




一、新增员工
1.1 新增员工
1.1.1 实现思路
在新增员工的时候,在表单中,我们既要录入员工的基本信息,又要录入员工的工作经历信息。 员工基本信息,对应的表结构是emp表,员工工作经历信息,对应的表结构是emp_expr 表,所以这里我们要操作两张表,往两张表中保存数据。
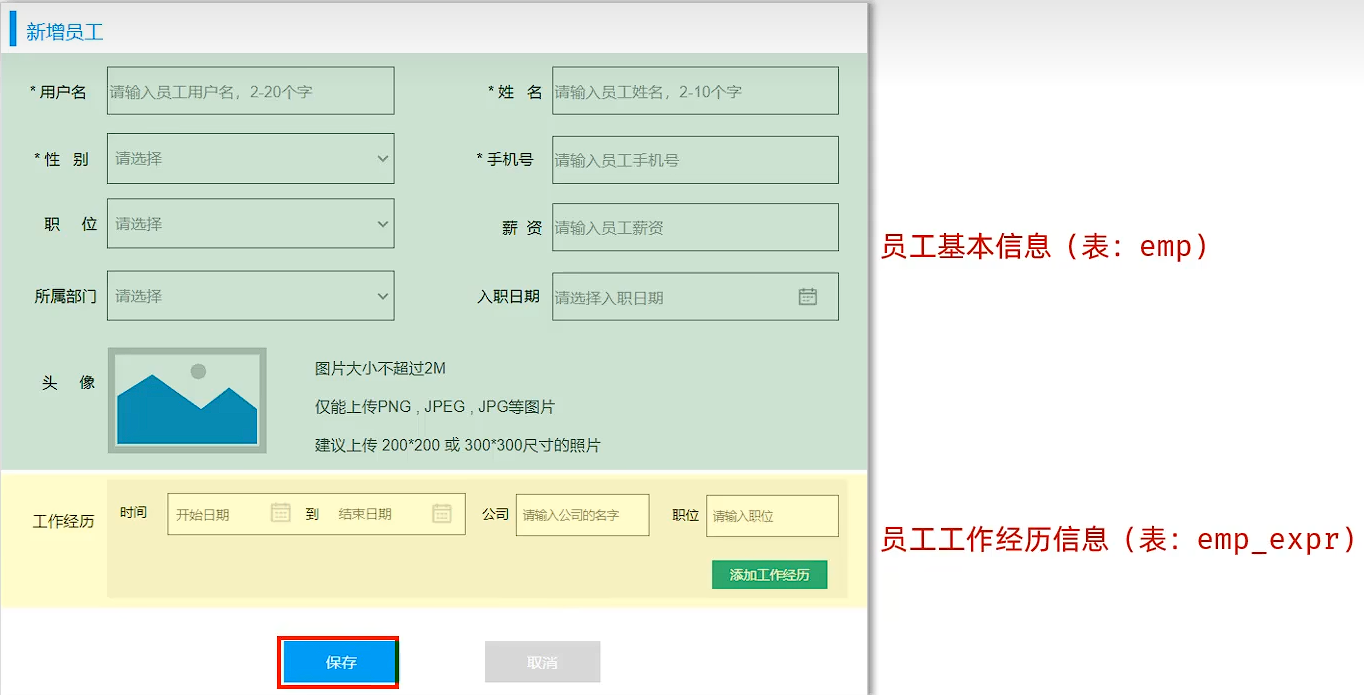
- 请求路径:
/emps- 请求方式:POST
- 接口描述:该接口用于添加员工的信息
- 请求参数样例:
{ "image": "https://web-framework.oss-cn-hangzhou.aliyuncs.com/2022-09-03-07-37-38222.jpg", "username": "孟德", "name": "曹操", "gender": 1, "job": 1, "entryDate": "2022-09-18", "deptId": 1, "phone": "18809091234", "salary": 80000, "exprList": [ { "company": "强汉股份有限公司", "job": "java开发", "begin": "2012-07-01", "end": "2019-03-03" }, { "company": "曹魏股份有限公司", "job": "架构师", "begin": "2019-03-15", "end": "2023-03-01" } ] }- 响应数据样例:
{ "code":1, "msg":"success", "data":null }
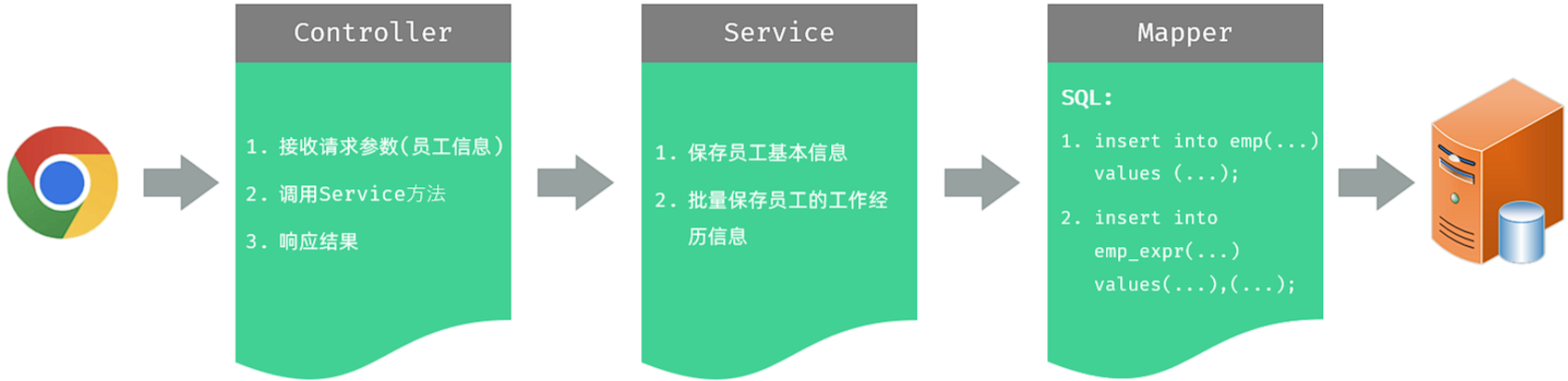
实现该功能时,三层架构每一层的职责:
-
Controller层:负责接收前端发起的请求,参数为员工信息和工作经历信息,并调用Service分页查询部门数据,然后响应数据。
-
Service层:负责调用Mapper接口方法,批量保存员工的基本信息和工作经历信息。
-
Mapper层:执行SQL语句执行插入两张数据表数据的操作。
新增员工基本信息的SQL语句:
insert into emp(username, name, gender, phone, job, salary, image, entry_date, dept_id, create_time, update_time)
values (#{username},#{name},#{gender},#{phone},#{job},#{salary},#{image},#{entryDate},#{deptId},#{createTime},#{updateTime})新增员工工作经历的SQL语句:
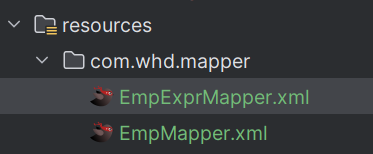
1.1.2 准备工作
准备 EmpExprMapper接口的映射配置文件 EmpExprMapper.xml ,并准备实体类接收前端传递的json格式的请求参数。
EmpExprMapper.xml 配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.whd.mapper.EmpExprMapper">
</mapper>请求参数有工作经历的列表,所以我们需要在Emp员工实体类中增加属性exprList来封装工作经历数据。 最终完整代码如下:
package com.whd.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.util.List;
/**
* 员工实体类
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Emp {
private Integer id; //ID,主键
private String username; //用户名
private String password; //密码
private String name; //姓名
private Integer gender; //性别, 1:男, 2:女
private String phone; //手机号
private Integer job; //职位, 1:班主任,2:讲师,3:学工主管,4:教研主管,5:咨询师
private Integer salary; //薪资
private String image; //头像
private LocalDate entryDate; //入职日期
private Integer deptId; //关联的部门ID
private LocalDateTime createTime; //创建时间
private LocalDateTime updateTime; //修改时间
//封装部门名称数
private String deptName; //部门名称
//封装工作经历信息
private List<EmpExpr> exprList; //工作经历
}
1.1.3 代码实现
1.1.3.1 Controller层
在EmpController上增加save方法,因为controller中需要接收的是json格式的请求参数,所以要在Emp前加注解@RequestBody,代码如下:
/**
* 添加员工
*/
@PostMapping
public Result save(@RequestBody Emp emp){
log.info("请求参数emp: {}", emp);
empService.save(emp);
return Result.success();
}1.1.3.2 Service层
在EmpService上增加save方法,代码如下:
/**
* 新增员工信息
*/
void save(Emp emp);在EmpServiceImpl上实现save方法,先完成保存员工基本信息的代码,代码如下:
/**
* 新增员工信息
*/
@Override
public void save(Emp emp) {
//1.补全基础属性,将创建时间和更新时间设置为当前系统更新时间
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//2.保存员工的基本信息
empMapper.insert(emp);
//3.保存员工工作经历信息
}之后保存员工工作经历的代码在完成EmpExprMapper接口的逻辑之后补全。
1.1.3.3 Mapper层
在EmpMapper上增加save方法,目的是插入员工信息,代码如下:
/**
* 新增员工基本信息
*/
@Insert("insert into emp(username, name, gender, phone, job, salary, image, entry_date, dept_id, create_time, update_time) " +
"values (#{username},#{name},#{gender},#{phone},#{job},#{salary},#{image},#{entryDate},#{deptId},#{createTime},#{updateTime})")
public void insert(Emp emp);@Options(useGeneratedKeys = true,keyProperty = "id")
由于稍后,我们在保存工作经历信息的时候,需要记录是哪位员工的工作经历。 所以,保存完员工信息之后,是需要获取到员工的ID的,那这里就需要通过Mybatis中提供的主键返回功能来获取。
在EmpExprMapper上增加insertBatch方法,目的是批量保存员工工作经历,代码如下:
/**
* 员工工作经历
*/
@Mapper
public interface EmpExprMapper {
/**
* 批量保存工作经历信息
*/
public void insertBatch(List<EmpExpr> exprList);
}在EmpExprMapper接口的映射配置文件 EmpExprMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.whd.mapper.EmpExprMapper">
<!--批量的插入员工经历信息
foreach标签:
collection:遍历集合的属性名
item:集合中的元素
separator:每次循环之间的分隔符
index:索引
open:开始符号
close:结束符号
-->
<insert id="insertBatch">
insert into emp_expr(emp_id,begin,end,company,job) values
<foreach collection="exprList" item="expr" separator=",">
(#{expr.empId},#{expr.begin},#{expr.end},#{expr.company},#{expr.job})
</foreach>
</insert>
</mapper>这里用到Mybatis中的动态SQL里提供的
<foreach>标签,改标签的作用,是用来遍历循环,常见的属性说明:
collection:集合名称
item:集合遍历出来的元素/项
separator:每一次遍历使用的分隔符
open:遍历开始前拼接的片段
close:遍历结束后拼接的片段
上述的属性,是可选的,并不是所有的都是必须的。 可以自己根据实际需求,来指定对应的属性。
现在可以补全EmpServiceImpl工作经历的代码了。
package com.whd.service.impl;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import com.whd.mapper.EmpExprMapper;
import com.whd.mapper.EmpMapper;
import com.whd.pojo.*;
import com.whd.service.EmpLogService;
import com.whd.service.EmpService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.CollectionUtils;
import org.springframework.web.bind.annotation.RequestParam;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.util.List;
/**
* 员工管理
*/
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpMapper empMapper;
@Autowired
private EmpExprMapper empExprMapper;
/**
* 新增员工信息
*/
@Override
public void save(Emp emp) {
//1.补全基础属性,将创建时间和更新时间设置为当前系统更新时间
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//2.保存员工的基本信息
empMapper.insert(emp);
//3.保存员工工作经历信息
List<EmpExpr> exprList = emp.getExprList();
// 工作经历可能为空,所以我们需要判断一下
// CollectionUtils的作用是:判断集合是否为空,为空返回true,不为空返回false
if (!CollectionUtils.isEmpty(exprList)){
// 遍历集合,为每个工作经历的empId设置当前保存的员工的id
exprList.forEach(expr -> expr.setEmpId(emp.getId()));
// 批量保存
empExprMapper.insertBatch(exprList);
}
}
}1.1.4 导入数据功能测试
将接口资料导入到Apifox
![]()
确定导入
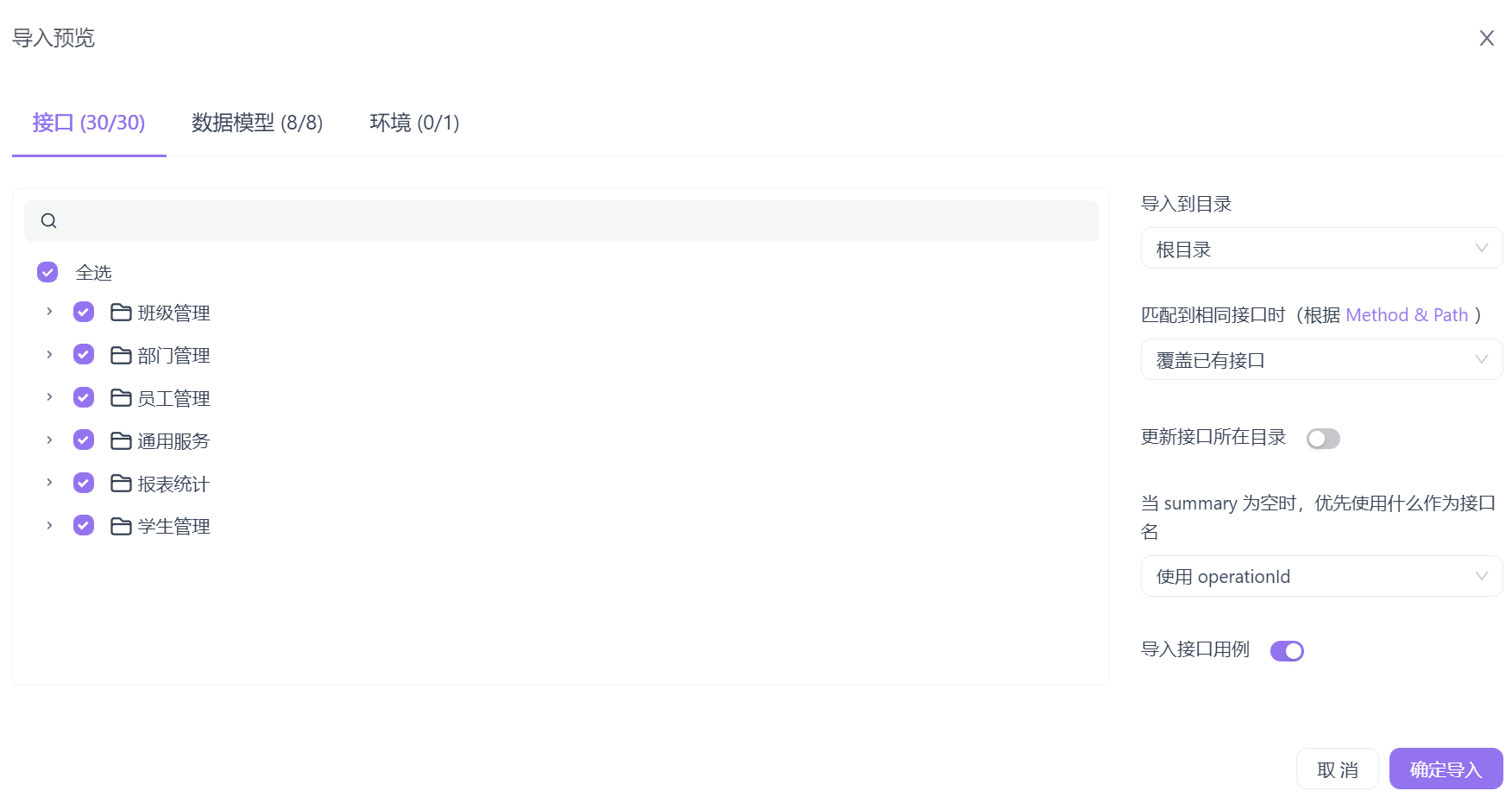
导入成功预览

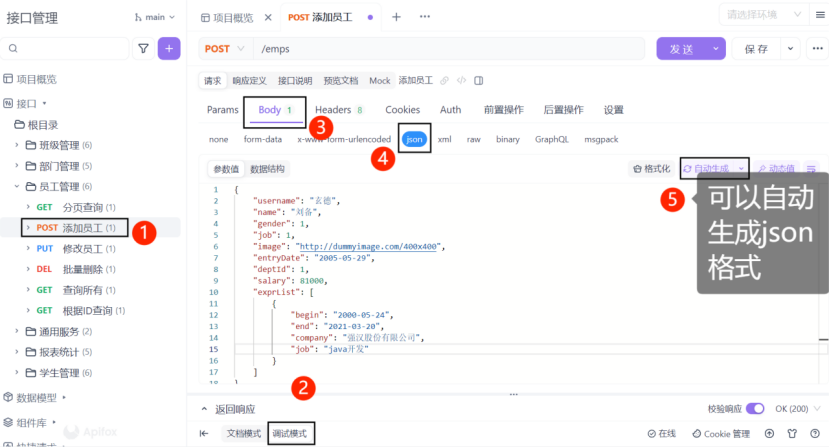
测试POST接口,自动生成会根据我们定义的接口文档自动生成json模拟数据,但生成的数据数据可能不规范,需要手动修改。
发送数据之前要先设置环境:
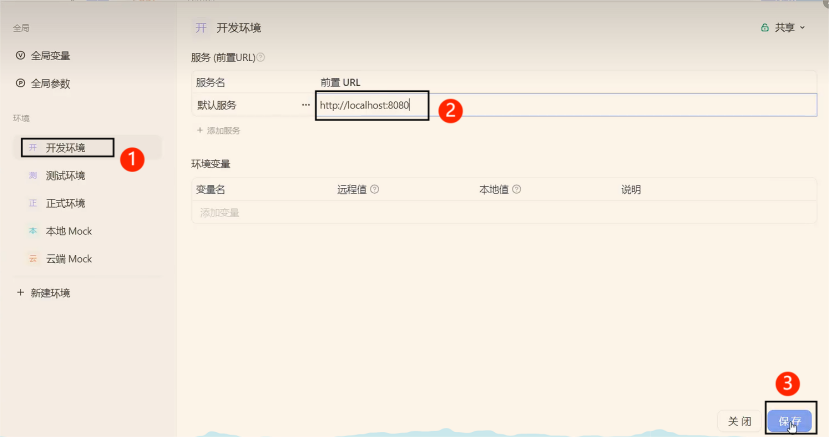
选择开发环境:

测试成功:
1.2 事务
1.2.1 什么是事务?
概念: 事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
就拿添加员工的这个业务为例,在这个业务操作中,包含了两个操作,那这两个操作是一个不可分割的工作单位。这两个操作,要么同时失败,要么同时成功。

默认MySQL的事务是自动提交的,也就是说,当执行一条DML语句,MySQL会立即隐式的提交事务。
1.2.2 事务操作
事务控制主要三步操作:开启事务、提交事务/回滚事务。
-
需要在这组操作执行之前,先开启事务(start transaction; / begin;)。
-
所有操作如果全部都执行成功,则提交事务(commit;)。
-
如果这组操作中,有任何一个操作执行失败,则运行回滚事务(rollback;),就会撤回之前但是操作。
-- 开启事务
start transaction; / begin;
-- 1. 保存员工基本信息
insert into emp values (39, 'Tom', '123456', '汤姆', 1, '13300001111', 1, 4000, '1.jpg', '2023-11-01', 1, now(), now());
-- 2. 保存员工的工作经历信息
insert into emp_expr(emp_id, begin, end, company, job) values (39,'2019-01-01', '2020-01-01', '百度', '开发'), (39,'2020-01-10', '2022-02-01', '阿里', '架构');
-- 提交事务(全部成功)
commit;
-- 回滚事务(有一个失败)
rollback;事务管理的场景,是非常多的,比如:
-
银行转账
-
下单扣减库存
在一个业务当中要操作多个数据表中的数据,要对事务进行增删操作,那就涉及到事务了。
1.2.3 为什么需要事务
目前我们实现的新增员工功能中,操作了两次数据库,执行了两次 insert 操作。
-
第一次:保存员工的基本信息到
emp表中。 -
第二次:保存员工的工作经历信息到
emp_expr表中。
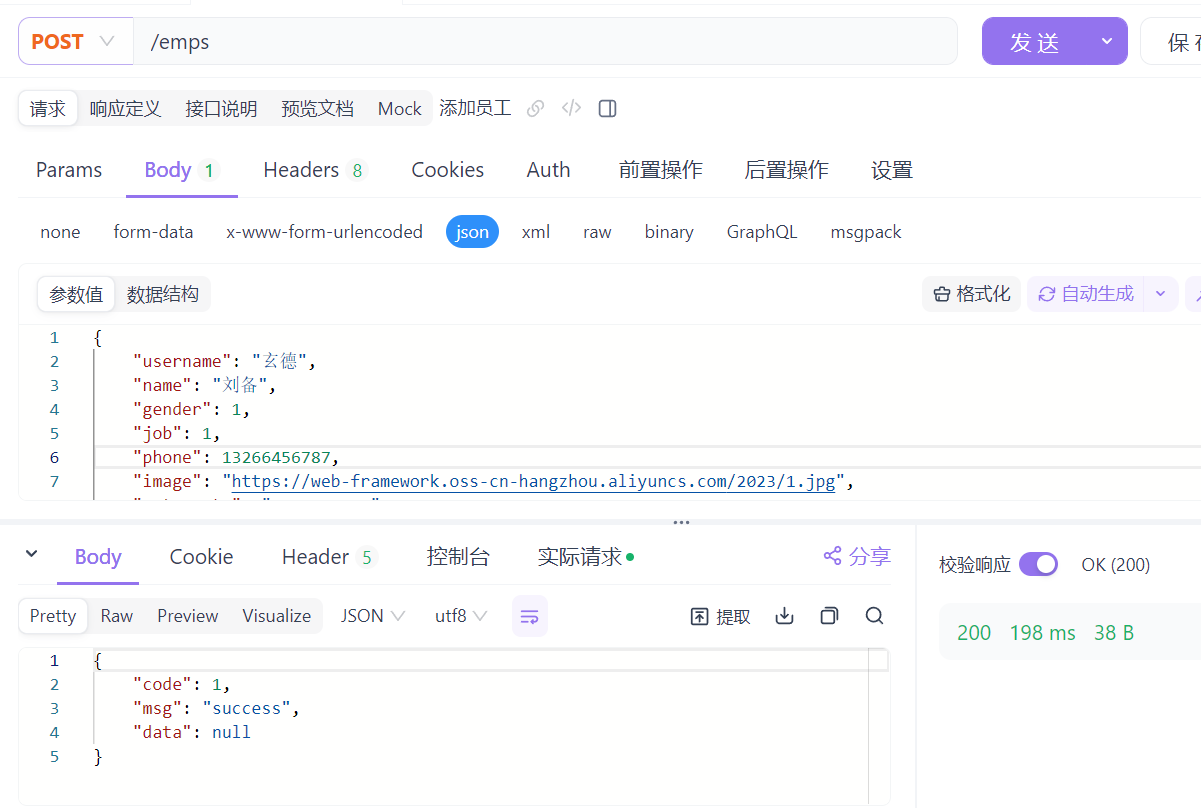
如果说,保存员工的基本信息成功了,而保存员工的工作经历信息出错了,会发生什么现象呢?那接下来,我们来做一个测试 。 我们可以在代码中,人为在保存员工的service层的save方法中,构造一个错误:

