






原文链接:http://www.juzicode.com/archives/1750
在看Python标准库文件或他人写的Python模块时,经常看到py文件最后有这样一段代码:
if __name__=='__main__':
'do something'从代码字面含义理解,如果__name__变量等于’__main__’就执行某些动作。__name__变量在这里又是什么含义呢?
1、__name__是什么
我们知道Python脚本执行时,解释器会从文件开始逐行往后解析,如果遇到用def定义的函数或class定义的类,就会跳过该段代码,如果是顶格写的某些语句就会执行它,即使这个py文件是作为模块被导入到其他文件中。下面我们看个例子来验证下,这里定义了2个py文件,一个是module1.py,这个是被调用的模块,在这个文件里首先打印module1文件开始,接着定义一个函数func1和一个类class1,在最后又用print打印module1文件结束。
'''
author: juzicode
address: www.juzicode.com
公众号: 桔子code/juzicode
date: 2020.11.10
description: 这个是模块文件
'''
print('\n公众号:桔子code, 我在module1的开始,')
def func1():
print('我在func1里面')
class class1:
def __init__(self):
a = 1
def prt(self):
print('我在class1里面')
print('juzicode.com, 我在module1的结尾')再定义一个call1.py文件,在这个文件里导入module1,也加入2个print语句:
'''
author: juzicode
address: www.juzicode.com
公众号: 桔子code/juzicode
date: 2020.11.10
description: 这个是顶层文件
'''
import module1
print('\n公众号:桔子code, 我在call1的开始,')
print('juzicode.com, 我在call1的结束')分别运行 python module1.py 和 python call1.py:
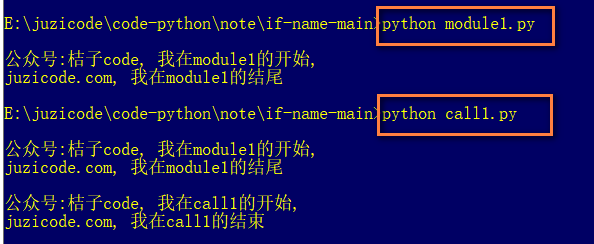
从运行结果看正好验证了前面的说法,module1.py文件里的2个print语句都被执行了,定义的函数func1和class1没有执行到。
回到module1.py文件中,我们在最后加上if __name__==’__main__’语句段,在语句段里打印一些内容:
'''
author: juzicode
address: www.juzicode.com
公众号: 桔子code/juzicode
date: 2020.11.10
description: 这个是模块文件
'''
print('\n公众号:桔子code, 我在module1的开始,')
def func1():
print('我在func1里面')
class class1:
def __init__(self):
a = 1
def prt(self):
print('我在class1里面')
print('juzicode.com, 我在module1的结尾')
if __name__=='__main__':
print('juzicode.com, 我在module1的if-name-main语句中') ####增加的print语句当再次运行python module1.py和python call1.py:
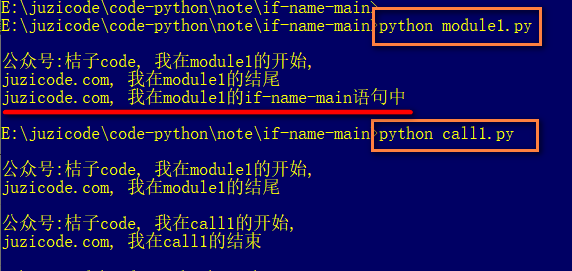
如果直接运行 python module1.py ,module1.py的 if name==’main’ 语句里的print语句得到执行,但是当作为模块导入到call1.py中,运行python call1.py时,print语句没有得到执行,这说明if __name__==’__main__’语句在py文件作为“主程序”时就能执行到,但是作为模块被导入时就不能执行到,到这里我们大概明白该语句的作用了。
if __name__==’__main__’ 语句其实可用作模块的测试代码,在编码、调试模块时,可以直接在文件中编写测试用例,但是到了发布模块时,我们并不希望测试代码被执行,所以该语句就能起到很好的“隔离”效果。
行文至此,你是不是也和我一样有些疑问,作为模块时__name__到底是个什么东东?这个时候我们还是请出最简单高效的调试方法:print(),要知道在Python中print()是可以打印一切的。继续改造module1.py,在文件开头写上这么一句:
print('__name__:',__name__)这时再次运行 python module1.py 和 python call1.py:
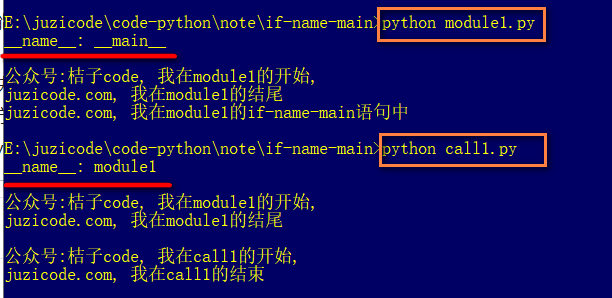
可以看到当作为模块被其他文件导入时,打印的内容是本模块名称’module1’。至此已经很明了了,__name__变量反应的py文件到底是作为模块还是主文件(‘__main__’)被运行的。
2、除了__name__还有什么
这时你是不是会好奇,有__name__这个变量,是不是还会有其他变量,从该变量的定义方式来看,最前面有2个下划线,我们知道在类的定义里2个下划线开始的变量一般是内部变量,我们可以推测 __name__ 应该是某种内部变量。
