









Python基础总结及数据分析代码记录(三、数据分析工具Pandas)
学习记录
20220603----数据分析工具Pandas
20220605----数据分析工具Pandas
20220605----Pandas统计计算和描述
20220606----Pandas层级索引
20220606----数据分组运算
一、Pandas
(一)Pandas 数据结构(Series)
import pandas as pd
ser_obj = pd.Series(range(10, 20)) # 类似一维数组对象
print(type(ser_obj)) # ser_obj = pd.Series(range(10))通过list构建
print(ser_obj.values) # 获取数据,索引在左,数据在右;索引是自动创建的
print(ser_obj.index) # 获取索引
print(ser_obj.head(3)) # 预览数据
print(ser_obj)
print(ser_obj[0]) # 通过索引获取数据,ser_obj[idx]
print(ser_obj[8])
print(ser_obj * 2) # 索引与数据的对应关系仍保持在数组运算的结果中
print(ser_obj > 15)
year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5} # 通过dict构建Series
ser_obj2 = pd.Series(year_data)
print(ser_obj2.head())
print(ser_obj2.index)
print(ser_obj2.values)
ser_obj2.name = 'temp' # name属性
ser_obj2.index.name = 'year' # ser_obj.name, ser_obj.index.name
print(ser_obj2.head())
(二)Pandas 数据结构(DataFrame)
DataFrame:DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等);DataFrame既有行索引也有列索引,它可以被看做由series组成的字典(共用同一个索引);
ndarray全称The N-dimensional array,是Numpy中的数据结构,是一个多维数组,存储着相同类型和大小的元素的多维数组。数组的维度和每个数组中的元素是由shape来决定的。数组中的元素类型是由dtype决定的;
import numpy as np
import pandas as pd
array = np.random.randn(5,4) # 通过ndarray构建DataFrame
print(array)
df_obj = pd.DataFrame(array)
print(df_obj.head())
dict_data = {'A': 1.,
'B': pd.Timestamp('20161217'),
'C': pd.Series(1, index=list(range(4)),dtype='float32'),
'D': np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["Python","Java","C++","C#"]),
'F' : 'ChinaHadoop' }
# print (dict_data)
df_obj2 = pd.DataFrame(dict_data) # 通过dict构建DataFrame
print(df_obj2.head())
print(df_obj2)
print(df_obj2['C']) # 通过列索引获取列数据
print(type(df_obj2['A']))
print(df_obj2.D)
print(df_obj2)
print(df_obj2['A']) # 通过列索引获取列数据(Series类型)
print(type(df_obj2['A'])) # df_obj[col_idx] 或 df_obj.col_idx
print(df_obj2.A)
df_obj2.A
df_obj2['G'] = df_obj2['D'] + 4 # 增加列数据,类似dict添加key-value
print(df_obj2.head())# df_obj[new_col_idx] = data
del(df_obj2['G'] ) # 删除列,del df_obj[col_idx]
print(df_obj2.head())
Series和DataFrame中的索引都是Index对象;不可变(immutable)
print(type(df_obj2.index)) # Series和DataFrame中的索引都是Index对象
print(df_obj2.index)
# df_obj2.index[0] = 2
(三)Pandas 数据操作(Series索引操作)
import pandas as pd
ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e'])
print(ser_obj.head())
print(ser_obj['a'])# 行索引,ser_obj[‘label’], ser_obj[pos]
print(ser_obj[0])
print(ser_obj.head())
print(ser_obj[1:3]) # 切片索引,ser_obj[2:4], ser_obj[‘label1’: ’label3’],按索引名切片操作时,是包含终止索引的;
print(ser_obj['b':'d'])
print(ser_obj[[0, 2, 4]]) # 不连续索引
print(ser_obj[['a', 'e']])# 不连续索引,ser_obj[[‘label1’, ’label2’, ‘label3’]]
