









DenseNet学习笔记
写的比较完整的一个链接
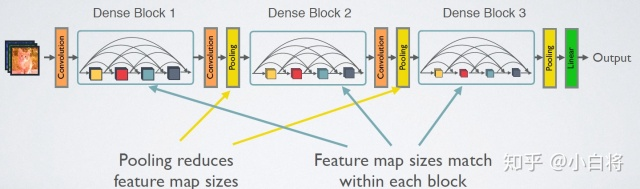
近几年来,Highway和ResNet结构中均提出了一种数据旁路(skip-layer)的技术来使得信号可以在输入层和输出层之间高速流通,核心思想都是创建了一个跨层连接来连通网路中前后层。在本文中,作者基于这个核心理念设计了一种全新的连接模式。为了最大化网络中所有层之间的信息流,作者将网络中的所有层两两都进行了连接,使得网络中每一层都接受它前面所有层的特征作为输入。由于网络中存在着大量密集的连接,作者将这种网络结构称为DenseNet。其结构示意图如下左图所示:
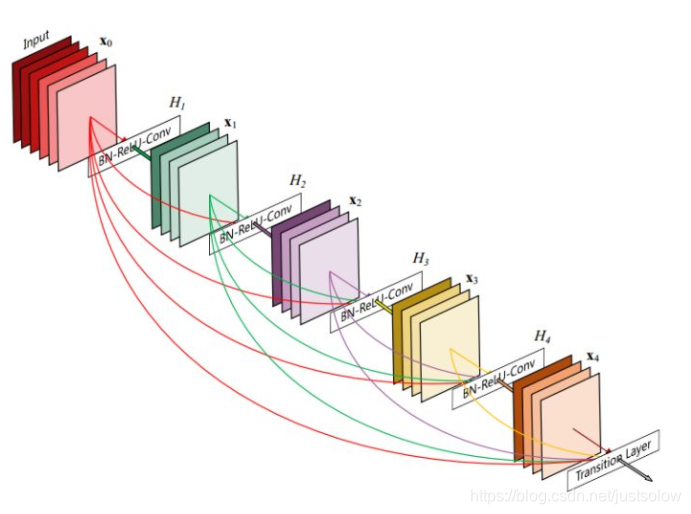
看这个可能更好理解:
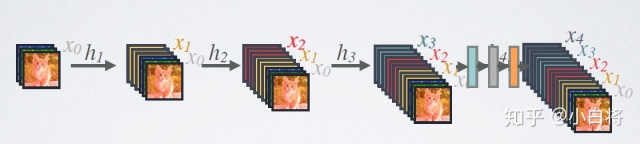
DenseNet网络的优点有:
1、DenseNet网络结构可以减轻网络的梯度消失
2、DenseNet加强了feature-map的传递
3、DenseNet相比之前的识别网络,对feature_map的利用更加有效
4、DenseNet相比之前的识别网络,减少了的网络的参数量
它主要拥有以下两个特性:1)一定程度上减轻在训练过程中梯度消散的问题。因为从上左图我们可以看出,在反传时每一层都会接受其后所有层的梯度信号,所以不会随着网络深度的增加,靠近输入层的梯度会变得越来越小。2)由于大量的特征被复用,使得使用少量的卷积核就可以生成大量的特征,最终模型的尺寸也比较小。
我对结构设计上的细节进行了以下总结:
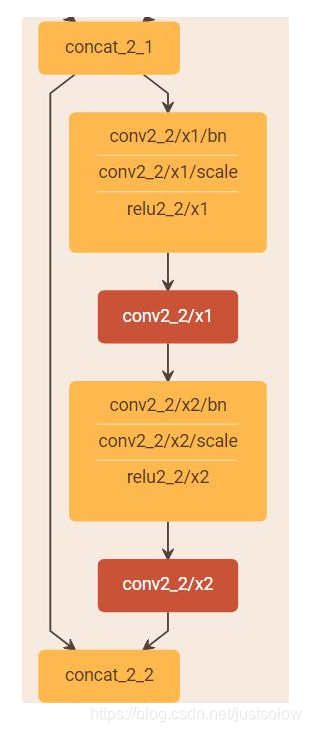
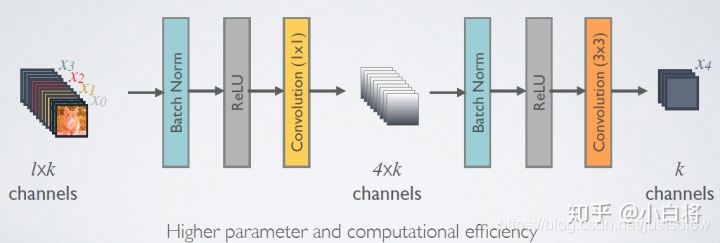
1)为了进行特征复用,在跨层连接时使用的是在特征维度上的Concatenate 操作,而不是Element-wise Addition 操作。
2)由于不需要进行Elewise-wise操作,所以在每个单元模块的最后不需要一个1X1的卷积来将特征层数升维到和输入的特征维度一致。
3)采用Pre-activation 的策略来设计单元,将BN操作从主支上移到分支之前。(BN->ReLU->1x1Conv->BN->ReLU->3x3Conv)
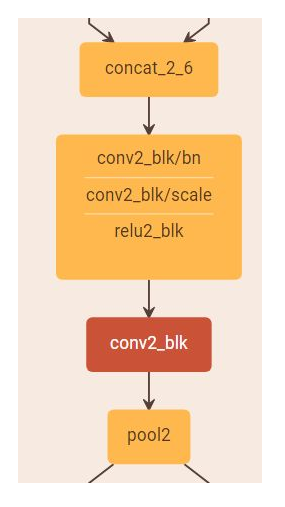
4)由于网络中每层都接受前面所有层的特征作为输入,为了避免随着网络层数的增加,后面层的特征维度增长过快,在每个阶段之后进行下采样的时候,首先通过一个卷积层将特征维度压缩至当前输入的一半,然后再进行Pooling的操作。如下图所示:
