









SSM: https://cyborg2077.github.io/2022/09/10/SSMIntegration/
全文的参考链接: https://cyborg2077.github.io/2022/10/22/RedisPractice/
优快云
关键代码
用户UserDTO线程
UserDTO:Long id , nickname, icon
public class UserHolder {
private static final ThreadLocal<UserDTO> tl = new ThreadLocal<>();
public static void saveUser(UserDTO user){
tl.set(user);
}
public static UserDTO getUser(){
return tl.get();
}
public static void removeUser(){
tl.remove();
}
}
验证码登录
redis数据本身就是共享的,就可以避免session共享的问题了
- 根据phone从redis获取验证码并校验,不存在创建用户;
- 为该用户生成一个唯一的 token,并将 UserDTO 转换为 Map 后与该 token 一起存储在 Redis 中。并设置有效期
public Result login(LoginFormDTO loginForm, HttpSession session) {
// 1.校验手机号
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)) {
// 2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
// 3.从redis获取验证码并校验
String cacheCode = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY + phone);
String code = loginForm.getCode();
if (cacheCode == null || !cacheCode.equals(code)) {
// 不一致,报错
return Result.fail("验证码错误");
}
// 4.一致,根据手机号查询用户 select * from tb_user where phone = ?
User user = query().eq("phone", phone).one();
// 5.判断用户是否存在
if (user == null) {
// 6.不存在,创建新用户并保存
user = createUserWithPhone(phone);
}
// 7.保存用户信息到 redis中
// 7.1.随机生成token,作为登录令牌
String token = UUID.randomUUID().toString(true);
// 7.2.将User对象转为HashMap存储
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
Map<String, Object> userMap = BeanUtil.beanToMap(userDTO, new HashMap<>(),
CopyOptions.create()
.setIgnoreNullValue(true)
.setFieldValueEditor((fieldName, fieldValue) -> fieldValue.toString()));
// 7.3.存储
String tokenKey = LOGIN_USER_KEY + token;
stringRedisTemplate.opsForHash().putAll(tokenKey, userMap);
// 7.4.设置token有效期
stringRedisTemplate.expire(tokenKey, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.返回token
return Result.ok(token);
}
对应的发送验证码:
public Result sendCode(String phone, HttpSession session) {
// 1.校验手机号
if (RegexUtils.isPhoneInvalid(phone)) {
// 2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
// 3.符合,生成验证码
String code = RandomUtil.randomNumbers(6);
// 4.保存验证码到redis
stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY + phone, code, LOGIN_CODE_TTL, TimeUnit.MINUTES);//和上面 3.从redis获取验证码并校验 对应
// 5.发送验证码
log.debug("发送短信验证码成功,验证码:{}", code);
// 返回ok
return Result.ok();
}
登录凭证保存在前端浏览器,所以不能用phone之类的个人数据
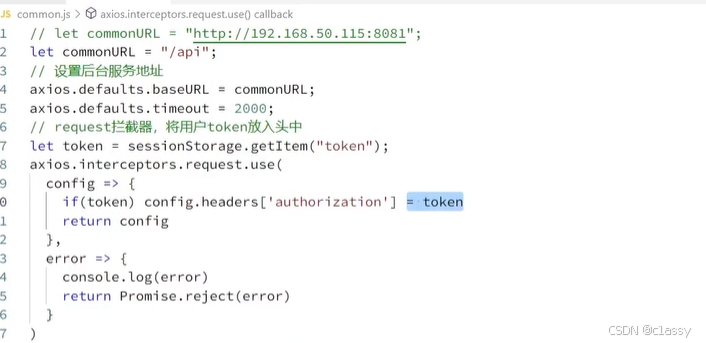
Redis情况:
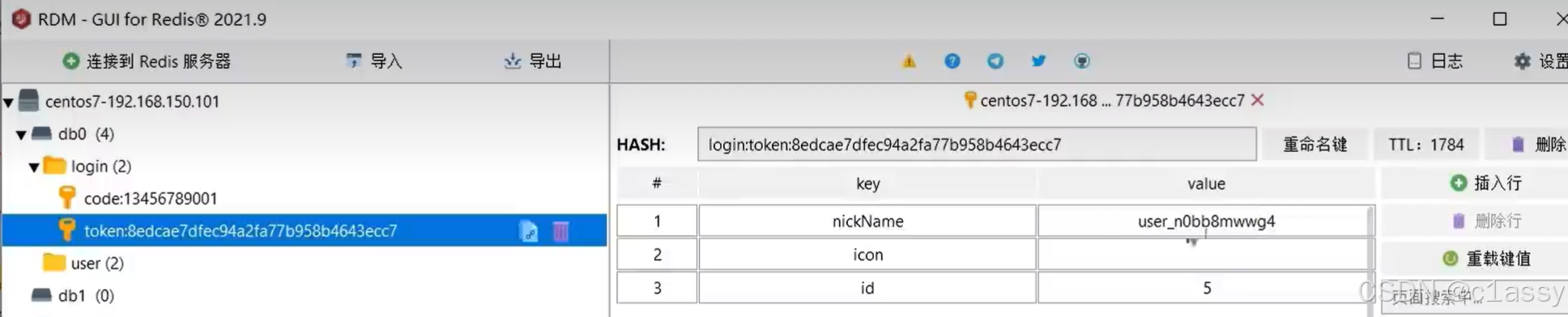
拦截器token判断
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取请求头中的token
String token = request.getHeader("authorization");
if (StrUtil.isBlank(token)) {
return true;
}
// 2.基于TOKEN获取redis中的用户
String key = LOGIN_USER_KEY + token;
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(key);
// 3.判断用户是否存在
if (userMap.isEmpty()) {
return true;
}
// 5.将查询到的hash数据转为UserDTO
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
// 6.存在,保存用户信息到 ThreadLocal
UserHolder.saveUser(userDTO);
// 7.刷新token有效期
stringRedisTemplate.expire(key, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.放行
return true;
}
点赞
内存肯定够用,而且redis有持久化机制,数据可以被持久化到磁盘
Blog.userId和Use.id关联
给Blog类中添加一个isLike字段,标示是否被当前用户点赞
判断这篇笔记是否被点赞过:stringRedisTemplate.opsForZSet().score(key, userId.toString())
点赞功能的实现:
public Result likeBlog(Long id) {
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是否已经点赞
String key = "blog:liked:" + id;
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if (score == null) {
// 3.如果未点赞,可以点赞
// 3.1.数据库点赞数 + 1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2.保存用户到Redis的set集合 zadd key value score
if (isSuccess) {
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {
// 4.如果已点赞,取消点赞
// 4.1.数据库点赞数 -1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
// 4.2.把用户从Redis的set集合移除
if (isSuccess) {
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}
return Result.ok();
}
两个地方需要用到:首页搜索推荐的分页查询 和 点进该笔记
判断是否点赞过,只需要笔记ID即博客ID,获取当前用户,查Redis
// 1.查询top5的点赞用户 zrange key 0 4
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);
这样并没解决频繁操作数据库,可以弄个异步任务,定时去同步redis的笔记的点赞数量,同步到mysql。现在的是点赞一次操作一次数据
lua实现一人一单,发送订单消息到队列
@Res**加粗样式**ource
private StringRedisTemplate stringRedisTemplate;
private static final DefaultRedisScript<Long> SECKILL_SCRIPT;
static {
SECKILL_SCRIPT = new DefaultRedisScript<>();
SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua"));
SECKILL_SCRIPT.setResultType(Long.class);
}
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
long orderId = redisIdWorker.nextId("order");//生成分布式ID
// 1.执行lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(), userId.toString(), String.valueOf(orderId)
);
int r = result.intValue();
// 2.判断结果是否为0
if (r != 0) {
// 2.1.不为0 ,代表没有购买资格
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 3.返回订单id
return Result.ok(orderId);
}

