




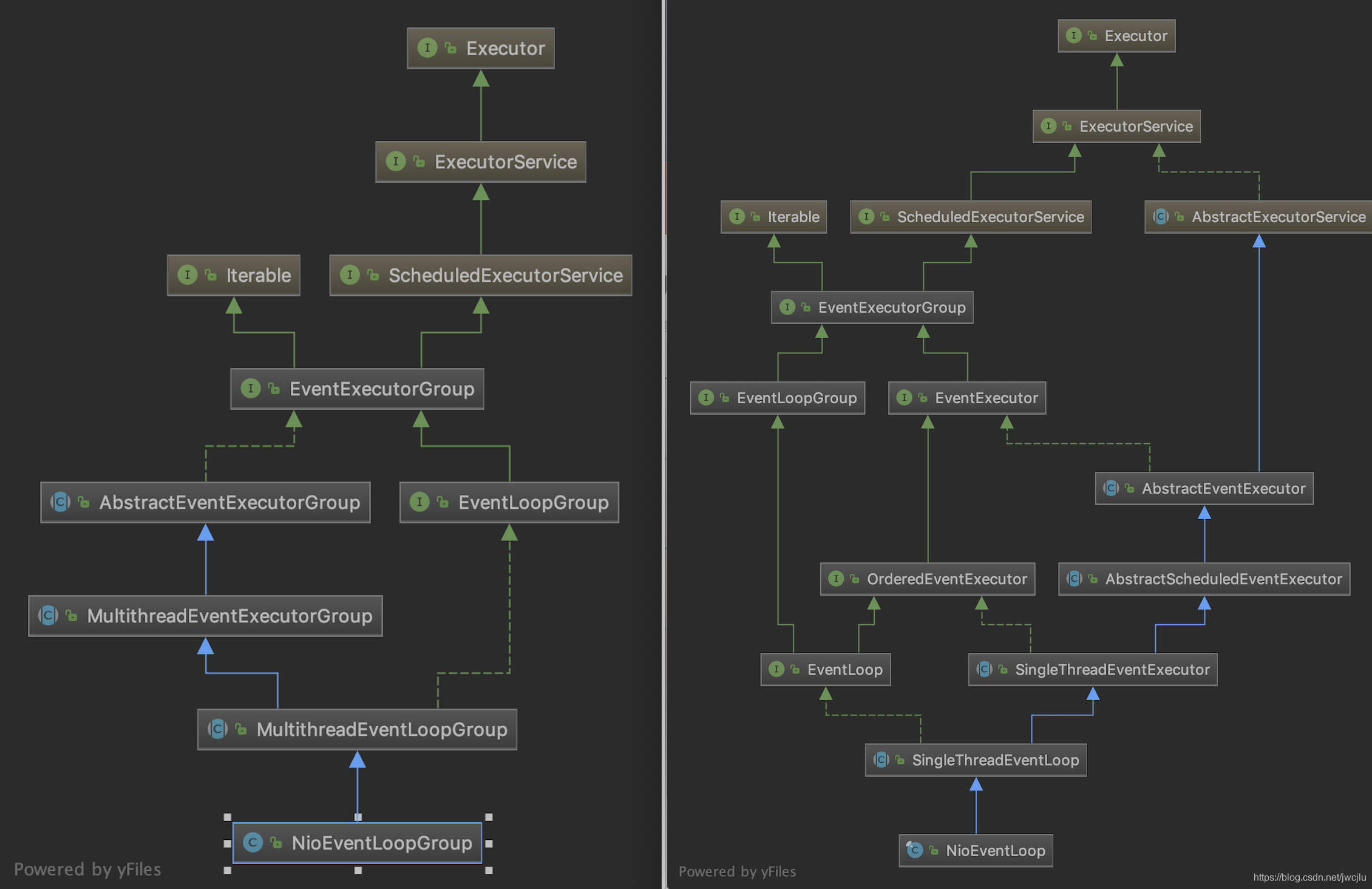
MultithreadEventExecutorGroup里面是EventExecutor的数组,该类的构造器最数组进行初始化,初始化过程交给newChild抽象方法
该抽象方法是由具体实现,下面是NioEventLoopGroup的具体实现如下
@Override
protected EventLoop newChild(Executor executor, Object... args) throws Exception {
return new NioEventLoop(this, executor, (SelectorProvider) args[0],
((SelectStrategyFactory) args[1]).newSelectStrategy(), (RejectedExecutionHandler) args[2]);
}
NioEventLoopGroup其实就是一组NioEventLoop的管理,具体执行执行任务时都是调用相应的某个EventExecutor实现类来执行
那这里到底选择哪个EventExecutor来执行呢?原来MultithreadEventExecutorGroup有个选择器chooser,netty支持选择器如下
/**
* Default implementation which uses simple round-robin to choose next {@link EventExecutor}.
*默认的实现是是简单的轮询选择器
*/
@UnstableApi
public final class DefaultEventExecutorChooserFactory implements EventExecutorChooserFactory {
public static final DefaultEventExecutorChooserFactory INSTANCE = new DefaultEventExecutorChooserFactory();
private DefaultEventExecutorChooserFactory() { }
@SuppressWarnings("unchecked")
@Override
public EventExecutorChooser newChooser(EventExecutor[] executors) {
if (isPowerOfTwo(executors.length)) {
return new PowerOfTwoEventExecutorChooser(executors);
} else {
return new GenericEventExecutorChooser(executors);
}
}
private static boolean isPowerOfTwo(int val) {
return (val & -val) == val;
}
private static final class PowerOfTwoEventExecutorChooser implements EventExecutorChooser {
private final AtomicInteger idx = new AtomicInteger();
private final EventExecutor[] executors;
PowerOfTwoEventExecutorChooser(EventExecutor[] executors) {
this.executors = executors;
}
@Override
public EventExecutor next() {
return executors[idx.getAndIncrement() & executors.length - 1];
}
}
private static final class GenericEventExecutorChooser implements EventExecutorChooser {
private final AtomicInteger idx = new AtomicInteger();
private final EventExecutor[] executors;
GenericEventExecutorChooser(EventExecutor[] executors) {
this.executors = executors;
}
@Override
public EventExecutor next() {
return executors[Math.abs(idx.getAndIncrement() % executors.length)];
}
}
}
该类是EventExecutorChooser的工厂类,根据数组大小,当数量是2的n次方的时候,用PowerOfTwoEventExecutorChooser,其他用GenericEventExecutorChooser。二个都是简单轮询的方式,只是当数量是2的n次方的时候可以用&的方式比取模的时候性能高而已。

















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









