







 超级会员免费看
超级会员免费看
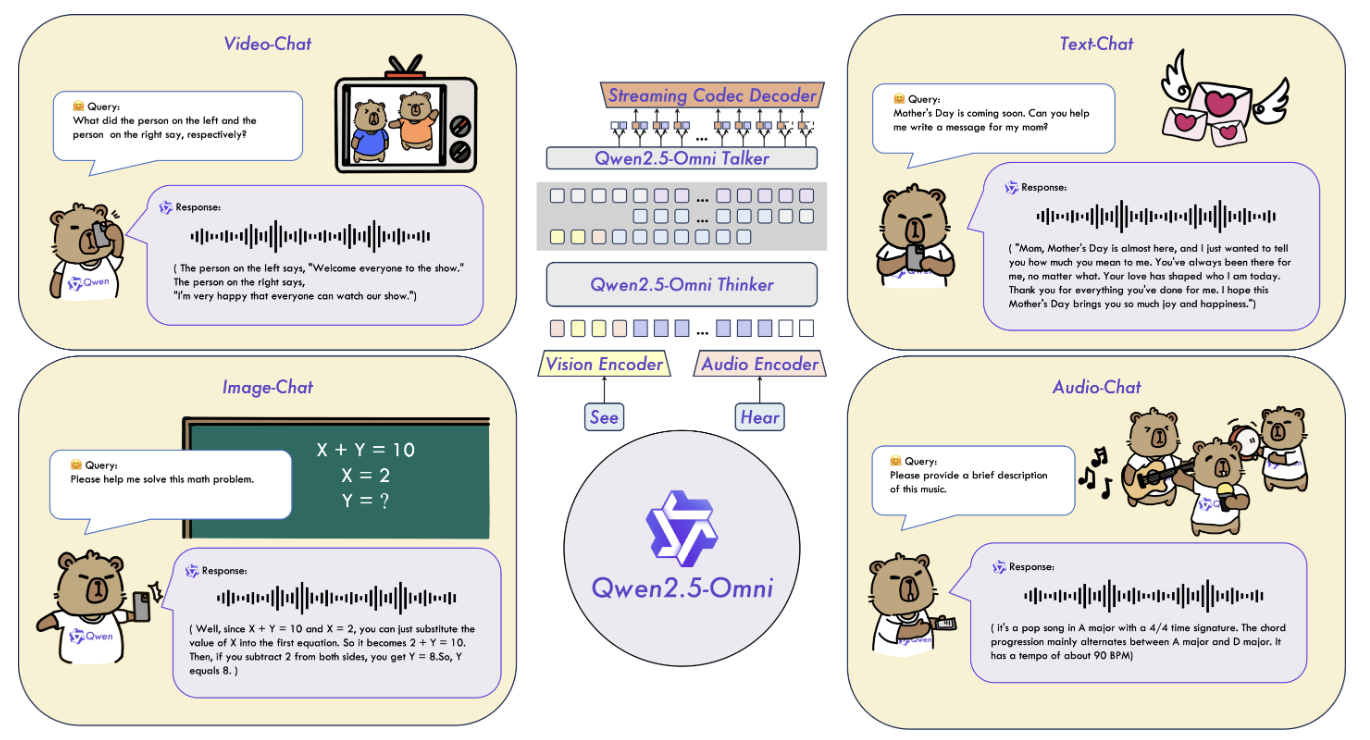
写在前面
**多模态大模型(MLLM)**应运而生。它们试图打破模态之间的壁垒,让 AI 不仅能“读懂”文字,还能“看见”图像、“听见”声音、“理解”视频。近年来,我们见证了 MLLM 的飞速发展,从理解图文到处理视频,再到实现语音对话,其能力边界不断拓展。
然而,构建一个真正统一、智能、且能实时交互的全能多模态模型,仍然面临着巨大的挑战:
- 多模态信息的融合:如何有效地融合来自不同模态(文本、图像、音频、视频)的信息,实现跨模态的理解和推理?
- 时序同步:如何处理视频中音频和视觉信号的时间同步问题?
- 并发生成:如何让模型同时生成文本和语音两种模态的输出,且互不干扰?
- 流式处理:如何实现对多模态信息的实时理解和实时响应,降低交互延迟?
为了应对这些挑战,阿里巴巴 Qwen 团队推出了

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