seckill.lua内容:
-- 1. 参数列表
-- 1.1. 优惠券 ID
local voucherId = ARGV[1]
-- 1.2. 用户 ID
local userId = ARGV[2]
-- 1.3. 订单 ID
local orderId = ARGV[3]
-- 2. 数据 key
-- 2.1. 库存 key
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2. 订单 key
local orderKey = 'seckill:order:' .. voucherId
-- 3. 脚本业务
-- 3.1. 判断库存是否充足 get stockKey
if(tonumber(redis.call('get', stockKey)) <= 0) then
-- 3.2. 库存不足,返回 1
return 1
end
-- 3.2. 判断用户是否下单 SISMEMBER orderKey userId
if(redis.call('sismember', orderKey, userId) == 1) then
-- 3.3. 存在,说明是重复下单,返回 2
return 2
end
-- 3.4. 扣库存 incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.5. 下单(保存用户)sadd orderKey userId
redis.call('sadd', orderKey, userId)
-- 3.6. 发送消息到队列中, XADD stream.orders * k1 v1 k2 v2 ...
redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId)
return 0
主要功能:
- 参数接收:通过 ARGV 参数接收优惠券 ID(voucherId)、用户 ID(userId)和订单 ID(orderId)。
即Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(), userId.toString(), String.valueOf(orderId)
);的参数 - 库存判断:使用 Redis 的 get 命令检查库存是否充足。如果库存为 0 或更少,返回 1 表示库存不足。
- 重复下单检查:使用 sismember 检查用户是否已经下单。如果是,返回 2 表示重复下单。//SISMEMBER 是 Redis 的一个原生命令,用于检查一个元素是否存在于 Redis 的 集合(set)中。
- 扣除库存:通过 incrby 命令扣减库存,每次秒杀成功后,库存减 1。
- 记录订单:使用 sadd 将用户 ID 加入到 orderKey 中,表示该用户已成功下单。
- 发送消息到队列:使用 xadd 将订单信息发送到 Redis 流(stream.orders),用于后续的异步处理,如创建订单、扣减库存等。
Controller:提供一个 REST API 接口,接受用户请求并调用业务逻辑。
@RestController
@RequestMapping("/voucher-order")
public class VoucherOrderController {
@Resource
private IVoucherOrderService voucherOrderService;
@PostMapping("seckill/{id}")
public Result seckillVoucher(@PathVariable("id") Long voucherId) {
return voucherOrderService.seckillVoucher(voucherId);
}
}
从队列中获取订单信息,创建订单
代码工作流程
初始化:
@PostConstruct 注解的 init() 方法会在应用启动后自动执行,并启动一个单线程的 ExecutorService(SECKILL_ORDER_EXECUTOR),提交 VoucherOrderHandler 任务,开始处理秒杀订单。
消费者从 Redis Stream 读取订单消息:
VoucherOrderHandler 类中的 run() 方法循环读取 Redis Stream 中的订单信息,并通过 XREADGROUP 命令获取新消息。每次获取一条订单消息,处理后确认该消息。
异常处理和重试:
在处理订单过程中出现异常时,会调用 handlePendingList 方法,重新处理那些未确认的消息。
分布式锁确保顺序性:
每个用户的订单创建都通过分布式锁 RLock 来保证,避免同一个用户多次下单。
import java.util.concurrent.Executors;
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
@PostConstruct
private void init() {
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
private class VoucherOrderHandler implements Runnable {
@Override
public void run() {
while (true) {
try {
// 1.获取消息队列中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 >
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"), // 消费者组 g1 中的消费者 c1
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)), // 读取 1 条消息,最多阻塞 2 秒
StreamOffset.create("stream.orders", ReadOffset.lastConsumed()) // 从上次消费的位置开始读取
);
// 2.判断订单信息是否为空
if (list == null || list.isEmpty()) {
// 如果为null,说明没有消息,继续下一次循环
continue;
}
// 解析数据
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> value = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(value, new VoucherOrder(), true);
// 3.创建订单
createVoucherOrder(voucherOrder);
// 4.确认消息 XACK
stringRedisTemplate.opsForStream().acknowledge("s1", "g1", record.getId());
} catch (Exception e) {
log.error("处理订单异常", e);
handlePendingList();
}
}
}
XREADGROUP:这个命令是消费者组专用的,它允许消费者组的成员从指定流中读取数据。每次读取后,Redis 会记录每个消费者读取到的最后一条消息的 ID,确保每个消费者不会重复消费消息。
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"), // 消费者组 g1 中的消费者 c1
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)), // 读取 1 条消息,最多阻塞 2 秒
StreamOffset.create("stream.orders", ReadOffset.lastConsumed()) // 从上次消费的位置开始读取
);
XACK:该命令用于在消费者成功处理消息后,向 Redis 表示确认该消息已被成功消费。确认的消息会从消费者组的 pending list 中移除。
stringRedisTemplate.opsForStream().acknowledge("s1", "g1", record.getId());
这段代码在成功处理订单后,通过 XACK 命令确认已经消费了流中的消息
handlePendingList 方法重新处理那些未确认的消息。
private void handlePendingList() {
while (true) {
try {
// 1.获取pending-list中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 0
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1),
StreamOffset.create("stream.orders", ReadOffset.from("0"))
);
// 2.判断订单信息是否为空
if (list == null || list.isEmpty()) {
// 如果为null,说明没有异常消息,结束循环
break;
}
// 解析数据
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> value = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(value, new VoucherOrder(), true);
// 3.创建订单
createVoucherOrder(voucherOrder);
// 4.确认消息 XACK
stringRedisTemplate.opsForStream().acknowledge("s1", "g1", record.getId());
} catch (Exception e) {
log.error("处理订单异常", e);
}
}
}
StreamOffset.create(“stream.orders”, ReadOffset.from(“0”)): 这个部分非常关键,ReadOffset.from(“0”) 表示从流的最开始位置读取消息。通常情况下,XREADGROUP 会从 上次消费的位置(ReadOffset.lastConsumed())开始读取,但在 handlePendingList 中,它是从流的 最开始位置 读取消息,意味着它将读取所有 未确认的挂起消息。
创建订单
private void createVoucherOrder(VoucherOrder voucherOrder) {
Long userId = voucherOrder.getUserId();
Long voucherId = voucherOrder.getVoucherId();