运行后可以打开IDEA控制台看一下,报出的错误信息。 我们看到,保存了员工的基本信息之后,系统出现了除0异常。

程序先执行新增员工的操作,这步执行完毕,就已经往员工表 emp 插入了数据。之后执行除0 操作,抛出异常,抛出异常之后,下面所有的代码都不会执行了,同样批量保存工作经历信息这个操作也不会执行 。
程序出现了异常 ,员工表 emp 数据保存成功了, 但是 emp_expr 员工工作经历信息表,数据保存失败了。 那是否允许这种情况发生呢?
不允许,因为这属于一个业务操作,如果保存员工信息成功了,保存工作经历信息失败了,就会造成数据库数据的不完整、不一致。
1.3 Spring事务管理
问题:员工基本信息保存,但员工的工作经历信息未保存,导致业务操作前后数据不一致。
方法:想保证操作前后,数据的一致性,就需要让新增员工中涉及到的两个业务操作,要么全部成功,要么全部失败。就可以通过事务来实现,因为一个事务中的多个业务操作,要么全部成功,要么全部失败。
此时,我们就需要在新增员工功能中添加事务。在方法运行之前,开启事务,如果方法成功执行,就提交事务,如果方法执行的过程当中出现异常了,就回滚事务。
在spring框架当中就已经把事务控制的代码都已经封装好了,并不需要我们手动实现。我们使用了spring框架,我们只需要通过一个简单的注解@Transactional就搞定了。
1.3.1 Transactional注解
注解:@Transactional
作用:就是在当前这个方法执行开始之前来开启事务,方法执行完毕之后提交事务。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作。
位置:业务层的方法上、类上、接口上
-
方法上:当前方法交给spring进行事务管理
-
类上:当前类中所有的方法都交由spring进行事务管理
-
接口上:接口下所有的实现类当中所有的方法都交给spring进行事务管理
1.3.2 修改代码
在EmpServiceImpl的save方法上加上@Transactional来控制事务,代码如下:
/**
* 新增员工信息
*/
@Override
@Transactional //事务注解
public void save(Emp emp) {
//1.补全基础属性,将创建时间和更新时间设置为当前系统更新时间
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//2.保存员工的基本信息
empMapper.insert(emp);
//3.保存员工工作经历信息
List<EmpExpr> exprList = emp.getExprList();
// 工作经历可能为空,所以我们需要判断一下
// CollectionUtils的作用是:判断集合是否为空,为空返回true,不为空返回false
if (!CollectionUtils.isEmpty(exprList)){
// 遍历集合,为每个工作经历的empId设置当前保存的员工的id
exprList.forEach(expr -> expr.setEmpId(emp.getId()));
// 批量保存
empExprMapper.insertBatch(exprList);
}
}@Transactional注解:我们一般会在业务层当中来控制事务,因为在业务层当中,一个业务功能可能会包含多个数据访问的操作。在业务层来控制事务,我们就可以将多个数据访问操作控制在一个事务范围内。
说明:可以在application.yml配置文件中开启事务管理日志,这样就可以在控制看到和事务相关的日志信息了
#spring事务管理日志
logging:
level:
org.springframework.jdbc.support.JdbcTransactionManager: debug接下来,我们再次添加员工,看看控制台输出的日志信息。

添加Spring事务管理后,由于服务端程序引发了异常,所以事务进行回滚。
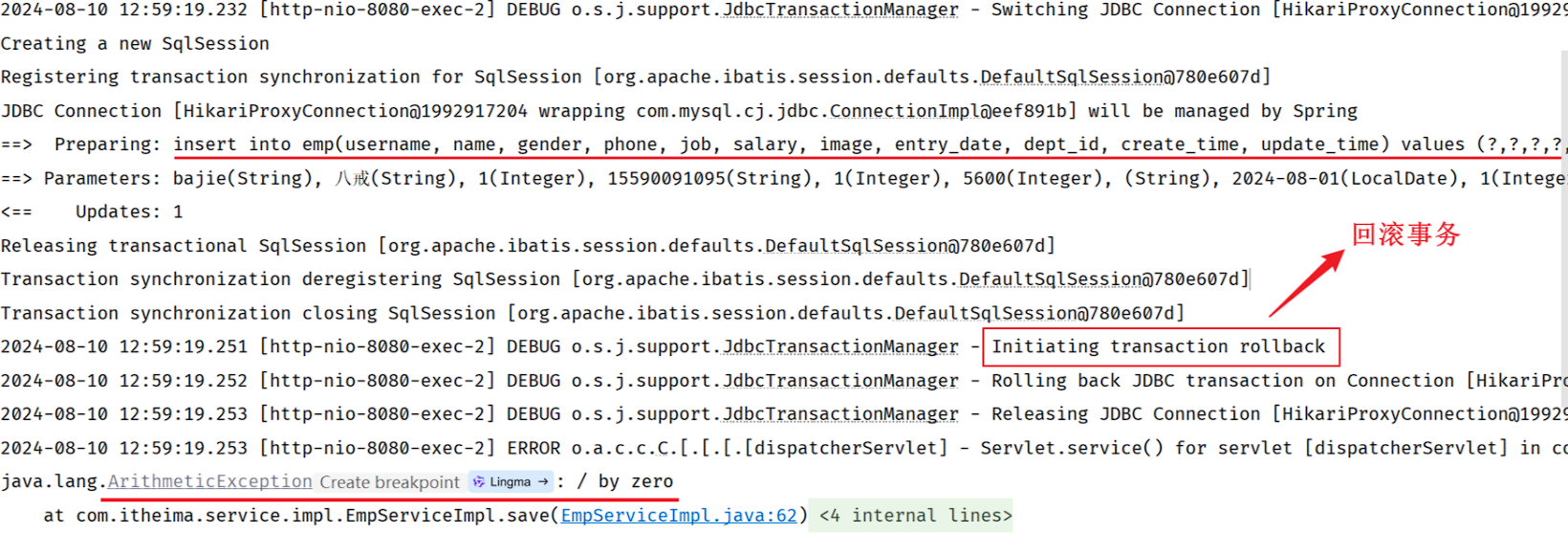
打开数据库,我们会看到 emp 表 与 emp_expr 表中都没有对应的数据信息,保证了数据的一致性、完整性。
1.4 事务进阶
1.4.1 rollbackFor
我们在之前编写的业务方法上添加了@Transactional注解,来实现事务管理。运行代码时发生异常就会执行rollback回滚操作,从而保证事务操作前后数据是一致的。
下面我们在做一个测试,我们修改业务功能代码,在模拟异常的位置上直接抛出Exception异常(编译时异常) 。
@Transactional
@Override
public void save(Emp emp) {
//1.补全基础属性
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//2.保存员工基本信息
empMapper.insert(emp);
//模拟:异常发生
if(true){
throw new Exception("出现异常了~~~");
}
//3. 保存员工的工作经历信息 - 批量
Integer empId = emp.getId();
List<EmpExpr> exprList = emp.getExprList();
if(!CollectionUtils.isEmpty(exprList)){
exprList.forEach(empExpr -> empExpr.setEmpId(empId));
empExprMapper.insertBatch(exprList);
}
}说明:在service中向上抛出一个Exception编译时异常之后,由于是controller调用service,所以在controller中要有异常处理代码,此时我们选择在controller中继续把异常向上抛。
重新启动服务后,打开Apifox进行测试,请求添加员工的接口:
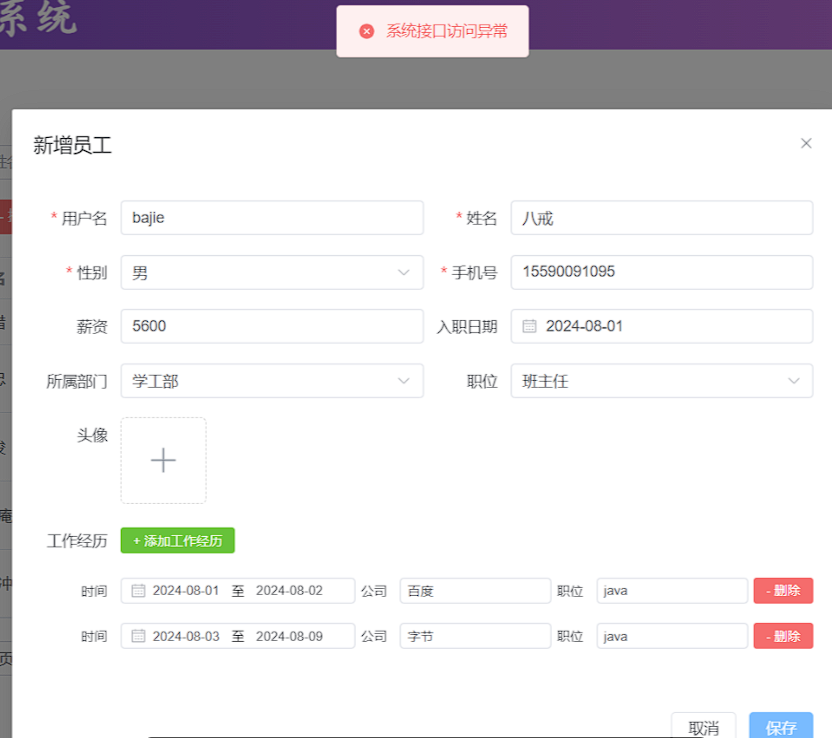
通过Apifox返回的结果,我们看到抛出异常了。然后我们在回到IDEA的控制台来看一下。
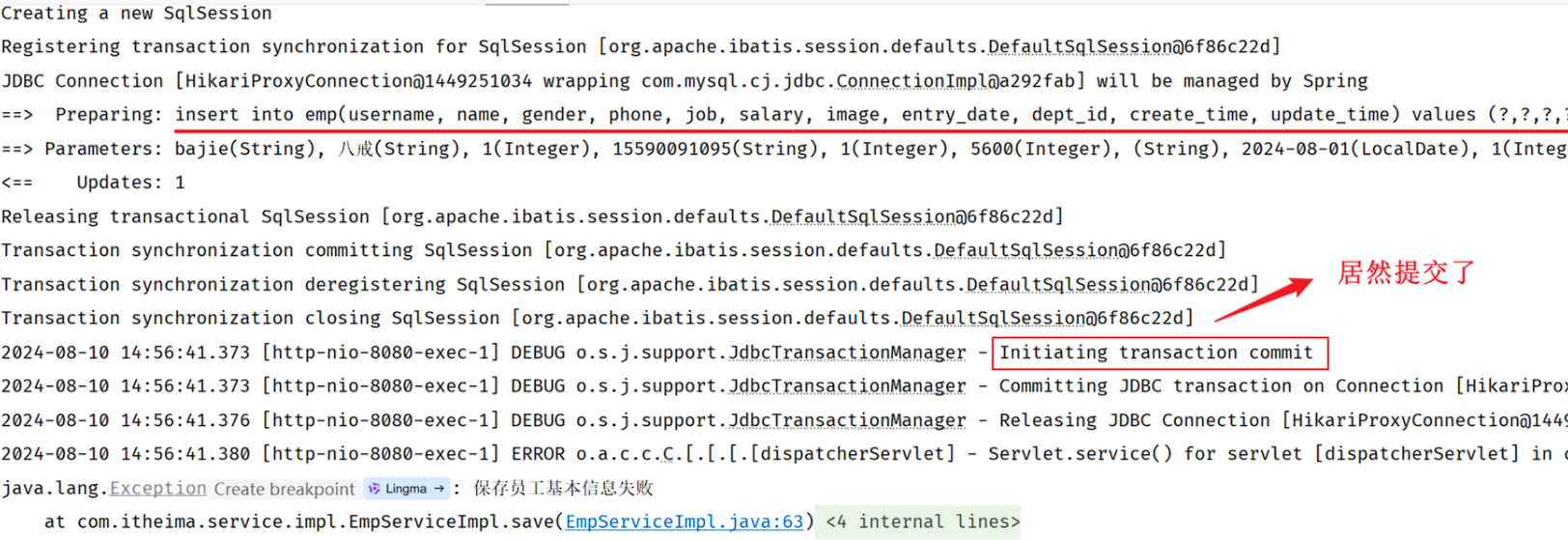
我们看到数据库的事务居然提交了,并没有进行回滚。
通过以上测试可以得出一个结论:默认情况下,只有出现RuntimeException(运行时异常)才会回滚事务。
假如我们想让所有的异常都回滚,需要来配置@Transactional注解当中的rollbackFor属性,通过rollbackFor这个属性可以指定出现何种异常类型回滚事务。
/**
* 新增员工信息
*/
@Override
@Transactional(rollbackFor = Exception.class) // 添加事务注解,出现异常就回滚
public void save(Emp emp) {
//1.补全基础属性,将创建时间和更新时间设置为当前系统更新时间
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//2.保存员工的基本信息
empMapper.insert(emp);
//3.保存员工工作经历信息
List<EmpExpr> exprList = emp.getExprList();
// 工作经历可能为空,所以我们需要判断一下
// CollectionUtils的作用是:判断集合是否为空,为空返回true,不为空返回false
if (!CollectionUtils.isEmpty(exprList)){
// 遍历集合,为每个工作经历的empId设置当前保存的员工的id
exprList.forEach(expr -> expr.setEmpId(emp.getId()));
// 批量保存
empExprMapper.insertBatch(exprList);
}
}接下来我们重新启动服务,测试新增员工的操作:
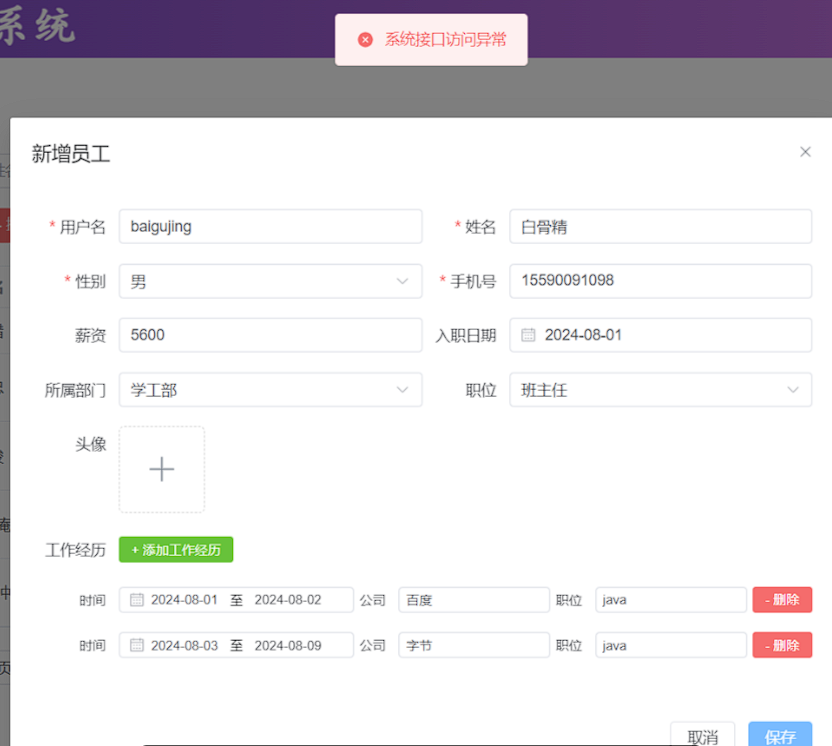
控制台日志,可以看到因为出现了异常又进行了事务回滚。
结论:
在Spring的事务管理中,默认只有运行时异常RuntimeException才会回滚。
如果还需要回滚指定类型的异常,可以通过rollbackFor属性来指定。
1.4.2 propagation
@Transactional注解当中的第二个属性propagation,这个属性是用来配置事务的传播行为的。
事务的传播行为:就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制。
例如:两个事务方法,一个A方法,一个B方法。在这两个方法上都添加了@Transactional注解,就代表这两个方法都具有事务,而在A方法当中又去调用了B方法。

所谓事务的传播行为,指的就是在A方法运行的时候,首先会开启一个事务,在A方法当中又调用了B方法, B方法自身也具有事务,那么B方法在运行的时候,到底是加入到A方法的事务当中来,还是B方法在运行的时候新建一个事务?这个就涉及到了事务的传播行为。
我们要想控制事务的传播行为,在@Transactional注解的后面指定一个属性propagation,通过 propagation 属性来指定传播行为。接下来我们就来介绍一下常见的事务传播行为。