# ser_obj[[pos1, pos2, pos3]]
print(ser_obj)
ser_bool = ser_obj > 2 # 布尔索引
print(ser_bool)
print(ser_obj[ser_bool])
print(ser_obj[ser_obj > 2])
(四)Pandas 数据操作(DataFrame索引操作)
import numpy as np
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'], index = ['A', 'B', 'C', 'D', 'E'])
print(df_obj.head()) # df.columns/df.index
print('列索引') # df_obj[‘label’]
print(df_obj['a']) # 返回Series类型
print(type(df_obj[[0]])) # 返回DataFrame类型
print('不连续索引')# df_obj[[‘label1’, ‘label2']]
print(df_obj[['a','c']])
print(df_obj[[1, 3]])
(五)Pandas 数据操作(.loc和.iloc索引操作)
print(ser_obj)
print(df_obj)
print(ser_obj['b':'e']) # Series标签索引 loc
print(ser_obj.loc['b':'e'])
print(df_obj['a']) # DataFrame标签索引 loc
print(df_obj.loc['B':'E', 'b'])
print(ser_obj[1:3]) # 整型位置索引 iloc
print(ser_obj.iloc[1:3])
print(df_obj.iloc[0:2, 0]) # # DataFrame位置索引 iloc,注意和df_obj.loc[0:2, 'a']的区别
DataFrame索引时可将其看作ndarray操作;标签的切片索引是包含末尾位置的
(六)Pandas 数据操作(运算与对齐)
s1 = pd.Series(range(10, 20), index = range(10))
s2 = pd.Series(range(20, 25), index = range(5))
print('s1: ' )
print(s1)
print('s2: ')
print(s2)
s1 + s2 # Series 对齐运算
import numpy as np
df1 = pd.DataFrame(np.ones((2,2)), columns = ['a', 'b'])
df2 = pd.DataFrame(np.ones((3,3)), columns = ['a', 'b', 'c'])
print('df1: ')
print(df1)
print('')
print('df2: ')
print(df2)
df1 + df2 # DataFrame对齐操作
print(s1)
print(s2)
s1.add(s2, fill_value = -1) # 填充未对齐的数据进行运算
df1.sub(df2, fill_value = 2.)
s3 = s1 + s2 # 填充NaN
print(s3)
s3_filled = s3.fillna(-1)
print(s3_filled)
df3 = df1 + df2
print(df3)
df3.fillna(100, inplace = True) # fill_value指定填充值
print(df3)
(七)Pandas 数据操作(函数应用)
df = pd.DataFrame(np.random.randn(5,4) - 1) # Numpy ufunc 函数
print(df)
print(np.abs(df)) # print(np.abs(df))
df_1 = np.abs(df)
f = lambda x : x.max()
print(df.apply(lambda x : x.max())) # 使用apply应用行或列数据,注意指定轴的方向,默认axis=0
print(df_1.apply(lambda x : x.max())) # 使用apply应用行或列数据
print(df.apply(lambda x : x.max(), axis=1)) # axis =1 指定轴方向;# 默认axis = 0
print(df_1.apply(lambda x : x.max(), axis=1))
f2 = lambda x : '%.2f' % x
print(df.applymap(f2)) # 使用applymap应用到每个数据
(八)Pandas 数据操作(排序)
s4 = pd.Series(range(10, 15), index = np.random.randint(5, size=5))
print(s4)
s5 = s4.sort_index() # 索引排序
print(s5)
df4 = pd.DataFrame(np.random.randn(3, 4),
index=np.random.randint(3, size=3),
columns=np.random.randint(4, size=4))
print(df4)
df4.sort_index(ascending=True)
df4.sort_index(ascending=False)
df4.sort_index(axis=1)
df4.sort_values(by=1) # 按值排序
(九)Pandas 数据操作(处理缺失数据)
df_data = pd.DataFrame([np.random.randn(3), [1., np.nan, np.nan],
[4., np.nan, np.nan], [1., np.nan, 2.]])
