 NLP实践:LTP与NetworkX实现依存句法分析可视化
NLP实践:LTP与NetworkX实现依存句法分析可视化




 该博客介绍了如何使用LTP库进行依存句法分析,并结合NetworkX进行可视化展示。首先,通过jieba进行分词,然后使用LTP进行词性标注和依存句法分析。接着,利用NetworkX创建无向图并绘制句法分析结果。文章还展示了如何处理可能出现的错误,如networkx的迭代问题。
该博客介绍了如何使用LTP库进行依存句法分析,并结合NetworkX进行可视化展示。首先,通过jieba进行分词,然后使用LTP进行词性标注和依存句法分析。接着,利用NetworkX创建无向图并绘制句法分析结果。文章还展示了如何处理可能出现的错误,如networkx的迭代问题。
修改自博客
 https://blog.youkuaiyun.com/jclian91/article/details/97695387
https://blog.youkuaiyun.com/jclian91/article/details/97695387from ltp import LTP
ltp = LTP()
# seg, hidden = ltp.seg(['熊高雄你吃饭了吗'])
# pos = ltp.pos(hidden)
# ner = ltp.ner(hidden)
# srl = ltp.srl(hidden)
# dep = ltp.dep(hidden)
# sdp = ltp.sdp(hidden)
#
# print(seg[0])
# print(pos)
# print(sdp)
# print(dep)
# -*- coding: utf-8 -*-
import os
import jieba
# sent = '2018年7月26日,华为创始人任正非向5G极化码(Polar码)之父埃尔达尔教授举行颁奖仪式,表彰其对于通信领域做出的贡献。'
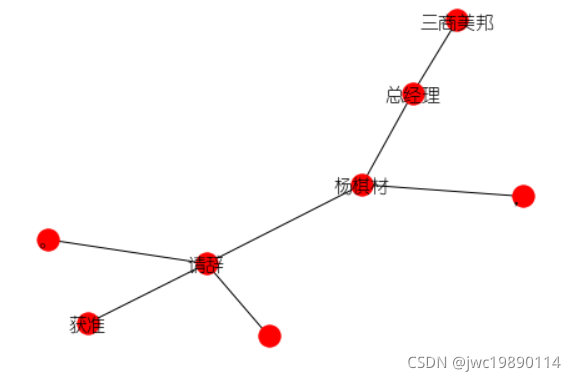
sent='三商美邦总经理杨棋材,请辞获准。'
jieba.add_word('Polar码')
jieba.add_word('5G极化码')
jieba.add_word('埃尔达尔')
jieba.add_word('之父')
words = list(jieba.cut(sent))
print(words)
seg, hidden = ltp.seg([sent])
print(seg[0])
# print(hidden)
# 词性标注
# pos_model_path = os.path.join(os.path.dirname(__file__), 'data/pos.model')
# postagger = Postagger()
# postagger.load(pos_model_path)
# postags = postagger.postag(words)
postags = ltp.pos(hidden)
ner = ltp.ner(hidden)
dep = ltp.dep(hidden)
rely_id = []
relation = []
for i in range(len(seg[0])):
# print(type(seg[0]),type(postags[0]))
print(seg[0][i], dep[0][i])
rely_id.append(dep[0][i][1])
relation.append(dep[0][i][2])
heads = ['Root' if id == 0 else seg[0][id - 1] for id in rely_id]
print(heads)
# 依存句法分析,ltp4改用 ltp.dep(hidden)
# 生成的数据是元组形式,使用列表读取
# arcs = parser.parse(words, postags)
# rely_id = [arc.head for arc in arcs] # 提取依存父节点id
# relation = [arc.relation for arc in arcs] # 提取依存关系
# heads = ['Root' if id == 0 else words[id-1] for id in rely_id] # 匹配依存父节点词语
#
# for i in range(len(words)):
# print(relation[i] + '(' + words[i] + ', ' + heads[i] + ')')
for i in range(len(seg[0])):
print(relation[i] + '(' + seg[0][i] + ', ' + heads[i] + ')')这里使用LTP4替换了之前的pyltp,输出依存信息
# 利用networkx绘制句法分析结果
import networkx as nx
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 指定默认字体
G = nx.Graph() # 建立无向图G
# 添加节点
for word in seg[0]:
G.add_node(word,desc=word)
G.add_node('Root')
# 添加边
for i in range(len(seg[0])):
G.add_edge(seg[0][i], heads[i])
pos = nx.spring_layout(G)
nx.draw(G, pos)
node_labels = nx.get_node_attributes(G, 'desc')
nx.draw_networkx_labels(G, pos, labels=node_labels,font_size=15, font_family ='YouYuan')
plt.savefig("undirected_graph.png")这里输出可视化,使用networkx可能会出现hook无法iterable的报错,需要将matplotlab降级到2.1.1。

















 8637
8637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