// 创建锁对象
RLock redisLock = redissonClient.getLock("lock:order:" + userId);
// 尝试获取锁
boolean isLock = redisLock.tryLock();
// 判断
if (!isLock) {
// 获取锁失败,直接返回失败或者重试
log.error("不允许重复下单!");
return;
}
try {
// 5.1.查询订单
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
// 5.2.判断是否存在
if (count > 0) {
// 用户已经购买过了
log.error("不允许重复下单!");
return;
}
// 6.扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherId).gt("stock", 0) // where id = ? and stock > 0
.update();
if (!success) {
// 扣减失败
log.error("库存不足!");
return;
}
// 7.创建订单
save(voucherOrder);
} finally {
// 释放锁
redisLock.unlock();
}
}
g1 是消费者组的名字,表示一组消费者一起读取流中的消息。
c1 是消费者的名字,在消费者组 g1 中的一个消费者实例。每个消费者组可以包含多个消费者,且每个消费者负责读取流中的一部分数据。
消费者组和消费者的工作方式:
消费者组:Redis 的 Stream 使用消费者组来管理消息的消费。消费者组的目的是让多个消费者共享消息,但每个消息只被组内的一个消费者消费。
消费者:每个消费者会从消息流中获取消息,并进行处理。在你的代码中,c1 是 g1 消费者组中的一个消费者。c1 会读取流中的消息,处理订单,并确认消息。
签到
public Result signCount() {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
LocalDateTime now = LocalDateTime.now();
// 3.拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;
// 4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5.获取本月截止今天为止的所有的签到记录,返回的是一个十进制的数字 BITFIELD sign:5:202203 GET u14 0
List<Long> result = stringRedisTemplate.opsForValue().bitField(
key,
BitFieldSubCommands.create()
.get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0)
);
if (result == null || result.isEmpty()) {
// 没有任何签到结果
return Result.ok(0);
}
Long num = result.get(0);
if (num == null || num == 0) {
return Result.ok(0);
}
// 6.循环遍历
int count = 0;
while (true) {
// 6.1.让这个数字与1做与运算,得到数字的最后一个bit位 // 判断这个bit位是否为0
if ((num & 1) == 0) {
// 如果为0,说明未签到,结束
break;
}else {
// 如果不为0,说明已签到,计数器+1
count++;
}
// 把数字右移一位,抛弃最后一个bit位,继续下一个bit位
num >>>= 1;
}
return Result.ok(count);
}
Session登录
1.2 基于Session实现登录流程
手机或者app端发起请求,请求我们的nginx服务器,nginx基于七层模型走的事HTTP协议,可以实现基于Lua直接绕开tomcat访问redis,也可以作为静态资源服务器,轻松扛下上万并发, 负载均衡到下游tomcat服务器,打散流量,我们都知道一台4核8G的tomcat,在优化和处理简单业务的加持下,大不了就处理1000左右的并发, 经过nginx的负载均衡分流后,利用集群支撑起整个项目,同时nginx在部署了前端项目后,更是可以做到动静分离,进一步降低tomcat服务的压力,这些功能都得靠nginx起作用,所以nginx是整个项目中重要的一环。
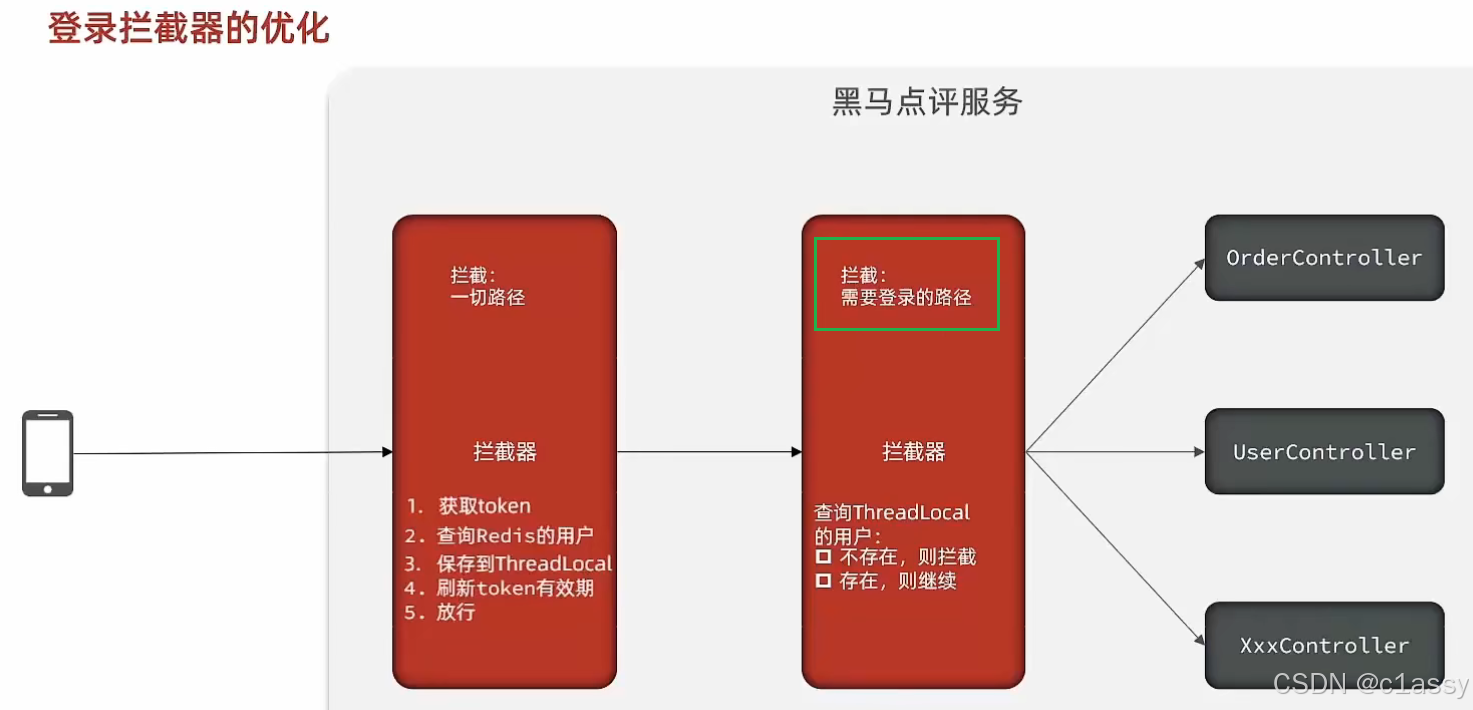
校验登录状态:
用户在请求时候,会从cookie中携带者JsessionId到后台,后台通过JsessionId从session中拿到用户信息,如果没有session信息,则进行拦截,如果有session信息,则将用户信息保存到threadLocal中,并且放行
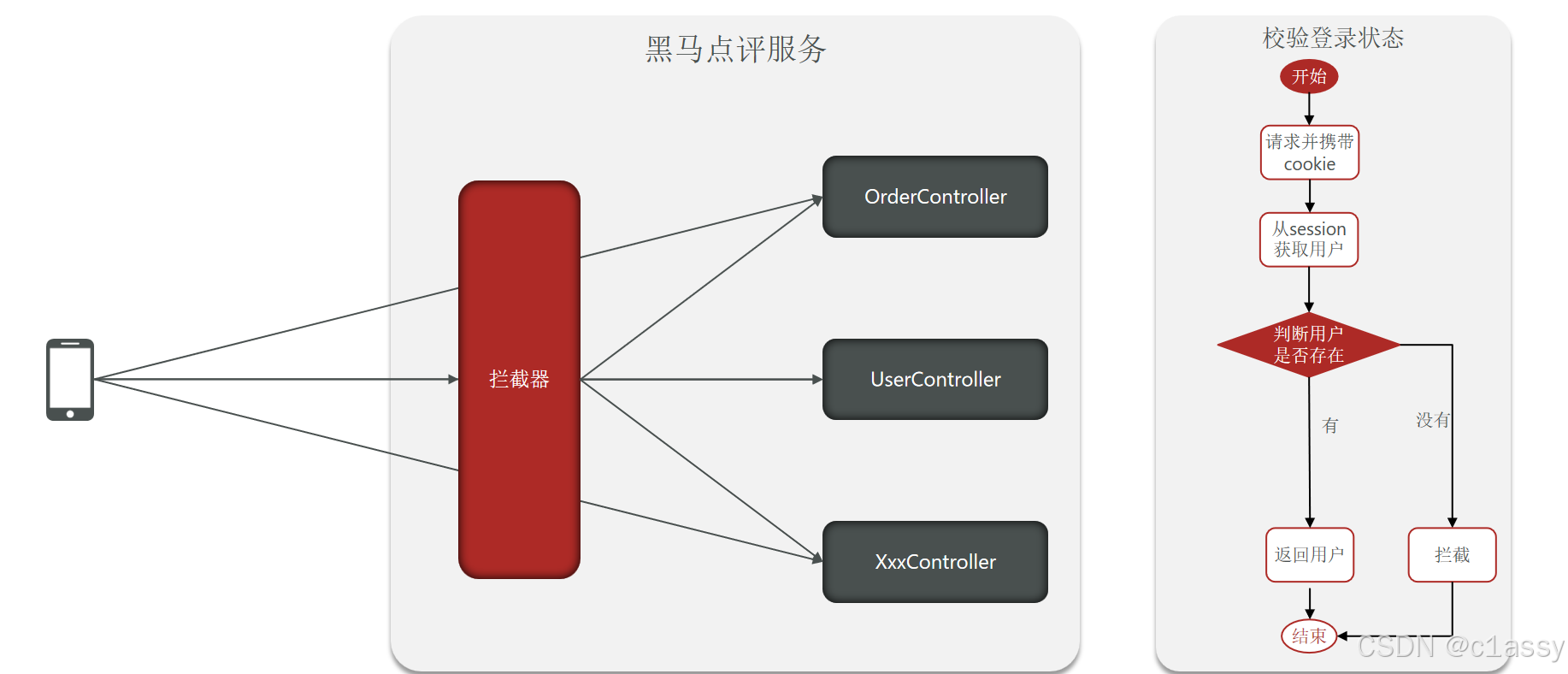
如果将 Token 存放在请求头中并希望在每次请求时刷新 Token 的存活时间,选择在拦截器中改造是一个合理的设计。
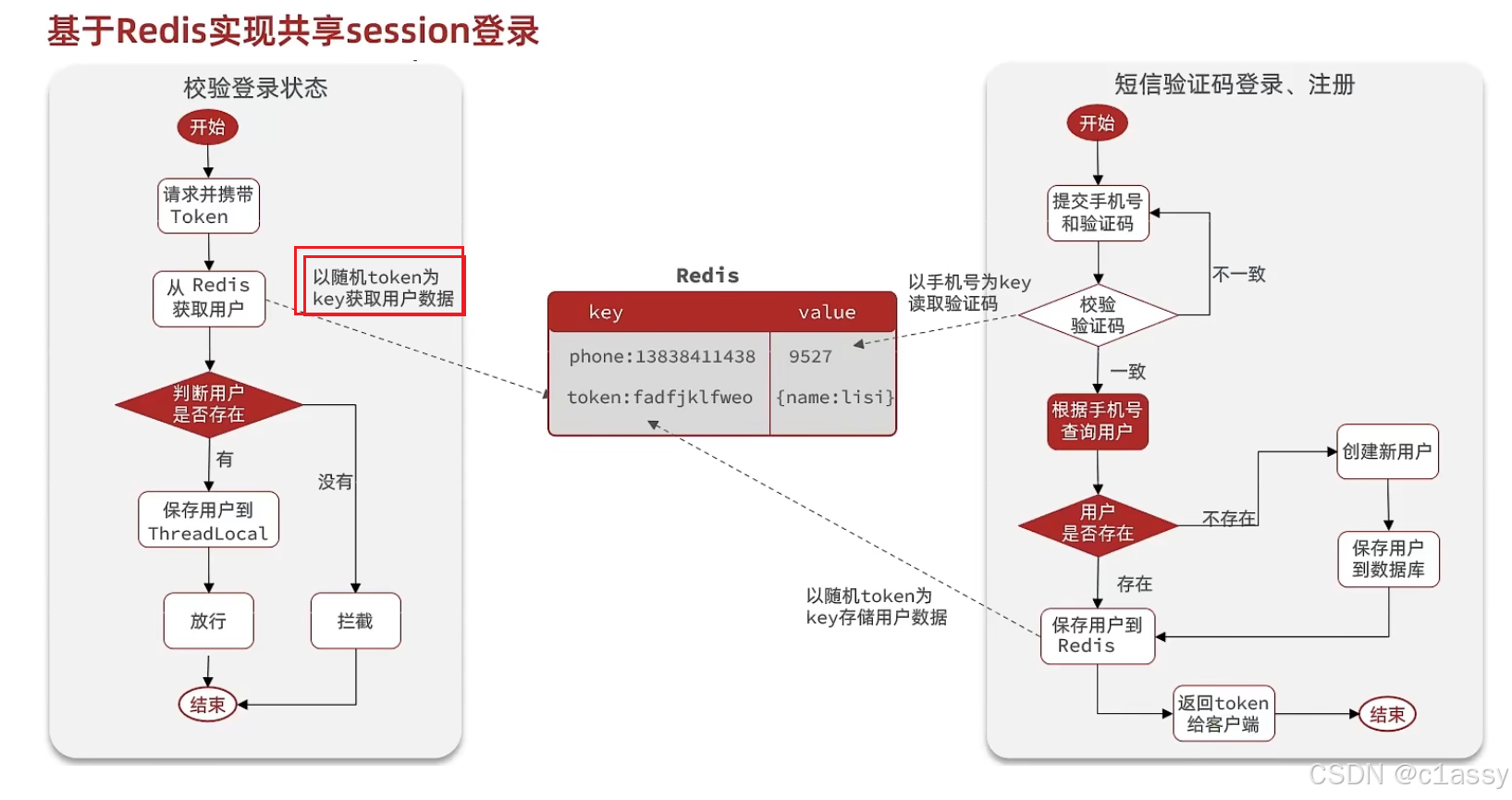
1.7 Redis代替session的业务流程
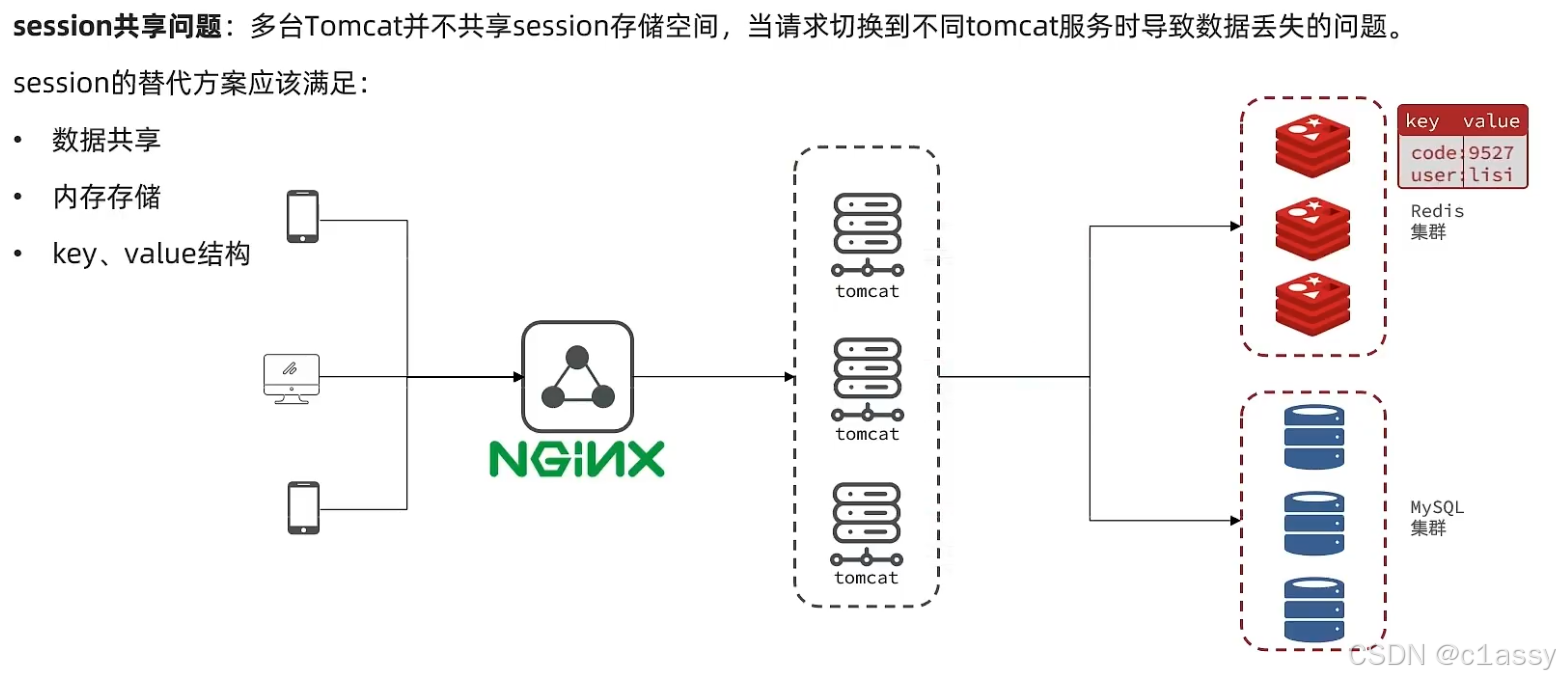
String结构,是JSON形式的,占用多一点空间,如果使用哈希,则他的value中只会存储他数据本身。
在设计这个key的时候,我们之前讲过需要满足两点
1、key要具有唯一性
2、key要方便携带
在后台生成一个随机串token,然后让前端带来这个token就能完成我们的整体逻辑了
// 7.1.随机生成token,作为登录令牌
String token = UUID.randomUUID().toString(true);
public class RefreshTokenInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取请求头中的token
String token = request.getHeader("authorization");
if (StrUtil.isBlank(token)) {
return true;
}
// 2.基于TOKEN获取redis中的用户
String key = LOGIN_USER_KEY + token;
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(key);
// 3.判断用户是否存在
if (userMap.isEmpty()) {
return true;
}
// 5.将查询到的hash数据转为UserDTO
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
// 6.存在,保存用户信息到 ThreadLocal
UserHolder.saveUser(userDTO);
// 7.刷新token有效期
stringRedisTemplate.expire(key, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 移除用户
UserHolder.removeUser();
}
}
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.判断是否需要拦截(ThreadLocal中是否有用户)
if (UserHolder.getUser() == null) {
// 没有,需要拦截,设置状态码
response.setStatus(401);
// 拦截
return false;
}
// 有用户,则放行
return true;
}
}
缓存
缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码(例如:
例1:Static final ConcurrentHashMap<K,V> map = new ConcurrentHashMap<>(); 本地用于高并发
例2:static final Cache<K,V> USER_CACHE = CacheBuilder.newBuilder().build(); 用于redis等缓存
例3:Static final Map<K,V> map = new HashMap(); 本地缓存
由于其被Static修饰,所以随着类的加载而被加载到内存之中,作为本地缓存,由于其又被final修饰,所以其引用(例3:map)和对象(例3:new HashMap())之间的关系是固定的,不能改变,因此不用担心赋值(=)导致缓存失效;
应用层缓存:可以分为tomcat本地缓存,比如之前提到的map,或者是使用redis作为缓存
数据库缓存:在数据库中有一片空间是 buffer pool,增改查数据都会先加载到mysql的缓存中
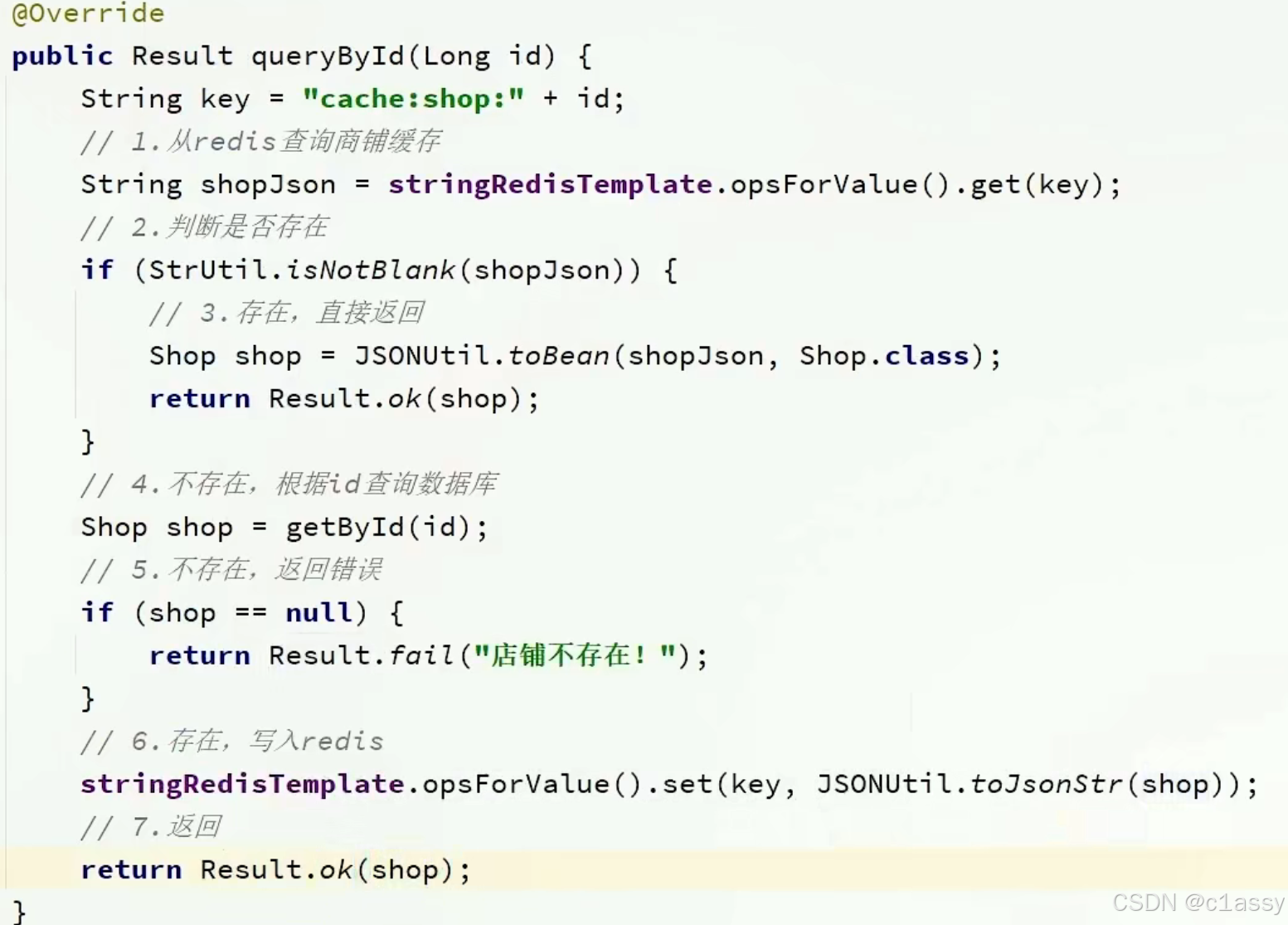
2.2 添加商户缓存
如果缓存有,则直接返回,如果缓存不存在,则查询数据库,然后存入redis。
2.3 缓存更新策略
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,所以redis会对部分数据进行更新,或者把他叫为淘汰更合适。
内存淘汰:redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
超时剔除:当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
主动更新:我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题

2.3.1 数据库缓存不一致解决方案:
数据库中数据发生变化,而缓存却没有同步,此时就会有一致性问题存在
Cache Aside Pattern 人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案
Read/Write Through Pattern : 由系统本身完成,数据库与缓存的问题交由系统本身去处理
Write Behind Caching Pattern :调用者只操作缓存,其他线程去异步处理数据库,实现最终一致
如果采用第一个方案,那么假设我们每次操作数据库后,都操作缓存,但是中间如果没有人查询,那么这个更新动作实际上只有最后一次生效,中间的更新动作意义并不大,我们可以把缓存删除,等待再次查询时,将缓存中的数据加载出来
-
删除缓存还是更新缓存?
