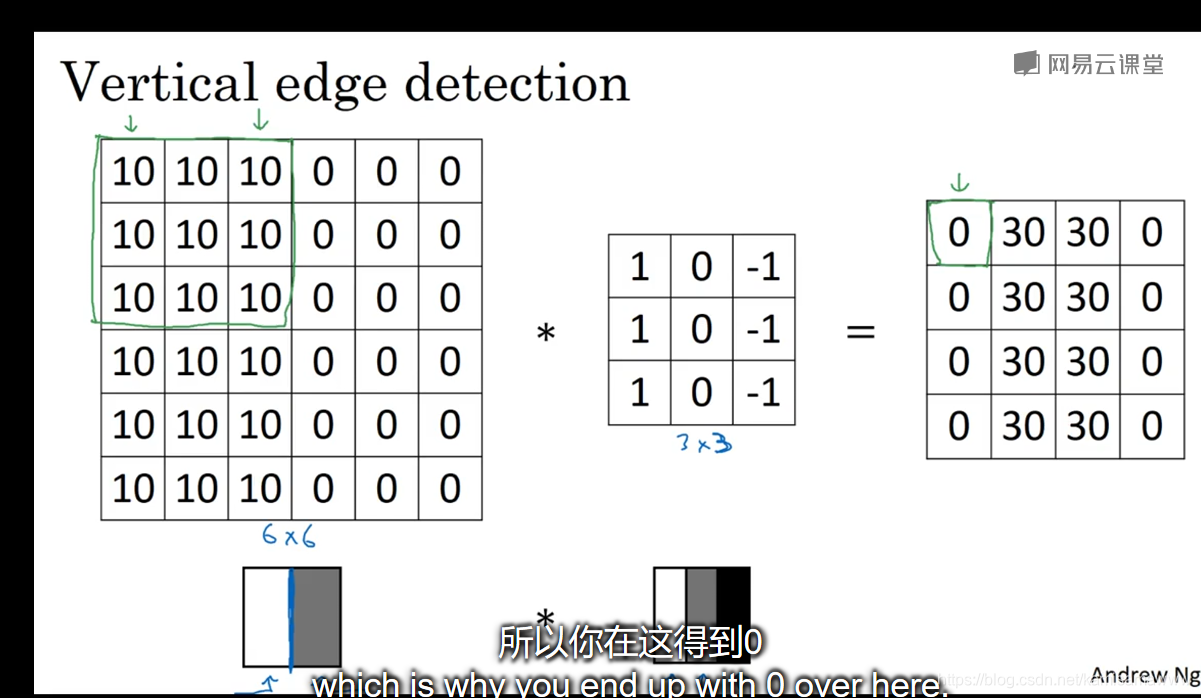
 简单了解了计算机视觉的概念以及卷积神经网络的作用及其基本组成部分——卷积运算
简单了解了计算机视觉的概念以及卷积神经网络的作用及其基本组成部分——卷积运算

2.优化算法的代码的了解
由于我在couresra的助学金还没申请下来,所以在csdn上找了并简单了解了优化算法的代码实现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