df_data.head()
df_data.isnull() # 判断是否存在缺失值,ser_obj.isnull(), df_obj.isnull()
df_data.dropna(axis=1)
df_data.dropna() # dropna,丢弃缺失数据
df_data.fillna(-100.) # fillna 填充缺失数据
二、Pandas统计计算和描述
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
print(df_obj)
df_obj.sum(axis = 1) # axis=1 按行统计
df_obj.sum(axis = 0) # axis=0 按列统计
df_obj.max()
df_obj.min(axis=1)
df_obj.describe()


三、Pandas层级索引
ser_obj = pd.Series(np.random.randn(12),
index=[['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],
[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]])
print(ser_obj)
print(type(ser_obj.index))
print(ser_obj.index)
# 应用于分组操作,透视表生成
print(ser_obj['c']) # 外层选取 ser_obj['outer_label']
print(ser_obj[:, 1]) # 内层选取 ser_obj[:,‘inner_label']
print(ser_obj.swaplevel())
四、Pandas分组与聚合
(一)分组操作(groupby)
import pandas as pd
import numpy as np
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'b'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print(df_obj)
df_obj
# GroupBy对象:对数据集进行分组,然后对每组进行统计分析,pandas能利用groupby进行更加复杂的分组运算;
# GroupBy对象:DataFrameGroupBy,SeriesGroupBy
# GroupBy对象没有进行实际运算,只是包含分组的中间数据
# GroupBy对象进行分组运算/多重分组运算,如mean()
# 分组运算过程:分组运算过程(split->apply->combine)
# 拆分:进行分组的根据;应用:每个分组运行的计算规则;合并:把每个分组的计算结果合并起来
print(type(df_obj.groupby('key1'))) # dataframe根据key1进行分组
print(type(df_obj['data1'].groupby(df_obj['key1']))) # data1列根据key1进行分组
grouped1 = df_obj.groupby('key2') # 分组运算
print(grouped1.max())
print(grouped1.mean())
grouped2 = df_obj['data1'].groupby(df_obj['key1'])
print(grouped2.mean())
print(grouped1.size()) # size() 返回每个分组的元素个数
print(grouped2.size())
df_obj.groupby('key1') # 按列名分组,obj.groupby(‘label')
print(df_obj)
self_def_key = [1, 1, 2, 3, 2, 2, 1, 3] # 按自定义key分组,列表
df_obj.groupby(self_def_key).max()
self_def_key = [1, 1, 2, 2, 2, 1, 1, 1] # obj.groupby(self_def_key),自定义的key可为列表或多层列表
df_obj.groupby(self_def_key).size()
df_obj.groupby(self_def_key).mean()
df_obj.groupby([df_obj['key1'], df_obj['key2']]).size() # 按自定义key分组,多层列表
df_obj.groupby([df_obj['key1'], df_obj['key2']]).max() # 按列名多层分组,obj.groupby([‘label1’, ‘label2’])->多层dataframe
print(df_obj)
grouped2 = df_obj.groupby(['key1', 'key2']) # 按多个列多层分组
print(grouped2.max())
print(grouped2_2.max())
grouped3 = df_obj.groupby(['key2', 'key1']) # 多层分组按key的顺序进行
print(grouped3.mean())
print(grouped3.mean().unstack())
(二)GroupBy对象分组迭代
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'b'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print(df_obj)
grouped6 = df_obj.groupby('key1')
print(grouped6.max())
# GroupBy对象支持迭代操作,每次迭代返回一个元组 (group_name, group_data),可用于分组数据的具体运算
for group_name, group_data in grouped6:
print(group_name)
