






💟博主:程序员君君:优快云作者、博客专家、全栈领域优质创作者
💟 专注于计算机毕业设计,大数据、深度学习、Java、小程序、 python、安卓等技术领域
📲文章末尾获取源码+数据库
🌈还有大家在毕设选题(免费咨询指导选题),毕设、作业项目以及论文编写等相关问题
⭐都可以直接找我解答、希望可以帮助更多人
今日要和大家分享的是《CBA球员数据可视化分析系统的设计与实现 》
关键技术: Python、Django和mysql、B/S模式框架、网络爬虫技术
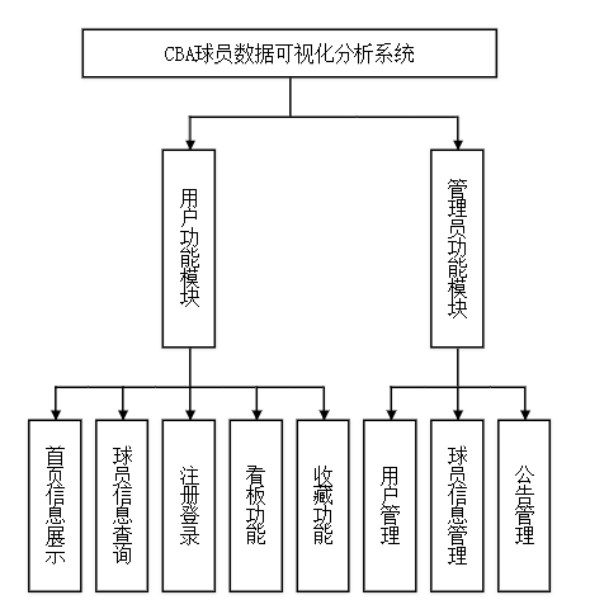
系统功能模块设计
系统功能模块主要分为用户和管理员两大模块,协同为用户提供CBA球员数据可视化分析服务。
用户模块功能包括:
1)首页模块:展示CBA最新动态、即将举行的比赛预告及热门球员信息,提供系统导航栏。
2)球员信息查询:支持通过姓名、球队、位置等关键词查询球员信息,结果以表格或图表展示,可查看详细比赛表现分析。
3)注册登录:用户注册需验证用户名唯一性、密码强度和邮箱格式,登录后享受个性化服务,如收藏球员和数据,设置展示偏好,提供找回密码功能。
4)看板模块:展示球队和球员排名,提供数据对比功能,数据实时更新,确保用户获取最新赛事统计信息。
管理员模块功能包括:
1)用户管理:查看、编辑用户信息,封禁违规用户,统计用户活跃度,为系统优化提供参考。
2)球员信息管理:添加、删除球员信息,进行数据校验,定期从CBA官网爬取最新数据,记录更新日志,清洗和预处理数据。
3)公告管理:发布系统公告,如维护通知、功能更新说明、赛事重要信息,对已发布的公告进行编辑和删除,公告按发布时间倒序排列展示。
业务逻辑层负责处理用户请求,调用相应功能模块,涉及数据操作则与数据访问层交互。管理员操作需进行权限验证和数据校验。系统设计充分考虑用户需求和可扩展性。
5.1 项目结构
项目采用分层架构组织代码,根目录下包含核心功能模块与资源文件:app目录为系统核心,包含models定义数据库模型(如User、Player)、controllers处理业务逻辑与请求响应、views存储前端模板与交互代码、services封装爬虫/数据分析/可视化等业务逻辑,并通过config.py配置数据库连接与系统参数,routes.py定义路由规则,app.py作为启动入口;辅助目录data存储爬取与处理后的数据文件,static存放CSS/JS/图片等静态资源,templates包含动态渲染的HTML模板;requirements.txt记录Python依赖包版本。该结构通过分层解耦实现模块化开发,提高代码复用性与可维护性,为系统扩展奠定基础。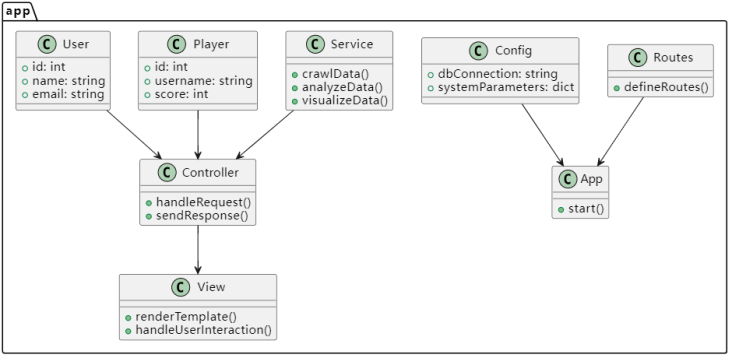
图5.1 app.py启动架构

图5.2 根目录架构
5.2 数据爬取模块实现
数据爬取模块是获取CBA球员数据的关键,需应对CBA官网的反爬虫机制。官网反爬虫机制包括IP限制、User-Agent检测、验证码验证,如同一IP短时间频繁访问会被封禁,不符合正常浏览器标识的请求会被拒,访问次数达到阈值会弹出验证码。本系统采取对应策略:构建代理IP池,随机选择代理IP避免单一IP被封;伪装请求头,设置常见浏览器标识并合理设置Referer字段;利用Tesseract-OCR结合深度学习模型识别图片字母数字验证码,用Selenium库模拟鼠标滑动处理滑块验证码。数据解析用BeautifulSoup库,方便提取数据元素并格式化处理。数据存储采用MySQL数据库,用MySQL-Connector-Python库操作。建立合适数据表结构,如“players”表存储球员数据,通过批量插入提高效率,对敏感数据加密存储,为后续分析和可视化提供准确、完整的数据。
