







 超级会员免费看
超级会员免费看
Whisper Large 模型结构解析
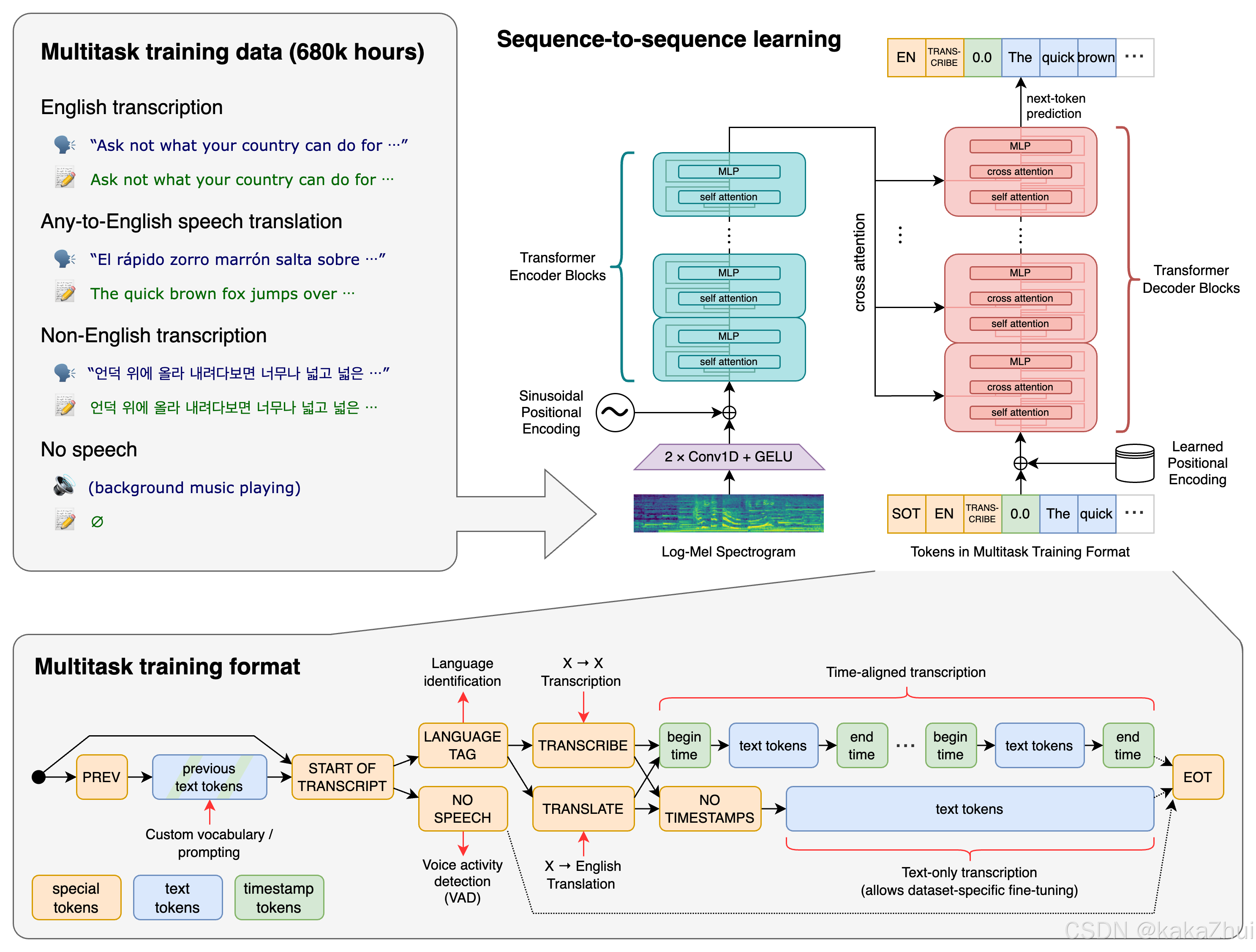
Whisper 模型是一种端到端的自动语音识别(ASR)系统,基于 Transformer 的编码器—解码器架构。其主要组成部分包括:
输入预处理
原始音频首先经过预处理,转换为 log‑Mel 谱图。这里通常使用固定参数的卷积层(例如 2 层卷积)进行特征提取和降采样,生成适合 Transformer 输入的特征矩阵。
编码器(Encoder)
编码器部分由多个 Transformer encoder 层堆叠构成,每一层包含:
1. 自注意力机制(Self-Attention):捕捉音频序列中的全局依赖关系。
2. 前馈神经网络(FFN):进行非线性变换。
3. 残差连接与层归一化:确保训练稳定性。
处理过程
编码器将 log‑Mel 特征映射到隐藏状态空间,形成全局音频表示。该过程通常首先将音频分割成30秒的片段&

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











