







一、写在前面
-
计算机存储单位:计算机只能识别二进制(10011001…),1bit就是一个0或者1,1byte = 1字节=8bit。
-
基本数据类型介绍
本数据类型 占用空间 二进制位数 取值范围 默认值 byte 1字节 8bit [ − 2 7 , 2 7 − 1 ] [-2^7, 2^7-1] [−27,27−1]、 [ − 128 , 127 ] [-128, 127] [−128,127] 0 short 2字节 16bit [ − 2 15 , 2 15 − 1 ] [-2^{15}, 2^{15}-1] [−215,215−1]、 [ − 32768 , 32767 ] [-32768,32767] [−32768,32767] 0 int 4字节 32bit [ − 2 31 , 2 31 − 1 ] [-2^{31}, 2^{31}-1] [−231,231−1]、 [ − 2147483648 , 2147483647 ] [-2147483648,2147483647] [−2147483648,2147483647] 0 long 8字节 64bit [ − 2 63 , 2 63 − 1 ] [-2^{63}, 2^{63}-1] [−263,263−1] 0L float 4字节 32bit [ − 2 31 , 2 31 − 1 ] [-2^{31}, 2^{31}-1] [−231,231−1] 0.0f double 8字节 64bit [ − 2 63 , 2 63 − 1 ] [-2^{63}, 2^{63}-1] [−263,263−1] 0.0 boolean 1字节 8bit true、false false char 2字节 16bit [ 0 , 2 16 − 1 ] [0, 2^{16}-1] [0,216−1]、 [ 0 , 65535 ] [0,65535] [0,65535] ‘\u0000’ 注意:
(1) 在任何情况下整数型数据默认被当作int类型处理,如果希望被当作long类型处理则需要在数据后面加上字母L// 自动类型转换,int转long long a = 2147483647; // 报错,因为2147483648这个数据默认被当作int,但其超出了int取值范围 long b = 2147483648; // 加上L后2147483648就被当作long long c = 2147483648L;(2) 基本数据类型容量大小排序:byte < short(char) < int < long < float < double(规定浮点型比整型大)
二、自动类型转换、强制类型转换和其他情况
-
自动类型转换:小容量类型可直接赋值给大容量类型,称为自动类型转换
int a = 1;// 不存在类型转换 long b = a;// int类型数据自动转为long类型数据 long c = 1;// int类型数据1自动转为long类型数据 long d = 1L;// 不存在类型转换 -
强制类型转换:大容量类型不可以直接赋值给小容量类型,需要强制类型转换
long a = 1; int b = (int)a; int c = a;// 编译不通过 -
其他情况
byte b = 127; short s = 10000; char c = 65535;注意:
(1) 强转的原理就是强制砍掉二进制位数,如:long转int就会强制砍掉左边4个二进制位数。所以强制类型转换在大容量类型数据超过小容量类型取值范围时,会导致精度损失。(2) 对于byte、short和char,只要数据值不超过它们的取值范围,则可以直接赋值,不用把默认的int强转为byte/short/char。
三、关于char
在《java核心技术》中描述char类型是UTF-16编码中的一个代码单元,因此可以知道char的字符编码是UTF-16。
测试:
char c1 = '中';
char c2 = 'a';
char c3 = 'A';
char c4 = '0';
System.out.println("字符:" + c1 + " " + "编码:" + (int) c1);
System.out.println("字符:" + c2 + " " + "编码:" + (int) c2);
System.out.println("字符:" + c3 + " " + "编码:" + (int) c3);
System.out.println("字符:" + c4 + " " + "编码:" + (int) c4);
字符:中 编码:20013
字符:a 编码:97
字符:A 编码:65
字符:0 编码:48
结论:
- char的取值范围是[0,65535]其中的每一个数字表示UTF-16的编码即对应1个字符
- char类型可以进行运算,但本质上是字符对应的编码进行运算,最终输出的运算结果为编码运算后对应的字符
四、多种基本数据类型的混合运算
-
byte、short、char混合运算:各自会先转为int后再进行运算,运算结果为int类型
byte a = 1; short b = 2; char c = '0';// 转为int后为48 System.out.println(a + b + c);// 输出51 -
包含long、int或浮点型的混合运算:谁大听谁的,各自转换为容量最大的那个数据类型再进行运算
long a = 1;// 1.0 double b = 0.2; char c = '9';// 57.0 System.out.println(a + b + c);// 58.2 -
练习:判断下列代码哪些编译不通过、输出结果是什么
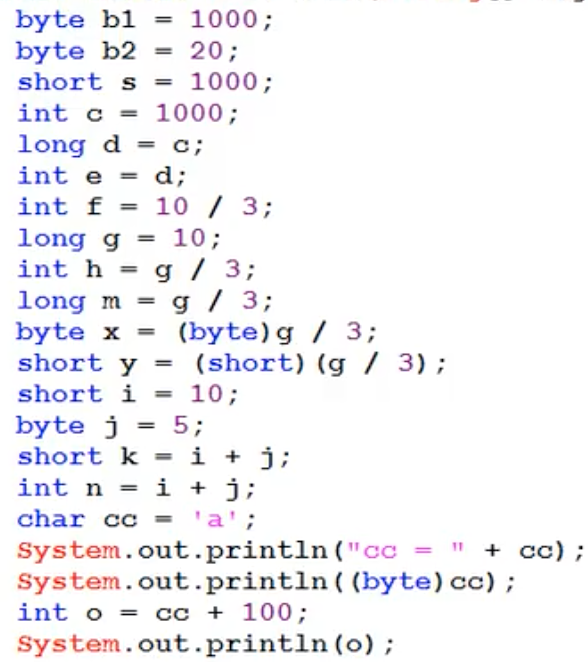
1. 编译报错,因为1000超过了byte的取值范围,此时需要把int强转为byte 2. 编译通过,20在byte取值范围内 (byte、short、char在其取值范围内可直接赋值,不用强转int) 3. 编译通过,1000在short取值范围内,理由如上 4. 编译通过 5. 编译通过,自动类型转换,小容量类型自动转换为大容量类型 6. 编译报错,大容量类型转为小容量类型需要强制类型转换 7. f=3 8. 小容量类型自动转换为大容量类型 9. 编译报错,g为long类型与3(int)运算结果为long,大容量类型转为小容量类型需要强制类型转换 10. 编译通过 11. 编译报错,首先把g强转为byte然后g会自动转换为int与3(int)运算最终结果为int类型 12. 编译通过 13. 编译通过 14. 编译通过 15. 编译报错,byte与short的运算会先转为int 16. 编译通过 17. 编译通过 18. 编译通过,字符串可以与字符相连 19. 输出字符'a'的ASCII码 20. 编译通过,char与int运算时,char会先转为int 21. 输出'a'的ASCII码与100相加后的结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