图5.3 数据爬取功能界面
部分实现代码如下所示:
import requests
from bs4 import BeautifulSoup
import mysql.connector
import random
代理IP池
proxy_list = [
{‘http’: ‘http://111.111.111.111:8080’},
{‘http’: ‘http://222.222.222.222:9090’},
# 更多代理IP
]
伪装请求头
headers = {
‘User - Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36’,
‘Referer’: ‘https://www.cba.net.cn/’
}
连接MySQL数据库
mydb = mysql.connector.connect(
host=“localhost”,
user=“root”,
password=“password”,
database=“cba_data”
)
mycursor = mydb.cursor()
爬取函数
def crawl_player_data(url):
proxy = random.choice(proxy_list)
try:
response = requests.get(url, headers=headers, proxies=proxy, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.content, ‘html.parser’)
# 解析数据,例如提取球员姓名
player_name = soup.find('span', class_='player - name').text.strip()
# 解析其他数据,如得分、篮板等
# 存储数据到数据库
sql = "INSERT INTO players (player_name, score, rebound, assist) VALUES (%s, %s, %s, %s)"
val = (player_name, score, rebound, assist)
mycursor.execute(sql, val)
mydb.commit()
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
except Exception as e:
print(f"解析或存储数据出错: {e}")
URL
url = ‘https://www.cba.net.cn/player/123’
crawl_player_data(url)
mycursor.close()
mydb.close()
5.3 数据处理模块实现
在数据清洗阶段,主要处理数据中的缺失值、重复值和异常值。对于缺失值,采用多种方法进行处理。如果缺失值所在的列对数据分析的影响较小,且缺失比例较高,可以考虑直接删除含有缺失值的行;若缺失比例较低,则根据数据的特点,使用均值、中位数或插值法进行填充。例如,对于球员的身高、体重等数值型数据,若存在缺失值,可以计算同位置球员的均值或中位数进行填充;对于比赛数据中的得分、篮板等数据,可根据球员在其他比赛中的表现进行插值填充。以Pandas库为例,使用fillna方法进行缺失值填充。