这里介绍一个强大的函数:dir(),如果用在模块上可以返回模块的所有属性,对于一个未知对象,我们可以用dir()一窥对象的概貌。
言归正传,我们在module1.py里面加入一行 print(dir()) 看看会得到什么,运行python module1.py:
dir(): ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']好家伙,果然有好多变量,本来想着用print()把这些变量一个个打印出来,敲了几个好累,加上桔子菌也实在太懒了,想到了另外一个好助手globals(),可以返回模块内的全局变量字典。
在module1.py文件加入:
print('globals():',globals())然后运行python module1.py:
globals(): {'__name__': '__main__', '__doc__': '\nauthor: juzicode\naddress: www.juzicode.com\n公众号: 桔子code/juzicode\ndate: 2020.11.10\ndescription: 这个是模块文 件\n', '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00000164989D75E0>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'module1.py', '__cached__': None}从打印内容可以看出__name__的内容是 ‘main‘,和前面看到的现象是一样的。
__doc__存储的是py文件中排除#注释内容的第一个字符串。
__file__变量存储的是当前文件的名称: module1.py,因为我们用的是python module1.py执行的,所以只包含了本文件名称。当module1.py作为模块被其他文件导入时得到的是该文件的完整路径,比如我们执行python call1.py时,得到’__file__’的值为’E:\juzicode\code-python\note\if-name-main\module1.py’ 。
3、__file__的另类用法
我们来看个例子,mod1.py和mod2.py 2个模块中都包含一个函数对数据进行类型转换,转换错误会捕获异常并打印提示信息,call_mode.py导入这2个模块:
=====mod1.py
def func1(val):
try:
int(val)
except:
print('值转换出错')
======mod2.py
def func2(val):
try:
int(val)
except:
print('值转换出错')
=====call_mod.py
from mod1 import *
from mod2 import *
print('公众号: 桔子code')
func1('A')
func2('B')运行python call_mod.py:
E:\juzicode\code-python\note\if-name-main>python call_mod.py
公众号: 桔子code
值转换出错
值转换出错是的,都出错了,虽然从顺序上看第一行是mod1.py文件的出错打印,第2行是mod2.py文件的出错打印,在这个例子中出错信息还比较少,一眼就能分辨清是哪里错,当源文件达到几十甚至几百个数量级的时候,还能分辨得清么?当然我们也可以在打印出错信息的地方手动输入当前模块名称,这样也能分辨出来:
=====mod1.py
def func1(val):
try:
int(val)
except:
print('mod1:值转换出错')
======mod2.py
def func2(val):
try:
int(val)
except:
print('mod2:值转换出错')运行看看效果:
E:\juzicode\code-python\note\if-name-main>python call_mod.py
公众号: 桔子code
mod1:值转换出错
mod2:值转换出错嗯,不错,确实能分辨出错误是哪个模块的了。桔子菌嘴角露出了微笑,但是转念一想,如果有几十、几百个文件要找出提示错误的位置,并且都按照这种方式改一遍,哪里还笑的出来。

对于桔子菌这种懒人,岂能容忍这样?这不是有__file__变量么,我们这样改造下 ,就不用去一个一个核对文件名称了 :
print(__file__,'值转换出错')运行之:
E:\juzicode\code-python\note\if-name-main>python call_mod.py
公众号: 桔子code
E:\juzicode\code-python\note\if-name-main\mod1.py:值转换出错
E:\juzicode\code-python\note\if-name-main\mod2.py:值转换出错现在代码一样,打印的内容却能区分出来是谁的错误,够“优雅”了吧!
好了好了,一个 __name__ 变量能扯这么远 ,今天就先聊到这,洗洗睡吧。
推荐阅读:
关注微信公众“桔子code”,不错过更冷的Python知识。


















 4222
4222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









