







4-知识图谱的抽取与构建-4_5事件识别和抽取
一、专业知识解析:知识图谱中的事件识别与抽取

1. 核心定义
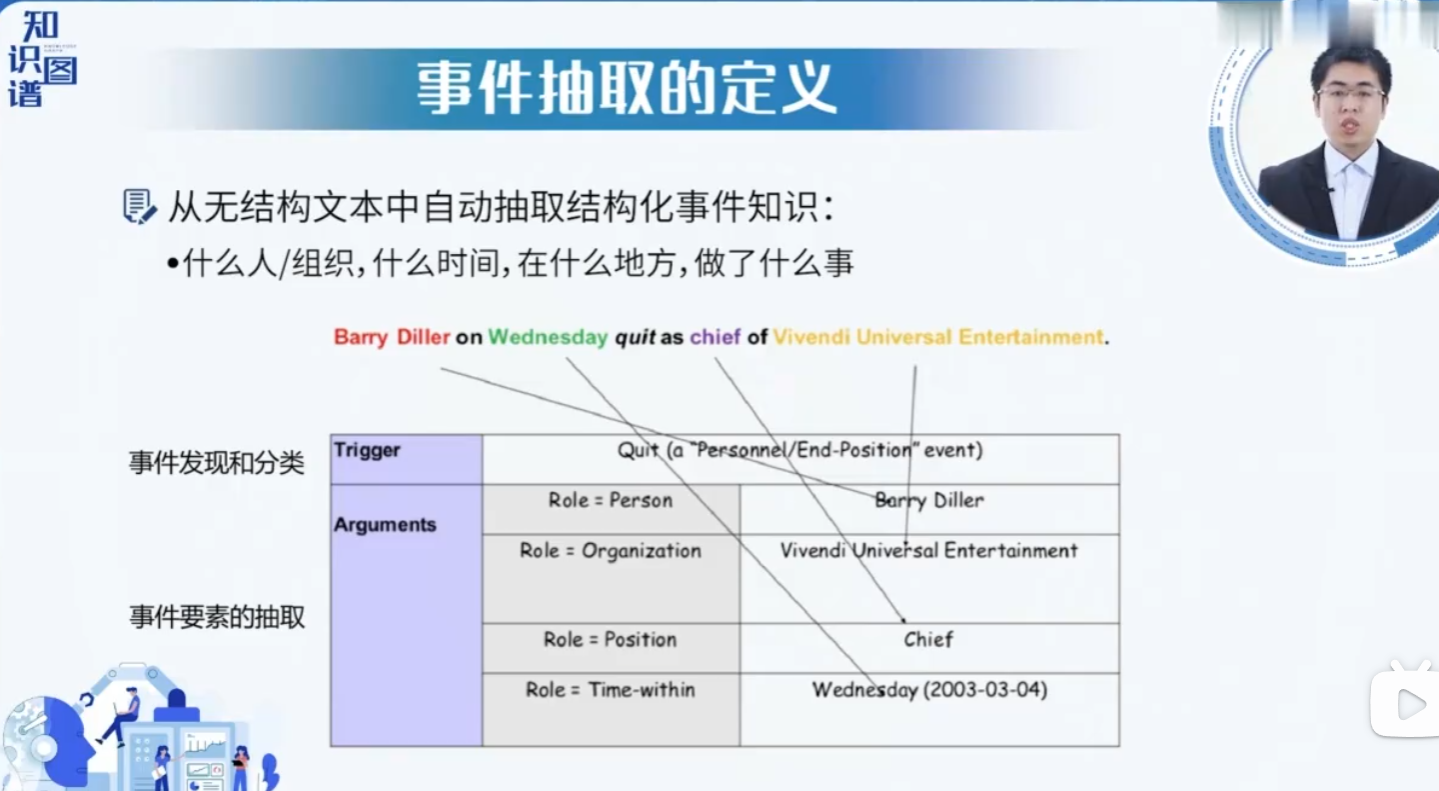
事件识别与抽取(Event Recognition and Extraction)是信息抽取(Information Extraction)的子任务,目标是从非结构化文本中检测事件描述,并结构化表示为:
-
事件类型(Event Type):如"收购"、“地震”、“会议”
-
触发词(Trigger):标识事件发生的核心词(动词/名词)
-

-
论元(Arguments):事件的参与者及属性
