



 本文介绍了一个使用批处理命令批量删除指定目录下所有文件的简单程序,并详细解释了del命令的参数用法。此外,还介绍了如何通过Windows系统的计划任务功能定期执行该程序。
本文介绍了一个使用批处理命令批量删除指定目录下所有文件的简单程序,并详细解释了del命令的参数用法。此外,还介绍了如何通过Windows系统的计划任务功能定期执行该程序。
1.写一个计划删除文件程序
@echo off
del /f /s /q C:\Users\hp\Desktop\directory\*.*
程序文件内容基本如上,可自行更改文件路径。
关于del的参数主要有以下:
/p:删除每一个文件之前提示确认;
/f:强制删除只读文件;
/s:删除所有子目录中的指定的文件;
/q:安静模式,删除全局通配符时,不要求确认。
2.设置计划任务
1.打开计算机(此电脑)——>右击属性——>控制面板——>系统与安全——>管理工具——>计划任务
2.创建任务

3.输入任务名称
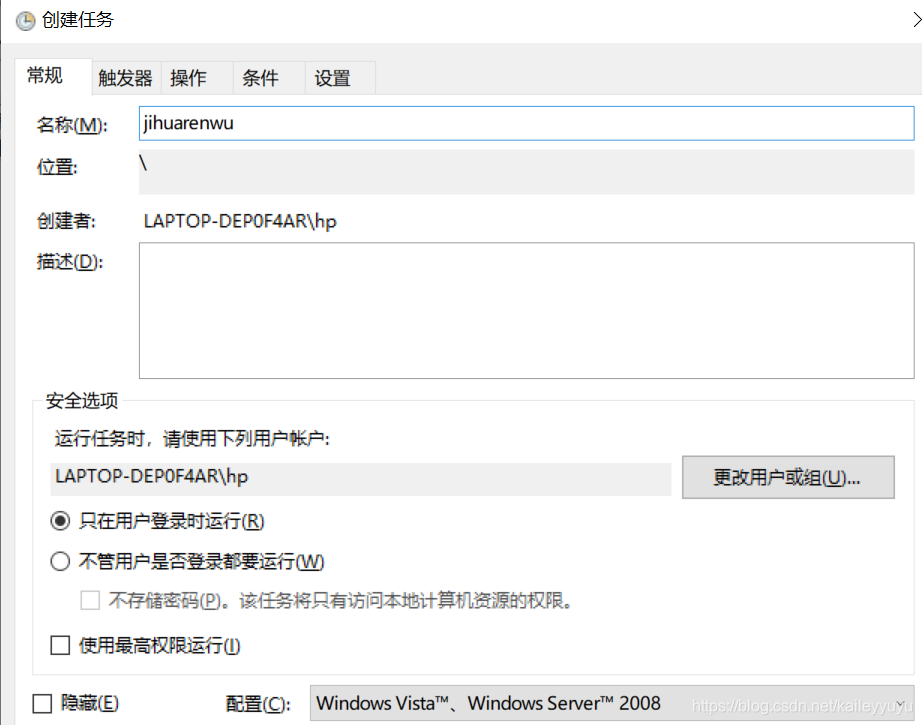
4.新建触发器,可以设置任务开始时间以及频率
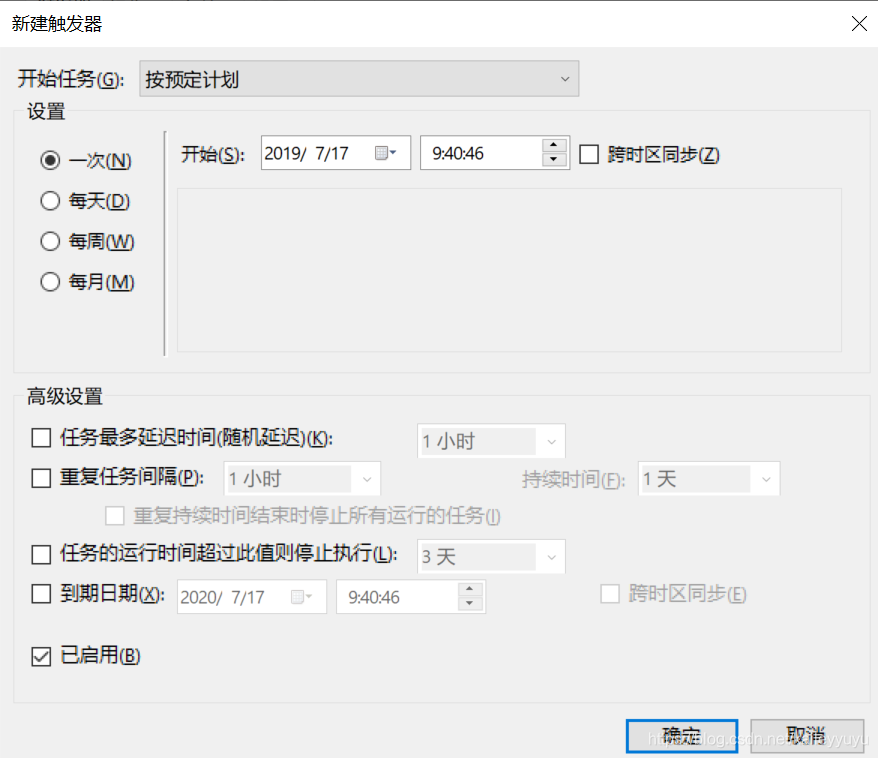
5.新建操作,可将需要执行的脚本添加进去,参数可根据需要自行设置
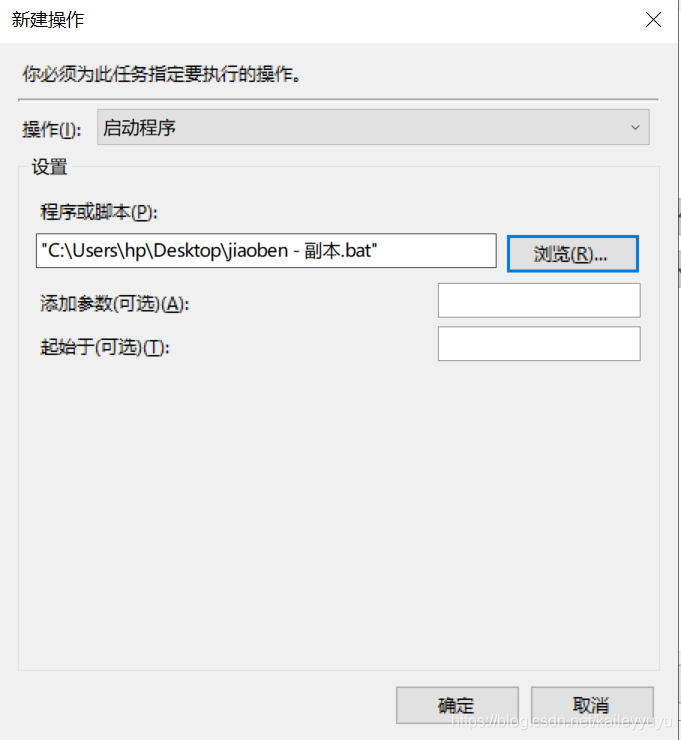
这样一个基本任务就完成了,可根据设置时间自行检测是否运行。


















 1275
1275





 到【灌水乐园】发言
到【灌水乐园】发言