重点关注:REQUIRED(默认值)、REQUIRES_NEW
1.4.3 用propagation改造代码
1.4.3.1 准备工作
需求:在新增员工信息时,无论是成功还是失败,都要记录操作日志。
步骤:
-
准备日志表 emp_log、实体类EmpLog、Mapper接口EmpLogMapper
-
在新增员工时记录日志
1). 创建数据库表 emp_log 日志表
-- 创建员工日志表
create table emp_log(
id int unsigned primary key auto_increment comment 'ID, 主键',
operate_time datetime comment '操作时间',
info varchar(2000) comment '日志信息'
) comment '员工日志表';2). 在pojo新建实体类:EmpLog
package com.whd.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.time.LocalDateTime;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class EmpLog {
private Integer id; //ID
private LocalDateTime operateTime; //操作时间
private String info; //详细信息
}3). 在Mapper新建接口EmpLogMapper:EmpLogMapper
package com.whd.mapper;
import com.whd.pojo.EmpLog;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface EmpLogMapper {
//插入日志
@Insert("insert into emp_log (operate_time, info) values (#{operateTime}, #{info})")
public void insert(EmpLog empLog);
}
4). 在Service 新建业务接口:EmpLogService
package com.whd.service;
import com.whd.pojo.EmpLog;
public interface EmpLogService {
//记录新增员工日志
public void insertLog(EmpLog empLog);
}
5). 在Service/Impl新建业务实现类:EmpLogServiceImpl
package com.whd.service.impl;
import com.whd.mapper.EmpLogMapper;
import com.whd.pojo.EmpLog;
import com.whd.service.EmpLogService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class EmpLogServiceImpl implements EmpLogService {
@Autowired
private EmpLogMapper empLogMapper;
@Transactional
@Override
public void insertLog(EmpLog empLog) {
empLogMapper.insert(empLog);
}
}1.4.3.2 代码实现
业务实现类:EmpServiceImpl
package com.whd.service.impl;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import com.whd.mapper.EmpExprMapper;
import com.whd.mapper.EmpMapper;
import com.whd.pojo.*;
import com.whd.service.EmpLogService;
import com.whd.service.EmpService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.CollectionUtils;
import org.springframework.web.bind.annotation.RequestParam;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.util.List;
/**
* 员工管理
*/
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpMapper empMapper;
@Autowired
private EmpExprMapper empExprMapper;
@Autowired
private EmpLogService empLogService;
/**
* 新增员工信息
*/
@Override
@Transactional(rollbackFor = Exception.class) // 添加事务注解,出现异常就回滚
public void save(Emp emp) {
try{
//1.补全基础属性,将创建时间和更新时间设置为当前系统更新时间
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
//2.保存员工的基本信息
empMapper.insert(emp);
//int i = 1 / 0; //除0错误
//3.保存员工工作经历信息
List<EmpExpr> exprList = emp.getExprList();
// 工作经历可能为空,所以我们需要判断一下
// CollectionUtils的作用是:判断集合是否为空,为空返回true,不为空返回false
if (!CollectionUtils.isEmpty(exprList)){
// 遍历集合,为每个工作经历的empId设置当前保存的员工的id
exprList.forEach(expr -> expr.setEmpId(emp.getId()));
// 批量保存
empExprMapper.insertBatch(exprList);
}
}finally {
//记录操作日志
EmpLog empLog = new EmpLog(null, LocalDateTime.now(), emp.toString());
empLogService.insertLog(empLog);
}
}
}
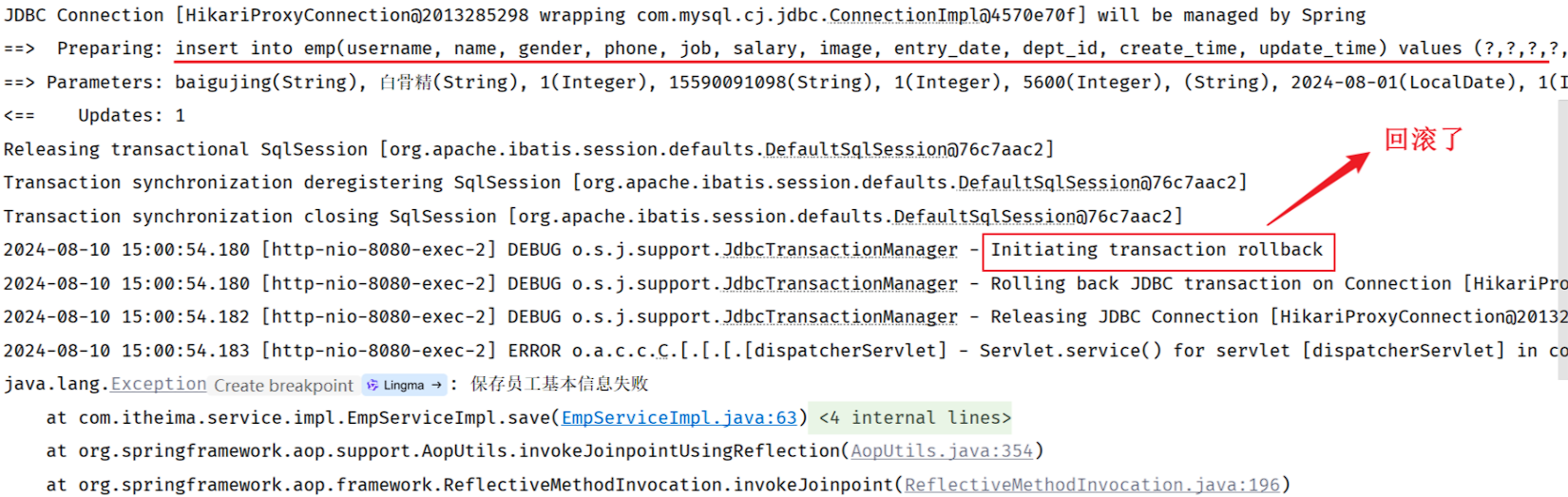
重新启动SpringBoot服务,测试新增员工操作 。我们可以看到控制台中输出的日志:
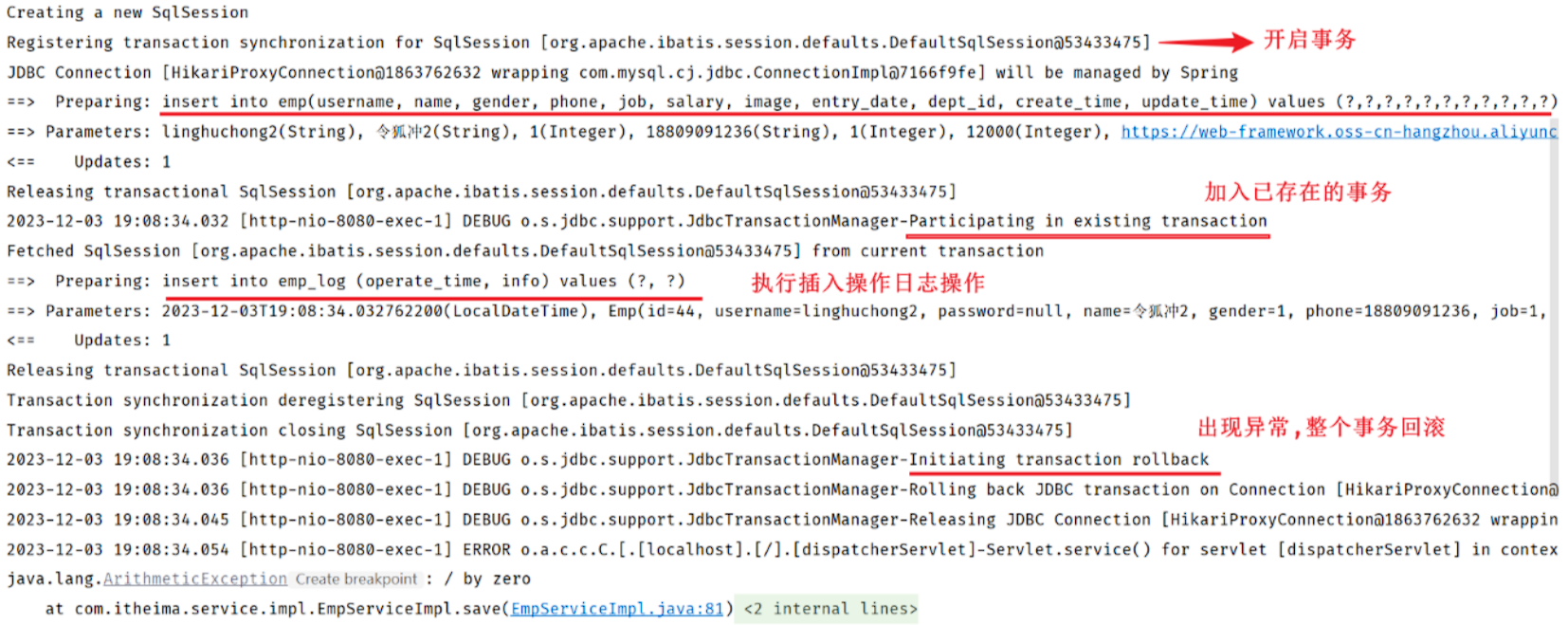
从日志中我们可以看到:
-
执行了插入员工数据的操作
-
执行了插入日志操作
-
程序发生Exception异常
-
执行事务回滚(保存员工数据、插入操作日志 因为在一个事务范围内,两个操作都会被回滚)
然后在 emp_log 表中没有记录日志数据 。
原因分析:
接下来我们就需要来分析一下具体是什么原因导致的日志没有成功的记录。
-
在执行
save方法时开启了一个事务 -
当执行
empLogService.insertLog操作时,insertLog设置的事务传播行是默认值REQUIRED,表示有事务就加入,没有则新建事务 -
此时:
save和insertLog操作使用了同一个事务,同一个事务中的多个操作,要么同时成功,要么同时失败,所以当异常发生时进行事务回滚,就会回滚save和insertLog操作
解决方案:
在EmpLogServiceImpl类中insertLog方法上,添加 @Transactional(propagation = Propagation.REQUIRES_NEW)
Propagation.REQUIRES_NEW :不论是否有事务,都创建新事务 ,运行在一个独立的事务中。
@Service
public class EmpLogServiceImpl implements EmpLogService {
@Autowired
private EmpLogMapper empLogMapper;
@Transactional(propagation = Propagation.REQUIRES_NEW)
@Override
public void insertLog(EmpLog empLog) {
empLogMapper.insert(empLog);
}
}重启SpringBoot服务,再次测试 新增员工的操作 ,会看到具体的日志如下:
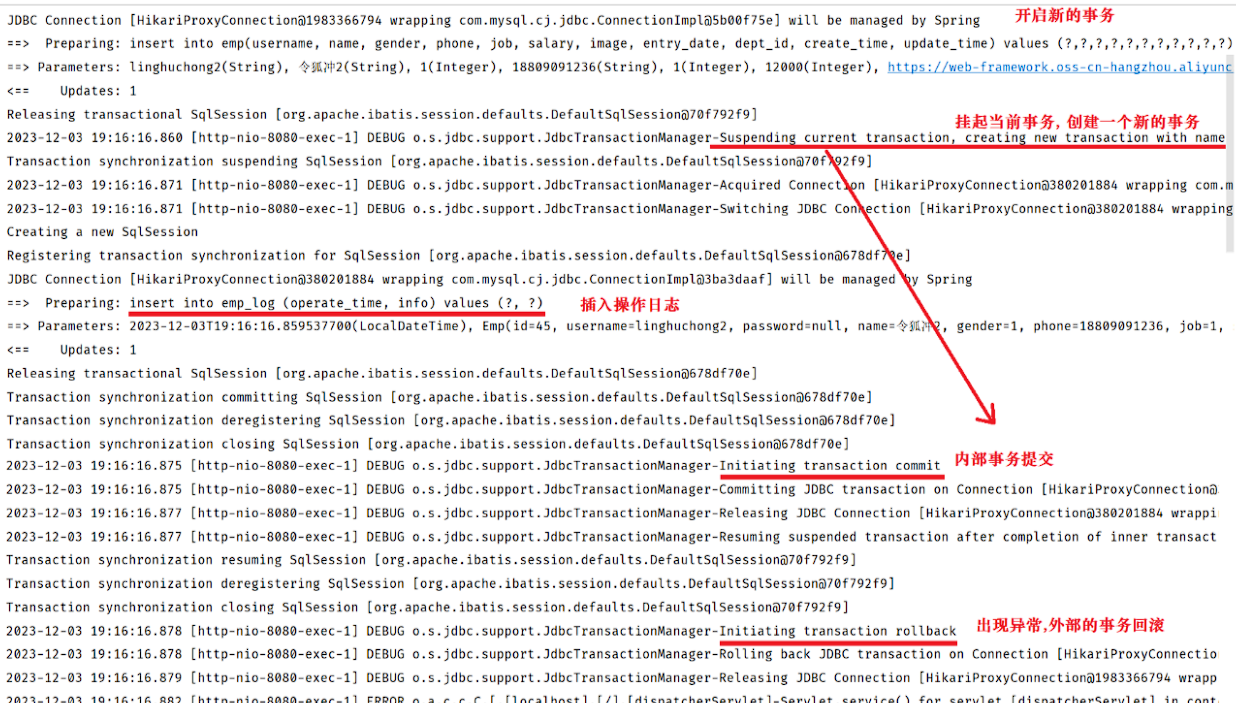
那此时,EmpServiceImpl 中的 save 方法运行时,会开启一个事务。 当调用 empLogService.insertLog(empLog) 时,也会创建一个新的事务,那此时,当 insertLog 方法运行完毕之后,事务就已经提交了。 即使外部的事务出现异常,内部已经提交的事务,也不会回滚了,因为是两个独立的事务。
REQUIRED:大部分情况下都是用该传播行为即可。
REQUIRES_NEW:当我们不希望事务之间相互影响时,可以使用该传播行为。比如:下订单前需要记录日志,不论订单保存成功与否,都需要保证日志记录能够记录成功。
1.4.4 事务四大特性
事务有哪些特性?(事务的四大特性简称为:ACID)
-
原子性(Atomicity) :原子性是指事务包装的一组sql是一个不可分割的工作单元,事务中的操作要么全部成功,要么全部失败。
-
一致性(Consistency):一个事务完成之后数据都必须处于一致性状态。
-
如果事务成功的完成,那么数据库的所有变化将生效。
-
如果事务执行出现错误,那么数据库的所有变化将会被回滚(撤销),返回到原始状态。
-
-
隔离性(Isolation):多个用户并发的访问数据库时,一个用户的事务不能被其他用户的事务干扰,多个并发的事务之间要相互隔离。
-
一个事务的成功或者失败对于其他的事务是没有影响。
-
-
持久性(Durability):一个事务一旦被提交或回滚,它对数据库的改变将是永久性的,哪怕数据库发生异常,重启之后数据亦然存在。

1.5 文件上传
1.5.1 简介
文件上传,是指将本地图片、视频、音频等文件上传到服务器,供其他用户浏览或下载的过程。文件上传在项目中应用非常广泛,我们经常发微博、发微信朋友圈都用到了文件上传功能。
在新增员工的时候,要上传员工的头像,此时就会涉及到文件上传的功能。在进行文件上传时,我们点击加号或者是点击图片,就可以选择手机或者是电脑本地的图片文件了。当我们选择了某一个图片文件之后,这个文件就会上传到服务器,从而完成文件上传的操作。
现在正在学习文件上传功能,如何基于HTML+SpringBoot完成文件上传功能?
1). 写一个测试的前端代码upload.html形式如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>上传文件</title>
</head>
<body>
<form action="/upload" method="post" enctype="multipart/form-data">
姓名: <input type="text" name="username"><br>
年龄: <input type="text" name="age"><br>
头像: <input type="file" name="file"><br>
<input type="submit" value="提交">
</form>
</body>
</html>
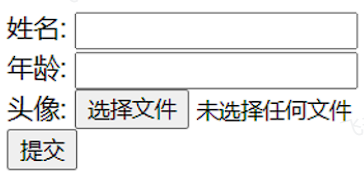
上传文件的原始form表单,要求表单必须具备以下三点(上传文件页面三要素):
-
表单必须有file域,用于选择要上传的文件
-
表单提交方式必须为POST:通常上传的文件会比较大,所以需要使用 POST 提交方式
-
表单的编码类型enctype必须要设置为multipart/form-data:普通默认的编码格式是不适合传输大型的二进制数据的,所以在文件上传时,表单的编码格式必须设置为multipart/form-data
直接将upload.html文件,复制到springboot项目工程下的static目录里面。
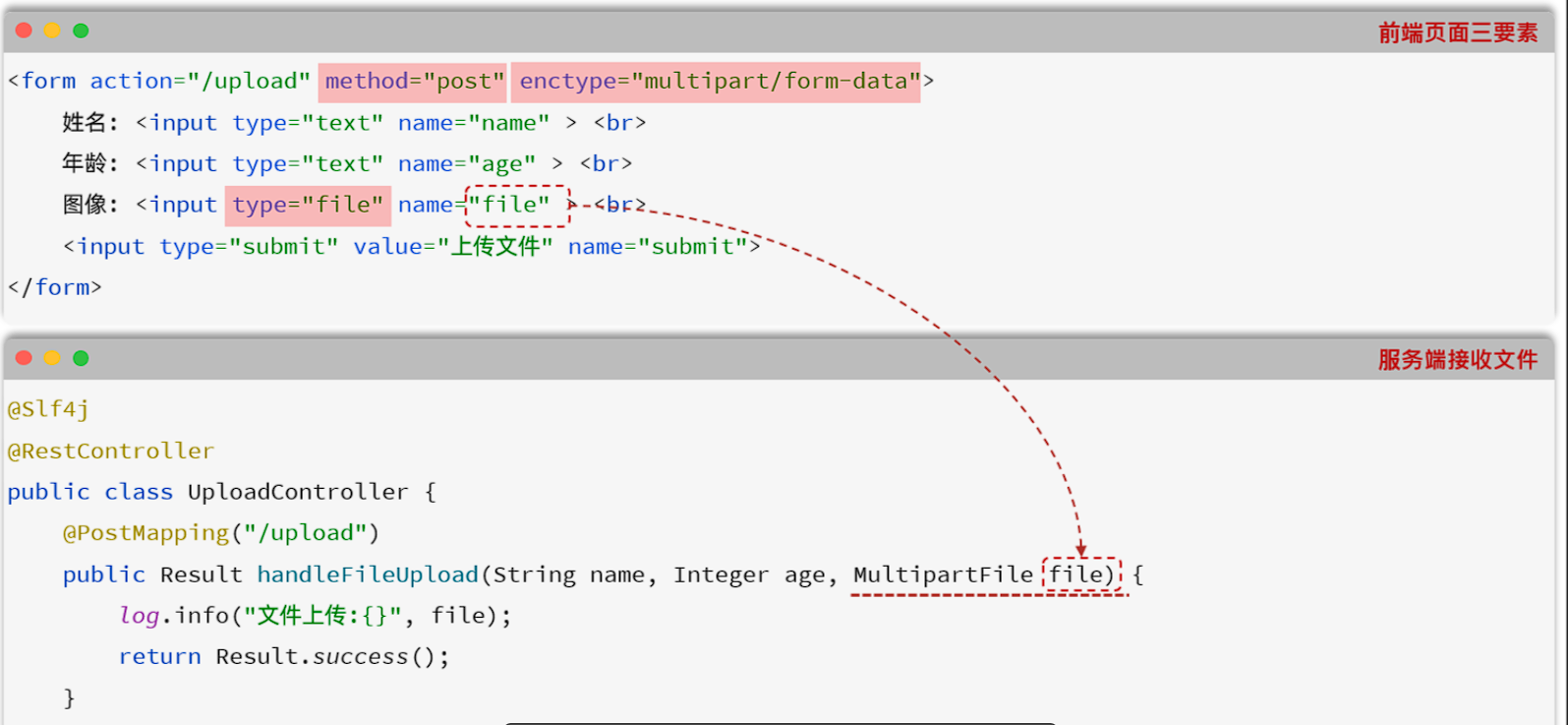
2). 服务端代码形式如下
在controller上新增UploadController.java文件

代码如下:
package com.whd.controller;
import com.whd.pojo.Result;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
@Slf4j
@RestController
public class UploadController {
/**
* 上传文件 - 参数名file
*/
@PostMapping("/upload")
public Result upload(String username, Integer age , MultipartFile file) throws Exception {
log.info("上传文件:{}, {}, {}", username, age, file);
return Result.success();
}
}在定义的方法中接收提交过来的数据 (方法中的形参名和请求参数的名字保持一致)
-
用户名:String username
-
年龄: Integer age
-
文件:MultipartFile file
Spring中提供了一个API:MultipartFile,使用这个API就可以来接收到上传的文件
问题:如果表单项的名字和方法中形参名不一致,该怎么办?
public Result upload(String username,
Integer age,
MultipartFile image) //image形参名和请求参数名file不一致解决:使用@RequestParam注解进行参数绑定
public Result upload(String username,
Integer age,
@RequestParam("file") MultipartFile image)在表单提交数据,文件上传到哪里了?
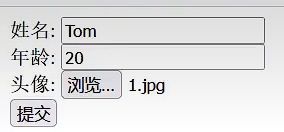
在这里打断点,看看数据在哪?
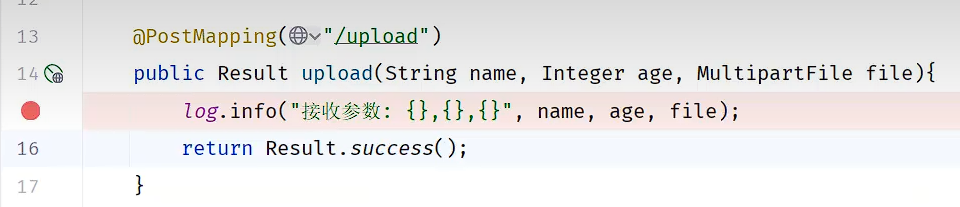
这个目录下保存着三个临时文档,保存的是我们的三个数据(姓名,年龄,二进制文件数据)

但这个临时文件会随着工程的结束而销毁,所以我们需要将文件保存在本地上。
1.5.2 本地存储
完成了文件上传最基本的功能实现,已经可以在服务端接收到上传的文件,并将文件保存在本地服务器的磁盘目录中了。要注意,如果上传的文件名相同,后面上传的会覆盖前面上传的文件。
要求:将接收到的文件存储在本地的磁盘目录中(D:/images)中, 并要保证上传的文件名不重复
在UploadController上修改upload函数,代码如下:
package com.whd.controller;
import com.whd.pojo.Result;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.util.UUID;
@Slf4j
@RestController
public class UploadController {
private static final String UPLOAD_DIR = "D:/images/";
/**
* 上传文件 - 参数名file
*/
@PostMapping("/upload")
public Result upload(String name,Integer age,MultipartFile file) throws Exception {
log.info("上传文件:{}, {}, {}", name, age, file);
if (!file.isEmpty()) {
// 获取文件名
String originalFilename = file.getOriginalFilename();
// 获取文件后缀名,根据最后一个"."开始字符串拼接
String extName = originalFilename.substring(originalFilename.lastIndexOf("."));
// 生成唯一文件名,randomUUID的作用是随机生成32位UUID字符串,replace("-", "")的作用是替换掉生成的UUID字符串中的"-",使得生成的字符串长度为32
String uniqueFileName = UUID.randomUUID().toString().replace("-", "") + extName;
// 拼接完整的文件路径
File targetFile = new File(UPLOAD_DIR + uniqueFileName);
// 如果目标目录不存在,则创建它
if (!targetFile.getParentFile().exists()) {
targetFile.getParentFile().mkdirs();
}
// 保存文件,transferTo的作用是将MultipartFile中的内容写入到目标文件
file.transferTo(targetFile);
}
return Result.success();
}
}MultipartFile 常见方法:
String getOriginalFilename();//获取原始文件名
void transferTo(File dest);//将接收的文件转存到磁盘文件中
long getSize();//获取文件的大小,单位:字节
byte[] getBytes();//获取文件内容的字节数组
InputStream getInputStream();//获取接收到的文件内容的输入流
利用 Apifox 测试,注意:请求参数名和controller方法形参名保持一致。
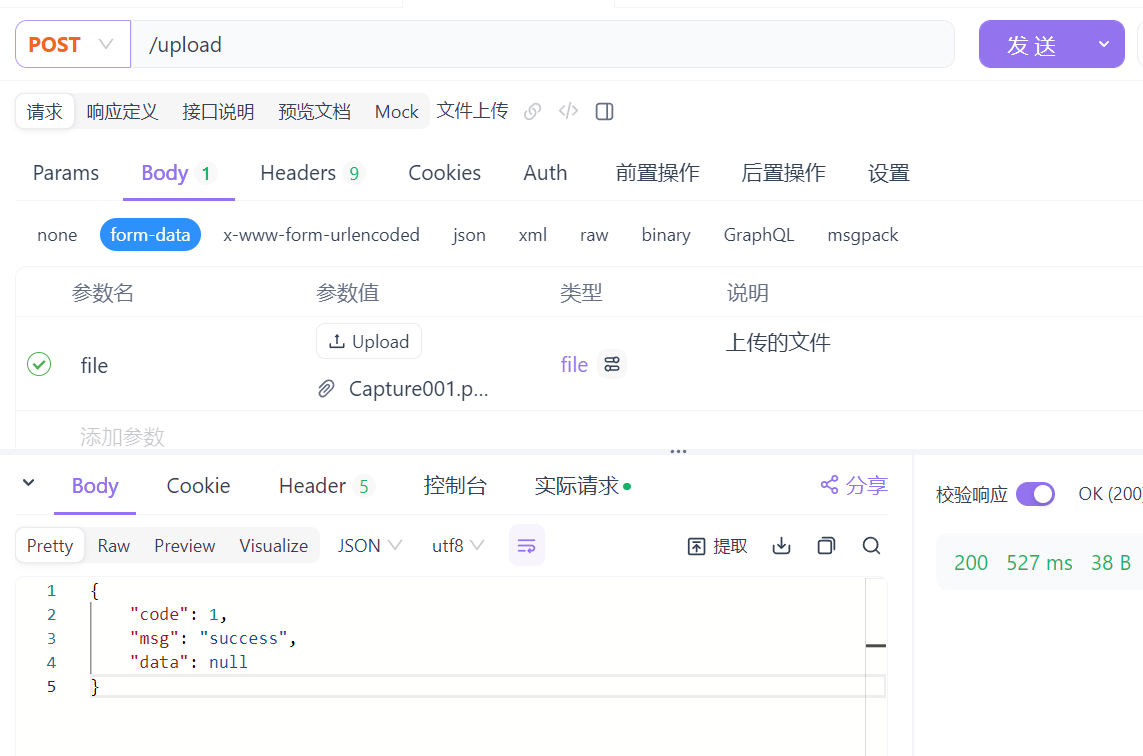 Error:文件过大,上传错误
Error:文件过大,上传错误
在解决了文件名唯一性的问题后,我们再次上传一个较大的文件(超出1M)时发现,后端程序报错:

报错原因是:在SpringBoot中,文件上传时默认单个文件最大大小为1M
如果需要上传大文件,可以在 application.properties 进行如下配置:
spring:
servlet:
multipart:
max-file-size: 10MB # 最大单个文件大小
max-request-size: 100MB # 最大请求大小(包括所有文件和表单数据)1.5.3 阿里云OSS
我们文件上传的本地存储方式已完成了。但是这种本地存储方式还存在一问题:

如果直接存储在服务器的磁盘目录中,存在以下缺点:
-
不安全:磁盘如果损坏,所有的文件就会丢失
-
容量有限:如果存储大量的图片,磁盘空间有限(磁盘不可能无限制扩容)
-
无法直接访问
为了解决上述问题呢,通常有两种解决方案:
-
自己搭建存储服务器,如:fastDFS 、MinIO
-
使用现成的云服务,如:阿里云,腾讯云,华为云
1.5.3.1 准备工作
阿里云是阿里巴巴集团旗下全球领先的云计算公司,也是国内最大的云服务提供商 。
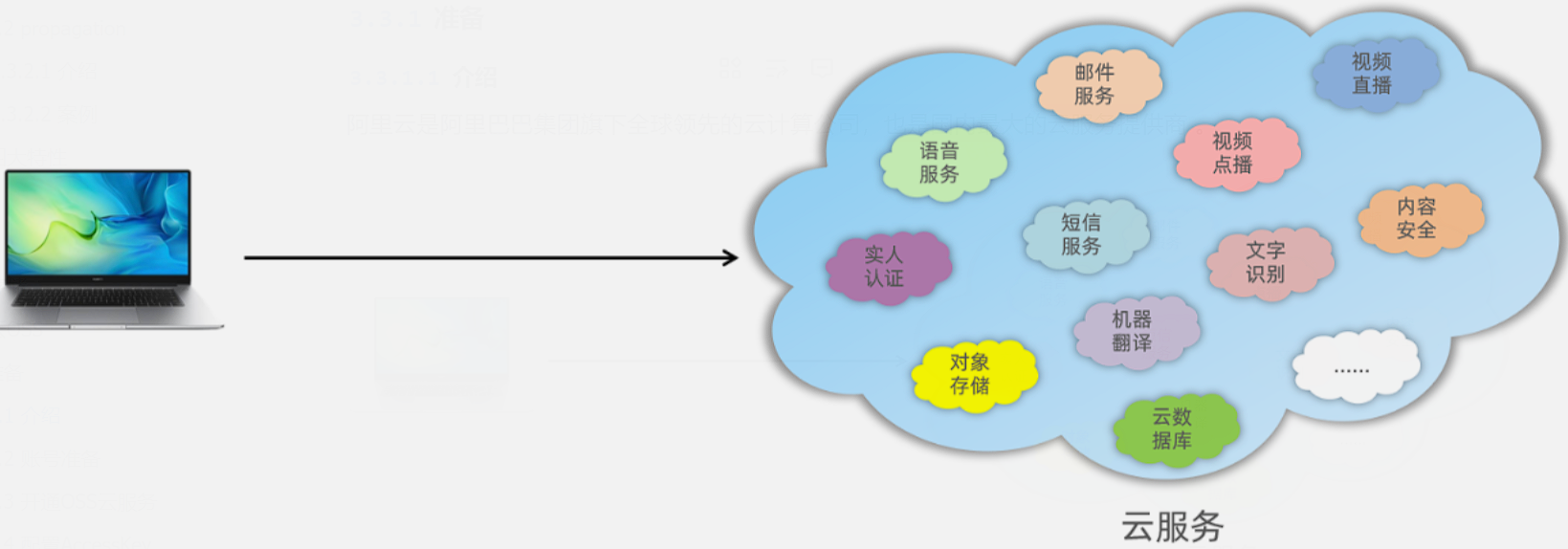
云服务指的就是通过互联网对外提供的各种各样的服务,比如像:语音服务、短信服务、邮件服务、视频直播服务、文字识别服务、对象存储服务等等。
当我们在项目开发时需要用到某个或某些服务,就不需要自己来开发了,可以直接使用阿里云提供好的这些现成服务就可以了。
比如:在项目开发当中,我们要实现一个短信发送的功能,如果我们项目组自己实现,将会非常繁琐,因为你需要和各个运营商进行对接。而此时阿里云完成了和三大运营商对接,并对外提供了一个短信服务。我们项目组只需要调用阿里云提供的短信服务,就可以很方便的来发送短信了。这样就降低了我们项目的开发难度,同时也提高了项目的开发效率。(大白话:别人帮我们实现好了功能,我们只要调用即可)
云服务提供商给我们提供的软件服务通常是需要收取一部分费用的。
阿里云对象存储OSS(Object Storage Service),是一款海量、安全、低成本、高可靠的云存储服务。使用OSS,您可以通过网络随时存储和调用包括文本、图片、音频和视频等在内的各种文件。
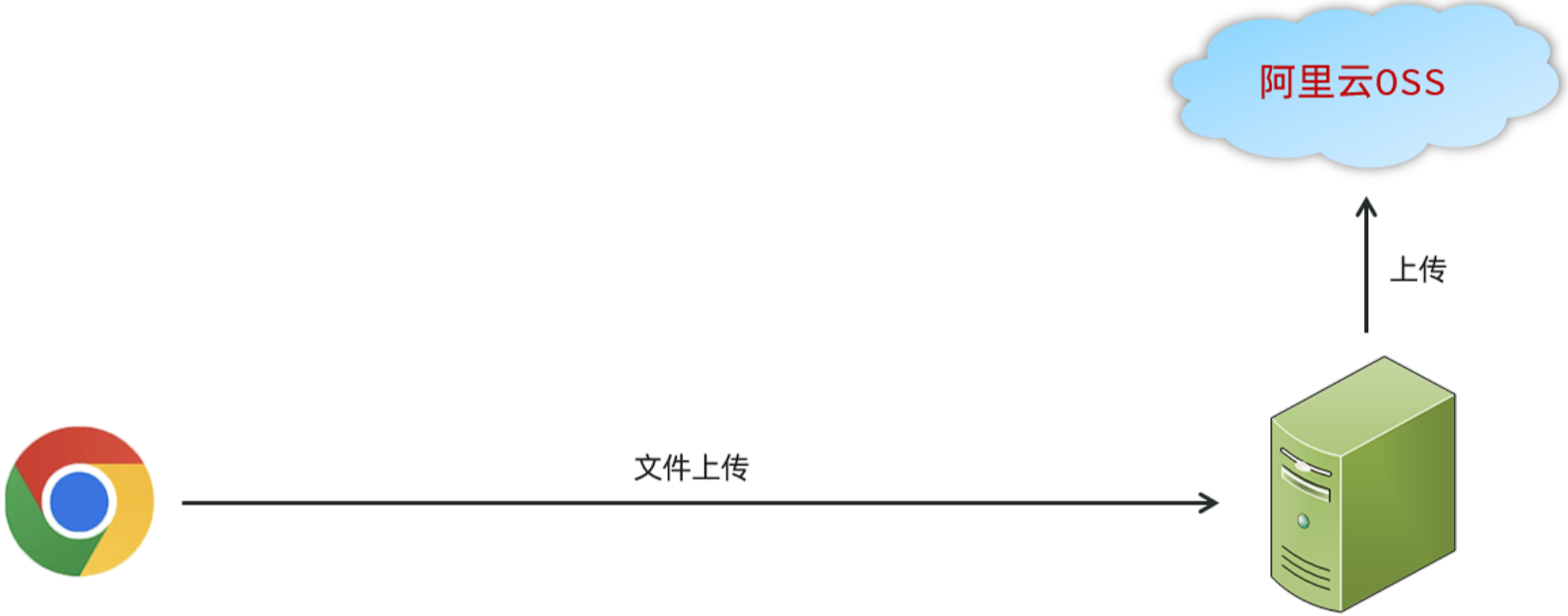
在我们使用了阿里云OSS对象存储服务之后,我们的项目当中如果涉及到文件上传这样的业务,在前端进行文件上传并请求到服务端时,在服务器本地磁盘当中就不需要再来存储文件了。我们直接将接收到的文件上传到oss,由 oss帮我们存储和管理,同时阿里云的oss存储服务还保障了我们所存储内容的安全可靠。
参照官方SDK编写入门程序,开通OSS服务,创建Bucket。
SDK:Software Development Kit 的缩写,软件开发工具包,包括辅助软件开发的依赖(jar包)、代码示例等,都可以叫做SDK。
简单说,sdk中包含了我们使用第三方云服务时所需要的依赖,以及一些示例代码。我们可以参照sdk所提供的示例代码就可以完成入门程序。
Bucket:存储空间是用户用于存储对象(Object,就是文件)的容器,所有的对象都必须隶属于某个存储空间。
1). 注册阿里云账户(注册完成后需要实名认证)
2). 注册完账号之后,登录阿里云,登录控制台
3). 通过控制台找到对象存储OSS服务,选择开通服务
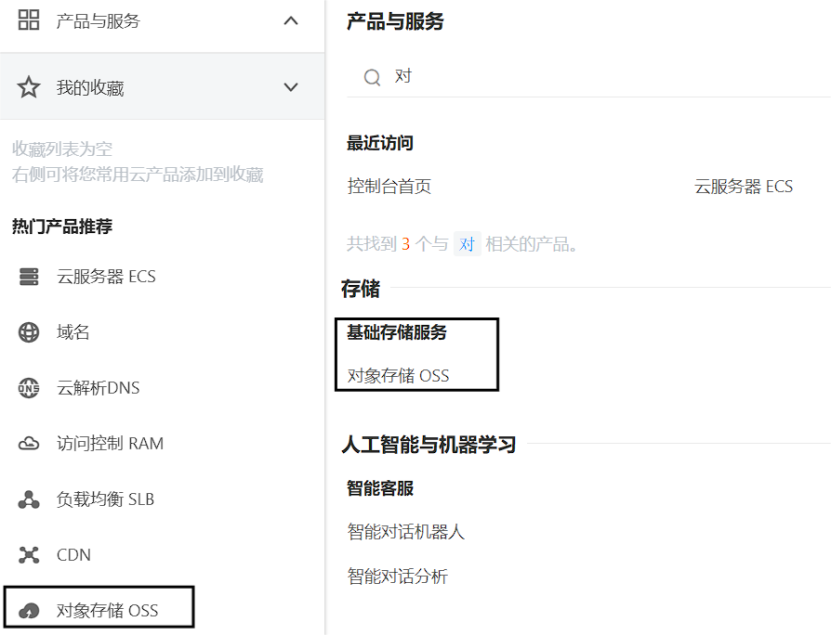
第一次访问需要开通对象存储服务OSS

开通后的控制台:
4). 点击左侧的 "Bucket列表",创建一个Bucket

输入Bucket的相关信息
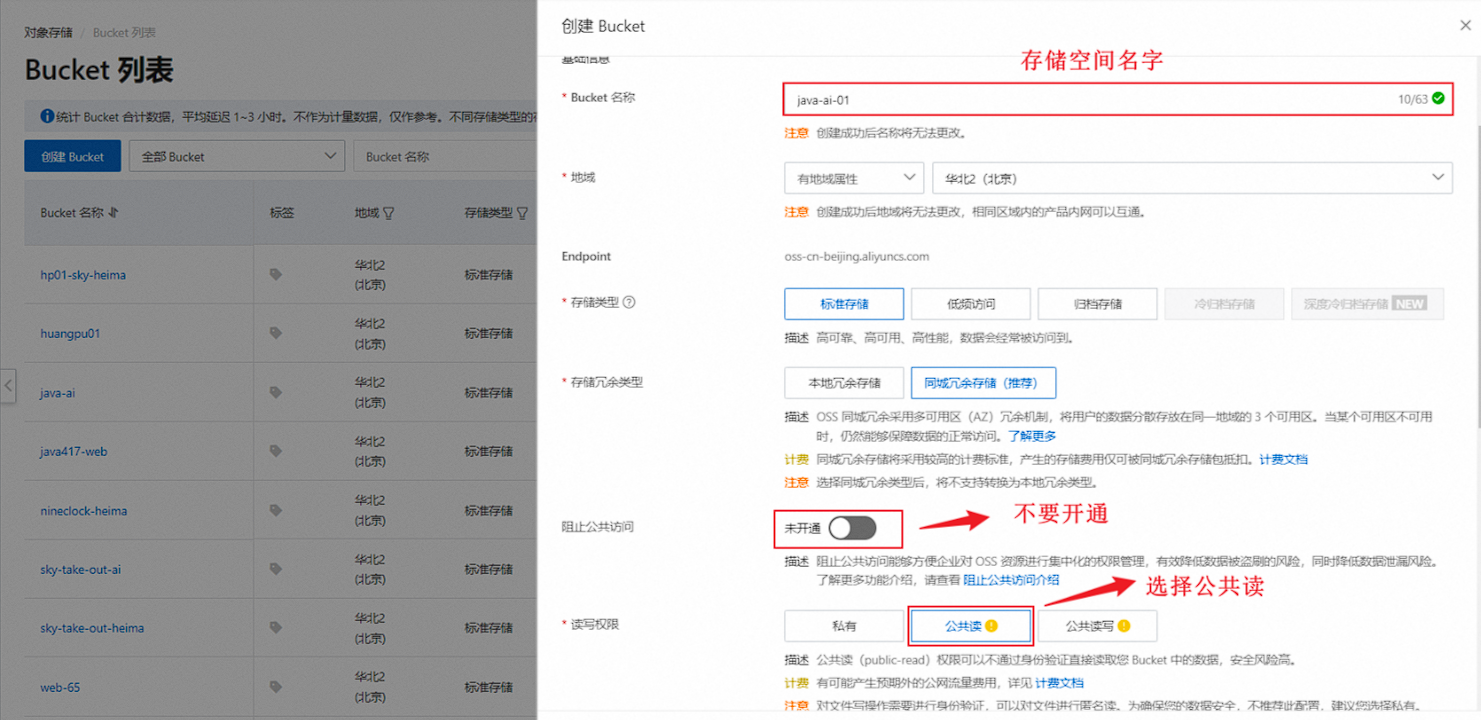
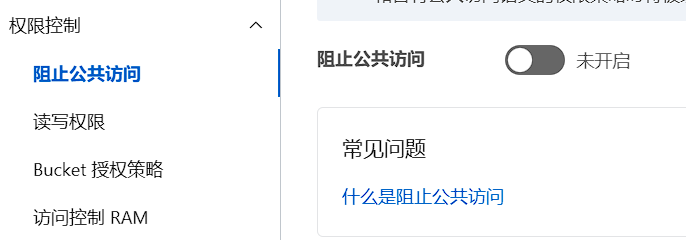
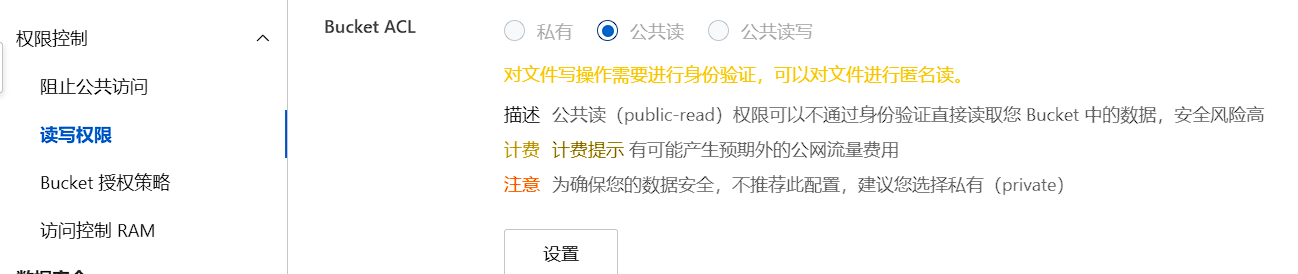
创建OSS时无法设置“阻止公共访问”的开通,读写权限也不能选择公共读,创建 OSS Bucket会默认打开阻止公共访问。若您的业务有公共访问需求,可在 Bucket 创建后,在 OSS 控制台或通过接口来关闭阻止公共访问功能。
5). 创建AccessKey
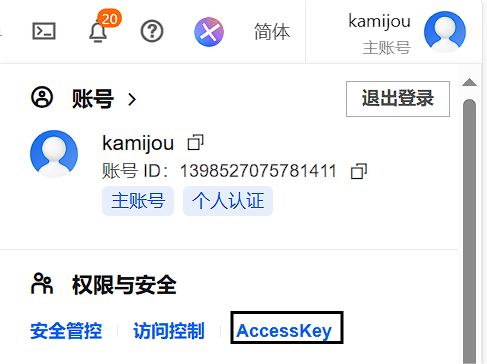
点击 "AccessKey管理",进入到管理页面。


6). 配置AccessKey
以管理员身份打开CMD命令行,执行如下命令,配置系统的环境变量。
set OSS_ACCESS_KEY_ID=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
set OSS_ACCESS_KEY_SECRET=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx注意:将上述的ACCESS_KEY_ID 与 ACCESS_KEY_SECRET 的值一定一定一定要替换成自己的 。
执行如下命令,让更改生效。
setx OSS_ACCESS_KEY_ID "%OSS_ACCESS_KEY_ID%"
setx OSS_ACCESS_KEY_SECRET "%OSS_ACCESS_KEY_SECRET%"执行如下命令,验证环境变量是否生效。
echo %OSS_ACCESS_KEY_ID%
echo %OSS_ACCESS_KEY_SECRET%
1.5.3.2 入门程序
参照官方所提供的sdk示例来编写入门程序。首先我们需要来打开阿里云OSS的官方文档,在官方文档中找到 SDK 的示例代码:

参照文档,引入依赖:

<!--阿里云OSS依赖-->
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.17.4</version>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>1.1.1</version>
</dependency>
<!-- no more than 2.3.3-->
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.3</version>
</dependency>
这是示例代码:
package com.whd;
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
import com.aliyun.oss.common.comm.SignVersion;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.nio.file.Files;
public class Demo {
public static void main(String[] args) throws Exception {
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = "https://oss-cn-beijing.aliyuncs.com";
// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Bucket名称,例如examplebucket。
String bucketName = "javaweb-whd";
// 填写Object完整路径,例如exampledir/exampleobject.txt。Object完整路径中不能包含Bucket名称。
String objectName = "001.jpg";
// 填写Bucket所在地域。以华东1(杭州)为例,Region填写为cn-hangzhou。
String region = "cn-beijing";
// 创建OSSClient实例。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
// 上传文件
try {
// 创建Bucket。
File filepath = new File("D:\\images\\1.png");
// 读取文件内容。
byte[] content = Files.readAllBytes(filepath.toPath());
// 创建PutObject请求。
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(content));
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
}
}在以上代码中,需要替换的内容为:
endpoint:阿里云OSS中的bucket对应的域名
bucketName:Bucket名称
objectName:对象名称,在Bucket中存储的对象的名称
filepath :需要上传的文件或者路径
切记,大家需要将上面的 endpoint ,bucketName,objectName,filepath 都需要改成自己的。运行以上程序后,会把本地的文件上传到阿里云OSS服务器上。
阿里云OSS中的bucket对应的域名在哪找?
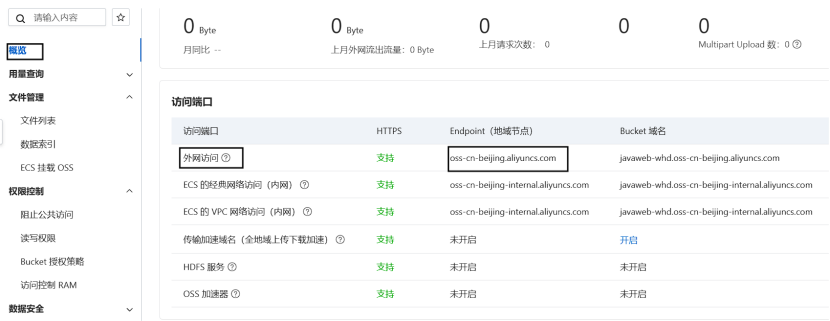
Error:在测试之前需要将IDEA重新打开
我们刚刚才在控制台中配置了AccessKey,如果不关闭IDEA,那环境变量是加载不到的,那程序读取环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET是读取不到的,就会报错!!!
Error:内网Endpoint使用错误
现象:代码中配置了内网Endpoint (oss-cn-beijing-internal.aliyuncs.com),但当前环境不在阿里云VPC内网
-
验证方法:
ping javaweb-whd.oss-cn-beijing-internal.aliyuncs.com # 若无法解析或超时,说明不在内网环境 -
修复方案:
// 修改为公网Endpoint(移除-internal) String endpoint = "https://oss-cn-beijing.aliyuncs.com";
1.5.3.3 集成
阿里云oss对象存储服务的准备工作以及入门程序我们都已经完成了,接下来我们就需要在UploadController当中集成oss对象存储服务,来存储和管理案例中上传的图片。
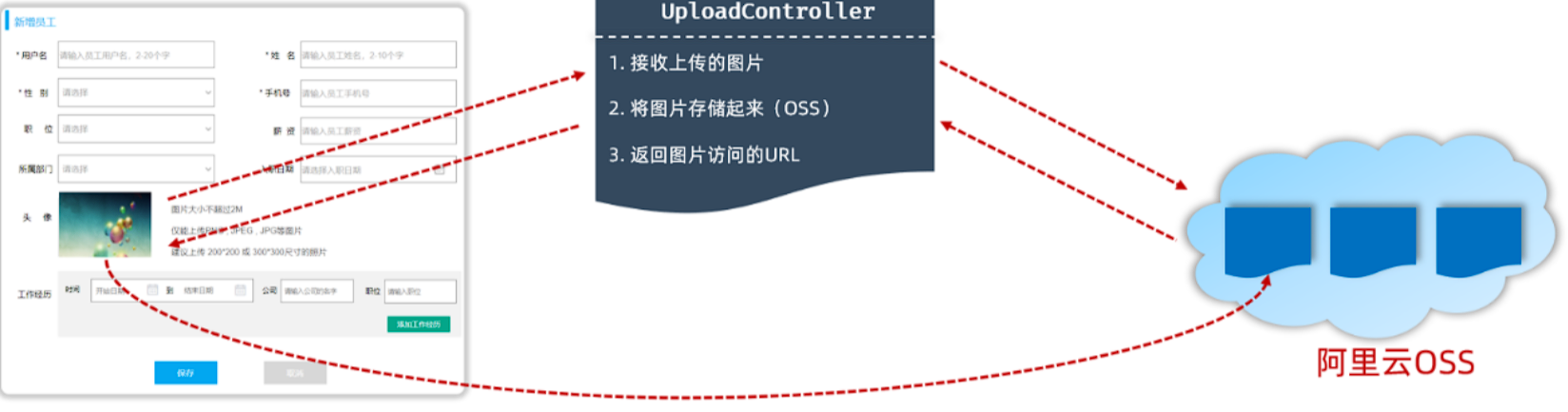
在新增员工的时候,上传员工的图像,而之所以需要上传员工的图像,是因为将来我们需要在系统页面当中访问并展示员工的图像。而要想完成这个操作,需要做两件事:
需要上传员工的图像,并把图像保存起来(存储到阿里云OSS)
访问员工图像(通过图像在阿里云OSS的存储地址访问图像)
OSS中的每一个文件都会分配一个访问的url,通过这个url就可以访问到存储在阿里云上的图片。所以需要把url返回给前端,这样前端就可以通过url获取到图像。
- 请求路径:/upload
- 请求方式:POST
- 接口描述:该接口用于上传图片
- 请求参数:multipart/form-data
- 响应数据样例:
{ "code": 1, "msg": "success", "data": "https://web-framework.oss-cn-hangzhou.aliyuncs.com/2022-09-02-00-27-0400.jpg" }
1). 引入阿里云OSS上传文件工具类
新建包utils,在包内新建OSSOperator.java文件,里面编写上传到阿里云OSS的代码(由官方的示例代码改造而来)
OSSOperator的代码如下:
package com.whd.utils;
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
import com.aliyun.oss.common.comm.SignVersion;
import org.springframework.stereotype.Component;
import java.io.ByteArrayInputStream;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.UUID;
@Component // 将当前类标记为组件
public class OSSOperator {
private String endpoint = "https://oss-cn-beijing.aliyuncs.com";
private String bucketName = "javaweb-whd";
private String region = "cn-beijing";
/**
* 上传文件到阿里云
* @param content 文件对应的字节数组
* @param originalFilename 文件的原始名称,包含文件后缀
* @return
* @throws Exception
*/
public String upload(byte[] content, String originalFilename) throws Exception {
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Object完整路径,例如202406/1.png。Object完整路径中不能包含Bucket名称。
//获取当前系统日期的字符串,格式为 yyyy/MM
String dir = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy/MM"));
//生成一个新的不重复的文件名
String newFileName = UUID.randomUUID() + originalFilename.substring(originalFilename.lastIndexOf("."));
String objectName = dir + "/" + newFileName;
// 创建OSSClient实例。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(content));
} finally {
ossClient.shutdown();
}
// 返回文件的访问路径
return endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + objectName;
}
}
2). 修改UploadController代码
@Autowired
private OSSOperator ossOperator;
/**
* 往阿里云OSS上传文件
* @param file 上传的文件
*/
@PostMapping("/upload")
public Result upload(MultipartFile file) throws Exception {
log.info("上传文件:{}", file.getOriginalFilename()); // 获取文件名
//getBytes()方法将MultipartFile中的内容转换为字节数组, getOriginalFilename()方法获取文件名
String url = ossOperator.upload(file.getBytes(), file.getOriginalFilename());
log.info("上传文件路径:{}", url);
return Result.success(url);
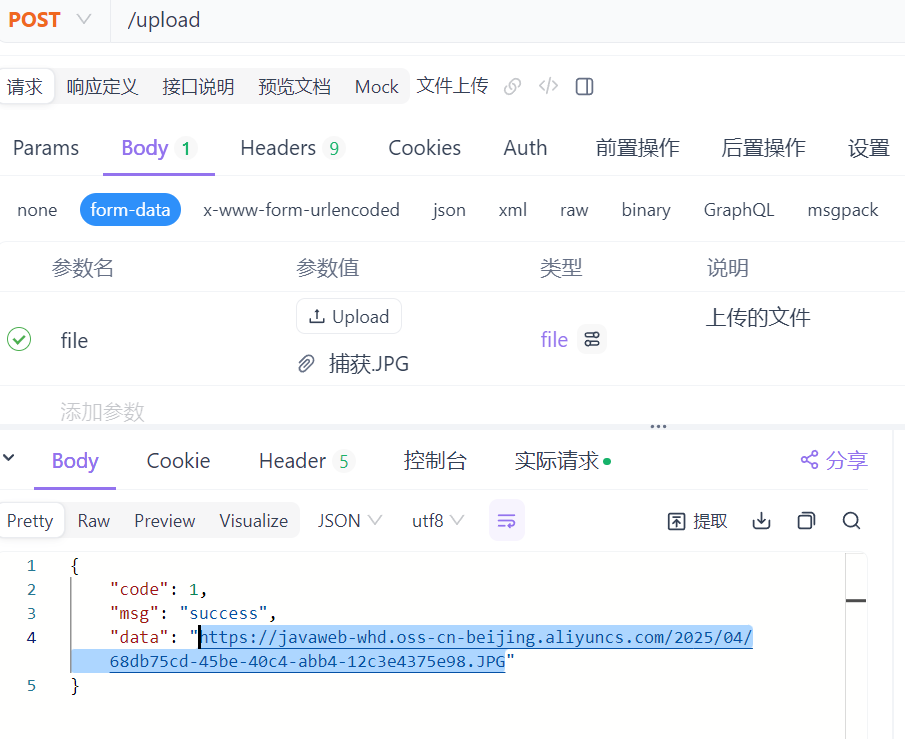
}测试结果返回的有图片的url
1.5.3.4 功能优化
员工管理的新增功能我们已开发完成,但在我们所开发的程序中还一些小问题,下面我们就来分析一下当前案例中存在的问题以及如何优化解决。
在刚才我们制作的AliyunOSS操作的工具类中,我们直接将 endpoint、bucketName参数直接在java文件中写死了,这样不易维护和管理。如下所示:
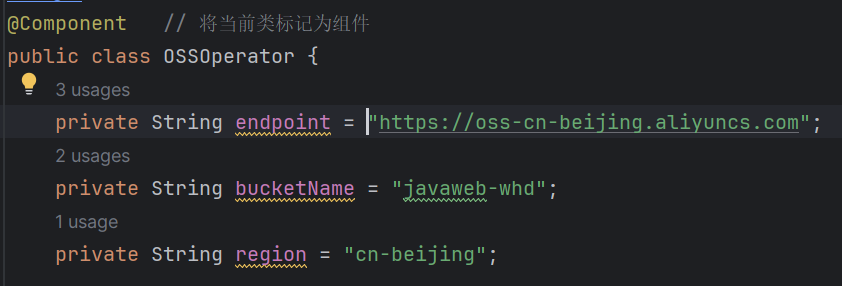
如果后续,项目要部署到测试环境、上生产环境,我们需要来修改这两个参数。 而如果开发一个大型项目,所有用到的技术涉及到的这些个参数全部写死在java代码中,是非常不便于维护和管理的。
那么我们的配置文件又有用啦!!!对于这些容易变动的参数,我们将其配置在配置文件中,然后通过 @Value 注解来注解外部配置的属性。如下所示:
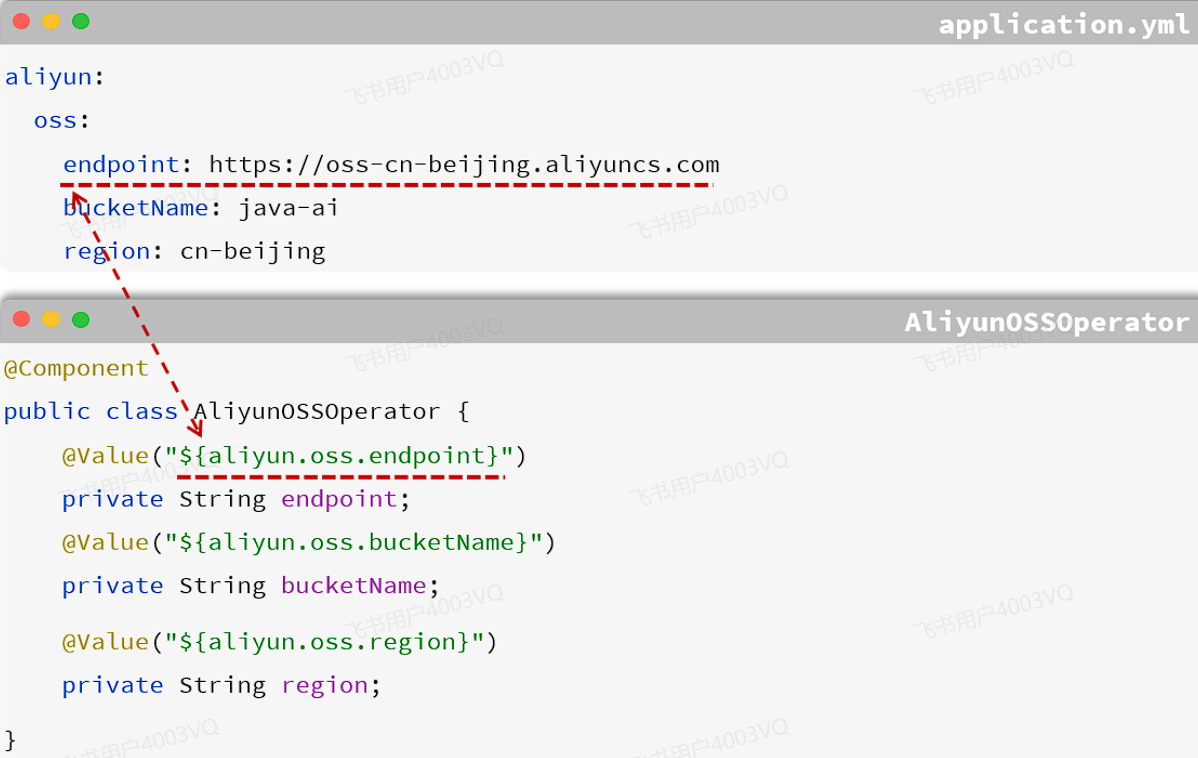
具体实现代码如下:
1). application.yml(这里要改成自己的 )
#阿里云OSS
aliyun:
oss:
endpoint: https://oss-cn-beijing.aliyuncs.com
bucketName: javaweb-whd
region: cn-beijing2). AliyunOSSOperator
方式一: 通过@Value注解一个属性一个属性的注入
@Component // 将当前类标记为组件
public class OSSOperator {
//方式一: 通过@Value注解一个属性一个属性的注入
@Value("${aliyun.oss.endpoint}")
private String endpoint;
@Value("${aliyun.oss.bucketName}")
private String bucketName;
@Value("${aliyun.oss.region}")
private String region; 如果只有一两个属性需要注入,而且不需要考虑复用性,使用@Value注解就可以了。但是使用@Value注解注入配置文件的配置项,如果配置项多,注入繁琐,不便于维护管理和复用。
但是!!!又是Spring,在Spring中给我们提供了一种简化方式,可以直接将配置文件中配置项的值自动的注入到对象的属性中。
Spring提供的简化方式套路:
- 需要创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须要一致,比如配置文件当中叫endpoint,实体类当中的属性也得叫endpoint,另外实体类当中的属性还需要提供 getter / setter方法
- 需要将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象
- 在实体类上添加
@ConfigurationProperties注解,并通过prefix属性来指定配置参数项的前缀
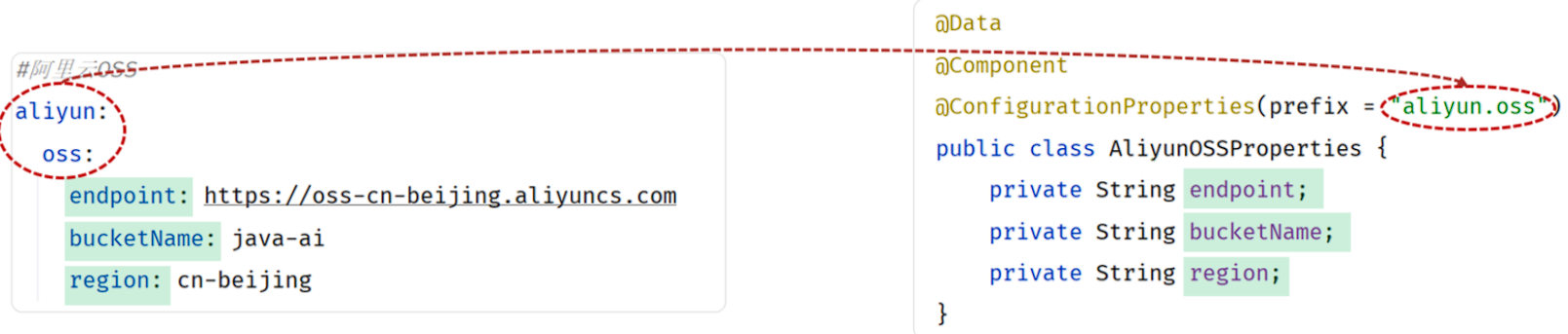
具体实现步骤:
1). 在utils定义实体类OSSProperties ,并交给IOC容器管理
package com.whd.utils;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Data
@Component // 交给IOC容器管理
@ConfigurationProperties(prefix = "aliyun.oss") // 读取配置文件中的配置项
public class OOSProperties {
// 成员变量名要与配置文件中的配置项名相同
private String endpoint;
private String bucketName;
private String region;
}2). 修改OSSOperator
// 下面三行代码需要写在upload方法里面
String endpoint = oosProperties.getEndpoint();
String bucketName = oosProperties.getBucketName();
String region = oosProperties.getRegion();
package com.whd.utils;
import com.aliyun.oss.*;
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
import com.aliyun.oss.common.comm.SignVersion;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.io.ByteArrayInputStream;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.UUID;
@Component // 将当前类标记为组件
public class OSSOperator {
//方式二: 通过封装变量的方式注入
@Autowired
private OOSProperties oosProperties;
/**
* 上传文件到阿里云
* @param content 文件对应的字节数组
* @param originalFilename 文件的原始名称,包含文件后缀
* @return
* @throws Exception
*/
public String upload(byte[] content, String originalFilename) throws Exception {
// 方式二: 通过封装变量的方式注入
String endpoint = oosProperties.getEndpoint();
String bucketName = oosProperties.getBucketName();
String region = oosProperties.getRegion();
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 填写Object完整路径,例如202406/1.png。Object完整路径中不能包含Bucket名称。
//获取当前系统日期的字符串,格式为 yyyy/MM
String dir = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy/MM"));
//生成一个新的不重复的文件名
String newFileName = UUID.randomUUID() + originalFilename.substring(originalFilename.lastIndexOf("."));
String objectName = dir + "/" + newFileName;
// 创建OSSClient实例。
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(content));
} finally {
ossClient.shutdown();
}
// 返回文件的访问路径
return endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + objectName;
}
}
二、删除员工
2.1 实现思路

当我们勾选列表前面的复选框,然后点击 "批量删除" 按钮,就可以将这一批次的员工信息删除掉了。也可以只勾选一个复选框,仅删除一个员工信息。
问题:我们需要开发两个功能接口吗?一个删除单个员工,一个删除多个员工
答案:不需要。 只需要开发一个功能接口即可(删除多个员工包含只删除一个员工)
请求路径:
/emps请求方式:
DELETE接口描述:该接口用于批量删除员工的数据信息
请求参数:员工的id数组
请求参数样例:
/emps?ids=1,2,3响应数据样例:
{ "code":1, "msg":"success", "data":null }
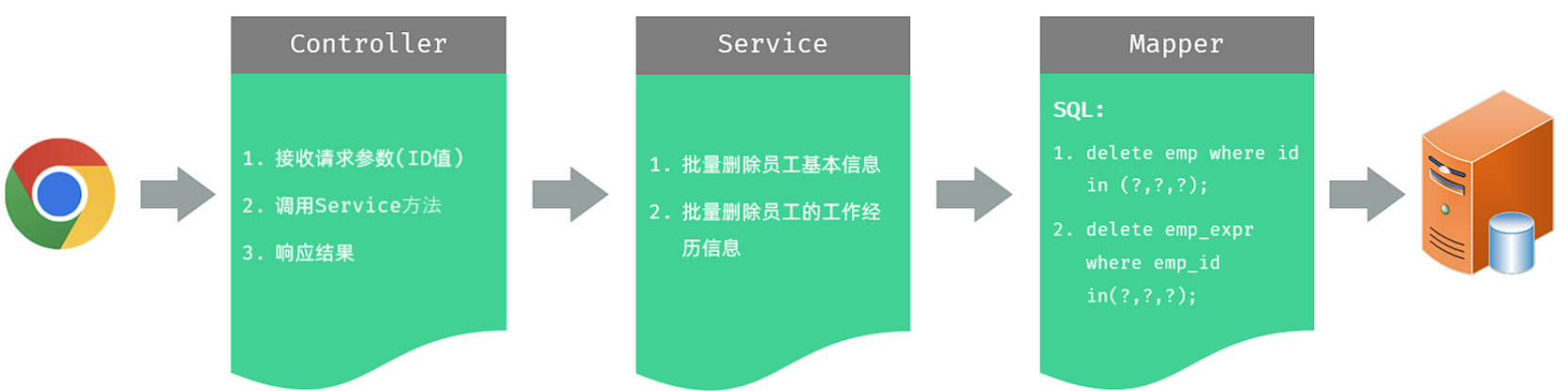
实现该功能时,三层架构每一层的职责:
-
Controller层:负责接收前端发起的请求值id数组,并调用Service删除员工数据,然后响应数据。
-
Service层:负责调用Mapper接口方法,批量删除员工的基本信息和工作经历信息。
-
Mapper层:执行SQL语句执行删除两张数据表数据的操作。
2.2 代码实现
2.2.1 Controller层
在EmpController中增加如下方法delete,来执行批量删除员工的操作。
方式一:在Controller方法中通过数组来接收
多个参数,默认可以将其封装到一个数组中,需要保证前端传递的参数名与方法形参名称保持一致
/**
* 批量删除员工
*/
@DeleteMapping
public Result delete(Integer[] ids){
log.info("批量删除部门: ids={} ", Arrays.asList(ids));
return Result.success();
}方式二:在Controller方法中通过集合来接收
也可以将其封装到一个List<Integer> 集合中,如果要将其封装到一个集合中,需要在集合前面加上 @RequestParam 注解。
/**
* 删除一个火多个员工
*/
@DeleteMapping
public Result delete(@RequestParam List<Integer> ids) {
log.info("删除员工:{}", ids);
empService.delete(ids);
return Result.success();
}两种方式,选择其中一种就可以,我们一般推荐选择集合,因为基于集合操作其中的元素会更加方便。
2.2.2 Service层
1). 在接口中EmpService中定义接口方法delete
/**
* 批量删除员工信息
*/
void delete(List<Integer> ids);2). 在实现类EmpServiceImpl中实现接口方法delete
在删除员工信息时,既需要删除 emp 表中的员工基本信息,还需要删除 emp_expr 表中员工的工作经历信息,操作多次数据库的删除,所以需要进行事务控制。
/**
* 删除员工基本信息和工作经历
*/
@Override
@Transactional(rollbackFor = Exception.class) // 添加事务注解,出现异常就回滚
public void delete(List<Integer> ids) {
// 1.删除员工的基本信息
empMapper.deleteByIds(ids);
// 2.删除员工的工作经历信息,根据员工id删除
empExprMapper.deleteByEmpIds(ids);
}2.2.3 Mapper层
1). 在EmpMapper接口中增加deleteByIds方法实现批量删除员工基本信息
/**
* 根据id批量删除员工基本信息
*/
void deleteByIds(List<Integer> ids);2). 在EmpMapper.xml配置文件中, 配置对应的SQL语句
<delete id="deleteByIds">
delete from emp where id in
<foreach collection="ids" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</delete>3). 在EmpMapper接口中增加deleteByEmpIds方法实现根据员工ID批量删除员工的工作经历
/**
* 根据id批量删除员工的工作经历信息
*/
void deleteByEmpIds(List<Integer> empIds);4). 在EmpMapper.xml配置文件中, 配置对应的SQL语句
<delete id="deleteByEmpIds">
delete from emp_expr where emp_id in
<foreach collection="empIds" item="empId" open="(" close=")" separator=",">
#{empId}
</foreach>
</delete>三、修改员工
3.1 查询回显
3.1.1 实现思路
在查询回显时,既需要查询出员工的基本信息,又需要查询出该员工的工作经历信息。