print(group_data)
list(grouped1) # GroupBy对象转换list
grouped2 = df_obj.groupby(['key1', 'key2']) # 按多个列多层分组
print(grouped2.max())
for group_name, group_data in grouped2: # 多层分组
print(group_name)
print(group_data)
dict(list(grouped1)) # GroupBy对象转换dict
print(df_obj.dtypes) # 按列分组
df_obj.groupby(df_obj.dtypes, axis=1).size() # 按数据类型分组
df_obj.groupby(df_obj.dtypes, axis=1).sum()
(三)其他分组方法
df_obj2 = pd.DataFrame(np.random.randint(1, 10, (5,5)),
columns=['a', 'b', 'c', 'd', 'e'],
index=['A', 'B', 'C', 'D', 'E'])
mapping_dict = {'a':'python', 'b':'python', 'c':'java', 'd':'C', 'e':'java'} # 通过字典分组
print(df_obj2.groupby(mapping_dict, axis=1).size())
print(df_obj2.groupby(mapping_dict, axis=1).count()) # 非NaN的个数
print(df_obj2.groupby(mapping_dict, axis=1).sum())
# 通过函数分组
df_obj3 = pd.DataFrame(np.random.randint(1, 10, (5,5)),
columns=['a', 'b', 'c', 'd', 'e'],
index=['AA', 'BBB', 'CC', 'D', 'EE'])
#df_obj3
def group_key(idx):
"""
idx 为列索引或行索引
"""
#return idx
return len(idx)
df_obj3.groupby(group_key).size()
# 以上自定义函数等价于
#df_obj3.groupby(len).size()
columns = pd.MultiIndex.from_arrays([['Python', 'Java', 'Python', 'Java', 'Python'],
['A', 'A', 'B', 'C', 'B']], names=['language', 'index'])
df_obj4 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=columns) # 通过索引级别分组
df_obj4
df_obj4.groupby(level='language', axis=1).sum() # 根据language进行分组
df_obj4.groupby(level='index', axis=1).sum()
(四)聚合操作(aggregation)
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randint(1,10, 8),
'data2': np.random.randint(1,10, 8)}
df_obj5 = pd.DataFrame(dict_obj)
print(df_obj5)
# 内置的聚合函数,数据产生标量的过程,应用于对分组后数据进行计算
# 内置的聚合函数,sum(), mean(), max(), min(), count(), size(), describe
print(df_obj5.groupby('key1').sum())
print(df_obj5.groupby('key1').max())
print(df_obj5.groupby('key1').min())
print(df_obj5.groupby('key1').mean())
print(df_obj5.groupby('key1').size())
print(df_obj5.groupby('key1').count())
print(df_obj5.groupby('key1').describe())
# 自定义聚合函数,传入agg方法中;grouped.agg(func);func的参数为groupby索引对应的记录
def peak_range(df):
"""
返回数值范围
"""
#print type(df) #参数为索引所对应的记录
return (df.max() - df.min())
print(df_obj5.groupby('key1').agg(peak_range))
print(df_obj5.groupby('key1').agg(lambda df : df.max() - df.min()))
# 同时应用多个聚合函数
print(df_obj5.groupby('key1').agg(['mean', 'std', 'count', peak_range])) # 默认列名为函数名
print(df_obj5.groupby('key1').agg(['mean', 'std', 'count', ('range', peak_range)])) # 通过元组提供新的列名
dict_mapping = {'data1':'mean',
'data2':'sum'}
print(df_obj5.groupby('key1').agg(dict_mapping)) # 每列作用不同的聚合函数
dict_mapping = {'data1':['mean','max'],
'data2':'sum'}
print(df_obj5.groupby('key1').agg(dict_mapping))
