








前言
在使用 pandas 去处理某些数据的过程中,我相信有些小伙伴会有些苦恼,如何能让 pandas 的处理速度能再提升一些呢?本文给大家提供一些可行的建议,帮助大家提升处理数据的效率。
什么是pandas?
Pandas 是数据科学和数据竞赛中常见的 Python 第三方库,我们使用 Pandas 可以进行快速读取数据、分析数据、构造特征。但 Pandas 在使用上有一些技巧和需要注意的地方,如果你没有正确的使用,那么 Pandas 的运行速度可能会非常慢。本文将整理一些 Pandas 使用技巧,主要是用来在同等软硬件条件下节约内存和提高代码运行速度。
一、使用pandas读取与存储数据优化
在 Pandas 中内置了众多的数据读取函数,可以读取众多的数据格式,最常见的就是 read_csv 函数从 csv 文件读取数据了。但 read_csv 在读取大文件时并不快,所以建议你使用 read_csv 读取一次原始文件,将 dataframe 存储为 HDF 或者 feather 格式。一般情况下 HDF 的读取比读取 csv 文件快几十倍,但 HDF 文件在大小上会稍微大一些。
性能测试:
接下来我会分别使用 read_csv 、 read_hdf 、以及 read_feather 分别进行一个 660MB 大小的文件读取测试(机器的软硬件条件不一样,运行得出的结果也会有所区别!):
① 一次性读取原生 CSV 文件:
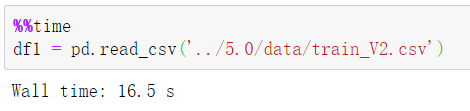
② 将读取出来的 dataframe 分别转存成 hdf5 以及 feather 格式的文件:
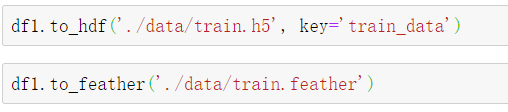
③ 一次性读取 hdf5 格式的文件:
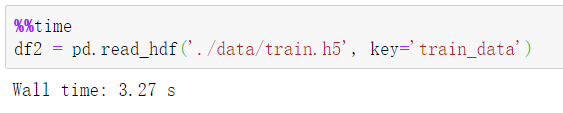
④ 一次性读取 feather 格式的文件:
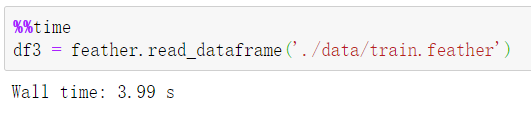
⑤ 事实上读取大容量的 CSV 文件我们还有其它省内存和加速的方法,就是使用 read_csv 中的 chunksize 参数和 iterator 参数,实现数据的分块读取和迭代器的构建,是比较 Pythonic 的方法:

同时如果你想要读取出来的 dataframe 尽量占用较小的内存,可以在 read_csv 时就设置好每列数据的数据类型,也就是指定 dtype 参数。
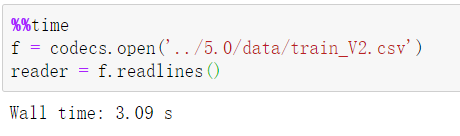
⑥ 在某些定长的字符数据的读取情况下, read_csv 读取速度比 codecs.readlines 慢很多倍:
总结一:
尽可能的避免读取原始 csv ,文件过大时可以使用 read_csv 中的 chunksize 和 iterator 参数读取,或者使用 hdf 、 feather 格式文件加快文件读取。
二、iterrows与itertuples的使用
itertuples 和 iterrows 都能实现按行对 dataframe 进行迭代的操作,但在任何情况下 itertuples 都比 iterrows 快很多倍。
官方迭代速度参考:
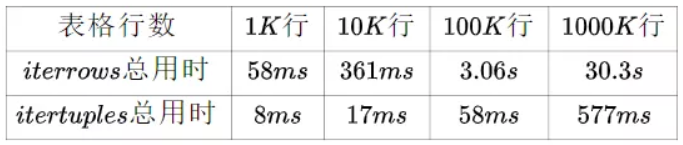
实际测试:
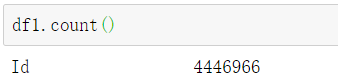
① 查看 dataframe 一共有多少行数据:
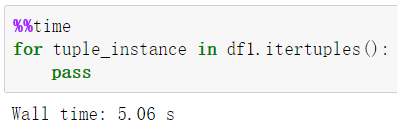
② 使用 itertuples 遍历 dataframe :
③ 使用 iterrows 遍历 dataframe :
总结二:
能使用 itertuples 就尽量不要使用 iterrows 。
三、使用transform和agg对数据做聚合处理
在很多情况下会遇到 groupby 之后做一些聚合计算或者统计运算,如果用内置函数的写法会快很多。
性能测试:
① 对 groupby 之后的数据分别按照 pandas 内置函数写法和不按照内置写法进行 transform :


② 对 groupby 之后的数据分别使用 pandas 内置函数写法和不按照内置写法进行 agg :


总结三:
在 agg 和 transform 时尽量使用 pandas内置函数写法 进行计算。
四、第三方并行库
由于 Pandas 的一些操作都是单核的,往往浪费其他核的计算时间,因此有一些第三方库对此进行了改进:
modin:对读取和常见的操作进行并行;swifter:对apply函数进行并行操作。
当然我之前也对此类库进行了尝试,在一些情况下会快一些,但还是不太稳定。如果用 joblib 库去做并行特征提取,会比单核特征提取快几十倍左右。
总结四:
如果条件允许,能使用并行就并行,能用第三方库或者自己手写多核计算就用。
五、代码优化思路
在优化 Pandas 时可以参考如下操作的时间对比:
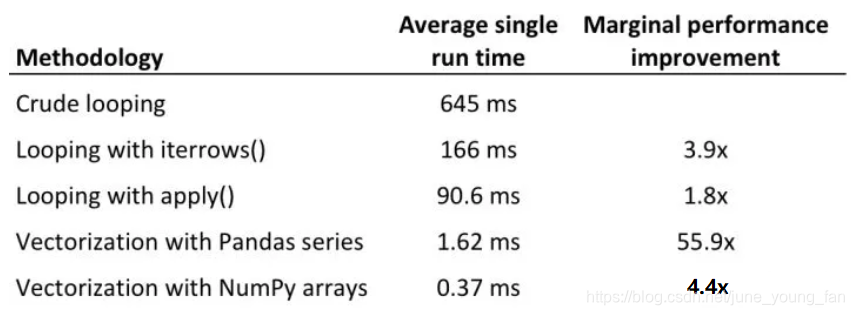
总结五:
在优化的过程中可以按照自己需求进行代码优化,写代码尽量避免暴力循环,尽量写能够向量化计算的代码、多核计算的代码。
结尾
Pandas 官方也写了一篇性能优化的文章,非常值得阅读:
https://pandas.pydata.org/pandas-docs/stable/user_guide/enhancingperf.html

















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









