



 本文深入解析了双链表的基本概念及其实现原理,重点介绍了如何通过四种不同情况将新节点插入到双链表中,并提供了详细的插入函数实现代码。
本文深入解析了双链表的基本概念及其实现原理,重点介绍了如何通过四种不同情况将新节点插入到双链表中,并提供了详细的插入函数实现代码。
双链表
单链表单向遍历决定了只能从头节点遍历到尾节点。而双链表解决了这个问题,在一个双链表中,每个节点都包含了两个指针——指向前一个节点和指向后一个节点的指针。这可以使我们以任何方向遍历双链表。
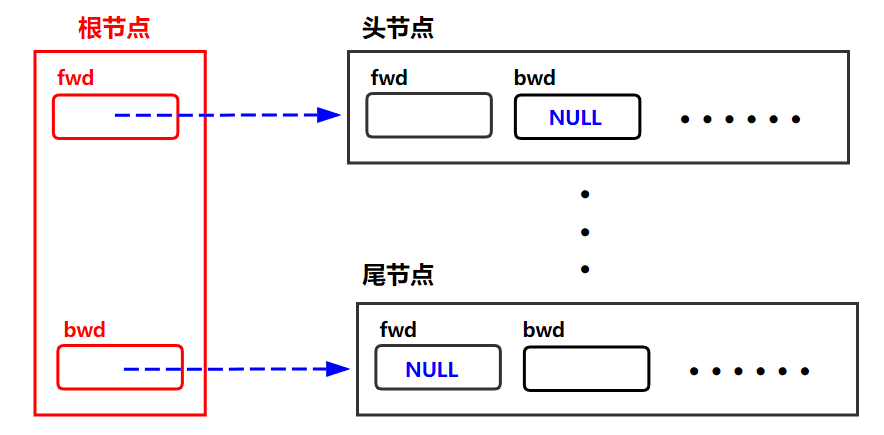
根据双链表的定义,我们应该能从链表的任何一端开始遍历链表,因此需要两个指针分别指向头节点和尾节点。
最直接的想法是把两个根指针分开声明为两个变量。但这样一来,我们必须把两个根指针都传递给操作双链表的函数。
为了更有效率,我们采取另一种方式:为根指针声明一个完整的节点。根节点的正向指针指向链表的第一个节点,反向指针指向链表的最后一个节点,如果链表为空,两个指针都为NULL。另外,我们也可以在根节点的值字段中保存一些关于链表的信息。
定义链表节点
typedef struct node {
struct node * fwd;
struct node * bwd;
int value;
}Node;节点间关系
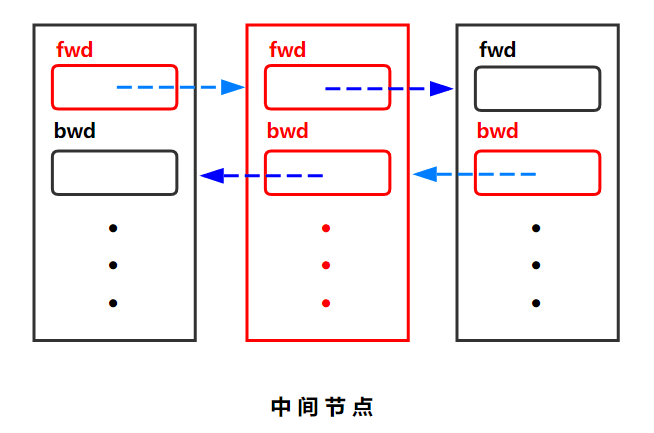
------------------------------------------------------------------------------------
双链表插入函数
通过双链表插入函数学习对双链表的操作,其他操作也可以类比实现。
函数分析
对双链表,我们考虑每个节点。谁正向指向它,谁反向指向它,它正向指向谁,它反向指向谁。
于是,当我们把一个节点插入到链表时,可能出现4 种情况。
(1) 新节点插入到链表的中间位置。
(2) 新节点插入到链表的起始位置。
(3) 新节点插入到链表的结束位置。
(4) 新节点既插入到链表的起始位置,又插入到链表的结束位置。
在每种情况下,都有 4 个指针必须进行修改。我们通过是否插入到起始位置,是否插入到结束位置两个条件划分这4种情况。
函数调用
root = list_insert(root, value);函数实现
Node * insert(Node *rootp, int new_value){
Node *current;
Node *next;
Node *newnode;
for(current = rootp; (next = current->fwd) != NULL; current = next)
{
if (next->value == new_value){
printf("the same value");
return rootp;
}
if (next->value > new_value)
break;
}
newnode = (Node *)malloc( sizeof (Node) );
if (newnode == NULL){
printf("fail to allocate newnode");
return rootp;
}
newnode->value = new_value;
if (next != NULL){
if ( current != rootp){ //插入到中间节点
current->fwd = newnode;
next->bwd = newnode;
newnode->fwd = next;
newnode->bwd = current;
} else { //插入到开始位置,且不是结束位置
rootp->fwd = newnode;
next->bwd = newnode;
newnode->fwd = next;
newnode->bwd = NULL;
}
} else {
if ( current != rootp){ //插入到结束位置,且不是开始位置
current->fwd = newnode;
rootp->bwd = newnode;
newnode->fwd = NULL;
newnode->bwd = current;
} else { //插入到开始位置,且是开始位置
rootp->fwd = newnode;
rootp->bwd = newnode;
newnode->fwd = NULL;
newnode->bwd = NULL;
}
}
return rootp;
} 

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