我们可以先通过一条SQL语句,查询出指定员工的基本信息,及其员工的工作经历信息。SQL如下:
select e.*,
ee.id ee_id,
ee.begin ee_begin,
ee.end ee_end,
ee.company ee_company,
ee.job ee_job
from emp e left join emp_expr ee on e.id = ee.emp_id where e.id = 39;请求路径:
/emps/{id}请求方式:
GET接口描述:该接口用于根据主键ID查询员工的信息
请求参数:路径参数id
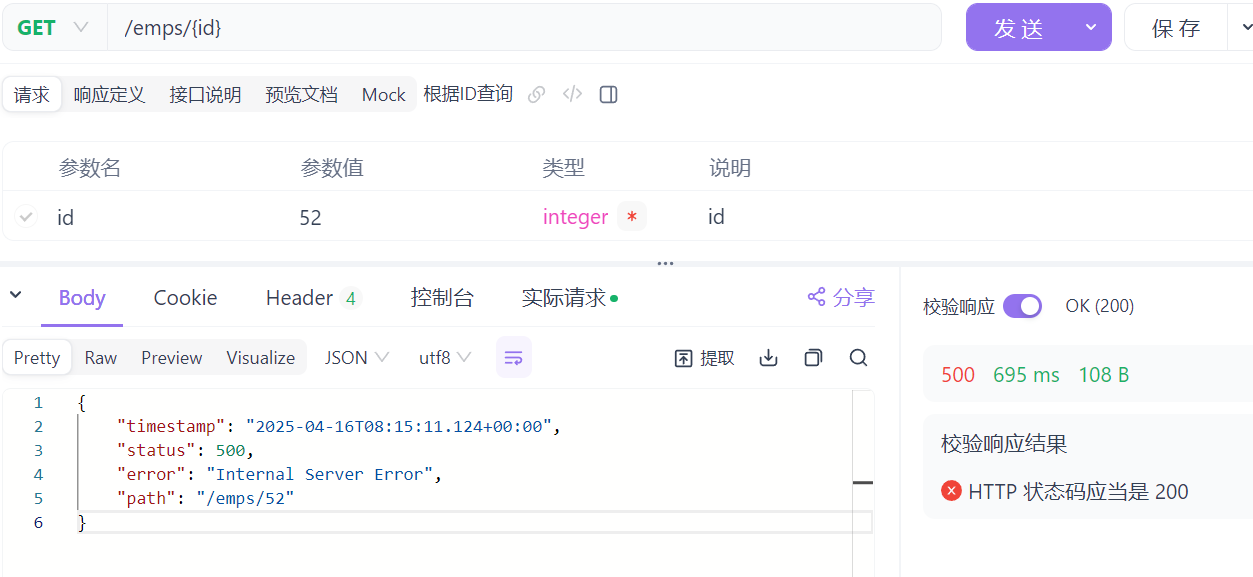
请求参数样例:
/emps/1响应数据样例:
{ "code": 1, "msg": "success", "data": { "id": 2, "username": "zhangwuji", "name": "张无忌", "gender": 1, "image": "https://web-framework.oss-cn-hangzhou.aliyuncs.com/2022-09-02-00-27-53B.jpg", "job": 2, "salary": 8000, "entryDate": "2015-01-01", "deptId": 2, "createTime": "2022-09-01T23:06:30", "updateTime": "2022-09-02T00:29:04", "exprList": [ { "id": 1, "begin": "2012-07-01", "end": "2019-03-03" "company": "百度科技股份有限公司" "job": "java开发", "empId": 2 }, { "id": 2, "begin": "2019-3-15", "end": "2023-03-01" "company": "阿里巴巴科技股份有限公司" "job": "架构师", "empId": 2 } ] } }
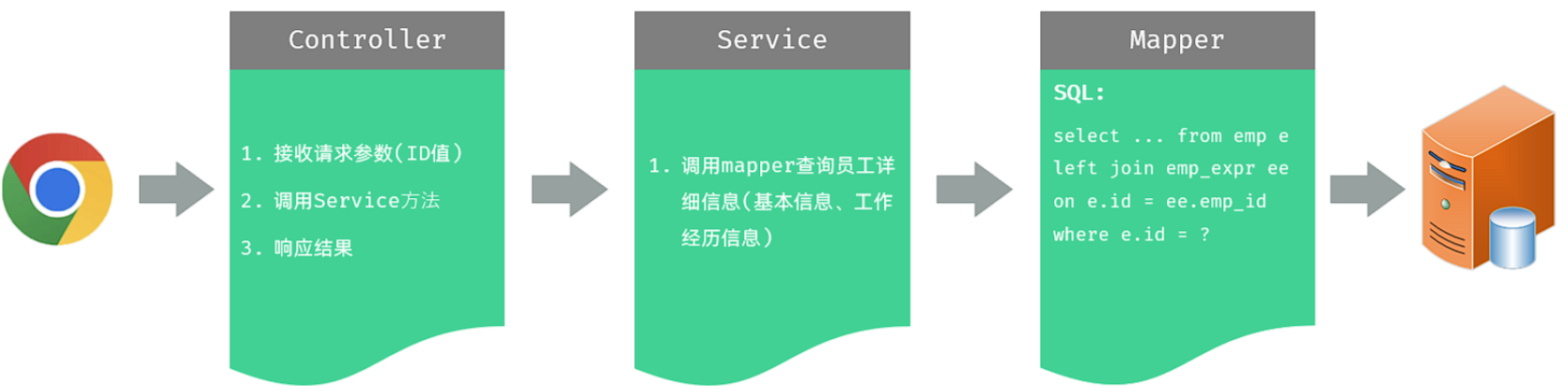
实现该功能时,三层架构每一层的职责:
-
Controller层:负责接收前端发起的路径参数id,并调用Service查询该员工数据,然后响应数据。
-
Service层:负责调用Mapper接口方法,查询员工的基本信息和工作经历信息。
-
Mapper层:执行SQL语句执行查询两张数据表数据的操作。
3.1.2 代码实现
3.1.2.1 Controller层
在EmpController 添加 getInfo 用来根据ID查询员工数据,用于页面回显
/**
* 查询回显
*/
@GetMapping("/{id}")
public Result getInfo(@PathVariable Integer id){
log.info("根据id查询员工的详细信息");
Emp emp = empService.getInfo(id);
return Result.success(emp);
}3.1.2.2 Service层
1). EmpService接口中增加getInfo方法
/**
* 根据ID查询员工的详细信息
*/
Emp getInfo(Integer id);2). EmpServiceImpl实现类中实现getInfo方法
@Override
public Emp getInfo(Integer id) {
return empMapper.getById(id);
}3.1.2.3 Mapper层
1). EmpMapper接口中增加getById方法
/**
* 根据ID查询员工详细信息
*/
Emp getById(Integer id);2). EmpMapper.xml配置文件中定义对应的SQL
<!--根据ID查询员工的详细信息-->
<select id="getById" resultType="com.whd.pojo.Emp">
select e.*,
ee.id ee_id,
ee.emp_id ee_empid,
ee.begin ee_begin,
ee.end ee_end,
ee.company ee_company,
ee.job ee_job
from emp e left join emp_expr ee on e.id = ee.emp_id
where e.id = #{id}
</select>测试完之后发现工作经历exprList为空
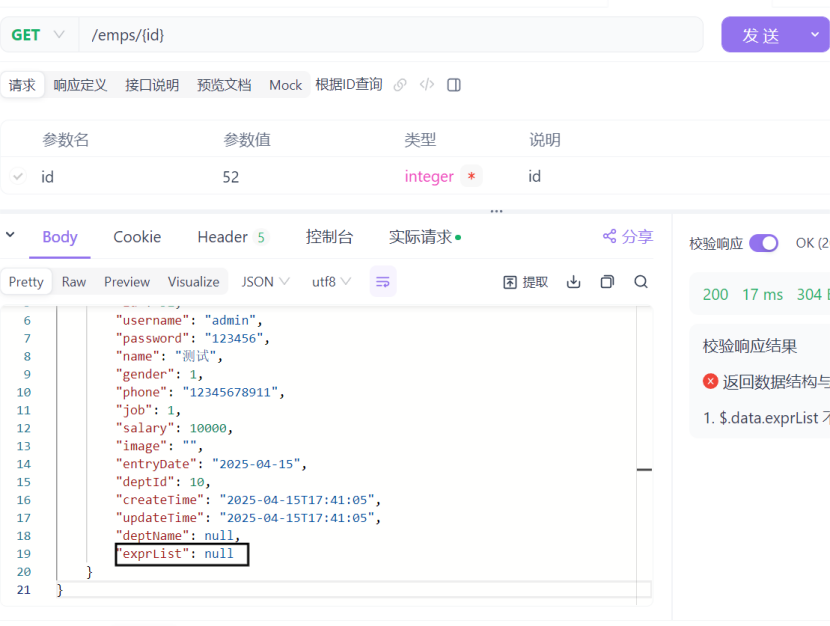
在控制台中我们发现工作经历的数据有传过来,这是工作经历只有一条的情况,我们在新建一条工作经历看看。

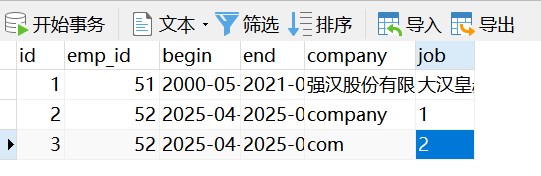
我们可以看到出错了,这里一共传回两个Emp员工对象,而我们在EmpMapper的getById方法中,返回值是Emp,只能接受一个员工对象,对象不对应,所以才出错了。