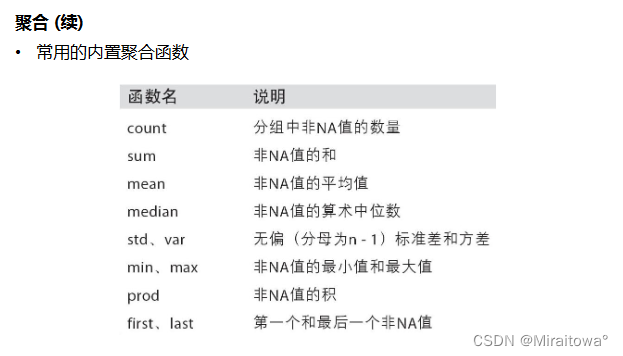
(五)数据分组运算
import pandas as pd
import numpy as np
# 分组运算后保持shape;聚合运算改变了原始数据的shaape,如何保持原始shape不变?
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randint(1, 10, 8),
'data2': np.random.randint(1, 10, 8)}
df_obj = pd.DataFrame(dict_obj)
df_obj
k1_sum = df_obj.groupby('key1').sum().add_prefix('sum_') # 按key1分组后,计算data1,data2的统计信息并附加到原始表格中
pd.merge(df_obj, k1_sum, left_on='key1', right_index=True) # 方法1,使用merge进行外连接
k1_sum_tf = df_obj.groupby('key1').transform(np.sum).add_prefix('sum_') # 方法2,使用transform
# 当transform作用于单列Series时较为简单 ,对salary列进行transform变换我们可以传入任意的非聚合类函数;
k1_sum_tf
# transform作用于整个DataFrame时,实际上就是将传入的所有变换函数作用到每一列中;
df_obj[k1_sum_tf.columns] = k1_sum_tf
df_obj
# transform的计算结果和原始数据的shape保持一致;grouped.transform(np.mean);也可以传入自定义函数;
# grouped.apply(func);func函数在各分组上调用,然后结果通过pd.concat组装到一起;
# 产生层级索引:(1)外层索引是分组名;(2)内层索引是df_obj的行索引;(3)禁止层级索引, group_keys=False;
# apply可以用来处理不同分组内的缺失数据填充;如:填充该分组的均值;
# 自定义函数传入transform
def diff_mean(s):
"""
返回数据与均值的差值
"""
return s - s.mean()
df_obj.groupby('key1').transform(diff_mean)
dataset_path = './starcraft.csv'
df_data = pd.read_csv(dataset_path, usecols=['LeagueIndex', 'Age', 'HoursPerWeek',
'TotalHours', 'APM'])
df_data # 链接:https://pan.baidu.com/s/1YocpemYxEuVWVNB6RrwhnQ 提取码:3aw6
def top_n(df, n=3, column='APM'):
"""
返回每个分组按 column 的 top n 数据
"""
return df.sort_values(by=column, ascending=False)[:n]
df_data.groupby('LeagueIndex').apply(top_n)
df_data.groupby('LeagueIndex').apply(top_n, n=2, column='Age') # apply函数接收的参数会传入自定义的函数中
df_data.groupby('LeagueIndex', group_keys=False).apply(top_n) # 禁止分组 group_keys=False
五、数据清洗、合并、转化、重构
(一)数据清洗
处理缺失数据:pd.fillna(),pd.dropna()
(二)数据连接
import pandas as pd
import numpy as np
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'key': ['a', 'b', 'c'],
'data2' : np.random.randint(0,10,3)})
print(df_obj1)
print('')
print(df_obj2) # pd.merge 根据单个或多个键将不同DataFrame的行连接起来
pd.merge(df_obj1, df_obj2) # 默认将重叠列的列名作为“外键”进行连接
pd.merge(df_obj1, df_obj2, on='key') # on显示指定“外键”
# 更改列名,left_on,right_on分别指定左侧数据和右侧数据的“外键”
df_obj1 = df_obj1.rename(columns={'key':'key1'})
df_obj2 = df_obj2.rename(columns={'key':'key2'})
pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2')
pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2', how='outer') # “外连接”(outer),结果中的键是并集
pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2', how='left') # 左连接
pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2', how='right') # 右连接
# 处理重复列名,suffixes,默认为_x, _y
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data' : np.random.randint(0,10,3)})
pd.merge(df_obj1, df_obj2, on='key', suffixes=('_left', '_right'))
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'data2' : np.random.randint(0,10,3)}, index=['a', 'b', 'd'])