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存
-
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
先操作缓存还是先操作数据库?
先操作缓存还是先操作数据库?
- 先删除缓存,再操作数据库-----会导致> 这样缓存里面就是未更新数据库的值
- 先操作数据库,再删除缓存
要先操作数据库,再删除缓存
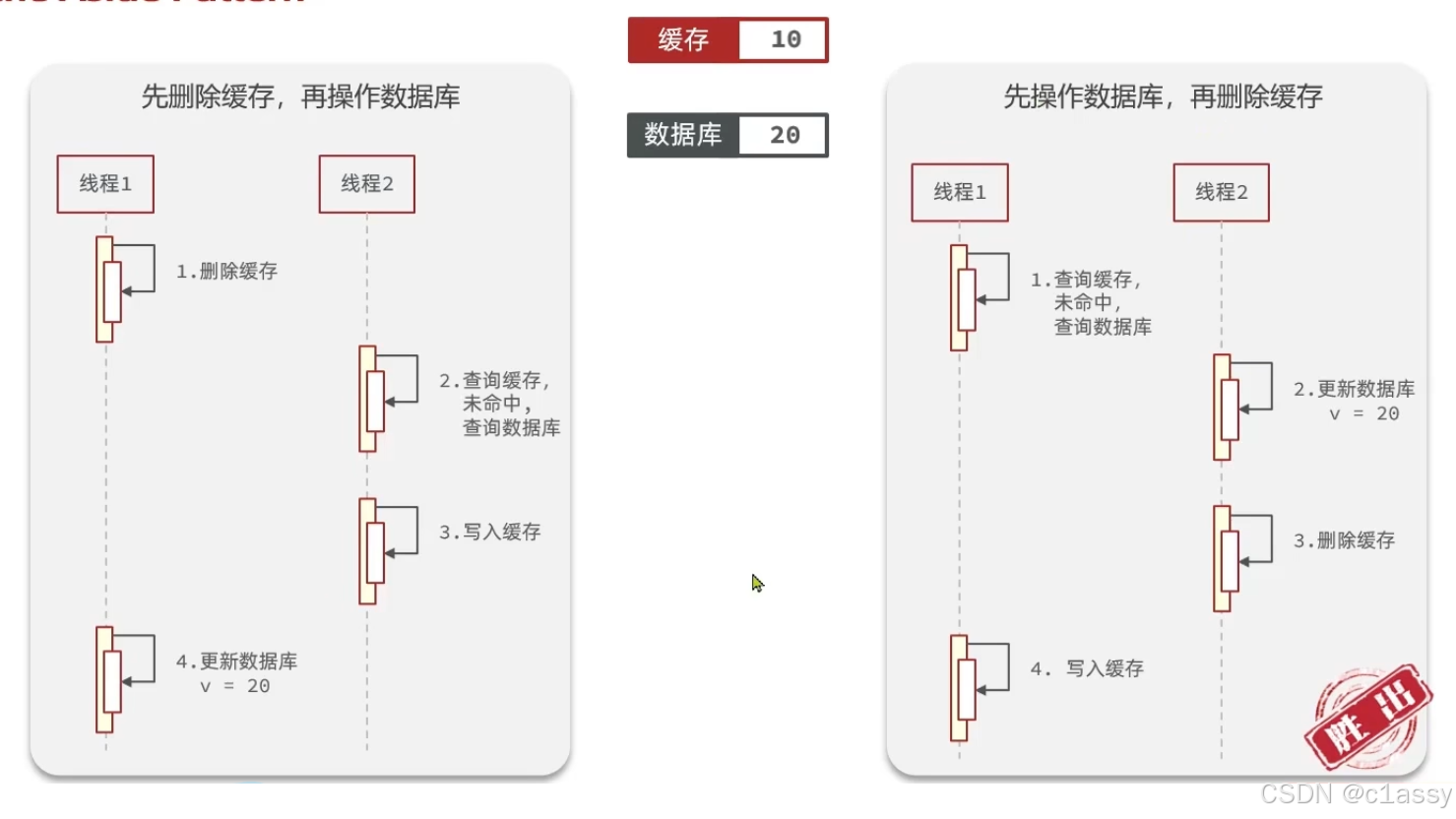
在分布式系统或高并发场景中,先操作数据库,再删除缓存是一种常见的缓存一致性策略,主要是为了避免数据不一致问题。以下是原因及详细解释:
-
操作顺序的重要性
- 如果您 先删除缓存,再更新数据库,可能会导致缓存和数据库的数据不一致。
- 假设以下场景:
- 线程 A 读取缓存,发现缓存已被删除。
- 线程 A 查询数据库,获取旧数据,并重新写入缓存。
- 此时,线程 B 更新数据库,使得缓存中的数据变成了过期数据。
- 这会导致缓存和数据库之间的数据不一致问题。
-
为什么要先操作数据库,再删除缓存
先更新数据库,确保数据是最新的,然后删除缓存,防止旧数据继续被使用。
- 数据库是权威数据来源:通过先更新数据库,保证持久化存储中的数据始终是正确的。
- 删除缓存避免脏数据:在更新完数据库之后,再删除缓存,确保后续的读取操作会触发缓存重新加载,从数据库获取最新数据。
- 常见的时序问题
即使采用“先操作数据库,再删除缓存”的策略,也可能出现并发问题,比如:
- 线程 A 更新数据库并删除缓存;
- 同时,线程 B 读取缓存发现为空,去数据库读取旧数据并写入缓存(因为线程 A 的事务未提交)。
- 解决时序问题的进一步优化
为了解决并发导致的缓存不一致问题,可以使用以下方法:
(1)延时双删策略- 在删除缓存后,短时间内再次删除缓存,确保缓存中没有旧数据:
updateDatabase();
deleteCache();
Thread.sleep(delay); // 等待数据库事务提交
deleteCache(); // 再次删除缓存
(2)异步消息队列更新
- 使用消息队列确保缓存和数据库的一致性:
- 更新数据库后,发送删除缓存的消息到消息队列;
- 消费者监听消息队列,执行缓存删除操作。
(3)分布式锁
- 在操作缓存和数据库前,使用分布式锁,确保同一时间只有一个线程操作数据库和缓存。
- 如果反过来操作(先删缓存再改数据库)
可能会导致缓存数据被提前写回,出现脏数据问题:- 缓存被删除后,其他线程可能立即查询数据库并重建缓存。
- 如果这时数据库还没更新,查询的将是旧数据,导致脏数据写回缓存。
- 总结
- 先操作数据库,再删除缓存 是为了避免缓存中出现脏数据。
- 常见优化策略包括:延时双删、消息队列同步、分布式锁等。
- 此方法的核心思想是:以数据库为准,确保缓存一致性,同时减少并发问题的发生。
2.4 实现商铺和缓存与数据库双写一致
核心思路如下:
修改ShopController中的业务逻辑,满足下面的需求:
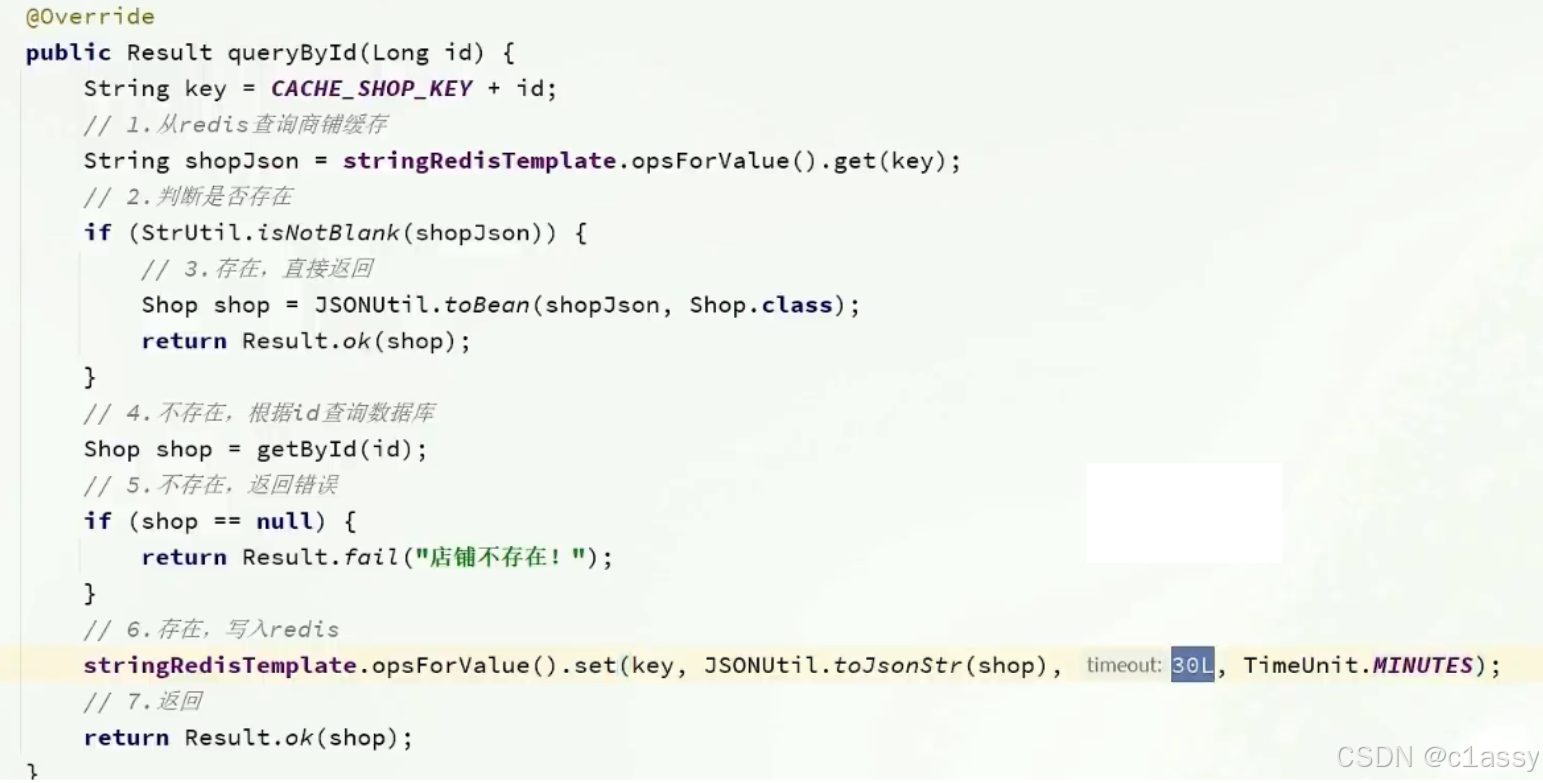
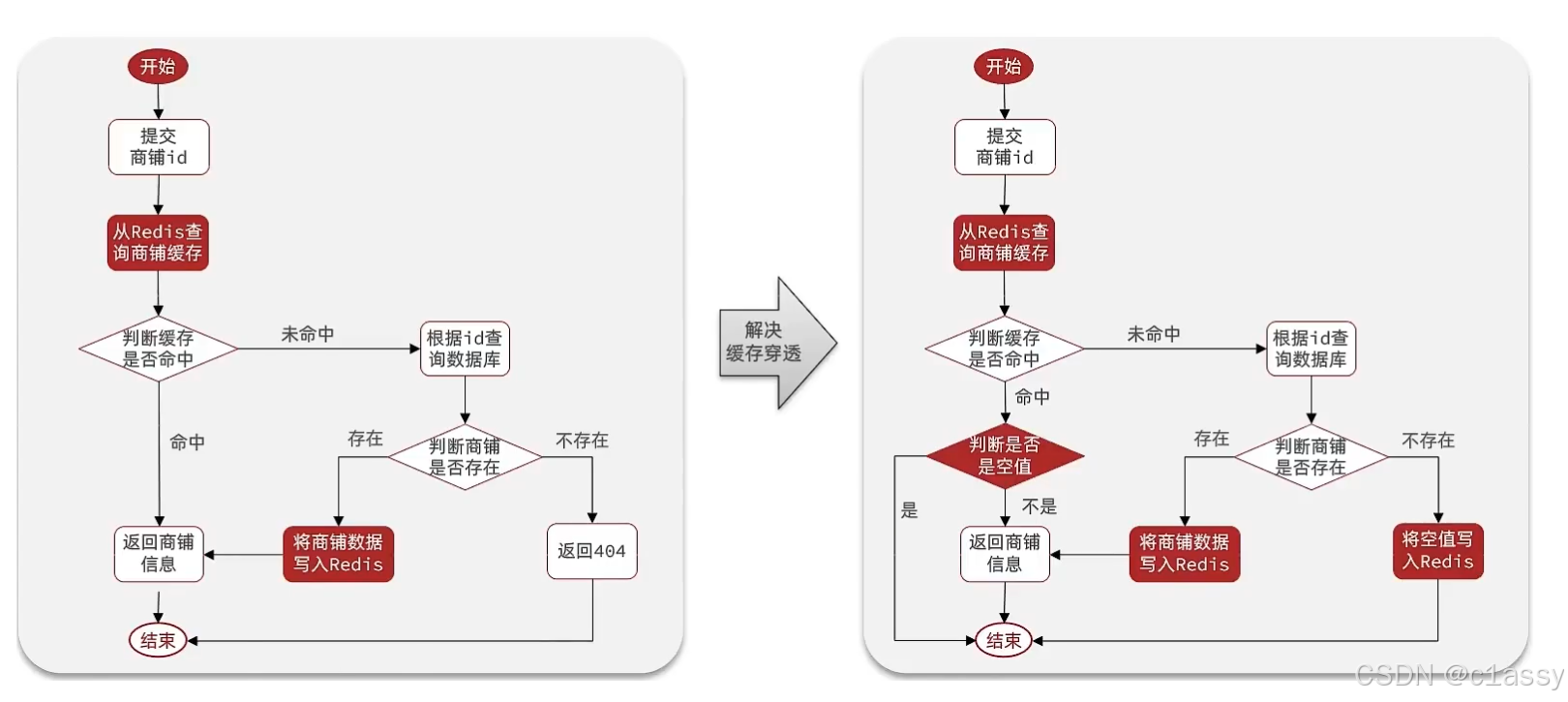
根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
根据id修改店铺时,先修改数据库,再删除缓存
2.5 缓存穿透问题的解决思路
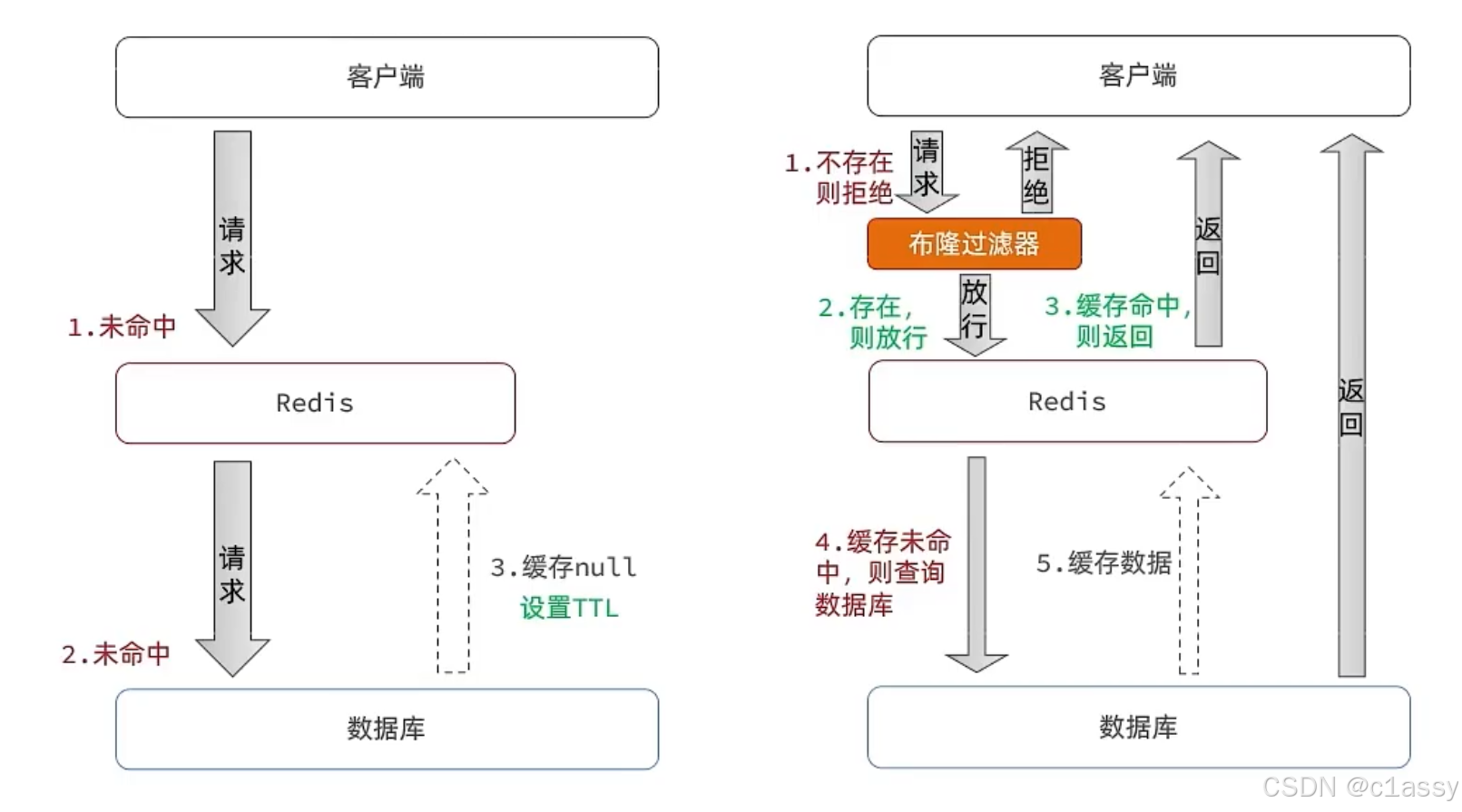
缓存穿透 :指用户请求的数据既不在缓存中,也不在数据库中,这样的请求绕过了缓存,直接访问了数据库,造成了不必要的数据库查询压力。缓存穿透的原因通常是由于某些请求访问了不存在的数据,导致每次都访问数据库,从而导致缓存的失效。
常见的解决方案有两种:
- 缓存空对象:即使某个数据在数据库中不存在,我们也把这个数据的“空值”缓存到 Redis 或其他缓存中,这样下一次请求该数据时,就不需要再查询数据库,而是直接从缓存中获取空值,减少不必要的数据库压力。
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
- 布隆过滤:通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能(Hash值一样,好的Hash函数可能性为0)
缓存穿透的解决方案有哪些?
- 缓存null值
- 布隆过滤
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
2.7 缓存雪崩问题及解决思路
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存

2.8 缓存击穿问题及解决思路
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