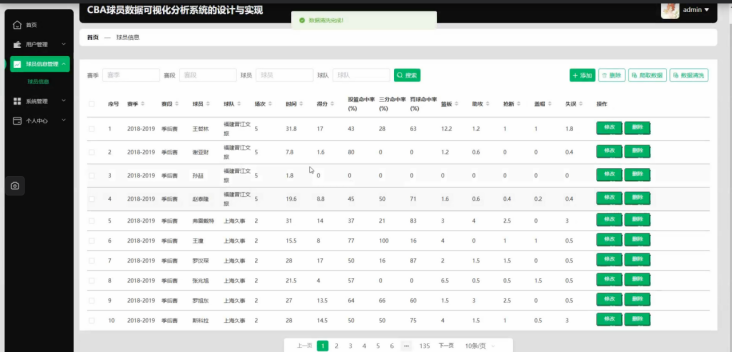
图5.4 数据清洗功能界面
部分实现代码如下所示:
import pandas as pd
data是包含球员数据的DataFrame
使用均值填充得分列的缺失值
mean_score = data[‘score’].mean()
data[‘score’] = data[‘score’].fillna(mean_score)
使用中位数填充篮板列的缺失值
median_rebound = data[‘rebound’].median()
data[‘rebound’] = data[‘rebound’].fillna(median_rebound)
5.4 数据可视模块实现
数据可视化模块是系统的关键展示部分,通过直观的图表和图形,将CBA球员数据以易于理解的方式呈现给用户,帮助用户快速洞察数据背后的信息和规律。在实现过程中,充分利用Python丰富的数据可视化库,如Matplotlib、Seaborn和PlotlyExpress,根据不同的数据特点和用户需求,创建多样化的可视化图表,同时注重图表的交互性和美观性,以提升用户体验。Matplotlib作为基础的数据可视化库,在本模块中主要用于创建简单的静态图表,如柱状图、折线图等,以展示球员的基本数据和比赛表现趋势。例如,展示球员在不同赛季的得分变化趋势时,可以使用Matplotlib绘制折线图。

图5.5(a) 可视化看板功能整体界面
图5.5(b)以场次为横坐标,得分、投篮命中率、三分命中率等为纵坐标,呈现了K・威尔誓、丁皓然、亚当斯、付博文等球员的部分数据情况。在得分方面,球员间存在一定差异,例如可能K・威尔誓得分相对较高,在图中展现出的得分曲线位置偏高;投篮命中率和三分命中率上,也各有不同,反映出不同球员在得分能力和得分方式上的特点。数据处理层利用Pandas完成缺失值填充、异常值检测及数据标准化等操作,确保数据质量。在可视化层面,借助Matplotlib、Seaborn与PlotlyExpress等工具,能更直观地呈现数据。例如,利用Matplotlib绘制折线图展示球员得分随场次的变化趋势,若将图片中的数据以折线图呈现,可清晰看到各球员得分的波动情况;使用Seaborn绘制成对关系图,可分析得分与投篮命中率、三分命中率之间的相关性;借助PlotlyExpress创建交互式图表,球迷、教练和球队管理层能通过交互操作,如悬停提示、缩放、平移等,深入探索这些球员数据的细节和变化,为战术制定、球员评估等提供有力支持。
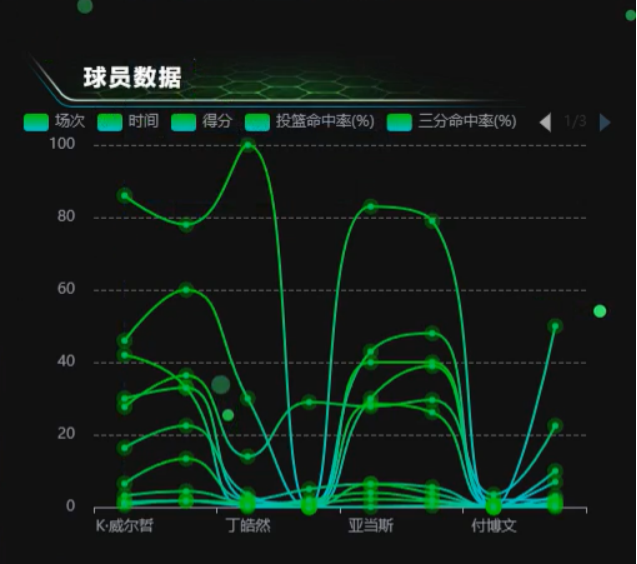
图5.5(b) 球员数据分析
图5.5(c)是CBA赛季统计的饼状图,展示了2018-2024年各赛季数据占比情况。其中2020-2021赛季占比最高,达23.81%,说明该赛季在统计范畴内可能有较多关键数据,或许是比赛场次增多、数据统计维度更丰富等原因。2019-2020赛季占比最低,为13.09%。各赛季占比差异反映出不同时期联赛发展状态、赛事规模或数据统计重点的变化。例如,占比较高的赛季可能在商业推广、赛事影响力等方面表现突出,吸引更多关注与资源投入;占比低的赛季或许受外部因素影响,如疫情冲击等,导致相关数据产出受限。通过这些占比数据,能帮助联赛管理者、分析师等洞察CBA联赛在不同阶段的特征与发展趋势,为后续决策与规划提供参考。
