



 本文提供了一种解决谷歌资源在国内下载容易卡住的问题方案。首先推荐使用百度网盘下载数据集压缩包,并存放于特定文件夹。接着,通过修改tensorflow_datasets的源码,定义本地压缩文件路径,从而实现资源的顺利下载。
本文提供了一种解决谷歌资源在国内下载容易卡住的问题方案。首先推荐使用百度网盘下载数据集压缩包,并存放于特定文件夹。接着,通过修改tensorflow_datasets的源码,定义本地压缩文件路径,从而实现资源的顺利下载。
谷歌的资源国内下载很容易卡住
首先从百度网盘下载数据集压缩包存放到 XXX/tensorflow_datasets 文件夹
链接:imdb_reviews
提取码:vfng
然后修改源码中如下方法
tensorflow_datasets.text.imdb.IMDBReviews#_split_generators
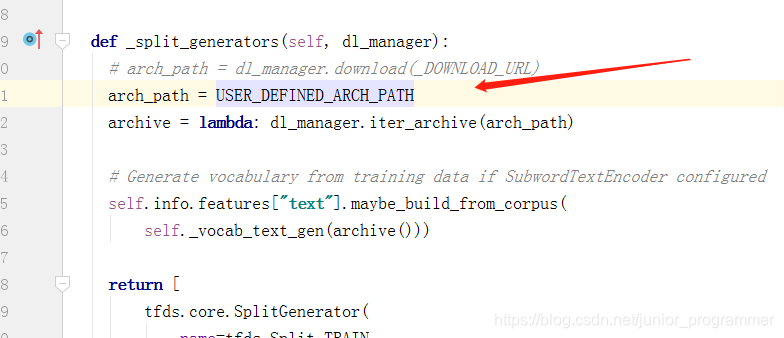
定义压缩文件路径:USER_DEFINED_ARCH_PATH= r'XXX/tensorflow_datasets/imdb_reviews.tar.gz'
按下图注释并修改官方的代码

















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