- 互斥锁
- 逻辑过期
a.数据库与缓存数据不一致,导致多线程安全问题
根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
根据id修改店铺时,先修改数据库,再删除缓存。等下一次再来查询数据时,再从数据库中加载到缓存中。
b.缓存穿透:布隆过滤器实现较为复杂所以就用了缓存空对象的方法。
先从前台提交要查询的商户id,打到redis中判断是否命中缓存,如果redis中命中缓存了,再判断缓存是否是空值,如果是的话,直接结束查询,不是的话就返回数据。如果redis没有命中的话,就来到数据库中查询,在数据库中查询到了数据,便将数据写入缓存,同时返回数据。如果没有的话,直接将空数据写入缓存,结束查询。
c.缓存击穿热key问题–>逻辑过期的实现:把过期时间设置在 redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。Redisson 提供了分布式锁机制,可以在缓存失效后,确保只有一个线程能够更新缓存,从而避免大量请求直接击中数据库
3、优惠卷秒杀
每个店铺都可以发布优惠券:
当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增ID就存在一些问题:
3.1 -SnowFlake算法来生成分布式环境下的全局唯一ID
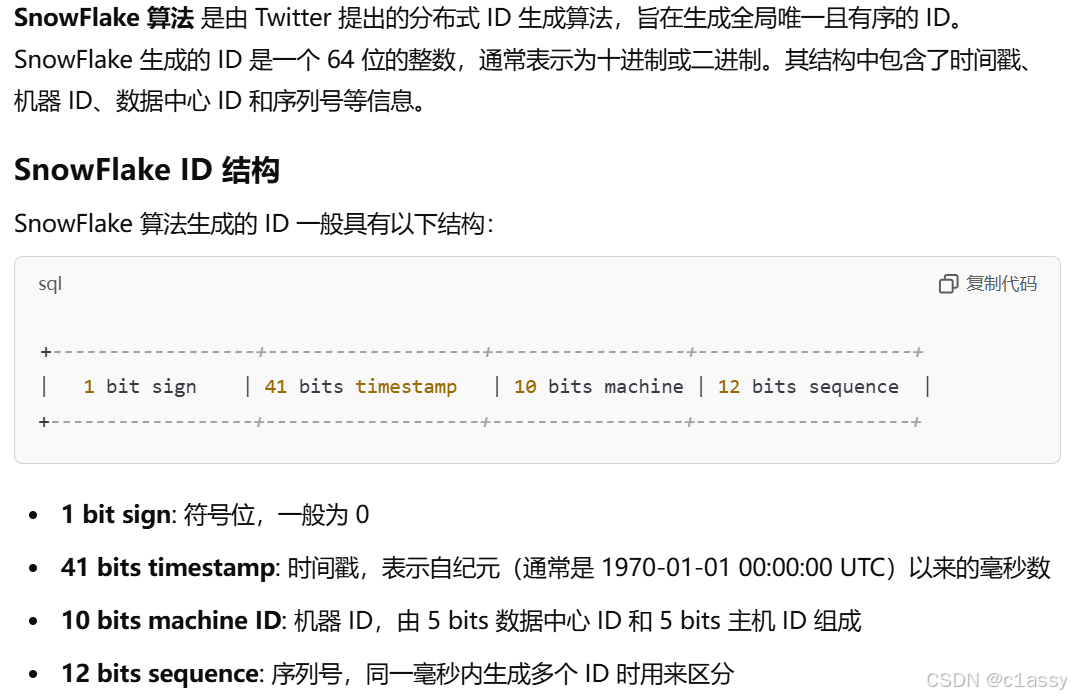
getId()方法就是生成一个唯一ID的入口,每次调用这个方法时,都会返回一个由SnowFlake实例生成的ID。实现了SnowFlake算法的单例模式,保证了ID生成器在多线程环境下的唯一性和线程安全。
3.3 添加优惠卷
每个店铺都可以发布优惠券,分为平价券和特价券。平价券可以任意购买,而特价券需要秒杀抢购:
tb_voucher:优惠券的基本信息,优惠金额、使用规则等
tb_seckill_voucher:优惠券的库存、开始抢购时间,结束抢购时间。特价优惠券才需要填写这些信息
平价卷由于优惠力度并不是很大,所以是可以任意领取
而代金券由于优惠力度大,所以像第二种卷,就得限制数量,从表结构上也能看出,特价卷除了具有优惠卷的基本信息以外,还具有库存,抢购时间,结束时间等等字段

3.4 实现秒杀下单
当用户开始进行下单,我们应当去查询优惠卷信息,查询到优惠卷信息,判断是否满足秒杀条件
比如时间是否充足,如果时间充足,则进一步判断库存是否足够,如果两者都满足,则扣减库存,创建订单,然后返回订单id,如果有一个条件不满足则直接结束。
3.5 库存超卖问题分析
超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁:而对于加锁,我们通常有两种解决方案:
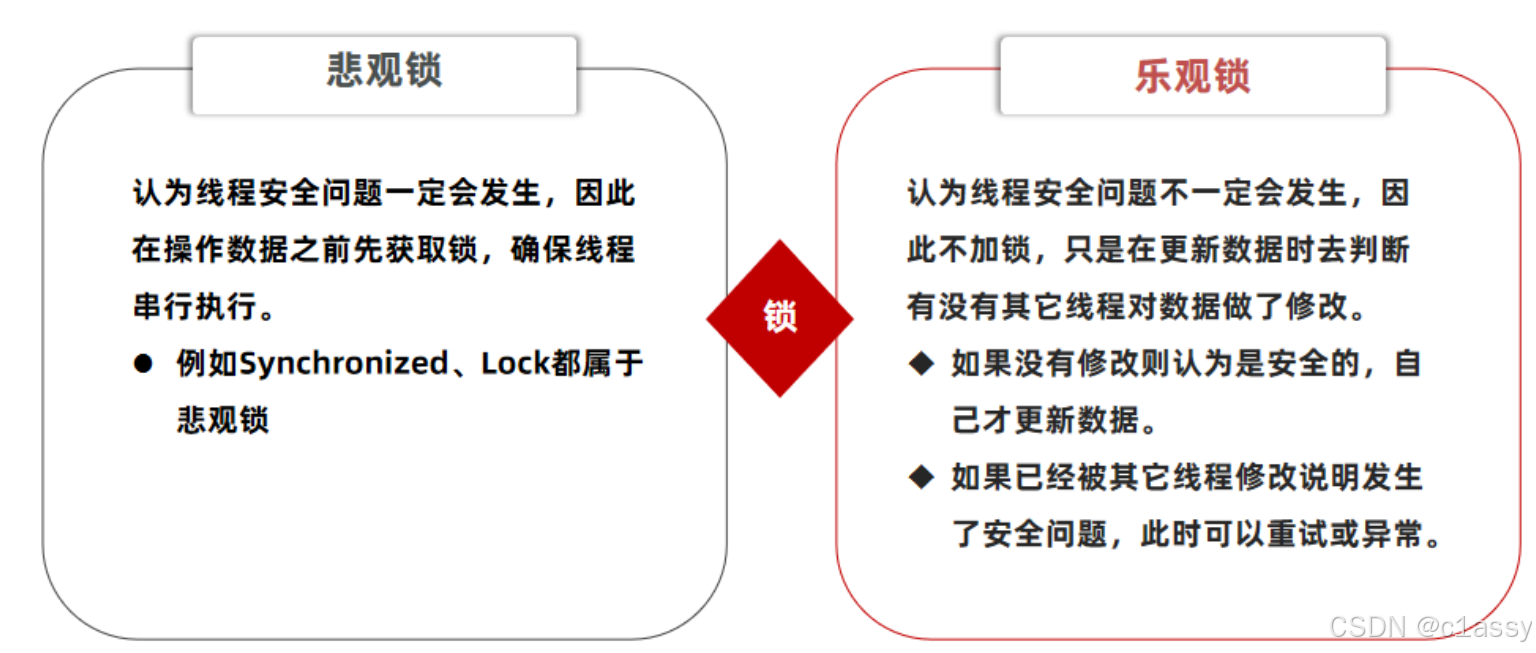
悲观锁:
悲观锁可以实现对于数据的串行化执行,比如syn,和lock都是悲观锁的代表,同时,悲观锁中又可以再细分为公平锁,非公平锁,可重入锁,等等
乐观锁:
乐观锁:会有一个版本号,每次操作数据会对版本号+1,再提交回数据时,会去校验是否比之前的版本大1 ,如果大1 ,则进行操作成功,这套机制的核心逻辑在于,如果在操作过程中,版本号只比原来大1 ,那么就意味着操作过程中没有人对他进行过修改,他的操作就是安全的,如果不大1,则数据被修改过,当然乐观锁还有一些变种的处理方式比如cas
乐观锁的典型代表:就是cas,利用cas进行无锁化机制加锁,var5 是操作前读取的内存值,while中的var1+var2 是预估值,如果预估值 == 内存值,则代表中间没有被人修改过,此时就将新值去替换 内存值
其中do while 是为了在操作失败时,再次进行自旋操作,即把之前的逻辑再操作一次。


3.6 优惠券秒杀-一人一单
让一个用户只能下一个单
4、分布式锁
可见性:多个线程都能看到相同的结果,注意:这个地方说的可见性并不是并发编程中指的内存可见性,只是说多个进程之间都能感知到变化的意思
互斥:互斥是分布式锁的最基本的条件,使得程序串行执行
高可用:程序不易崩溃,时时刻刻都保证较高的可用性
高性能:由于加锁本身就让性能降低,所有对于分布式锁本身需要他就较高的加锁性能和释放锁性能
Zookeeper:zookeeper也是企业级开发中较好的一个实现分布式锁的方案
4.2 、Redis分布式锁的实现核心思路
实现分布式锁时需要实现的两个基本方法:
-
获取锁:
- 互斥:确保只能有一个线程获取锁
- 非阻塞:尝试一次,成功返回true,失败返回false
-
释放锁:
- 手动释放
- 超时释放:获取锁时添加一个超时时间
核心思路:
我们利用redis 的setnx方法,当有多个线程进入时,我们就利用该方法,第一个线程进入时,redis 中就有这个key 了,返回了1,如果结果是1,则表示他抢到了锁,那么他去执行业务,然后再删除锁,退出锁逻辑,没有抢到锁的哥们,等待一定时间后重试即可