在这种一对多的查询中,我们要想成功的封装的结果,需要手动的基于 <resultMap> 来进行封装结果。
在EmpMapper.xml配置SQL:
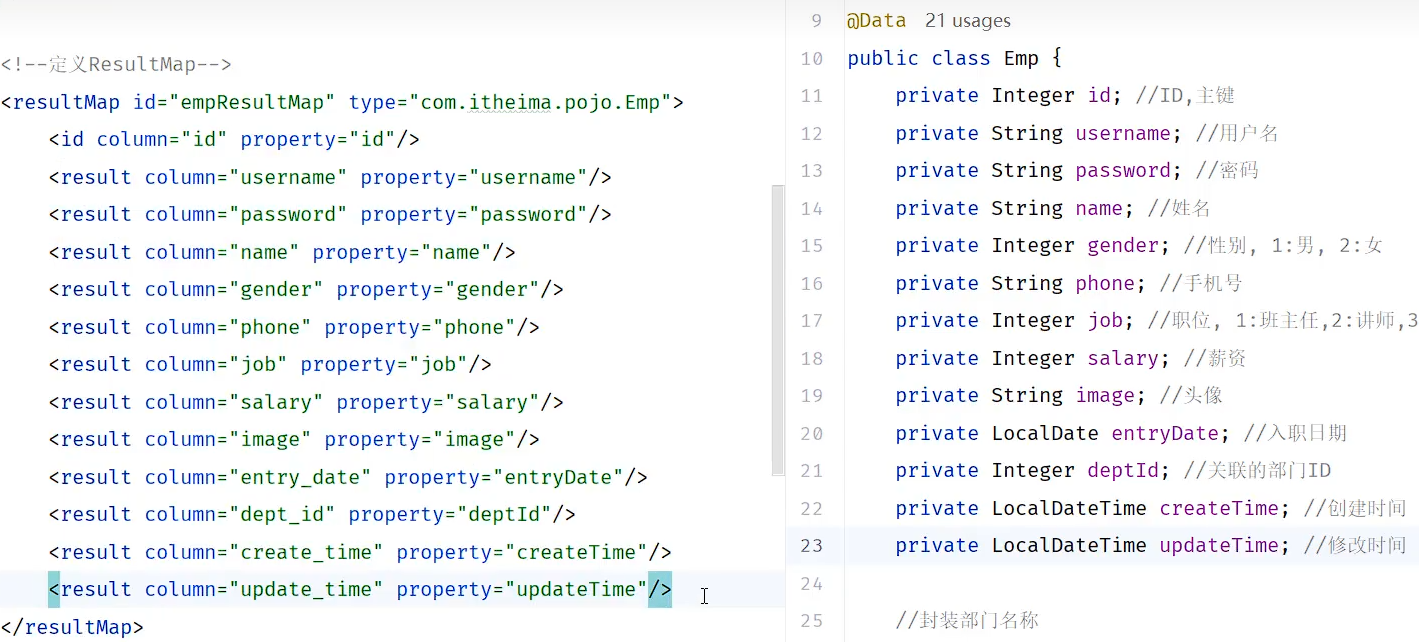
<!--自定义结果集ResultMap-->
<resultMap id="empResultMap" type="com.itheima.pojo.Emp">
<id column="id" property="id" />
<result column="username" property="username" />
<result column="password" property="password" />
<result column="name" property="name" />
<result column="gender" property="gender" />
<result column="phone" property="phone" />
<result column="job" property="job" />
<result column="salary" property="salary" />
<result column="image" property="image" />
<result column="entry_date" property="entryDate" />
<result column="dept_id" property="deptId" />
<result column="create_time" property="createTime" />
<result column="update_time" property="updateTime" />
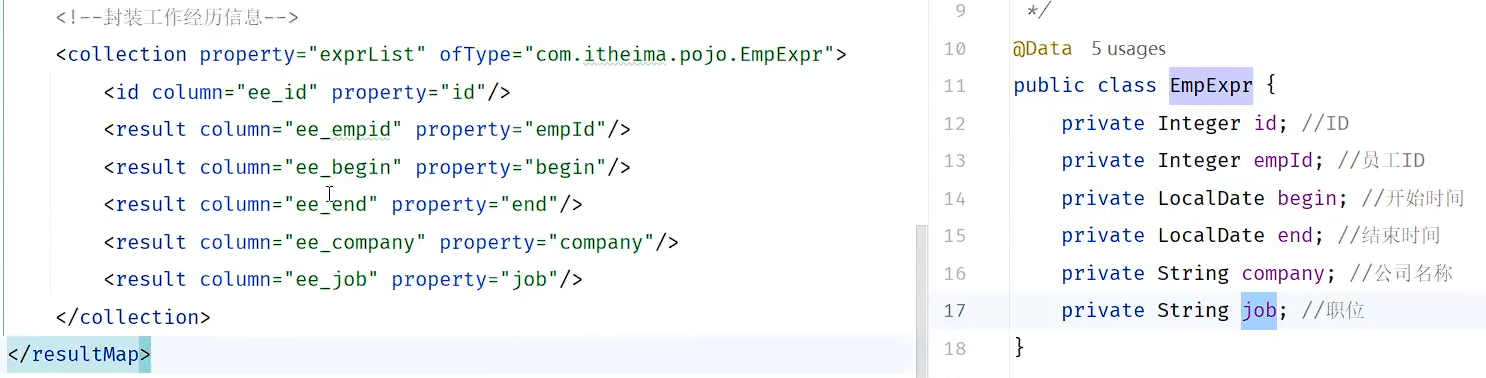
<!--封装exprList-->
<collection property="exprList" ofType="com.itheima.pojo.EmpExpr">
<id column="ee_id" property="id"/>
<result column="ee_company" property="company"/>
<result column="ee_job" property="job"/>
<result column="ee_begin" property="begin"/>
<result column="ee_end" property="end"/>
<result column="ee_empid" property="empId"/>
</collection>
</resultMap>
<!--根据ID查询员工的详细信息-->
<select id="getById" resultMap="empResultMap">
select e.*,
ee.id ee_id,
ee.emp_id ee_empid,
ee.begin ee_begin,
ee.end ee_end,
ee.company ee_company,
ee.job ee_job
from emp e left join emp_expr ee on e.id = ee.emp_id
where e.id = #{id}
</select>这里column要与emp表的字段名一一对应,property要与Emp类的变量名一一对应
封装集合需要用collection,里面的column要与emp_expr表的字段名一一对应,property要与EmpExpr的变量名一一对应。
Mybatis中封装查询结果,什么时候用 resultType,什么时候用resultMap ?
如果查询返回的字段名与实体的属性名可以直接对应上,用resultType。
如果查询返回的字段名与实体的属性名对应不上,或实体属性比较复杂,可以通过resultMap手动封装。
3.2 修改员工信息
3.2.1 实现思路
查询回显之后,就可以在页面上修改员工的信息了。
-
当用户修改完数据之后,点击保存按钮,就需要将数据提交到服务端,然后服务端需要将修改后的数据更新到数据库中 。
-
而此次更新的时候,既需要更新员工的基本信息; 又需要更新员工的工作经历信息 。
请求路径:
/emps请求方式:
PUT接口描述:该接口用于修改员工的数据信息
请求数据样例:
{ "id": 2, "username": "zhangwuji", "password": "123456", "name": "张无忌", "gender": 1, "image": "https://web-framework.oss-cn-hangzhou.aliyuncs.com/2022-09-02-00-27-53B.jpg", "job": 2, "salary": 8000, "entryDate": "2015-01-01", "deptId": 2, "createTime": "2022-09-01T23:06:30", "updateTime": "2022-09-02T00:29:04", "exprList": [ { "id": 1, "begin": "2012-07-01", "end": "2015-06-20" "company": "中软国际股份有限公司" "job": "java开发", "empId": 2 }, { "id": 2, "begin": "2015-07-01", "end": "2019-03-03" "company": "百度科技股份有限公司" "job": "java开发", "empId": 2 }, { "id": 3, "begin": "2019-3-15", "end": "2023-03-01" "company": "阿里巴巴科技股份有限公司" "job": "架构师", "empId": 2 } ] }响应数据样例:
{ "code":1, "msg":"success", "data":null }
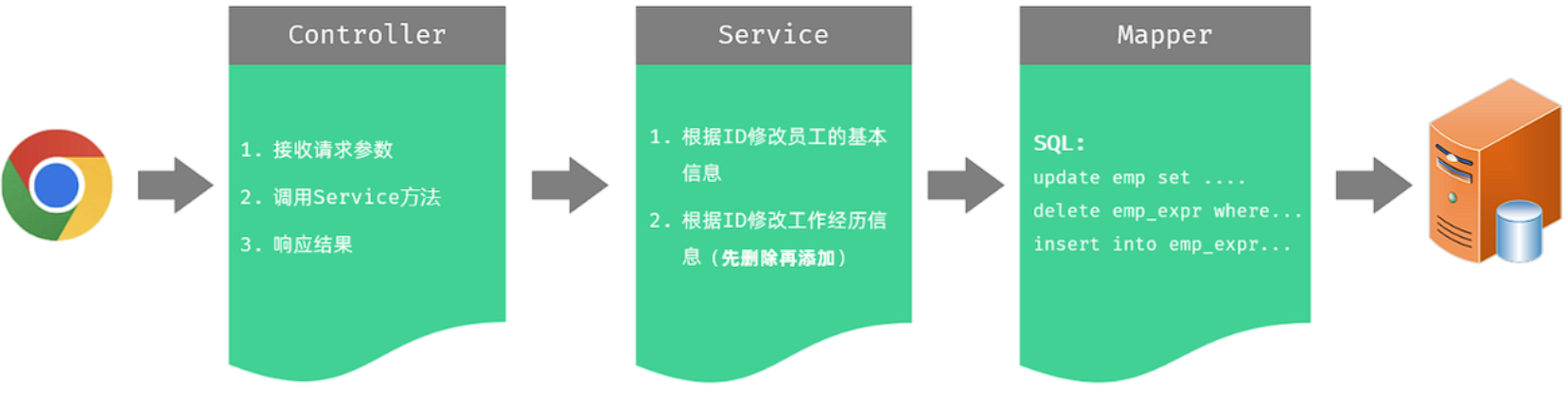
实现该功能时,三层架构每一层的职责:
-
Controller层:负责接收前端发起的请求参数,并调用Service删除员工数据,然后响应数据。
-
Service层:调用Mapper接口方法,根据ID查询修改员工的基本信息,之后删除所有工作经历,再添加修改后的工作经历。
-
Mapper层:执行SQL语句执行删除两张数据表数据的操作。
3.2.2 代码实现
3.2.2.1 Controller层
在EmpController增加update方法接收请求参数,响应数据
/**
* 修改员工
*/
@PutMapping
public Result update(@RequestBody Emp emp) {
log.info("修改员工信息:{}", emp);
empService.update(emp);
return Result.success(emp);
}3.2.2.2 Service层
1).EmpService接口增加update方法
/**
* 修改员工信息
*/
void update(Emp emp);2).EmpServiceImpl实现类实现update方法
- 将传过来的请求参数员工对象emp的更新时间设置为当前时间,更新员工信息
- 调用工作经历接口的删除方法,根据id将对应的工作经历全部删除
- 获取emp的工作经历集合,将所有工作经历数据的EmpId都设置为emp的id
- 调用工作经历接口的插入方法,将新的工作经历插入
@Override
@Transactional(rollbackFor = Exception.class)
public void update(Emp emp) {
//1. 根据id查询修改员工的基本信息
emp.setUpdateTime(LocalDateTime.now());
empMapper.updateById(emp);
//2. 根据id查询修改员工的工作经历信息
//2.1 先删除原本的工作经历
empExprMapper.deleteByEmpIds(Arrays.asList(emp.getId()));
//2.2 再插入新的工作经历
List<EmpExpr> exprList = emp.getExprList();
// 如果exprList不为空,则遍历集合,为每个工作经历的empId设置当前保存的员工的id
if (!CollectionUtils.isEmpty(exprList)){
exprList.forEach(expr -> expr.setEmpId(emp.getId()));
// 批量保存
empExprMapper.insertBatch(exprList);
}
}3.2.2.3 Mapper层
1).EmpMapper接口中增加updateById方法
/**
* 修改员工信息
*/
void updateById(Emp emp);
2).EmpMapper.xml配置文件中定义对应的SQL语句
<update id="updateById">
update emp set
username = #{username},
password = #{password},
name = #{name},
gender = #{gender},
phone = #{phone},
job = #{job},
salary = #{salary},
image = #{image},
entry_date = #{entryDate},
dept_id = #{deptId},
update_time = #{updateTime}
where id = #{id}
</update>3.2.3 代码优化
如果用上面的代码更新员工数据,会出现一个问题,就是必须修改所有的数据,否则没修改的数据会被置为空。但是修改数据不可能一直修改所有数据,所以我们需要基于动态SQL更新员工信息。
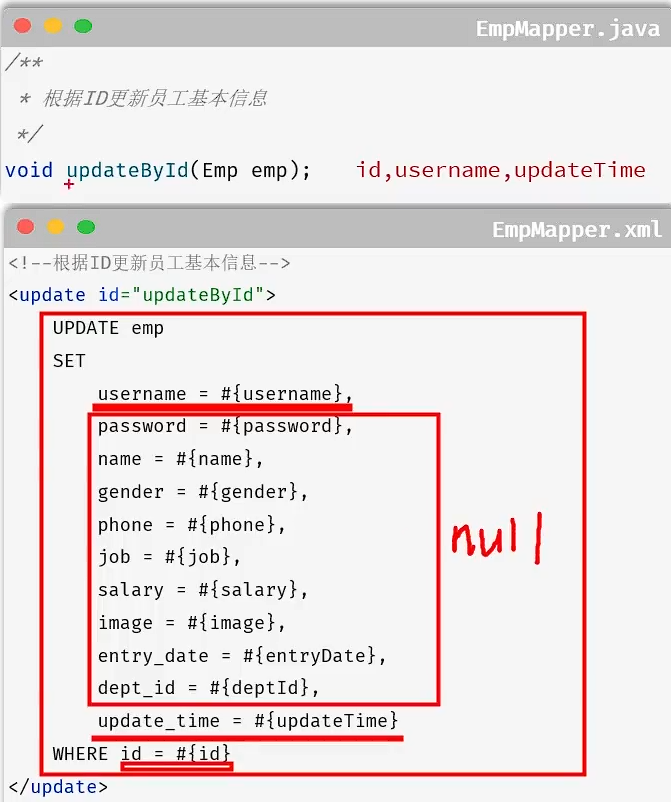
<update id="updateById">
update emp
<set>
<if test="username != null and username != ''">username = #{username},</if>
<if test="password != null and password != ''">password = #{password},</if>
<if test="name != null and name != ''">name = #{name},</if>
<if test="gender != null">gender = #{gender},</if>
<if test="phone != null and phone != ''">phone = #{phone},</if>
<if test="job != null">job = #{job},</if>
<if test="salary != null">salary = #{salary},</if>
<if test="image != null and image != ''">image = #{image},</if>
<if test="entryDate != null">entry_date = #{entryDate},</if>
<if test="deptId != null">dept_id = #{deptId},</if>
<if test="updateTime != null">update_time = #{updateTime},</if>
</set>
where id = #{id}
</update><set>标签的作用:自动生成set关键字,并删除多余的逗号
四、异常处理
4.1 问题分析
我们在修改部门数据的时候,如果输入一个在数据库表中已经存在的手机号,点击保存按钮之后,前端提示了错误信息,但是返回的结果并不是统一的响应结果,而是框架默认返回的错误结果 。
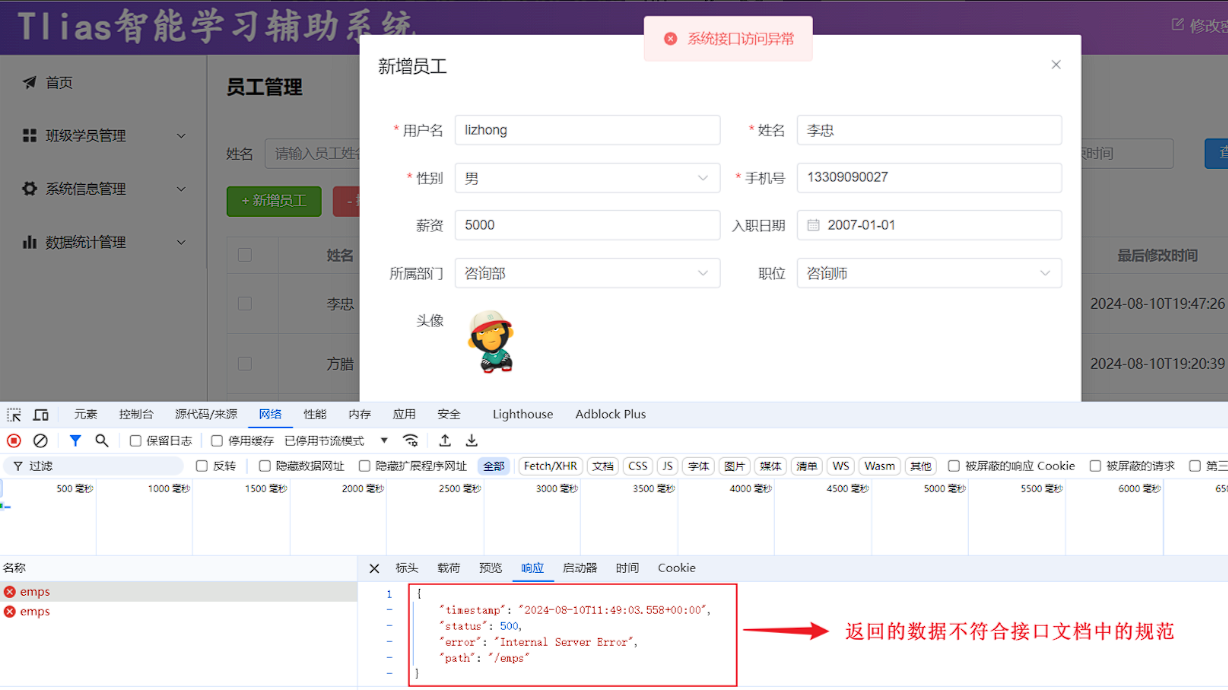
状态码为500,表示服务器端异常,我们打开idea,来看一下,服务器端出了什么问题。
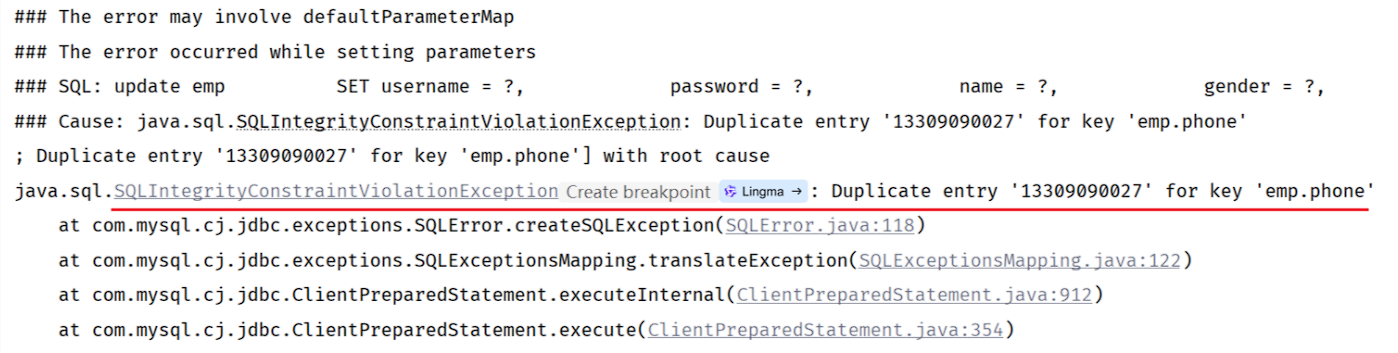
上述错误信息的含义是,emp员工表的phone手机号字段的值重复了,因为在数据库表emp中已经有了13309090027这个手机号了,我们之前设计这张表时,为phone字段建议了唯一约束,所以该字段的值是不能重复的。
而当我们再将该员工的手机号也设置为 13309090027,就违反了唯一约束,此时就会报错。我们来看一下出现异常之后,最终服务端给前端响应回来的数据长什么样。
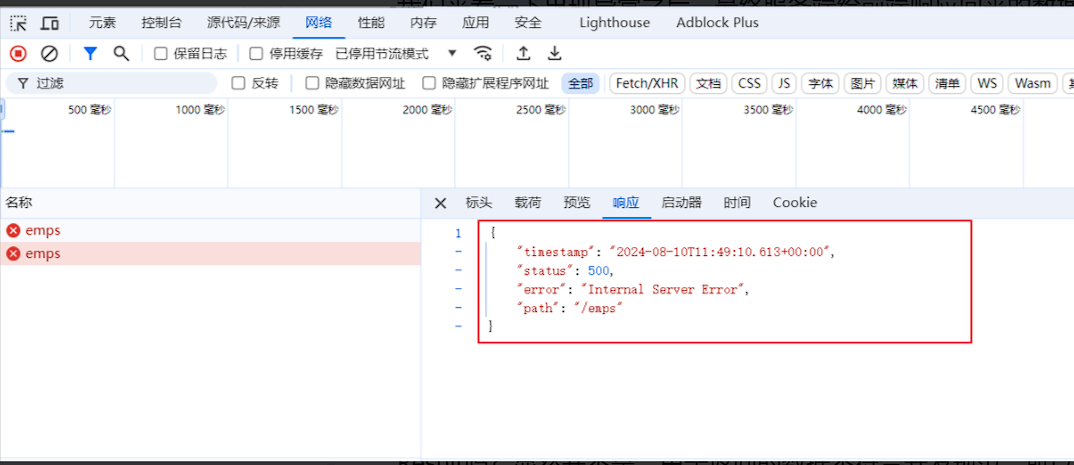
响应回来的数据是一个JSON格式的数据。但这种JSON格式的数据还是我们开发规范当中所提到的统一响应结果Result吗?显然并不是。由于返回的数据不符合开发规范,所以前端并不能解析出响应的JSON数据 。
接下来我们需要思考的是出现异常之后,当前案例项目的异常是怎么处理的?
答案:没有做任何的异常处理