pd.merge(df_obj1, df_obj2, left_on='key', right_index=True) # 按索引连接,left_index=True或right_index=True
(三)数据合并(pd.concat)
1.NumPy的concat
import numpy as np
import pandas as pd
arr1 = np.random.randint(0, 10, (3, 4))
arr2 = np.random.randint(0, 10, (3, 4))
print(arr1)
print(arr2)
print(np.concatenate([arr1, arr2]))
print('')# NumPy的concat,沿轴方向将多个对象合并到一起;默认axis = 0
print(np.concatenate([arr1, arr2], axis=1))
2.Series上的concat
# index 没有重复的情况
ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(0,5))
ser_obj2 = pd.Series(np.random.randint(0, 10, 4), index=range(5,9))
ser_obj3 = pd.Series(np.random.randint(0, 10, 3), index=range(9,12))
print(ser_obj1)
print(ser_obj2)
print(ser_obj3)
# pd.concat([ser_obj1, ser_obj2, ser_obj3])
# pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1)
# index 有重复的情况
ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(5))
ser_obj2 = pd.Series(np.random.randint(0, 10, 4), index=range(4))
ser_obj3 = pd.Series(np.random.randint(0, 10, 3), index=range(3))
print(ser_obj1)
print(ser_obj2)
print(ser_obj3)
pd.concat([ser_obj1, ser_obj2, ser_obj3])
pd.concat([ser_obj1, ser_obj2, ser_obj3], axis = 1)
pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1, join='inner') # join指定合并方式,默认为outer
3.DataFrame上的concat
df_obj1 = pd.DataFrame(np.random.randint(0, 10, (3, 2)), index=['a', 'b', 'c'],
columns=['A', 'B'])
df_obj2 = pd.DataFrame(np.random.randint(0, 10, (2, 2)), index=['a', 'b'],
columns=['C', 'D'])
print(df_obj1)
print(df_obj2)
pd.concat([df_obj1, df_obj2]) # DataFrame合并时同时查看行索引和列索引
pd.concat([df_obj1, df_obj2], axis=1)
(四)数据重构(stack/unstack)
df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])
df_obj
stacked = df_obj.stack() # 将列索引旋转为行索引,完成层级索引
# print(stacked)
stacked
print(type(stacked))
print(type(stacked.index))
stacked.unstack() # 默认操作内层索引;Series->DataFrame
stacked.unstack(level=0) # 通过level指定操作索引的级别
stacked.unstack(level= -1) # 默认操作内层索引,即level=-1
(五)数据转换
1.处理重复数据
df_obj = pd.DataFrame({'data1' : ['a'] * 4 + ['b'] * 4,
'data2' : np.random.randint(0, 4, 8),
'data3' : np.random.randint(0, 4, 8),
})
df_obj
df_obj.duplicated() # duplicated() 返回布尔型Series表示每行是否为重复行
df_obj.drop_duplicates() # drop_duplicates() 过滤重复行;默认判断全部列;可指定按某些列判断
df_obj.drop_duplicates('data2')
2.map(Series根据map传入的函数对每行或每列进行转换)
ser_obj = pd.Series(np.random.randint(0,10,10))
ser_obj
ser_obj.map(lambda x : x * 2)
3.数据替换(replace)
ser_obj.replace(6, -100) # 替换单个值
ser_obj.replace([0, 2], -100) # 替换多个值
ser_obj.replace([0, 2], -100) # 替换多个值
ser_obj.replace([0, 2], [-100, -200]) # 替换多个值
20220605–数据分析工具Pandas
20220605–Pandas统计计算和描述
20220606----Pandas统计计算和描述
20220607----Pandas统计计算和描述
2022年6月7日
青海·西宁




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