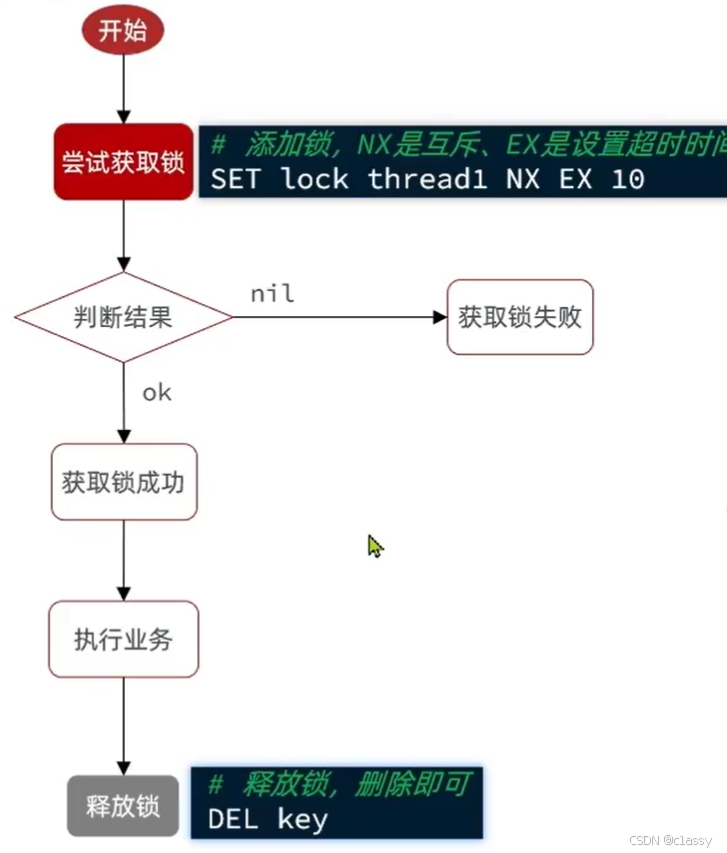
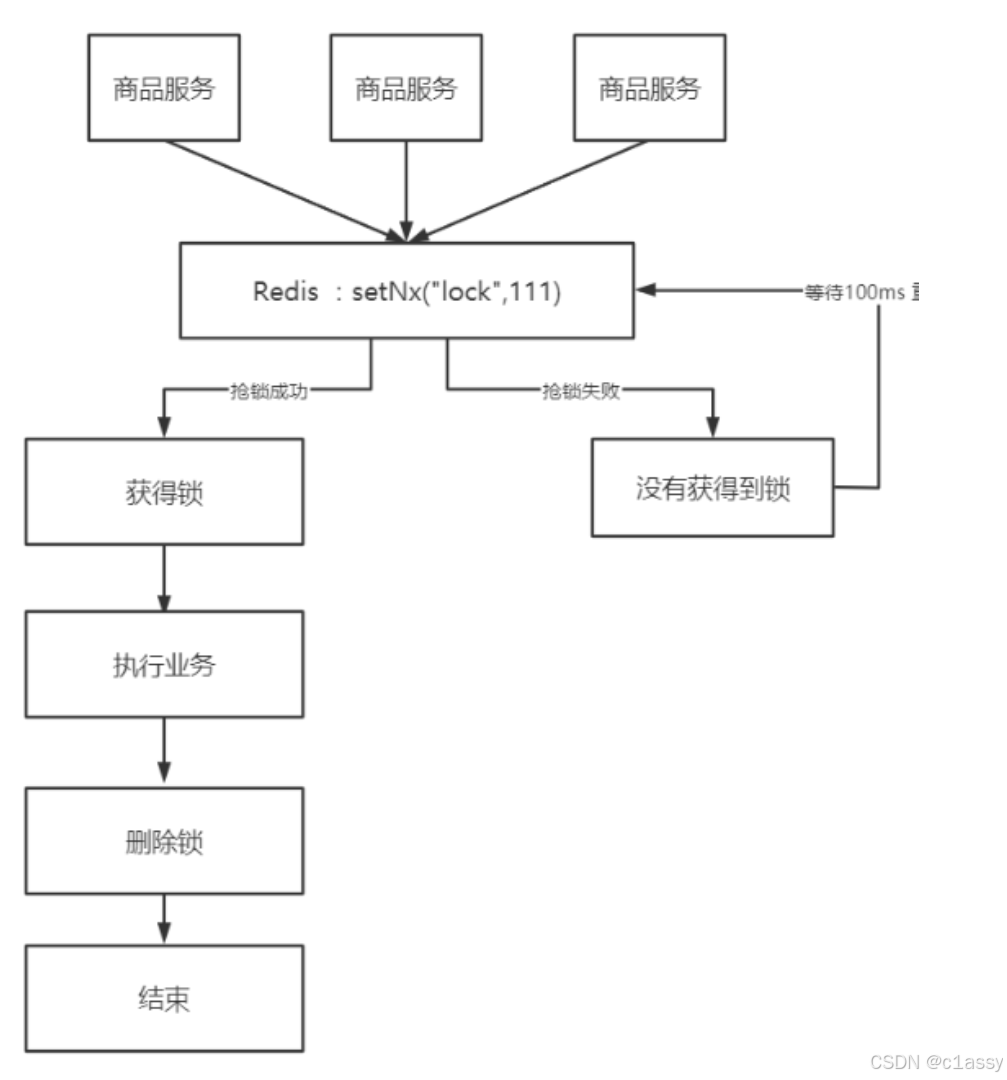
setnx
SETNX(Set if Not Exists)是 Redis 提供的一种原子操作,常用来实现分布式锁。通过 Redis 的 SETNX 命令,可以确保只有一个客户端能成功设置某个 key,从而实现分布式锁的效果。它是通过设置一个特定的 key 来锁定一个资源,其他客户端在尝试获取锁时会发现该 key 已经存在,因此无法获取锁。
使用 SETNX 实现分布式锁
在分布式系统中,多个服务实例可能同时尝试访问共享资源。通过分布式锁,可以保证同一时间只有一个实例能访问该资源。Redis 的 SETNX 操作常常用于这种场景。
基本思路:
- 客户端尝试通过
SETNX设置一个唯一的锁标识符(通常是一个随机值或者唯一标识符)。 - 如果
SETNX返回 1,表示获取锁成功;如果返回 0,表示锁已经存在,获取锁失败。 - 锁的有效期一般会设置为一个合理的超时(如 10 秒),以防止由于服务故障或异常导致锁永远无法释放。
1. 使用 SETNX 实现分布式锁的基本步骤
-
客户端尝试获取锁
- 使用
SETNX命令设置一个唯一的锁标识符(key)。 - 如果
SETNX返回 1,表示成功获取锁。 - 如果返回 0,表示锁已存在,尝试重新获取锁或失败。
- 使用
-
设置锁的有效期
- 使用
EXPIRE或者SET命令来设置锁的超时,防止死锁。例如,如果没有在规定时间内释放锁,则自动过期。
- 使用
-
释放锁
- 使用
DEL删除锁的 key 来释放锁。需要注意的是,在释放锁时必须保证只有持有锁的客户端能删除该锁的 key,以防止其他客户端错误地释放锁。
- 使用
2. Redis 实现分布式锁的代码示例(使用 Java)
假设我们要使用 Java 来实现 Redis 分布式锁,首先确保你有一个 Redis 客户端库,像是 Jedis 或者 Lettuce。
使用 Jedis 实现分布式锁
首先需要在项目中添加 Jedis 依赖:
<!-- pom.xml -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.6.0</version>
</dependency>
接下来是分布式锁的实现代码:
import redis.clients.jedis.Jedis;
import java.util.UUID;
public class RedisLock {
private Jedis jedis;
private static final String LOCK_KEY = "distributed_lock";
public RedisLock(Jedis jedis) {
this.jedis = jedis;
}
// 获取锁
public boolean acquireLock(String lockValue, int lockTimeout) {
// 通过 SETNX 命令获取锁
long result = jedis.setnx(LOCK_KEY, lockValue);
if (result == 1) {
// 如果设置成功,锁被获取,设置锁的超时时间
jedis.expire(LOCK_KEY, lockTimeout);
return true;
}
// 如果锁已经被其他客户端获取,则返回 false
return false;
}
// 释放锁
public boolean releaseLock(String lockValue) {
// 获取锁的值
String currentValue = jedis.get(LOCK_KEY);
// 判断锁是否被当前客户端持有
if (currentValue != null && currentValue.equals(lockValue)) {
jedis.del(LOCK_KEY); // 删除锁
return true;
}
return false; // 锁不属于当前客户端,无法释放
}
public static void main(String[] args) {
// 创建 Jedis 客户端
Jedis jedis = new Jedis("localhost", 6379);
// 创建锁实例
RedisLock lock = new RedisLock(jedis);
// 使用 UUID 作为唯一锁标识
String lockValue = UUID.randomUUID().toString();
// 获取锁(超时设置为 10 秒)
if (lock.acquireLock(lockValue, 10)) {
System.out.println("Successfully acquired lock!");
// 执行某些操作...