-

- 参与者:人物、组织、地点
- 时间:事件发生时间
- 方式:事件的具体方式
2. 技术实现原理
事件模式(Event Schema)示例:
{
"event_type": "企业收购",
"arguments": {
"收购方": {"type": "组织"},
"被收购方": {"type": "组织"},
"金额": {"type": "数值"},
"时间": {"type": "日期"}
}
}
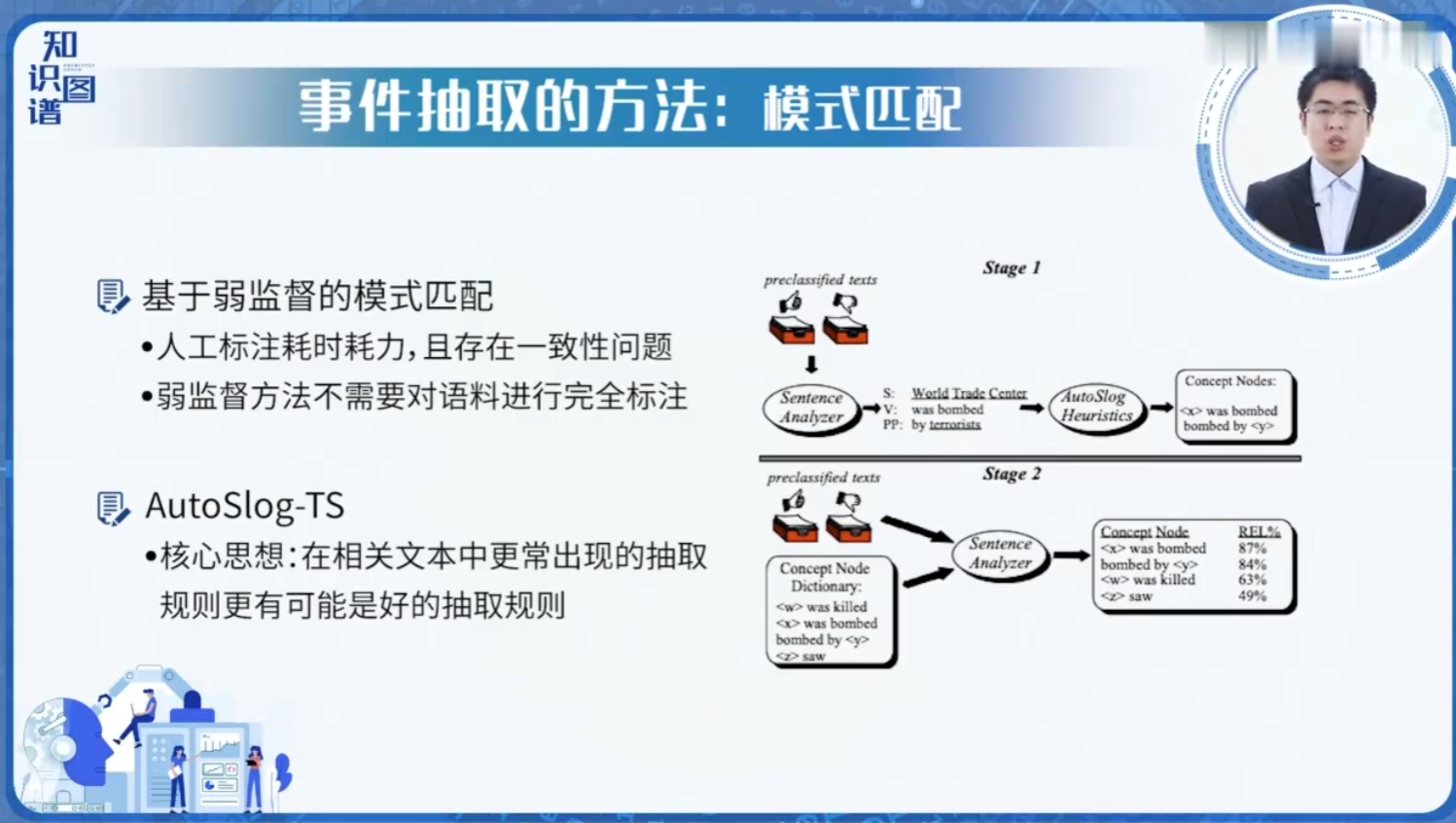
主流方法:

