




 本文介绍了一个简单的JSON解析器实现,该解析器能处理包含转义字符的JSON字符串,并将Unicode字符转换为UTF-8编码格式。文章通过代码示例详细解释了如何解析JSON字符串中的特殊字符。
本文介绍了一个简单的JSON解析器实现,该解析器能处理包含转义字符的JSON字符串,并将Unicode字符转换为UTF-8编码格式。文章通过代码示例详细解释了如何解析JSON字符串中的特殊字符。
图片和代码思路均参考:https://zhuanlan.zhihu.com/p/22731540
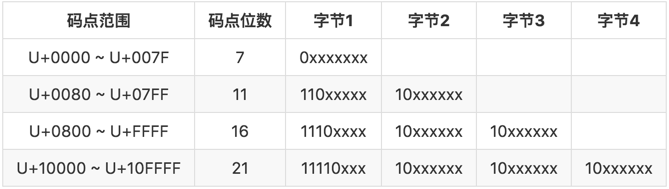
json的字符串格式为"...",下面写个解析器来解析json的字符串也就是主要处理包含转义字符\这种情况,其中\u表示unicode字符,我们需要转成utf-8的编码格式,为什么呢?看下图
 将会
将会
如果unicode用上图第一列的默认编码(utf-16),将会使每一个字符至少占用两个字节,而使用上图右边的utf-8编码,对于常用的字符(比如ASCII字符)将会占用一个字节,也意味着对ASCII字符的文档兼容性更好(都是一个字节为单位)。其实对于汉字来说,看上图的第二第三行,用utf-16更加节省内存,但是目前互联网英文文档居多,所以utf-8依然是主流的编码方式。
# include <stdio.h>
# include <stdlib.h>
# include <assert.h>
# include <string.h>
# define INIT_SIZE 256
char *s;//最终存储解析后的字符串
struct buff{
char *stk;//利用栈来模拟缓冲区
int SIZE, top;//栈容量和栈顶指针
}buff;//缓冲区
char *push(int len){//栈增加len容量
if(buff.top + len >= buff.SIZE){
if(buff.SIZE == 0) buff.SIZE = INIT_SIZE;
while(buff.top + len >= buff.SIZE){
buff.SIZE += buff.SIZE >> 1;//如果长度不够,变为原来的1.5倍
}
buff.stk = (char *)realloc(buff.stk, buff.SIZE);//重新分配内存
}
char *ret = buff.stk + buff.top;
buff.top += len;
return ret;
}
char *pop(int len){//栈释放len容量
assert(buff.top >= len);
return buff.stk + (buff.top -= len);
}
void put(char c){
*push(sizeof(c)) = c;
}
char *parse_hex4(char *p, unsigned *u){
*u = 0;
for(int i=0; i<4; ++i){
char c = *p++;
(*u) <<= 4;
if(c>='0' && c<='9') *u += c-'0';
else if(c>='a' && c<='f') *u += c-'a';
else if(c>='A' && c<='F') *u += c-'A';
else return NULL;
}
return p;
}
void encode_utf8(unsigned u){
if (u <= 0x7F)
put(u & 0xFF);
else if (u <= 0x7FF) {
put(0xC0 | ((u >> 6) & 0xFF));
put(0x80 | ( u & 0x3F));
}
else if (u <= 0xFFFF) {
put(0xE0 | ((u >> 12) & 0xFF));
put(0x80 | ((u >> 6) & 0x3F));
put(0x80 | ( u & 0x3F));
}
else {
assert(u <= 0x10FFFF);
put(0xF0 | ((u >> 18) & 0xFF));
put(0x80 | ((u >> 12) & 0x3F));
put(0x80 | ((u >> 6) & 0x3F));
put(0x80 | ( u & 0x3F));
}
}
bool parse_string(char *str){
char *p = str;
size_t head = buff.top, len;
unsigned u, u2;
if(p == NULL || *p != '\"') return false;
++p;
while(true){
char ch = *p++;
switch(ch){
case '\"':
len = buff.top-head;
s = (char *)malloc(len);
memcpy(s, pop(len), len);
return true;
case '\\':
switch(*p++){
case'\"': put('\"'); break;
case '\\': put('\\'); break;
case '/': put('/' ); break;
case 'b': put('\b'); break;
case 'f': put('\f'); break;
case 'n': put('\n'); break;
case 'r': put('\r'); break;
case 't': put('\t'); break;
case 'u':
if(!(p = parse_hex4(p, &u))) return false;
if(u>=0xD800 && u<=0xDBFF){
if(*p++ != '\\') return false;
if(*p++ != 'u') return false;
if(!(p = parse_hex4(p, &u2))) return false;
if (u2<0xDC00 || u2>0xDFFF) return false;
u = (((u - 0xD800) << 10) | (u2 - 0xDC00)) + 0x10000;
}
encode_utf8(u);
break;
default:
return false;
}
break;
case '\0': return false;
default:
if ((unsigned char)ch < 0x20)
return false;
put(ch);
}
}
}
int main(){
buff.stk = s = NULL;
buff.SIZE = buff.top = 0;
parse_string("\"hello\"");
return 0;
}

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