// 释放锁
if (lock.releaseLock(lockValue)) {
System.out.println("Successfully released lock!");
} else {
System.out.println("Failed to release lock!");
}
} else {
System.out.println("Failed to acquire lock!");
}
jedis.close(); // 关闭 Redis 连接
}
}
3. 锁的超时问题和改进
- 锁的超时: 上述代码设置了一个超时来避免死锁。当获取锁成功后,设置了
expire来自动释放锁。如果客户端在处理资源时发生异常或服务崩溃,锁将在超时后自动释放,避免死锁。 - 锁值的唯一性: 使用
UUID作为锁的值,以确保每个客户端的锁都是唯一的,避免其他客户端误释放锁。 - 检测锁是否超时: 如果你的业务需要获取锁的客户端对锁进行检查,也可以在每次获取锁时,使用
GET命令检查当前锁的值。
4. Redis 分布式锁的注意事项
- 死锁: 如果客户端获取锁后没有及时释放,且没有设置超时机制,可能会导致死锁。因此,锁应该有有效期,避免由于服务宕机等问题导致无法释放锁。
- 锁粒度: 锁的粒度不应太粗或太细。锁的粒度过大可能导致性能下降,粒度过小则可能导致多次锁争用。
- 分布式环境下的原子操作: 使用 Redis 提供的原子操作(如
SETNX)保证分布式锁的正确性和性能。
总结:
SETNX是实现分布式锁的基础命令,通过它可以实现原子性操作来控制锁的获取。- 确保设置锁的有效期,防止死锁。
- 使用
UUID确保锁值的唯一性,防止误释放锁。
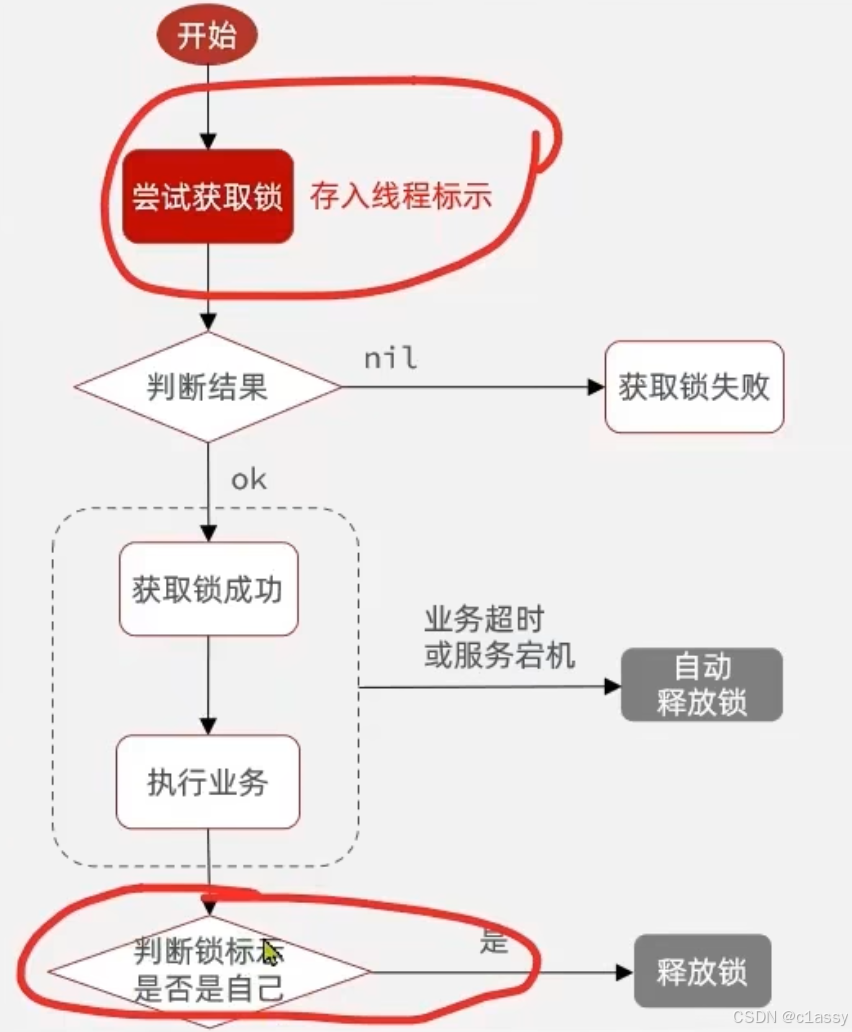
4.4 Redis分布式锁误删情况说明
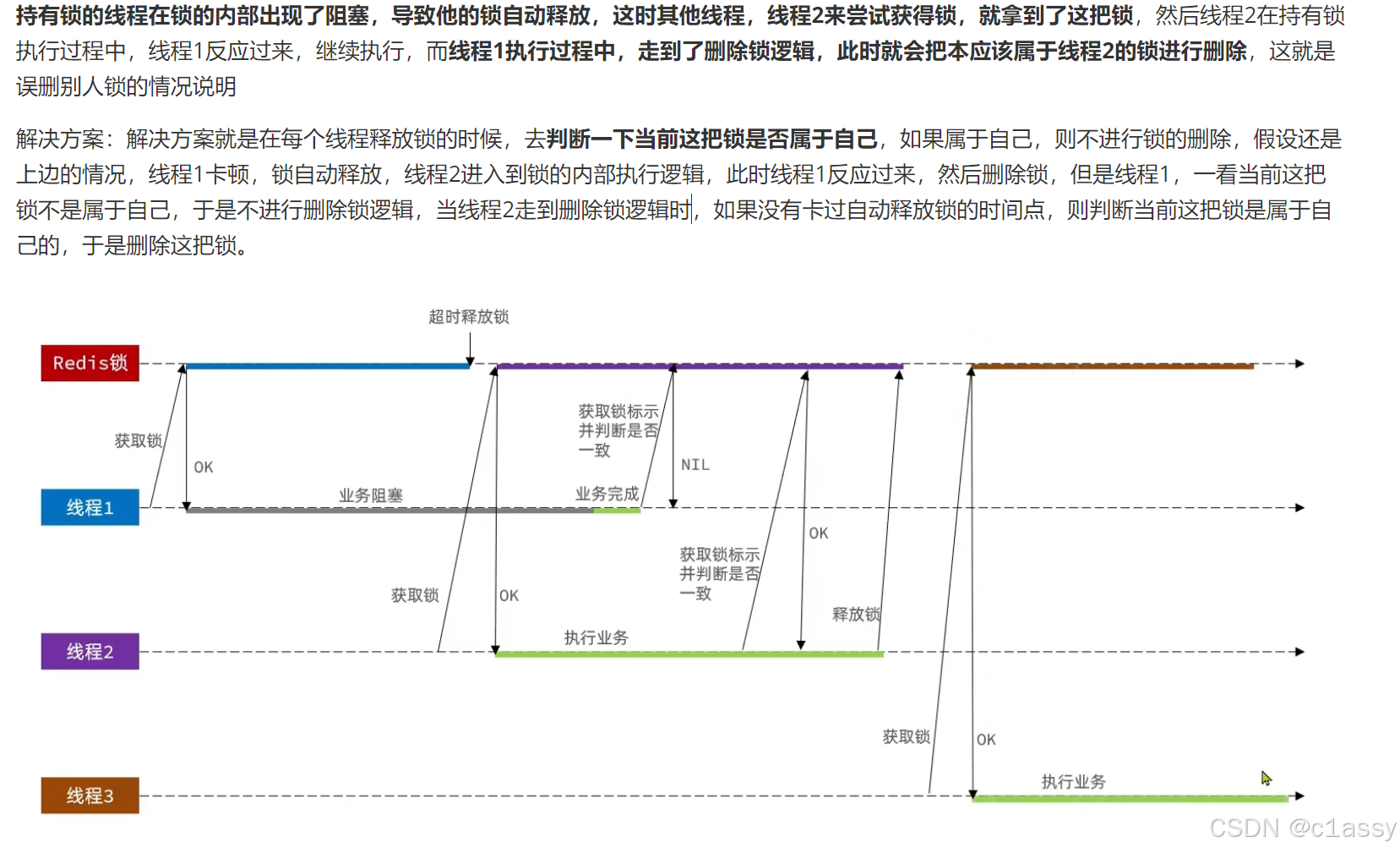
4.5 解决Redis分布式锁误删问题
需求:修改之前的分布式锁实现,满足:在获取锁时存入线程标示(可以用UUID表示)
在释放锁时先获取锁中的线程标示,判断是否与当前线程标示一致
- 如果一致则释放锁
- 如果不一致则不释放锁
核心逻辑:在存入锁时,放入自己线程的标识,在删除锁时,判断当前这把锁的标识是不是自己存入的,如果是,则进行删除,如果不是,则不进行删除。
uuid是用来区分不同jvm的,同一个jvm使用一个uuid
具体代码如下:加锁
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
4.7 Lua脚本解决多条命令原子性问题
因为线程1的拿锁,比锁,删锁,实际上并不是原子性的
redis.call(‘命令名称’, ‘key’, ‘其它参数’, …)
JAVA:RedisTemplate中,可以利用execute方法去执行lua脚本
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.core.script.RedisScript;
public class RedisService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public void executeLuaScript() {
// 创建Lua脚本
String script = "if redis.call('exists', KEYS[1]) == 0 then redis.call('set', KEYS[1], ARGV[1]) end return redis.call('incrby', KEYS[2], ARGV[2])";
// 创建一个DefaultRedisScript对象来指定返回值类型
RedisScript<Long> redisScript = new DefaultRedisScript<>(script, Long.class);
// 执行Lua脚本
Long result = redisTemplate.execute(redisScript, Arrays.asList("user:123", "user:123:score"), "John", 10);
// 输出执行结果
System.out.println("Result: " + result);
}
}
5、分布式锁-redisson
以后用分布式锁直接用redisson


GPT. Redis 分布式锁的改进(使用 Redisson)
如果需要更为健壮的分布式锁管理,可以使用 Redisson,它是一个基于 Redis 的 Java 客户端,提供了丰富的分布式锁 API。Redisson 提供了更高级的功能,比如可重入锁、锁的等待超时等,适合大规模分布式应用。
<!-- pom.xml -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.1</version>
</dependency>
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.client.codec.StringCodec;
import org.redisson.config.Config;
public class RedissonLockExample {
public static void main(String[] args) throws InterruptedException {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("distributed_lock");
lock.lock();
try {
// 执行任务
System.out.println("Lock acquired, executing task...");
Thread.sleep(5000);
} finally {
lock.unlock();
}
redisson.shutdown();
}
}
Redisson 封装了很多 Redis 锁的高级功能,推荐用于需要更高并发和可靠性的应用。
5.1 分布式锁-redission功能介绍
分布式锁–redisson中:
Redisson提供了.分布式锁的多种多样功能
可重入锁(Reentrant Lock)
公平锁(Fair Lock)…
5.3 分布式锁-redission可重入锁原理
在Lock锁中,他是借助于底层的一个voaltile的一个state变量来记录重入的状态的,比如当前没有人持有这把锁,那么state=0,假如有人持有这把锁,那么state=1,如果持有这把锁的人再次持有这把锁,那么state就会+1 ,如果是对于synchronized而言,他在c语言代码中会有一个count,原理和state类似,也是重入一次就加一,释放一次就-1 ,直到减少成0 时,表示当前这把锁没有被人持有。
5.4 分布式锁-redission锁重试和WatchDog机制
在分布式系统中,为了避免多个节点同时执行相同任务,常常会使用分布式锁来确保任务的唯一性和顺序性。Redisson 是一种常见的分布式锁实现,它基于 Redis 提供了分布式锁的功能,并且支持一些高级特性,例如锁重试和 WatchDog 机制。
1. Redisson 锁重试机制 (Lock Retry Mechanism)
