




 本文详细介绍自动编码器(autoencoder)的基本原理及其在特征学习和数据降维中的应用,并通过手动编写代码实现自动编码器,对MNIST数据集进行训练,展示了模型训练过程及3D可视化效果。
本文详细介绍自动编码器(autoencoder)的基本原理及其在特征学习和数据降维中的应用,并通过手动编写代码实现自动编码器,对MNIST数据集进行训练,展示了模型训练过程及3D可视化效果。
自动编码器(autoencoder) 是神经网络的一种,该网络可以看作由两部分组成:一个编码器函数h = f(x) 和一个生成重构的解码器r = g(h)。传统上,自动编码器被用于降维或特征学习
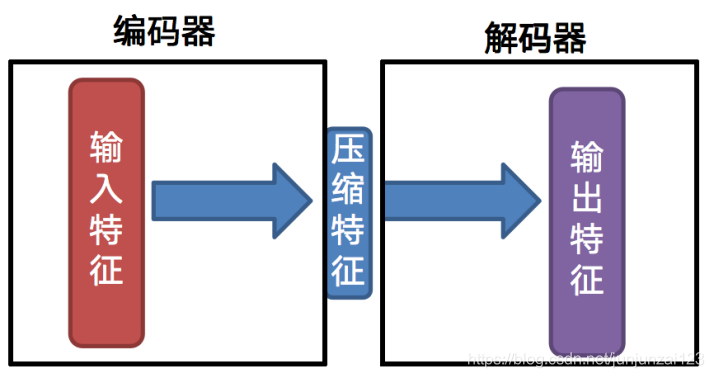
自编码器原理示意图
编码器:将原始高维特征数据映射为低维度表征数据
解码器:将低纬度的压缩特征重构回原始数据
核心:输入特征等于输出特征
那么我们就会有一个疑问:压缩特征为什么小于输入特征?这里我们使用的是欠完备自动编码器:输入特征大于压缩特征.
下面我们手动编写一个自动编码器, 我们先来整理一下编写流程:
1. 获取数据
2. 模型搭建
3. 最优化设置
4. 模型训练
5. 数据3D可视化
然后呢, 我们就按照这个流程来编写我们的代码, 此代码的前提是有GPU, 代码才不会报错.
1. 获取数据
import numpy as np
import torch
import torchvision
import torchvis 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5613
5613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









