



 本文深入探讨Kafka的Controller选举过程,当Broker故障时,Controller如何从Zookeeper获取通知并重新分配Leader分区。同时,文章分析了如何防止Controller出现裂脑情况,利用epoch number确保集群一致性。
本文深入探讨Kafka的Controller选举过程,当Broker故障时,Controller如何从Zookeeper获取通知并重新分配Leader分区。同时,文章分析了如何防止Controller出现裂脑情况,利用epoch number确保集群一致性。
Broker如何成为Controller和解决脑裂问题?
(一)Broker如何成为Controller

最先在Zookeeper上创建临时节点/controller成功的Broker就是Controller。
源码路径(Kafka2.2):
Kafka#main->KafkaServerStartable#startup()->KafkaServer#startup()->KafkaController#startup()->eventManager.put(Startup)->elect()-> zkClient.registerControllerAndIncrementControllerEpoch


Controller重度依赖Zookeeper,依赖zookeepr保存元数据,依赖zookeeper进行服务发现。Controller大量使用Watch功能实现对集群的协调管理。
当broker节点因故障离开Kafka集群时,broker中存在的leader分区将不可用(因为客户端只对leader分区进行读写)。
为了最大限度地减少停机时间,需要快速找到替代的领导分区。Controller可以从zookeeper watch获取通知信息。Zookeeper给了客户端监听znode变化的能力,也就是所谓的watch通知功能。一旦znode节点创建、删除、子节点数量发生变化,或者znode中存储的数据本身发生变化,Zookeeper会通过节点变化处理程序显式通知客户端。
当Broker宕机或主动关闭时,Broker与Zookeeper的会话结束,znode会被自动删除。同样的,Zookeeper的watch机制把这个变化推送给Controller,让Controller知道有Broker down或者up,这样Controller就可以进行后续的协调操作。
Controller将收到通知并对其采取行动,以确定Broker上的哪些分区将成为Leader partition。然后,它会通知每个相关的Broker,或者Broker上的topic partition将成为leader partition,或者LeaderAndIsrRequest从新的leader分区复制数据。
(二)如何避免Controller出现裂脑
如果Controller所在的Broker故障,Kafka集群必须有新的Controller,否则集群将无法正常工作。这儿存在一个问题。很难确定Broker是宕机还是只是暂时的故障。但是,为了使集群正常运行,必须选择新的Controller。如果之前更换的Controller又正常了,不知道自己已经更换了,那么集群中就会出现两个Controller。
其实这种情况是很容易发生的。例如,由于垃圾回收(GC),一个Controller被认为是死的,并选择了一个新的控制器。在GC的情况下,在原Controller眼里没有任何变化,Broker甚至不知道自己已经被暂停了。因此,它将继续充当当前Controller,这在分布式系统中很常见,称为裂脑。
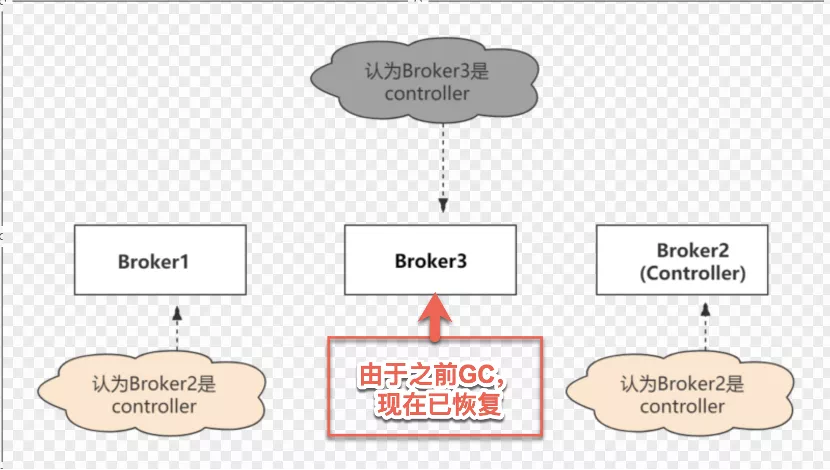
现在,集群中有两个Controller,可能会一起发出相互冲突的事件,这会导致脑裂。可能会导致严重的不一致。所以需要一种方法来区分谁是集群的最新Controller。
Kafka是通过使用epoch number来处理,epoch number只是一个单调递增的数。第一次选择控制器时,epoch number值为1。如果再次选择新控制器,epoch number为2,依次单调递增。
每个新选择的Controller通过zookeeper的条件递增操作获得一个新的更大的epoch number。当其他Broker知道当前的epoch number时,如果他们从Controller收到包含旧(较小)epoch number的消息,则它们将被忽略。即Broker根据最大的epoch number来区分最新的Controller。
epoch number记录在Zookeepr的一个永久节点controller_epoch。
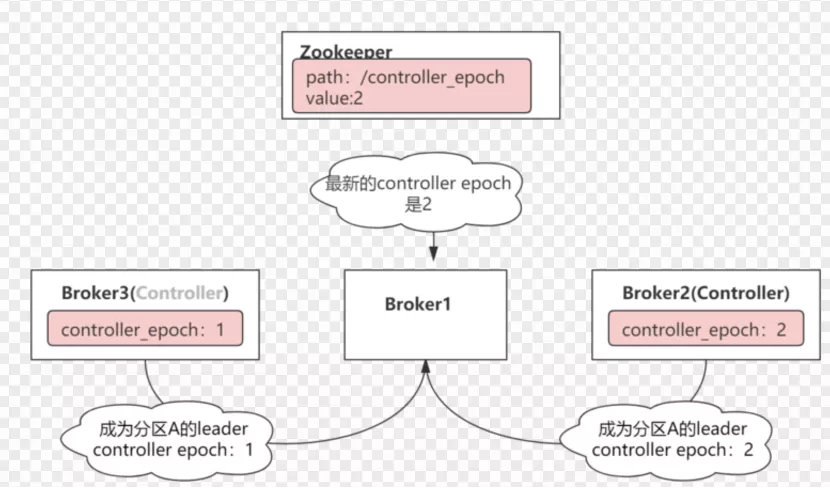
上图中,Broker3向Broker1下发命令:将Broker1上的partitionA做为leader,消息的epoch number值为1,同时Broker2也向Broker1发送同样的命令。不同的是,消息的epoch number值为2,此时broker1只监听broker2的命令(由于其epoch号大),而会忽略broker3的命令,以免发生脑裂。
国内最大最权威的 Kafka中文社区 ,在这里你可以结交各大互联网Kafka大佬以及近2000+Kafka爱好者,一起实现知识共享,实时掌控最新行业资讯,免费加入中~


















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