当我们没有做任何的异常处理时,我们三层架构处理异常的方案:
-
Mapper接口在操作数据库的时候出错了,此时异常会往上抛(谁调用Mapper就抛给谁),会抛给service。
-
service 中也存在异常了,会抛给controller。
-
而在controller当中,我们也没有做任何的异常处理,所以最终异常会再往上抛。最终抛给框架之后,框架就会返回一个JSON格式的数据,里面封装的就是错误的信息,但是框架返回的JSON格式的数据并不符合我们的开发规范。
4.2 解决问题
那么在三层构架项目中,出现了异常,该如何处理?
方案一:在所有Controller的所有方法中进行try…catch处理(缺点:代码臃肿,不推荐)
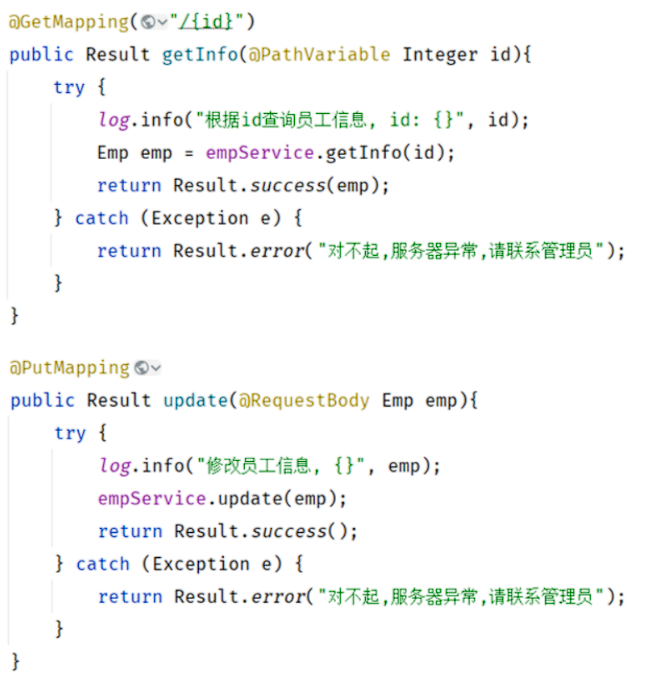
方案二:全局异常处理器
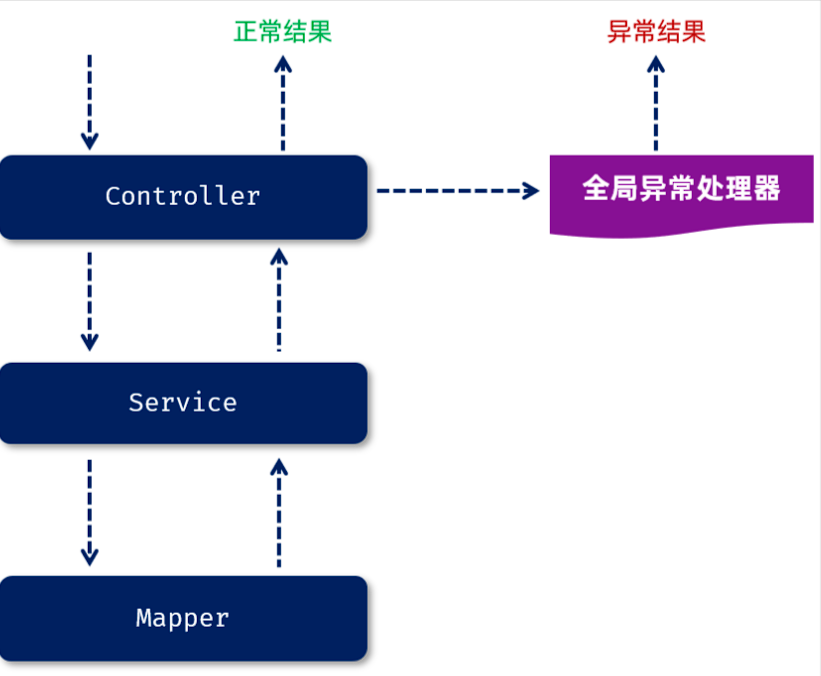
4.3 全局异常处理器
我们该怎么样定义全局异常处理器?
-
定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解@RestControllerAdvice,加上这个注解就代表我们定义了一个全局异常处理器。
-
在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解@ExceptionHandler。通过@ExceptionHandler注解当中的value属性来指定我们要捕获的是哪一类型的异常。
新建包exception,在里面新建GlobalExceptionHandler类
import com.whd.pojo.Result;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
/**
* 全局异常处理
*/
@Slf4j
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler
public Result handleException(Exception e) {
log.error("服务器发生异常:{}", e.getMessage());
return Result.error("服务器发生异常");
}
}@RestControllerAdvice = @ControllerAdvice + @ResponseBody
处理异常的方法返回值会转换为json后再响应给前端
重新启动SpringBoot服务,打开浏览器,再来测试一下 修改员工 这个操作,我们依然设置已存在的 13309090027这个手机号:
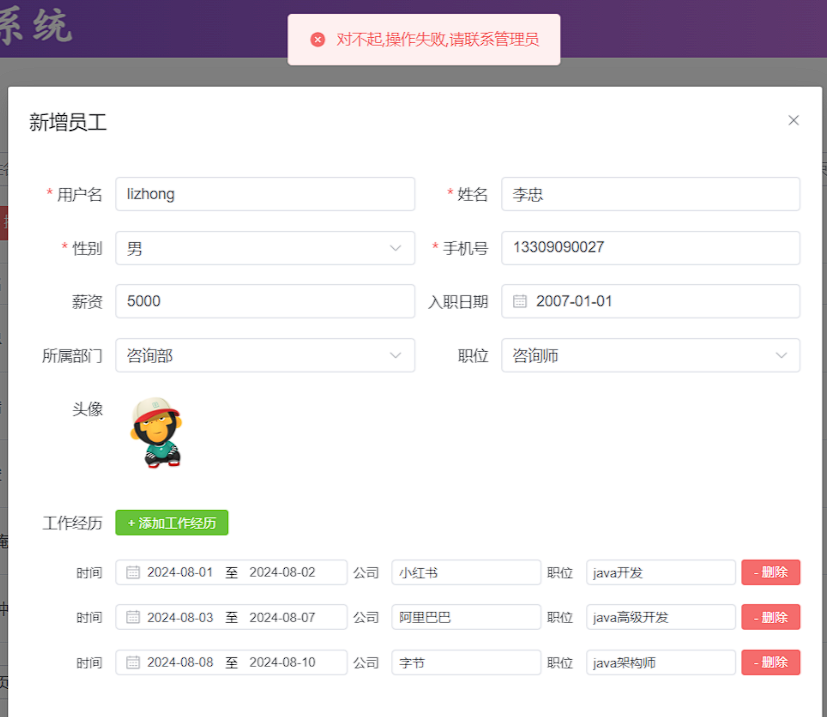
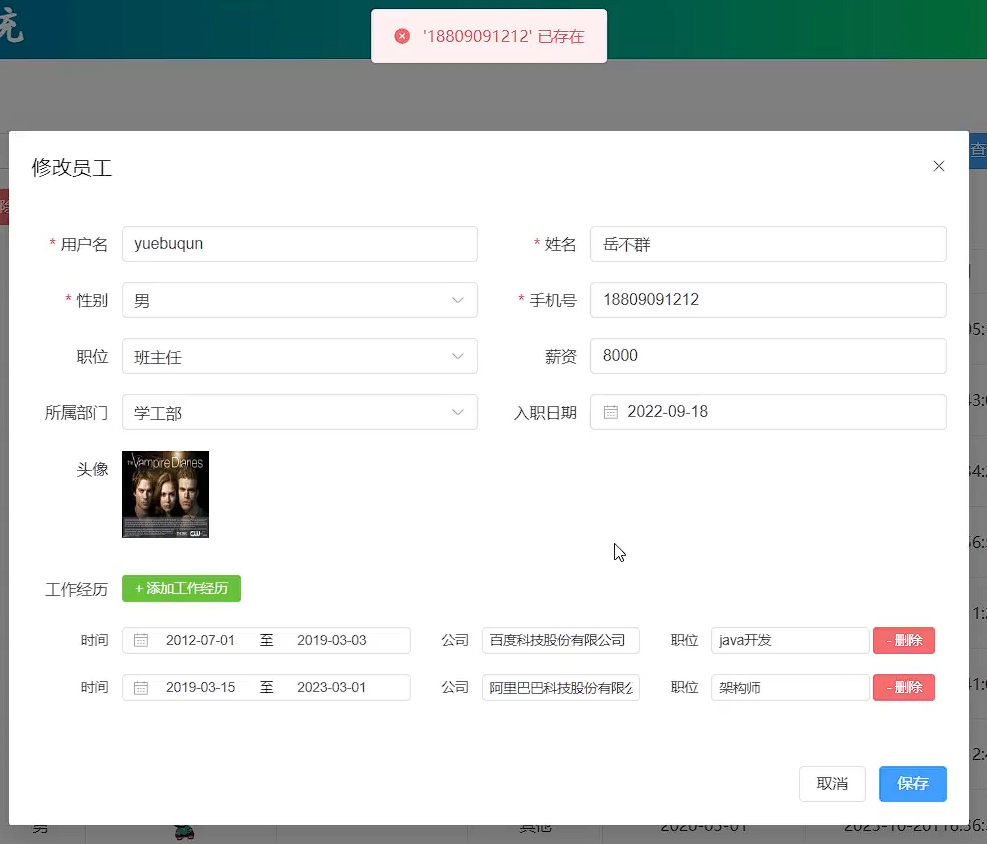
此时,我们可以看到,出现异常之后,异常已经被全局异常处理器捕获了。然后返回的错误信息,被前端程序正常解析,然后提示出了对应的错误提示信息。
如果想在前端显示具体的错误,可以再写个方法
![]()
@ExceptionHandler
public Result handleDuplicateKeyException(DuplicateKeyException e) {
log.error("服务器发生异常:", e);
String message = e.getMessage();
int i = message.indexOf("Duplicate entry");
String errMsg = message.substring(i);
String[] arr = errMsg.split(" ");
return Result.error(arr[2] + " 已存在");
}
DuplicateKeyException是org.springframework.dao包下的一个异常类 。在基于 Spring 框架开发,尤其是涉及数据库操作时经常会遇到。当在数据库执行插入操作,而插入的数据违反了数据库表中唯一性约束(比如主键约束、唯一索引约束等)时,Spring 的 JdbcTemplate 等数据访问组件在捕获到数据库驱动抛出的底层唯一性冲突异常后,通常会将其包装转换为DuplicateKeyException向上抛出,以便上层应用统一处理异常。是 org.springframework.dao 包下的一个异常类 。
以上就是全局异常处理器的使用,主要涉及到两个注解:
@RestControllerAdvice //表示当前类为全局异常处理器
@ExceptionHandler //指定可以捕获哪种类型的异常进行处理
五、职位统计
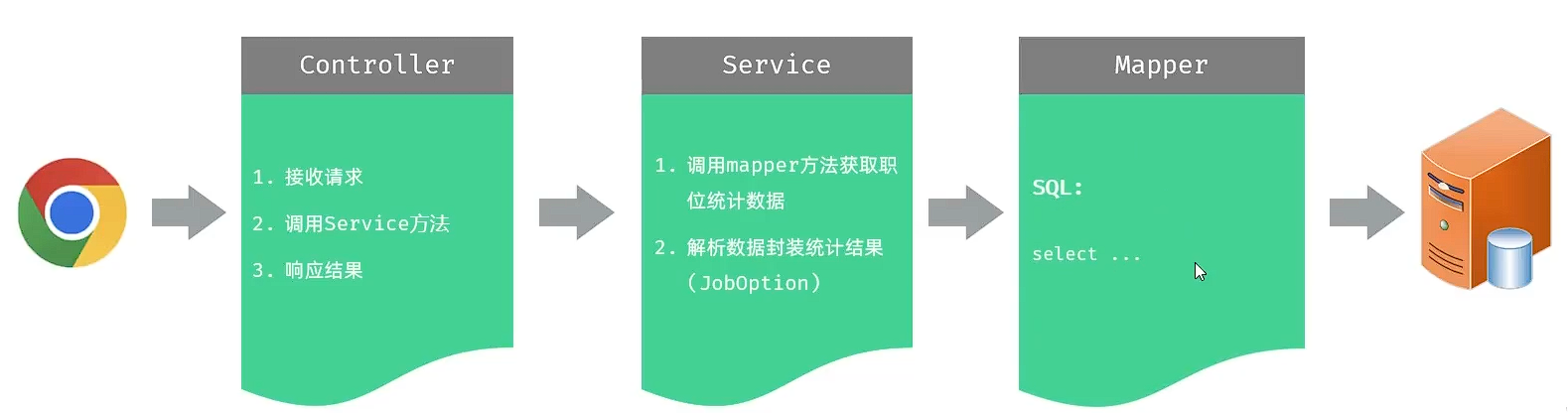
5.1 思路分析
员工管理的增删改查功能我们已开发完成,接下来,我们再来完成员工信息统计的接口开发。 对于这些图形报表的开发,其实呢,都是基于现成的一些图形报表的组件开发的,比如:Echarts、HighCharts等。
而报表的制作,主要是前端人员开发,引入对应的组件(比如:ECharts)即可。 服务端开发人员仅为其提供数据即可。
官网:https://echarts.apache.org/zh/index.html
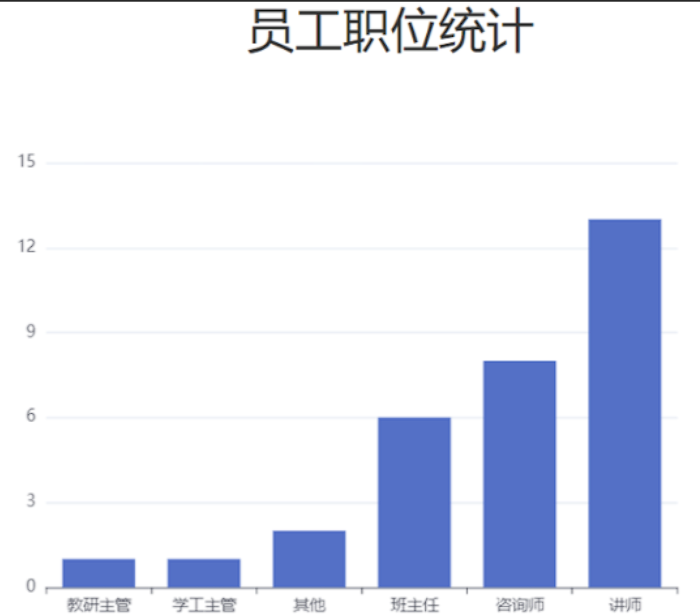
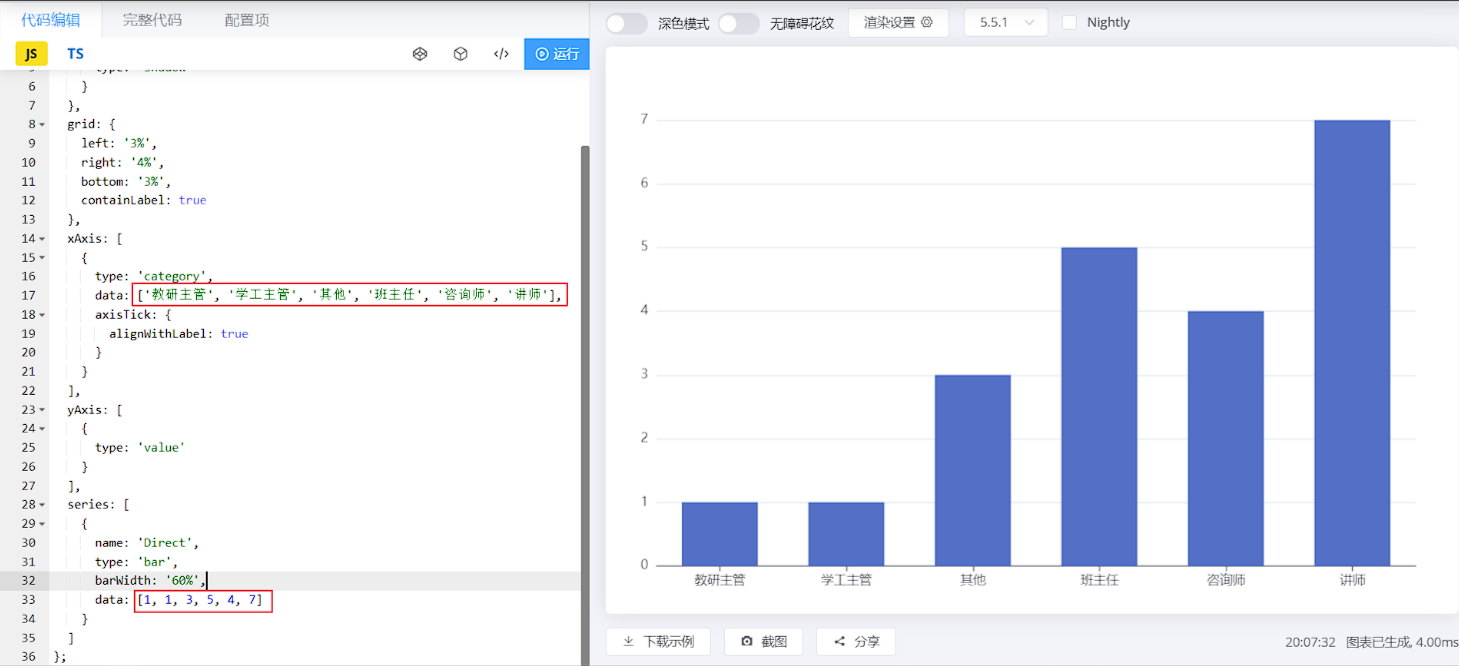
对于这类的图形报表,服务端要做的,就是为其提供数据即可。 我们可以通过官方的示例,看到提供的数据其实就是X轴展示的信息,和对应的数据。
请求路径:
/report/empJobData请求方式:
GET接口描述:统计各个职位的员工人数
请求参数:无
响应数据样例:
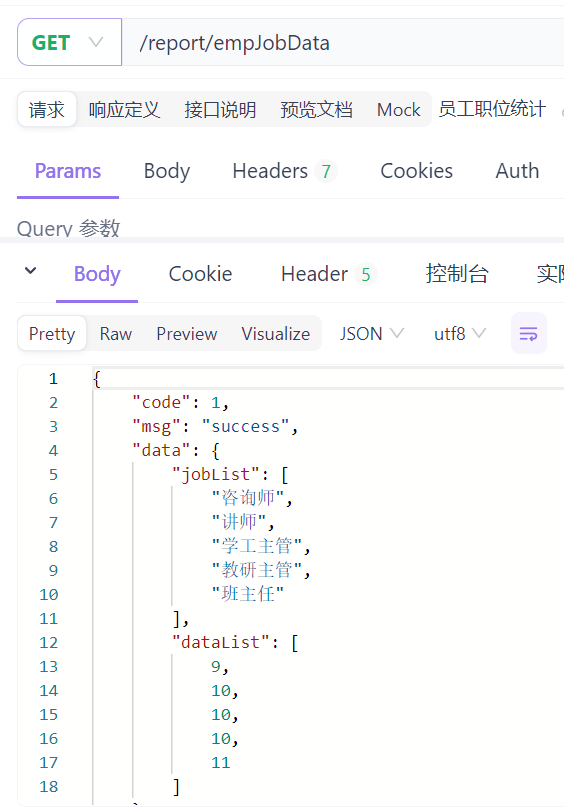
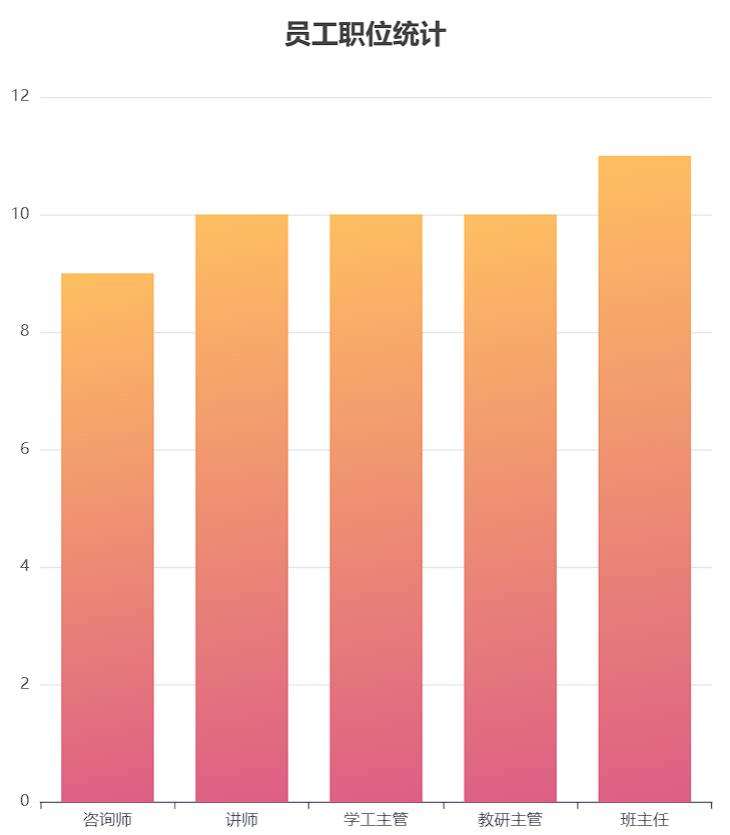
{ "code": 1, "msg": "success", "data": { "jobList": ["教研主管","学工主管","其他","班主任","咨询师","讲师"], "dataList": [1,1,2,6,8,13] } }
在pojo上新建类jobOption,用来保存职位信息和人数信息。
package com.whd.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.List;
/**
* 用来保存职位信息和各职位的人数信息
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class JobOption {
private List jobList;
private List dataList;
}
SQL语句如下:
select
(case job when 1 then '班主任'
when 2 then '讲师'
when 3 then '学工主管'
when 4 then '教研主管'
when 5 then '咨询师'
else '其他' end) pos,
count(*) total
from emp group by job //根据工作分组
order by total //根据人数排序实现该功能时,三层架构每一层的职责:
-
Controller层:负责接收前端发起的请求,调用Service查询数据,然后响应结果。
-
Service层:负责调用Mapper接口方法,获取职位统计数据,并封装进JobOption。
-
Mapper层:执行SQL语句执行职位统计数据的操作。
5.2 代码实现
1). 定义EmpMapper 接口
统计的是员工的信息,所以需要操作的是员工表。 所以代码我们就写在EmpMapper 接口即可。
/**
* 统计各个职位的员工人数
*/
@MapKey("pos")
List<Map<String,Object>> countEmpJobData();如果查询的记录往Map中封装,可以通过@MapKey注解指定返回的map中的唯一标识是那个字段。【也可以不指定】
2). 定义EmpMapper.xml
<!-- 统计各个职位的员工人数 -->
<select id="countEmpJobData" resultType="java.util.Map">
select
(case job when 1 then '班主任'
when 2 then '讲师'
when 3 then '学工主管'
when 4 then '教研主管'
when 5 then '咨询师'
else '其他' end) pos,
count(*) total
from emp group by job
order by total
</select>case流程控制函数:
语法一:case when cond1 then res1 [ when cond2 then res2 ] else res end ;
含义:如果 cond1成立, 取 res1。 如果 cond2 成立,取 res2。 如果前面的条件都不成立,则取 res。
语法二(仅适用于等值匹配):case expr when val1 then res1 [ when val2 then res2 ] else res end ;
含义:如果 expr 的值为 val1 , 取 res1。 如果 expr 的值为 val2 ,取 res2。 如果前面的条件都不成立,则取 res。
3). 定义ReportController,并添加方法。
在controller新建类ReportController

package com.whd.controller;
import com.whd.pojo.JobOption;
import com.whd.pojo.Result;
import com.whd.service.ReportService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@Slf4j
@RequestMapping("/report")
@RestController
public class ReportController {
@Autowired
private ReportService reportService;
/**
*统计员工职位人数
*/
@GetMapping("/empJobData")
public Result getEmpJobData() {
log.info("统计员工职位人数");
JobOption jobOption = reportService.getEmpJobData();
return Result.success(jobOption);
}
}
4). 定义ReportService接口,并添加接口方法。
在service新建ReportService接口,新建ReportServiceImpl类
import com.whd.pojo.JobOption;
public interface ReportService {
/**
* 获取员工职位统计数据
*/
JobOption getEmpJobData();
}
5). 定义ReportServiceImpl实现类,并实现方法
import com.whd.mapper.EmpMapper;
import com.whd.pojo.JobOption;
import com.whd.service.EmpService;
import com.whd.service.ReportService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
@Service
public class ReportServiceImpl implements ReportService {
@Autowired
private EmpMapper empMapper;
@Override
public JobOption getEmpJobData() {
//1.调用Mapper接口,获取员工职位统计数据
List<Map<String,Object>> List = empMapper.countEmpJobData();
//2.组装结果,并返回
// List.stream()获取流, map()方法将流中的元素映射到一个新的流中
// dataMap -> dataMap.get("pos")获取Map中的pos属性,
// toList()将流中的元素收集到一个新的列表中
List<Object> jobList = List.stream().map(dataMap -> dataMap.get("pos")).toList();
List<Object> dataList = List.stream().map(dataMap -> dataMap.get("total")).toList();
return new JobOption(jobList, dataList);
}
}
5.3 测试
六、性别统计
6.1 思路分析
性别统计也是一样的思路。
对于这类的图形报表,服务端要做的,就是为其提供数据即可。 我们可以通过官方的示例,看到提供的数据就是一个json格式的数据。
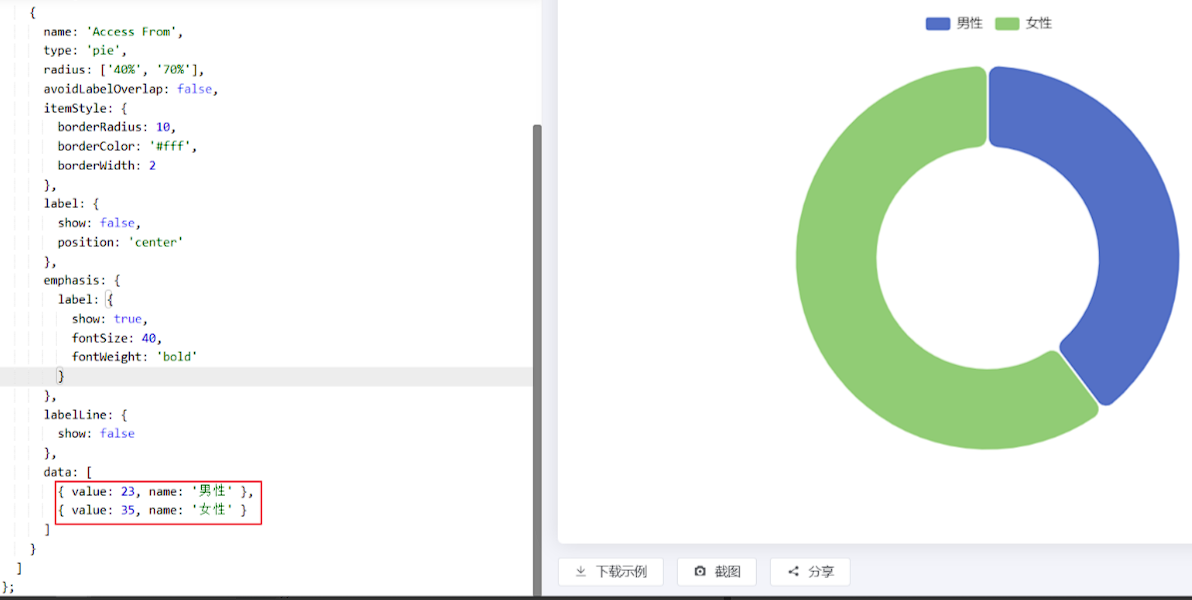
请求路径:
/report/empGenderData请求方式:
GET接口描述:统计员工性别信息
请求参数:无
响应数据样例:
{ "code": 1, "msg": "success", "data": [ {"name": "男性员工","value": 5}, {"name": "女性员工","value": 6} ] }
SQL语句如下:
select
if(gender = 1, '男', '女') as name,
count(*) as value
from emp group by genderif函数语法:
if(条件, 条件为true取值, 条件为false取值)ifnull函数语法:
ifnull(expr, val1)如果expr不为null,取自身,否则取val1
6.2 代码实现
1). 在ReportController添加方法。
/**
* 统计员工性别信息
*/
@GetMapping("/empGenderData")
public Result getEmpGenderData(){
log.info("统计员工性别信息");
List<Map<String,Object>> genderList = reportService.getEmpGenderData();
return Result.success(genderList);
}2). 在ReportService接口,添加接口方法。
/**
* 统计员工性别信息
*/
List<Map<String,Object>> getEmpGenderData();
3). 在ReportServiceImpl实现类,实现方法
@Override
public List<Map<String,Object>> getEmpGenderData() {
return empMapper.countEmpGenderData();
}4). 定义EmpMapper 接口
/**
* 统计员工性别信息
*/
@MapKey("name")
List<Map<String,Object>> countEmpGenderData();5). 定义EmpMapper.xml
<!-- 统计员工的性别信息 -->
<select id="countEmpGenderData" resultType="java.util.Map">
select
if(gender = 1, '男', '女') as name,
count(*) as value
from emp group by gender
</select>
6.3 测试
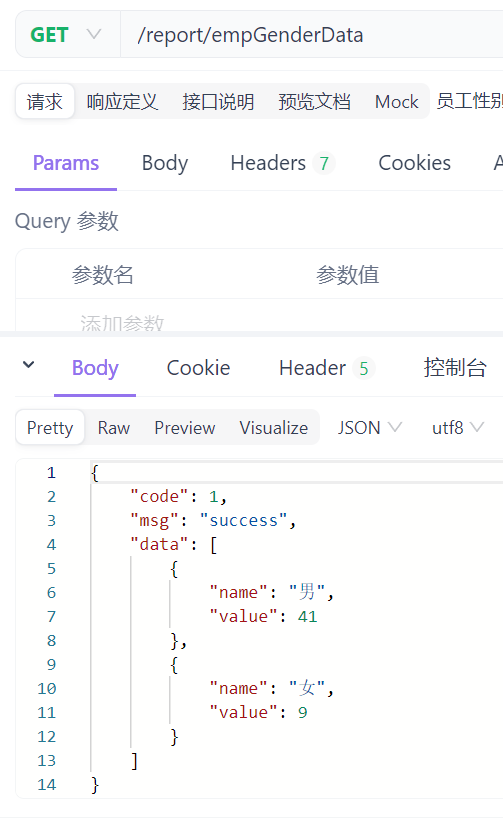
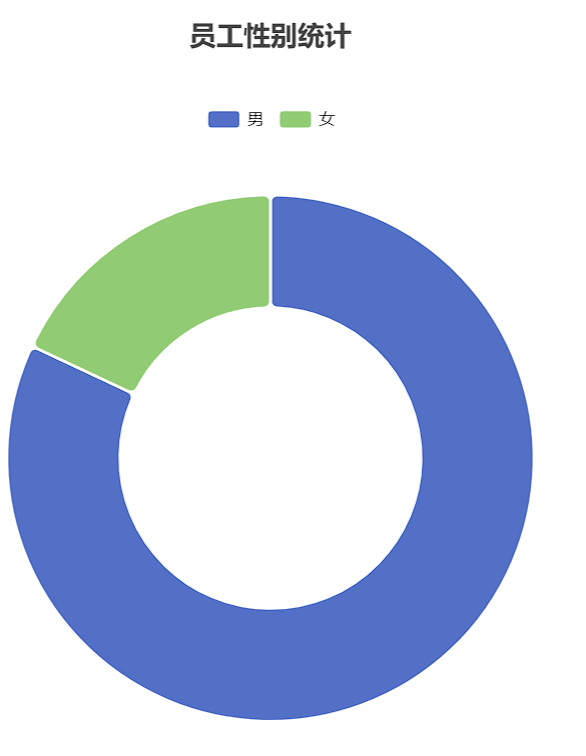

















 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









