







一、LRU原理
当内存不够的时候,先淘汰掉最不常用的。
自己实现LRU的方式考虑:
双向链表+hashmap
链表的实现:
每次新插入数据的时候将新数据插到链表的头部。
每次缓存命中(即数据被访问),则将数据移到链表头部。
当链表满的时候,就将链表尾部的数据丢弃。
hashmap的实现:
使用 HashMap 存储 key,这样可以做到 save 和 get key的时间都是 O(1),而 HashMap 的 Value 指向双向链表实现的 LRU 的 Node 节点
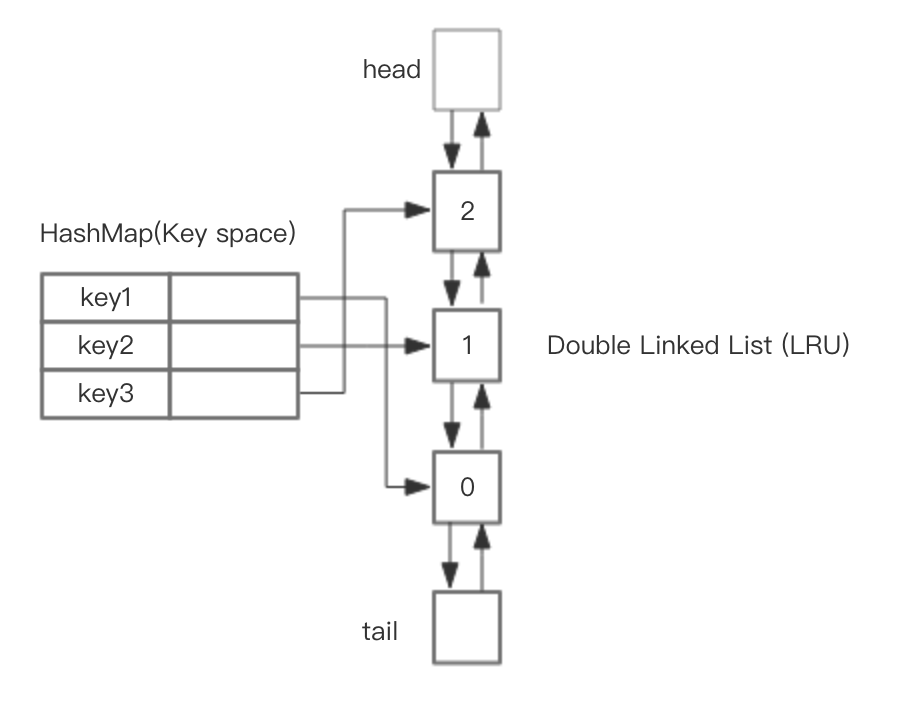
总结一下核心操作的步骤:
- save(key, value),首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队头。如果不存在,需要构造新的节点,并且尝试把节点塞到队头。如果LRU空间不足,则通过 tail 淘汰掉队尾的节点,同时在 HashMap 中移除 Key。
- get(key),通过 HashMap 找到 LRU 链表节点,把节点插入到队头,返回缓存的值。
JAVA代码实现:
package com.sid.test.lru;
public class DLinkedNode {
String key;
int value;
DLinkedNode pre;
DLinkedNode post;
}
package com.sid.test.lru;
import java.util.Hashtable;
public class LRUCache {
private Hashtable<String, DLinkedNode>
cache = new Hashtable<String, DLinkedNode>();
private int count;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.count = 0;
this.capacity = capacity;
head = new DLinkedNode();
head.pre = null;
tail = new DLinkedNode();
tail.post = null;
head.post = tail;
tail.pre = head;
}
public int get(String key) {
DLinkedNode node = cache.get(key);
if(node == null){
return -1; // should raise exception here.
}
// move the accessed node to the head;
this.moveToHead(node);
return node.value;
}
public void set(String key, int value) {
DLinkedNode node = cache.get(key);
if(node == null){
DLinkedNode newNode = new DLinkedNode();
newNode.key = key;
newNode.value = value;
this.cache.put(key, newNode);
this.addNode(newNode);
++count;
if(count > capacity){
// pop the tail
DLinkedNode tail = this.popTail();
this.cache.remove(tail.key);
--count;
}
}else{
// update the value.
node.value = value;
this.moveToHead(node);
}
}
/**
* Always add the new node right after head;
*/
private void addNode(DLinkedNode node){
node.pre = head;
node.post = head.post;
head.post.pre = node;
head.post = node;
}
/**
* Remove an existing node from the linked list.
*/
private void removeNode(DLinkedNode node){
DLinkedNode pre = node.pre;
DLinkedNode post = node.post;
pre.post = post;
post.pre = pre;
}
/**
* Move certain node in between to the head.
*/
private void moveToHead(DLinkedNode node){
this.removeNode(node);
this.addNode(node);
}
// pop the current tail.
private DLinkedNode popTail(){
DLinkedNode res = tail.pre;
this.removeNode(res);
return res;
}
}
二、redis中LRU的实现
如果按照HashMap和双向链表实现,需要额外的存储存放 next 和 prev 指针,牺牲比较大的存储空间,显然是不划算的。
所以Redis采用了一个近似的做法,就是随机取出若干个key,然后按照访问时间排序后,淘汰掉最不经常使用的。
最初redis是随机选三个Key,把idle time最大的那个Key移除。
后来把3改成可配置的一个参数,默认为N=5:maxmemory-samples 5
再后来的版本采用了pool的概念。
Redis3.0之后又改善了算法的性能,会提供一个待淘汰候选key的pool,里面默认有16个key,按照空闲时间排好序。
更新时从Redis键空间随机采样(samping)N个key,分别计算它们的空闲时间idle,key只会在pool不满或者空闲时间大于pool里最小的时,才会进入pool,使得pool里面总是保存着随机选择过的key的idle time最大的那些key。
需要evict key时,直接从pool里面取出idle time最大的key,将之evict掉

















 4358
4358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