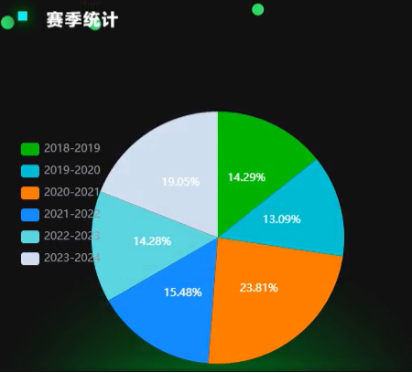
图5.5(c) 赛季统计
从图5.5(d)这张表格呈现了2024-2025赛季CBA部分球员的信息,涵盖常规赛和季后赛。从场次看,刘传兴、TJ·利夫等球员出战33场,场次较多,表明其在球队中上场机会稳定,可能是球队战术体系中的重要组成部分。时间方面,韦瑟斯庞场均39.8分钟,高居榜首,显示他是球队核心,承担大量场上任务。得分上,韦瑟斯庞以28.6分领先,克里斯、TJ·利夫、林葳、基兹林克得分也超20分,说明他们在进攻端具备较强火力,是球队得分关键人物。季后赛中,余嘉豪得分13.6分,在有限数据中表现尚可,而孟子凯数据相对逊色,可能受上场时间等因素限制。这些数据能帮助球队评估球员表现,调整战术,也便于球迷和媒体了解球员赛场贡献。
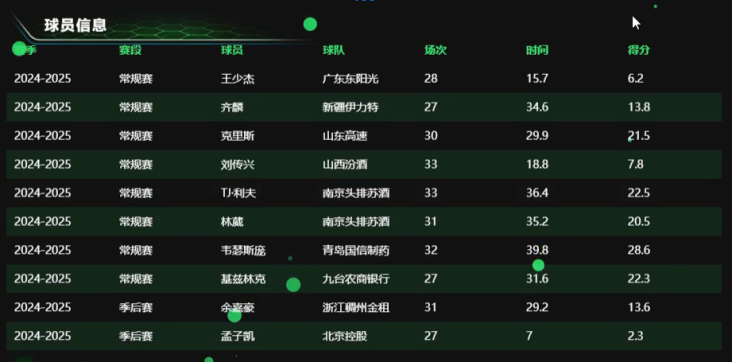
图5.5(d) 球员信息统计
图5.5(e)展示了CBA不同赛段的统计数据,采用了渐变色彩的条形形式呈现。2020-2021赛段的条形最长,数值接近20,在各赛段中处于领先位置,说明该赛段在统计指标上表现突出,可能是比赛场次多、总得分高或其他关键数据量较大。2019-2020、2018-2019等赛段数值相对较小,处于10-12左右。2024-2025、2023-2024、2022-2023以及2021-2022赛段数值介于两者之间。通过这些数据对比,能清晰看出各赛段在相应统计指标上的差异,有助于赛事组织者分析不同时期联赛的发展情况,比如判断赛事热度变化、竞技水平波动等,从而为后续赛事安排、资源调配等决策提供有力的数据支撑。
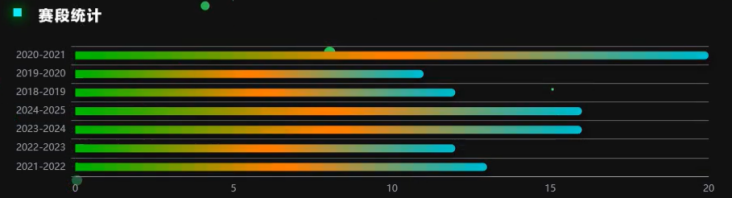
图5.5(e) 赛段统计
图5.5(f)是CBA球队统计的柱状图。从图中可知,不同球队在统计指标上存在明显差异。九台农商银行的柱子最高,数值达7,在该统计维度上表现最为突出,可能是在某方面(如胜场数、总得分等)大幅领先。山东高速数值为6,北京控股为5,也处于较高水平,说明这两支球队在对应统计内容上表现良好。四川丰谷酒业数值相对较低,为3左右,反映其在该指标上表现较弱。这些数据能帮助分析各球队在特定赛季或阶段的表现,便于评估球队实力,也为球迷、媒体和赛事组织者了解联赛格局提供数据参考。
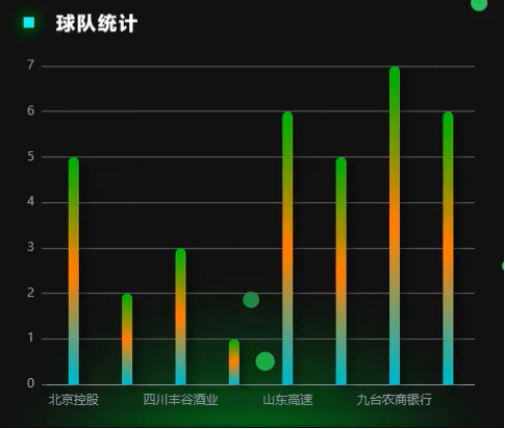
图5.5(f) 球队统计
图5.5(g)为CBA球员名称词云图。词云大小反映球员受关注程度或提及频率。其中,“闫鹏飞”“刘毅”“余嘉豪”“范子铭”“张皓嘉”等名字字体较大,表明他们在相关数据统计或讨论场景中更为突出,可能是因其在比赛中有出色表现,如得分、篮板、助攻等关键数据亮眼,或是在球队战术体系中扮演重要角色,吸引了更多关注。而字体较小的球员,可能在该统计周期内表现相对低调,或球队战术地位没那么核心。通过词云图能直观感受到哪些球员在特定情境下更受瞩目,为分析球员影响力和赛事热点提供了可视化视角。

图5.5(g) 球员名称展示
部分实现代码如下所示:
import matplotlib.pyplot as plt
import pandas as pd
data是包含球员得分和赛季数据的DataFrame
seasons = data[‘season’]
scores = data[‘score’]
plt.plot(seasons, scores, marker=‘o’)