https://www.bilibili.com/video/BV19FrDYgEUc?spm_id_from=333.788.player.switch&vd_source=7f7c364b89e4cadc6910920c946c39e4&p=19

-
规则驱动:基于触发词词典+句法模板
# 伪代码示例 if "收购" in sentence and ("亿" or "美元") in sentence: extract_arguments() -
机器学习:
-

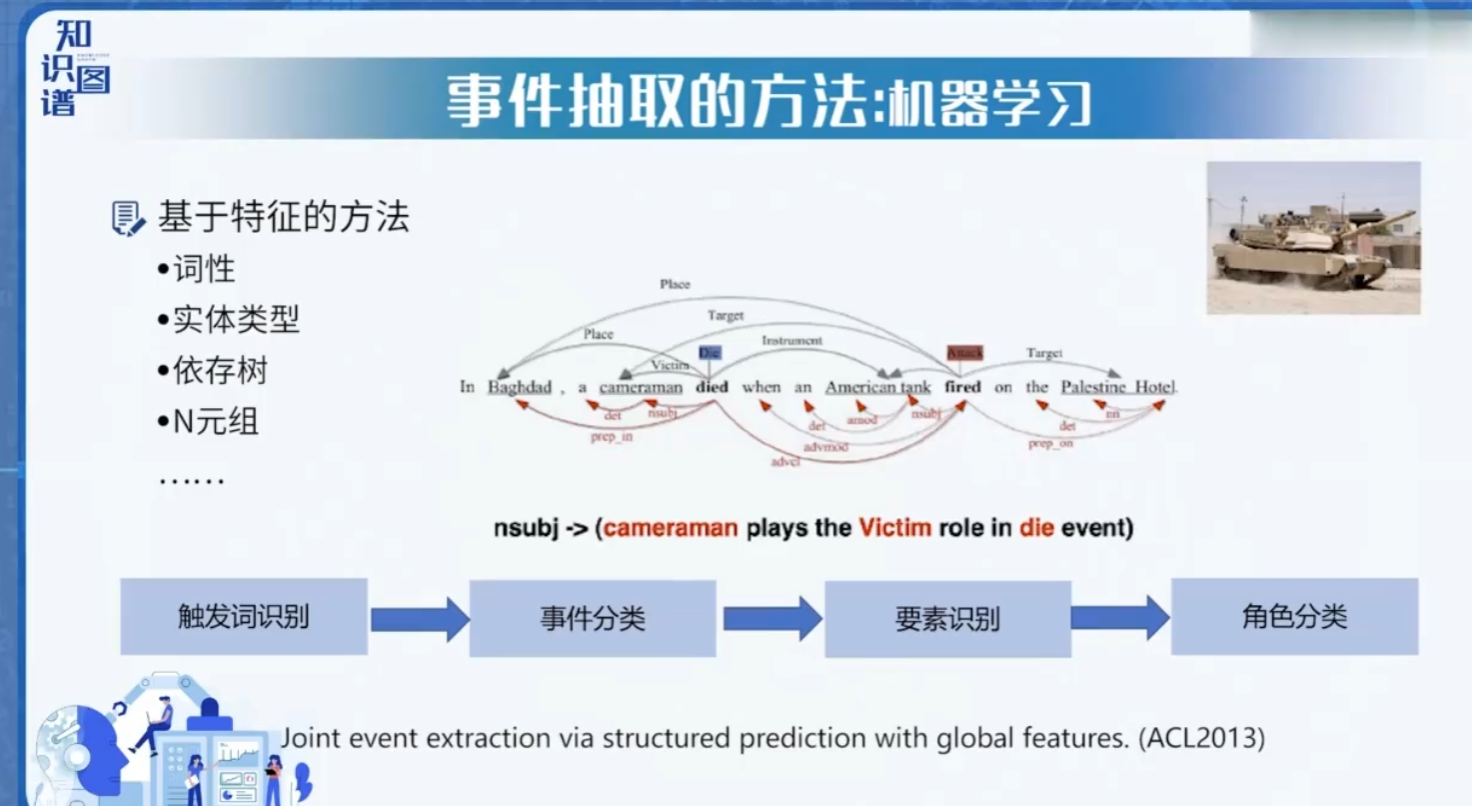
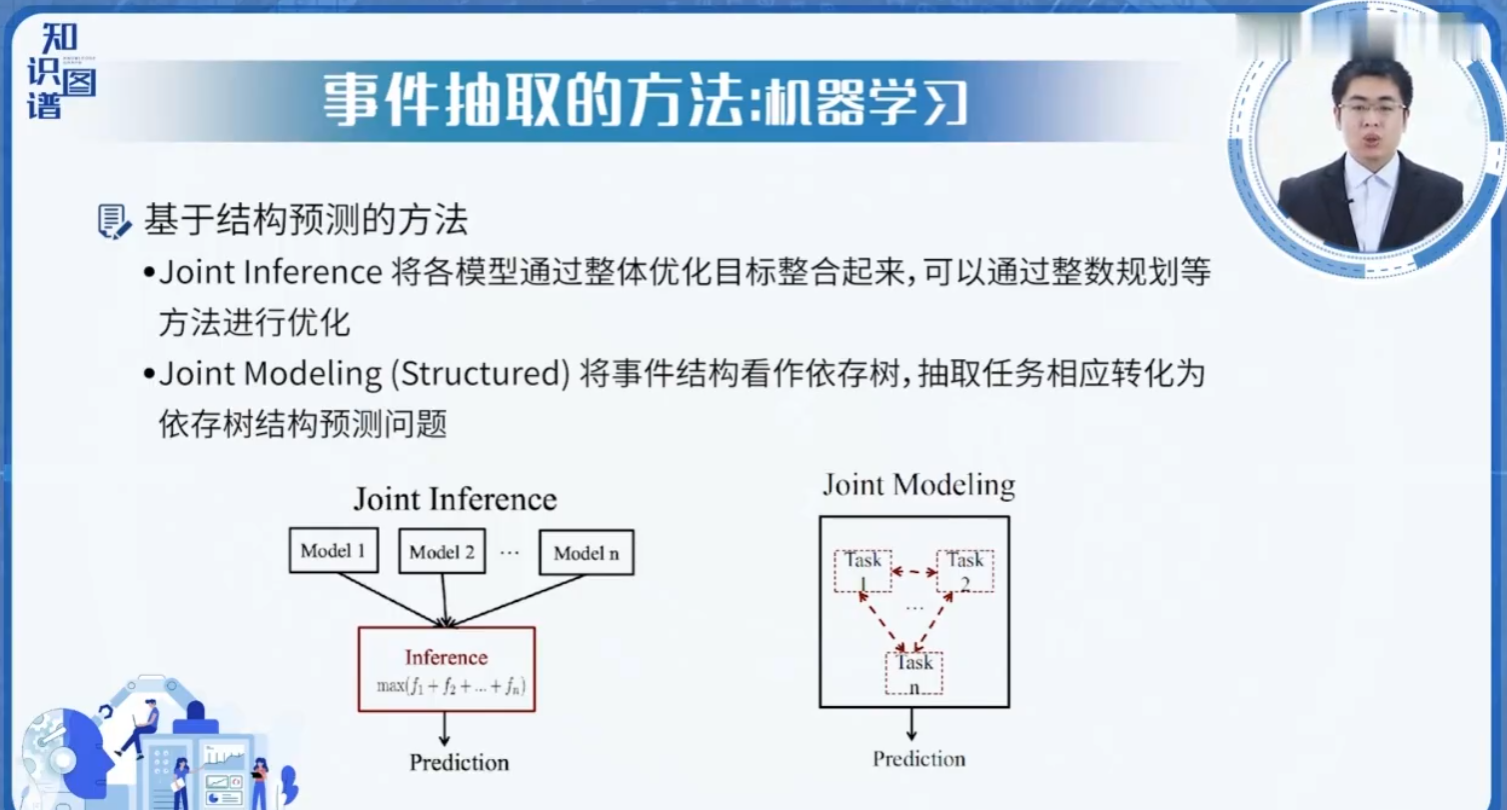
- BiLSTM-CRF:双向LSTM识别触发词和论元