5)增长率的设置。增长率指的是每个单元模块最后那个3x3的卷积核的数量,记为k。由于每个单元模块最后是以Concatenate的方式来进行连接的,所以每经过一个单元模块,下一层的特征维度就会增长k。它的值越大意味着在网络中流通的信息也越大,相应地网络的能力也越强,但是整个模型的尺寸和计算量也会变大。作者在本文中使用了k=32 和 k=48两种设置。
作者基于以上原则针对于ImageNet物体识别任务分别设计了DesNet-121(k=32)、DesNet-169(k=32)、DesNet-201(k=32)和DesNet-161(k=48)四种网络结构。其网络的组织形式和ResNet类似,也是分为4个阶段,将原先的ResNet的单元模块进行了替换,下采样过程略有不同。整体结构设计如下所示:
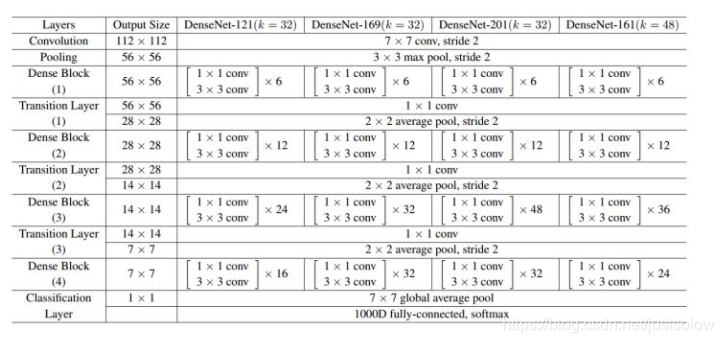
DenseNet的结构:
DenseNet的网络结构主要由DenseBlock和Transition组成:(每个DenseNet之间的部分就是Transition)
其中DenseBlock中用到了1x1卷积来减小通道数:
Transition:

作者Q&A:
Q1:DenseNet是否可以在物体检测任务中使用?效果如何?
A2:当然,DenseNet可以通过和ResNet一样的方法被应用到物体检测任务中。但是作者并没有在物体检测任务上进行实验,如果关注DenseNet在物体检测任务上的效果,可以参考第三方的将DenseNet用在物体检测任务上的实验结果。
Q2:通过图表可以看到,DenseNet在相对较小计算量和相对较小的模型大小的情况下,相比同等规模的ResNet的准确率提升会更明显。是否说明DenseNet结构更加适合小模型的设计?
A2:确实,在小模型的场景下DenseNet有更大的优势。同时,作者也和近期发表的MobileNet这一针对移动端和小模型设计的工作进行了对比,结果显示DenseNet(400MFlops)可以在更小的计算量的情况下取得比MobileNet(500MFlops)更高的ImageNet分类准确率。
Q3:DenseNet中非常关键的连续的跨层Concatenate操作仅存在于每个Dense Block之内,不同Dense Block之间则没有这种操作,是怎样一种考虑?
A3:事实上,每个Dense Block最后的特征图已经将当前Block内所有的卷积模块的输出拼接在一起,整体经过降采样之后送入了下一个Dense Block,其中已经包含了这个Dense Block的全部信息,这样做也是一种权衡。
Q4:DenseNet这样的模型结构在训练过程中是否有一些技巧?
A4:训练过程采用了和ResNet的文章完全相同的设定。但仍然存在一些技巧,例如因为多次Concatenate操作,同样的数据在网络中会存在多个复制,这里需要采用一些显存优化技术,使得训练时的显存占用可以随着层数线性增加,而非增加的更快。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