plt.title(‘Player Score Trends over Seasons’)
plt.xlabel(‘Season’)
plt.ylabel(‘Score’)
plt.show()
5.5 球员信息模块实现
球员信息模块是CBA球员数据可视化分析系统的重要组成部分,主要负责展示和管理球员的各类信息。该模块会从数据库中读取球员的基本信息、比赛数据、技术统计等内容,并以清晰易懂的方式呈现给用户。用户可以通过该模块查询特定球员的详细信息,也能查看所有球员的列表。在实现上,前端使用HTML、CSS和JavaScript构建页面,后端使用Python结合Flask框架处理请求和数据交互。
图5.6 球员信息功能界面
关键核心代码如下:
Flask 路由处理球员信息查询
@app.route(‘/player/int:player_id’)
def get_player_info(player_id):
# 从数据库获取球员信息
player = Player.query.get(player_id)
return jsonify({
‘name’: player.name,
‘age’: player.age,
‘team’: player.team
})
5.6 公告管理模块实现
公告管理模块用于发布、编辑和删除系统公告,方便管理员向用户传达重要信息。管理员可以通过该模块创建新的公告,设置公告的标题、内容、发布时间等,同时也能对已发布的公告进行修改和删除操作。该模块前端采用响应式设计,确保在不同设备上都能正常显示。后端使用 Python 和 SQLAlchemy 与数据库交互。
图5.7 公告管理功能界面
核心代码如下:
Flask 路由处理公告发布
@app.route(‘/announcement/add’, methods=[‘POST’])
def add_announcement():
data = request.get_json()
title = data.get(‘title’)
content = data.get(‘content’)
new_announcement = Announcement(title=title, content=content)
db.session.add(new_announcement)
db.session.commit()
return jsonify({‘message’: ‘公告发布成功’})
5. 本章小结
本章基于Python实现CBA球员数据可视化分析系统,采用分层架构管理代码。核心模块包括:数据爬取通过代理IP池、伪装请求头及验证码识别技术绕过反爬虫机制,利用BeautifulSoup解析数据并存储至MySQL;数据处理模块通过Pandas清洗缺失值、异常值并转换格式,结合NumPy/Scipy进行统计分析;可视化模块运用Matplotlib/Plotly生成静态及交互式图表,增强数据可读性。系统前端采用HTML5/CSS3/JavaScript构建用户界面,实现球员查询、数据看板及收藏功能,管理员界面支持用户管理与数据维护。通过模块化设计保障系统可扩展性,为CBA赛事分析提供完整解决方案,后续将开展全面测试验证系统稳定性与功能完整性。
专注于大学生日常作业项目和毕设项目,讲解开发,答疑辅导
点击下方名片可以联系哦~

















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