- BERT+Span标注:利用预训练模型捕捉上下文语义
-
混合方法:规则过滤+神经网络分类
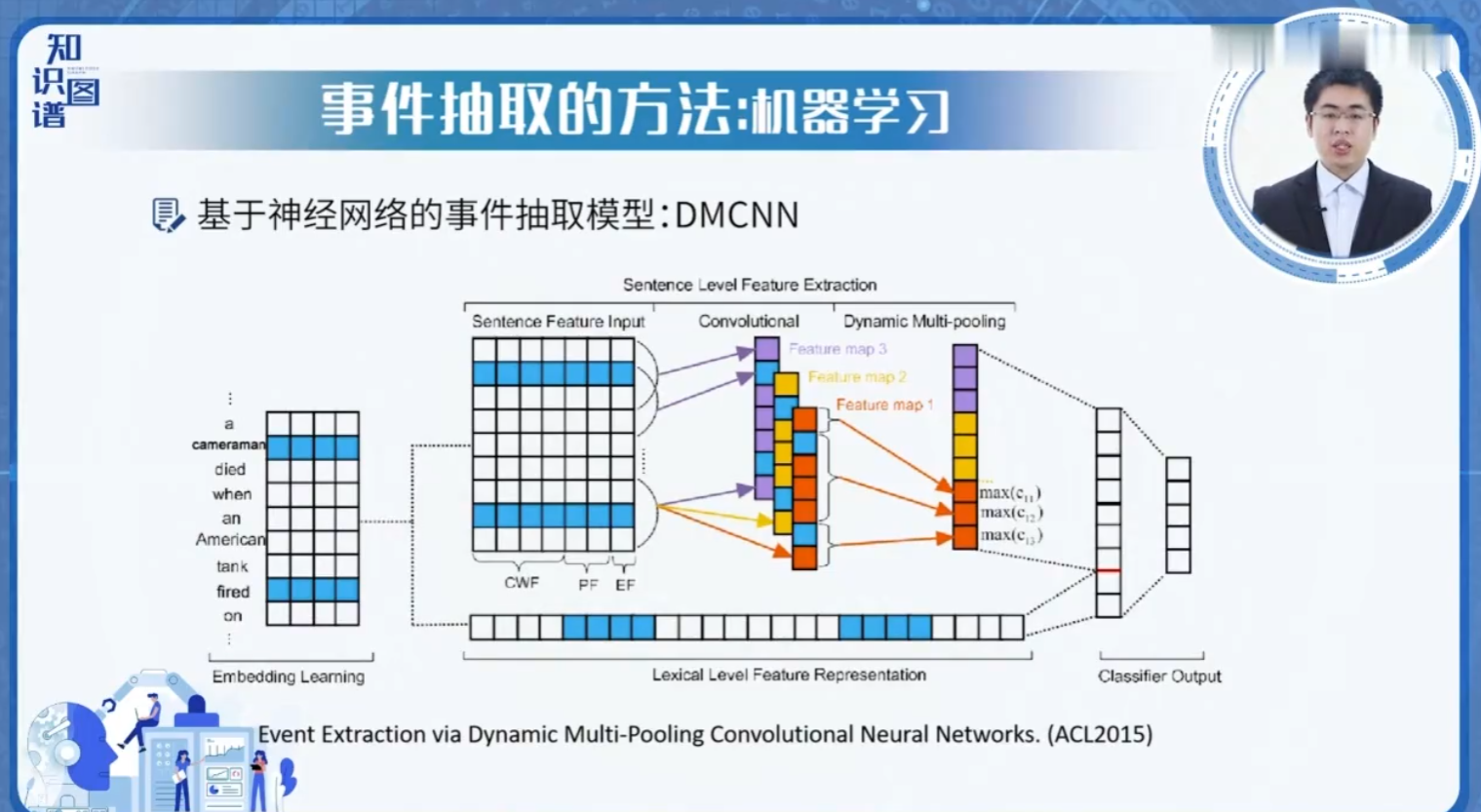
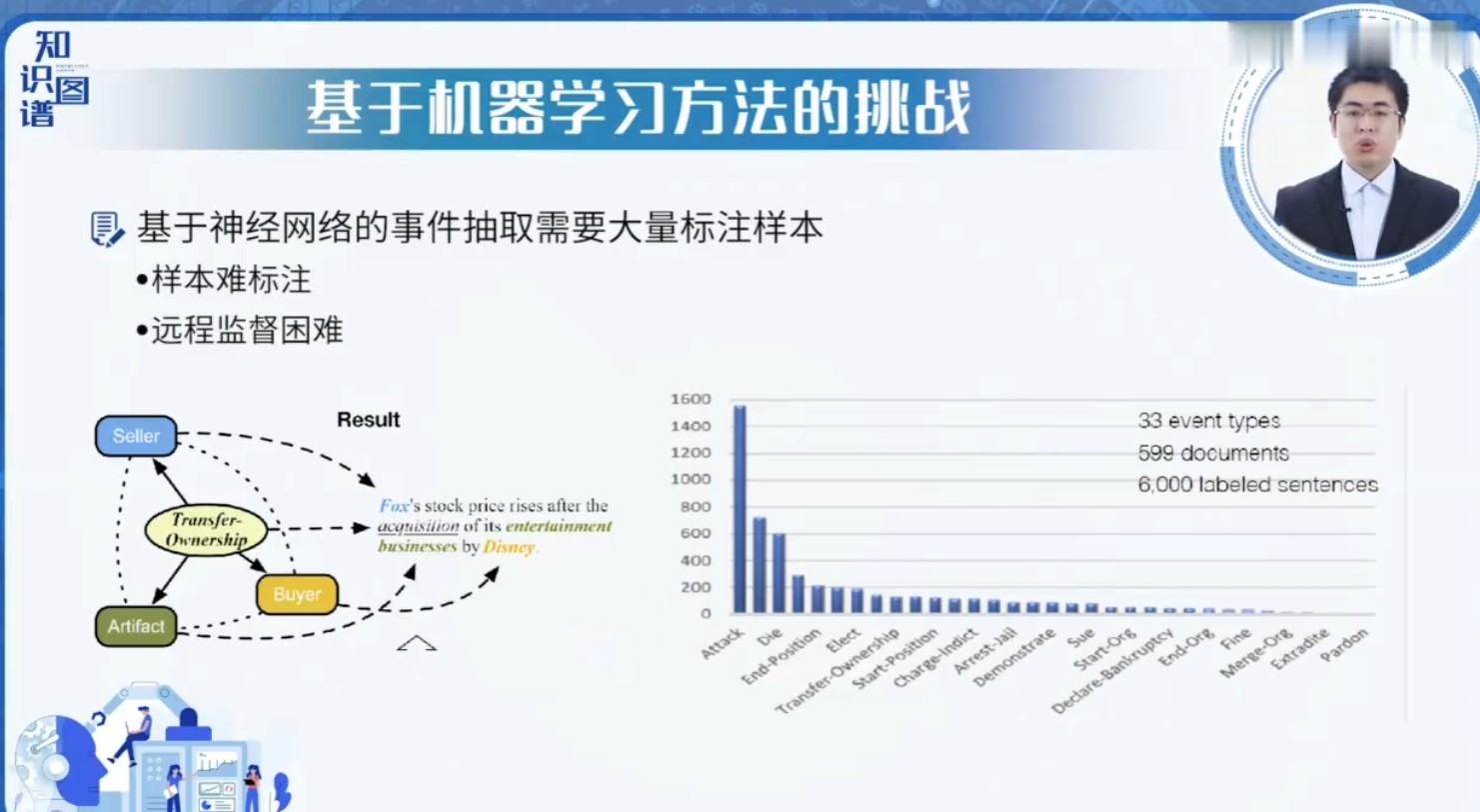
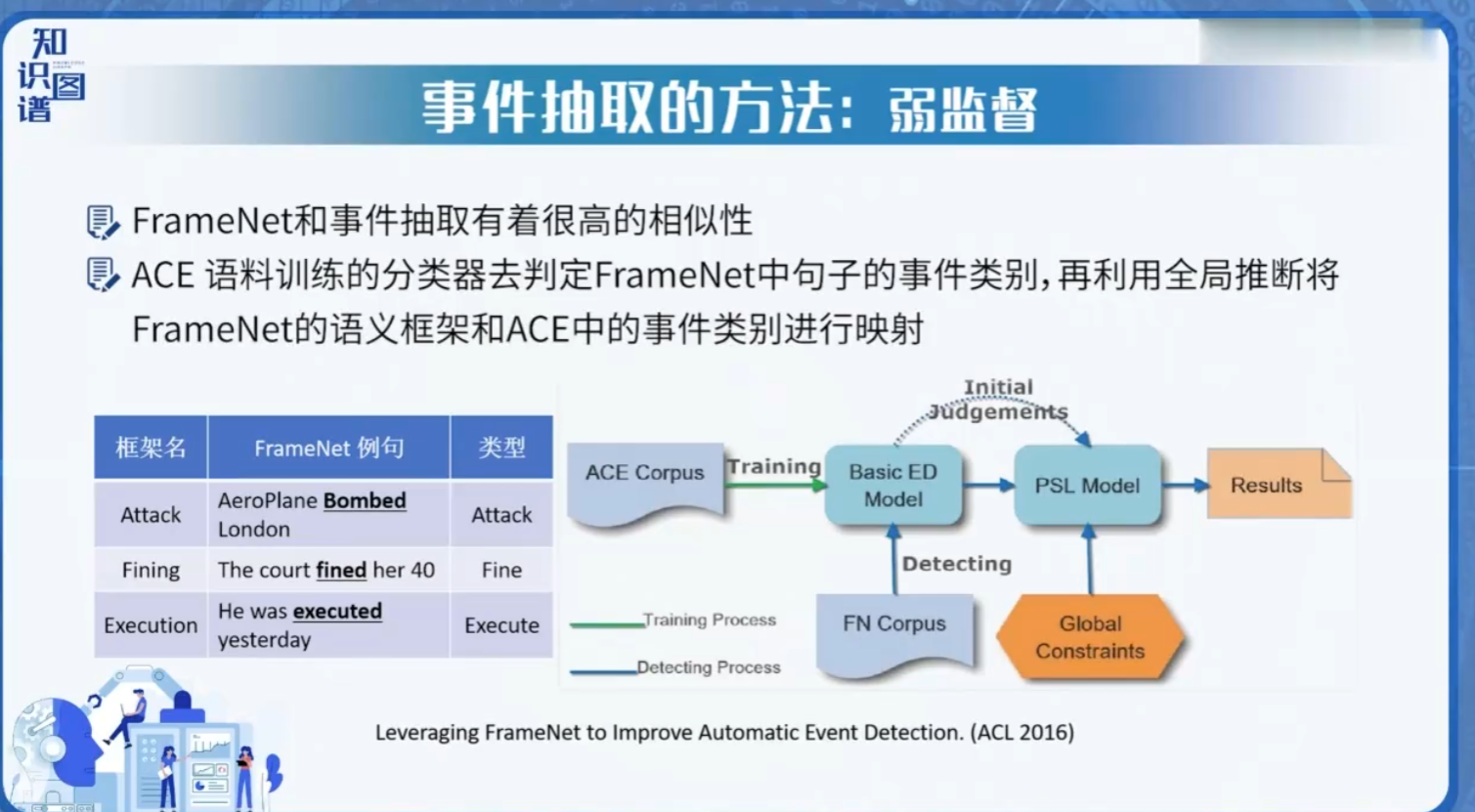


3. 评价指标
- 精确率(Precision):正确抽取的事件占比
- 召回率(Recall):实际存在事件的检出比例
- F1值:精确率和召回率的调和平均
二、通俗易懂的学习指南
学习步骤:
-
理解事件结构:就像分析"谁在什么时间做了什么"
- 例:“苹果公司(收购方)在2023年(时间)以10亿美元(金额)收购了AI初创(被收购方)”
-
识别关键信号:
- 找动作词:收购、发布、签约…
- 抓数字/日期:亿元、美元、2023年1月
-
关联参与角色:
- 公司名、人名、机构名需与动作词建立联系
三、实战案例演示
原始句子:
“特斯拉于北京时间8月5日宣布,将以全现金方式溢价20%收购SolarCity,交易估值达26亿美元”
抽取过程:
- 触发词检测:“收购”
- 类型判断:企业并购事件
- 论元抽取:
- 收购方:特斯拉
- 被收购方:SolarCity
- 时间:北京时间8月5日
- 金额:26亿美元
- 方式:全现金方式溢价20%
结构化输出:
{
"event_type": "企业收购",
"trigger": "收购",
"arguments": {
"收购方": "特斯拉",
"被收购方": "SolarCity",
"时间": "北京时间8月5日",
"金额": "26亿美元",
"方式": "全现金方式溢价20%"
}
}
四、定制化练习任务
初级练习(规则应用):
句子1:阿里巴巴集团昨日通过股权置换完成对饿了么的收购
句子2:马斯克在推特宣布将于2024年Q2发射新型星舰
任务要求:
- 用下划线标出触发词
- 用不同颜色标注:参与者(红色)、时间(蓝色)、数值(绿色)
- 填写事件类型表:
| 句子 | 事件类型 | 触发词 | 参与者1 | 参与者2 | 时间 | 其他参数 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 |
高级练习(模型训练):
- 使用SPO三元组标注工具标注20条新闻句子
- 在Google Colab运行以下代码体验事件抽取:
from paddlenlp import Taskflow
ie = Taskflow("information_extraction", schema=['企业收购'])
print(ie("大众汽车计划以30亿欧元收购电池制造商国轩高科"))
扩展思考:
- 如果遇到"微软可能考虑收购Netflix"这类含推测性词汇的句子,该如何处理?
- 当多个事件同时出现时(如"收购完成后将召开新闻发布会"),如何分离不同事件?
五、学习资源推荐
- 工具实践:试用DeepKE事件抽取模块
- 论文精读:《ACE Event Extraction Tech Report》
- 数据集:ACE2005英文事件数据集(需申请使用权限)
通过完成上述训练,您将掌握从基础规则到深度学习的事件抽取全流程能力。建议先从人工标注10个句子开始,逐步过渡到使用预训练模型优化效果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