Redisson 提供了锁重试机制,允许在尝试获取锁失败时进行重试。这个机制可以有效防止因为锁竞争而导致的长时间阻塞,并且避免了死锁的发生。
-
tryLock(long waitTime, long leaseTime, TimeUnit unit):
Redisson 的tryLock方法可以设置两个重要的时间参数:waitTime:表示如果锁不可用时,最多等待的时间。过了这个时间锁就会放弃。leaseTime:表示锁被持有的最大时间,即锁的过期时间。即使锁的持有者没有释放锁,过期时间到了,锁也会被自动释放。
通过合理设置这些参数,Redisson 可以避免在锁不可用时永久阻塞。若等待时间内锁可用,Redisson 将会成功获得锁,并且在指定的过期时间后自动释放锁。
-
重试机制:
在调用tryLock时,如果锁不可用,Redisson 会继续尝试获取锁,直到重试超时或获取到锁为止。重试的间隔时间通常是随机的,这样可以有效避免多个请求同时争抢锁时造成的“锁碰撞”问题。RLock lock = redisson.getLock("myLock"); // 设定最多等待5秒,每隔1秒重试一次,锁过期时间为10秒 boolean isLocked = lock.tryLock(5, 10, TimeUnit.SECONDS);
2. Redisson WatchDog 机制
Redisson 提供了 WatchDog 机制,它可以确保在持有锁的客户端未显式释放锁的情况下,自动延长锁的有效期,避免因锁超时释放而导致的并发问题。
-
WatchDog 的作用:
WatchDog 主要是为了防止客户端在持有锁的过程中崩溃或者网络中断,导致锁提前释放,造成其他客户端误认为锁已经释放,从而导致并发问题。它会在客户端持有锁时定期更新锁的过期时间。 -
如何使用 WatchDog:
在 Redisson 中,WatchDog 默认启用。当你通过RLock.lock()方法获取锁时,如果持有锁的时间超过设置的过期时间,Redisson 会自动延长锁的过期时间(称为 WatchDog 机制)。如果你手动释放锁(unlock()),WatchDog 也会停止工作。RLock lock = redisson.getLock("myLock"); // 获取锁时会自动启用 WatchDog lock.lock(); try { // 执行任务 } finally { // 释放锁 lock.unlock(); }如果锁被持续持有而没有显式释放,Redisson 会自动延长锁的有效期,直到锁被释放。
-
配置 WatchDog 的时间间隔:
默认情况下,Redisson 会以默认的时间间隔(通常是30秒)更新锁的过期时间。你可以通过配置 WatchDog 的心跳时间,控制它检查并延长锁有效期的频率。Config config = new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6379"); config.setLockWatchdogTimeout(10000); // 设置 WatchDog 超时时间为 10 秒 RedissonClient redisson = Redisson.create(config);
小结
- 锁重试机制可以有效避免锁竞争导致的阻塞,并允许在锁不可用时设置重试策略。
- WatchDog 机制可以避免因客户端崩溃或者锁超时导致的锁提前释放问题,确保锁的过期时间在持有期间得到自动延长。
这两个机制的结合使得 Redisson 在高并发的分布式环境中非常可靠,能够确保锁的公平性和有效性。
5.5 分布式锁-redission锁的MutiLock原理
原理:多个独立的Redis节点,必须在所有节点都获取重入锁,才算获取锁成功
为了提高Redis的可用性,我们会搭建集群或者主从,现在以主从为例
此时我们去写命令,写在主机上,主机会将数据同步给从机,但是假设主机还没来得及把数据写入到从机去的时候,主机宕机了
哨兵会发现主机宕机了,于是选举一个slave(从机)变成master(主机),而此时新的master(主机)上并没有锁的信息,那么其他线程就可以获取锁,又会引发安全问题
为了解决这个问题。Redisson提出来了MutiLock锁,使用这把锁的话,那我们就不用主从了,每个节点的地位都是一样的,都可以当做是主机,那我们就需要将加锁的逻辑写入到每一个主从节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获取锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性
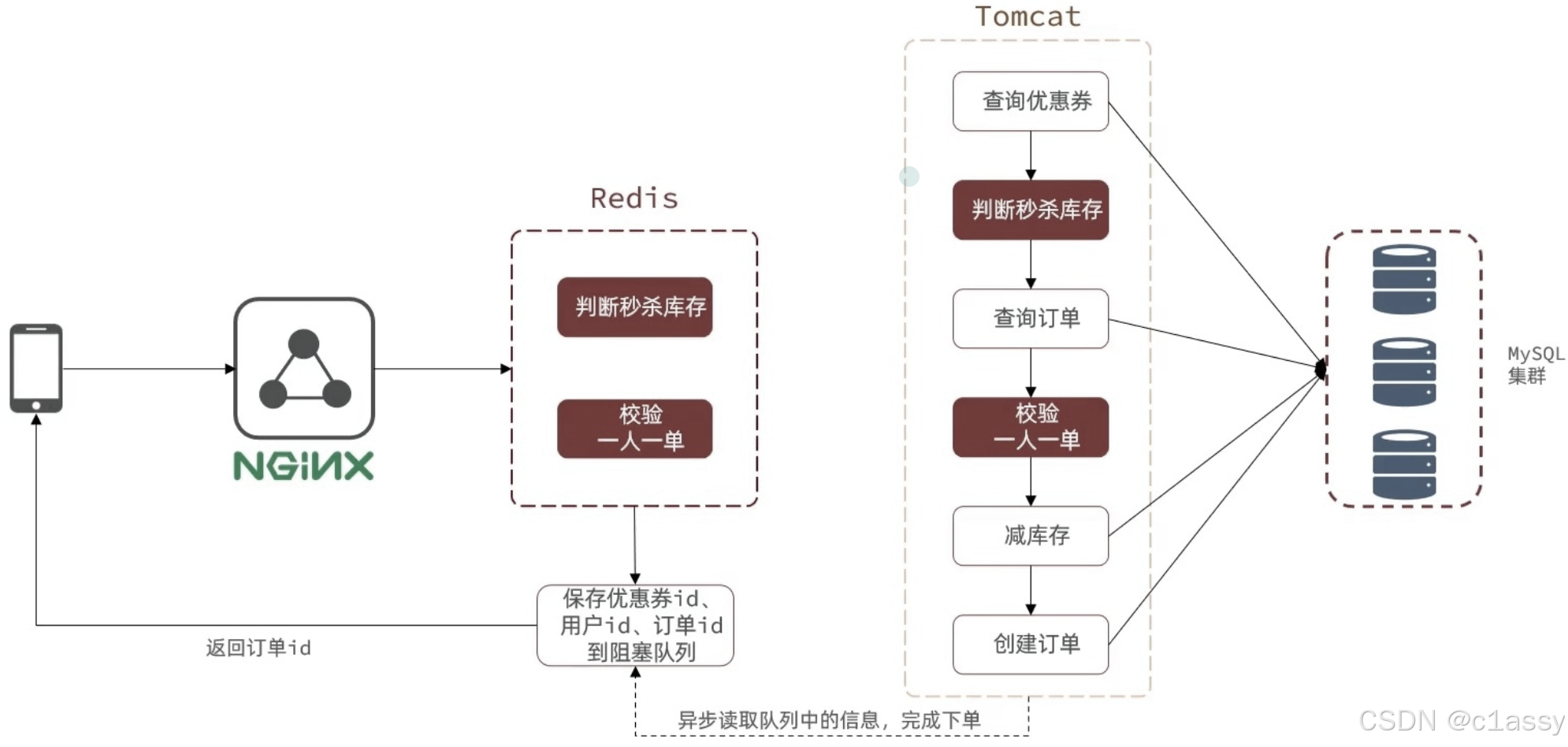
6.秒杀优化
当用户发起请求,此时会先请求Nginx,Nginx反向代理到Tomcat,而Tomcat中的程序,会进行串行操作,分为如下几个步骤
查询优惠券
判断秒杀库存是否足够
查询订单
校验是否一人一单
扣减库存
创建订单
在这六个步骤中,有很多操作都是要去操作数据库的,而且还是一个线程串行执行,这样就会导致我们的程序执行很慢,所以我们需要异步程序执行,那么如何加速呢?
优化方案:我们将耗时较短的逻辑判断放到Redis中,例如:库存是否充足,是否一人一单这样的操作,只要满足这两条操作,那我们是一定可以下单成功的,不用等数据真的写进数据库,我们直接告诉用户下单成功就好了。然后后台再开一个线程,后台线程再去慢慢执行队列里的消息,这样我们就能很快的完成下单业务。
但是这里还存在两个难点
- 我们怎么在Redis中快速校验是否一人一单,还有库存判断
- 我们校验一人一单和将下单数据写入数据库,这是两个线程,我们怎么知道下单是否完成。
我们需要将一些信息返回给前端,同时也将这些信息丢到异步queue中去,后续操作中,可以通过这个id来查询下单逻辑是否完成
我们现在来看整体思路:当用户下单之后,判断库存是否充足,只需要取Redis中根据key找对应的value是否大于0即可,如果不充足,则直接结束。如果充足,则在Redis中判断用户是否可以下单,如果set集合中没有该用户的下单数据,则可以下单,并将userId和优惠券存入到Redis中,并且返回0,整个过程需要保证是原子性的,所以我们要用Lua来操作,同时由于我们需要在Redis中查询优惠券信息,所以在我们新增秒杀优惠券的同时,需要将优惠券信息保存到Redis中
6.2 秒杀优化-Redis完成秒杀资格判断
需求:
-
新增秒杀优惠券的同时,将优惠券信息保存到Redis中
-
基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
-
如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
-
开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
6.3基于阻塞队列实现秒杀优化
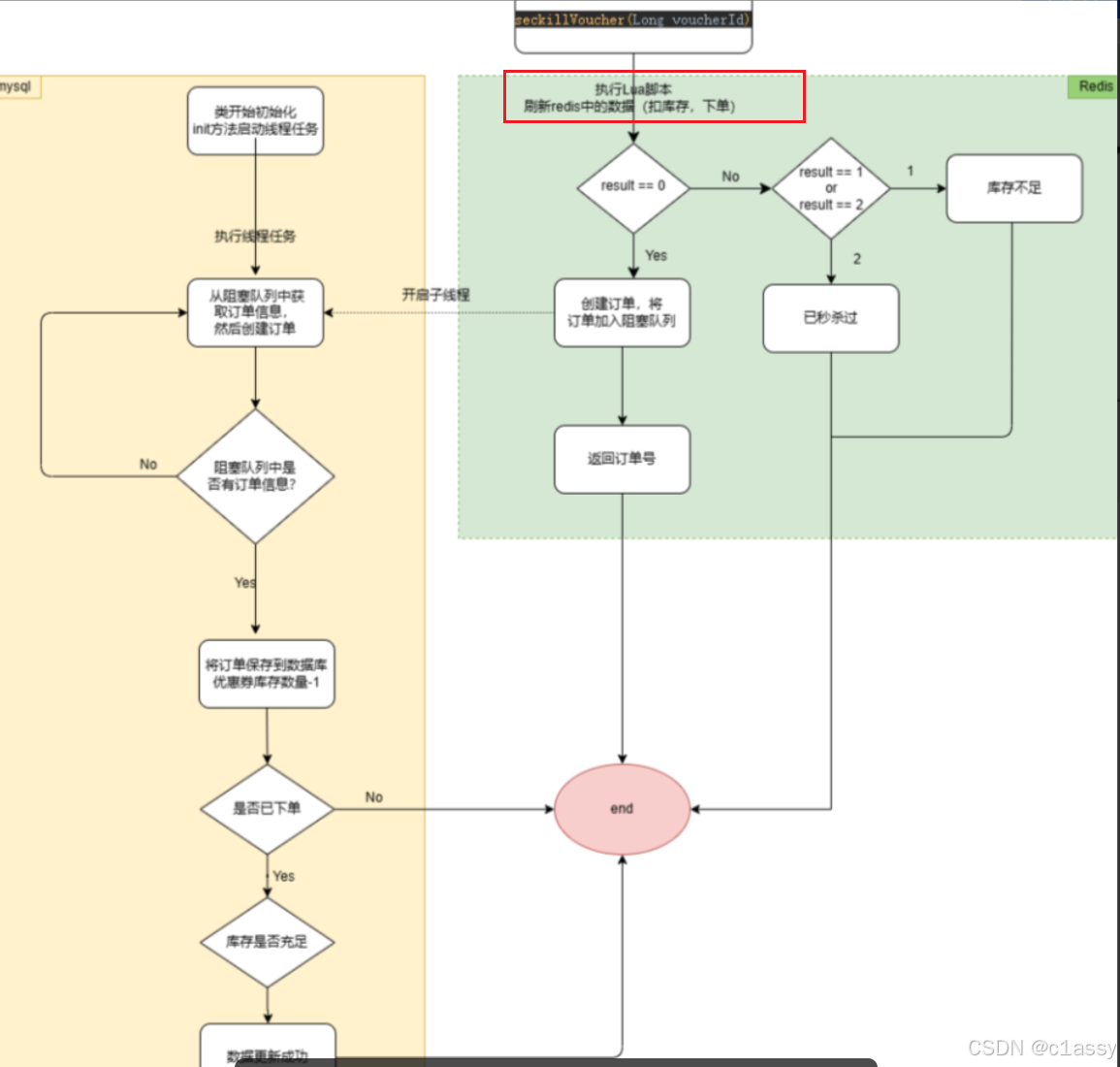
修改下单的操作,我们在下单时,是通过Lua表达式去原子执行判断逻辑,如果判断结果不为0,返回错误信息,如果判断结果为0,则将下单的逻辑保存到队列中去,然后异步执行
阻塞队列
需求:
- 如果秒杀成功,则将优惠券id和用户id封装后存入阻塞队列
- 开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
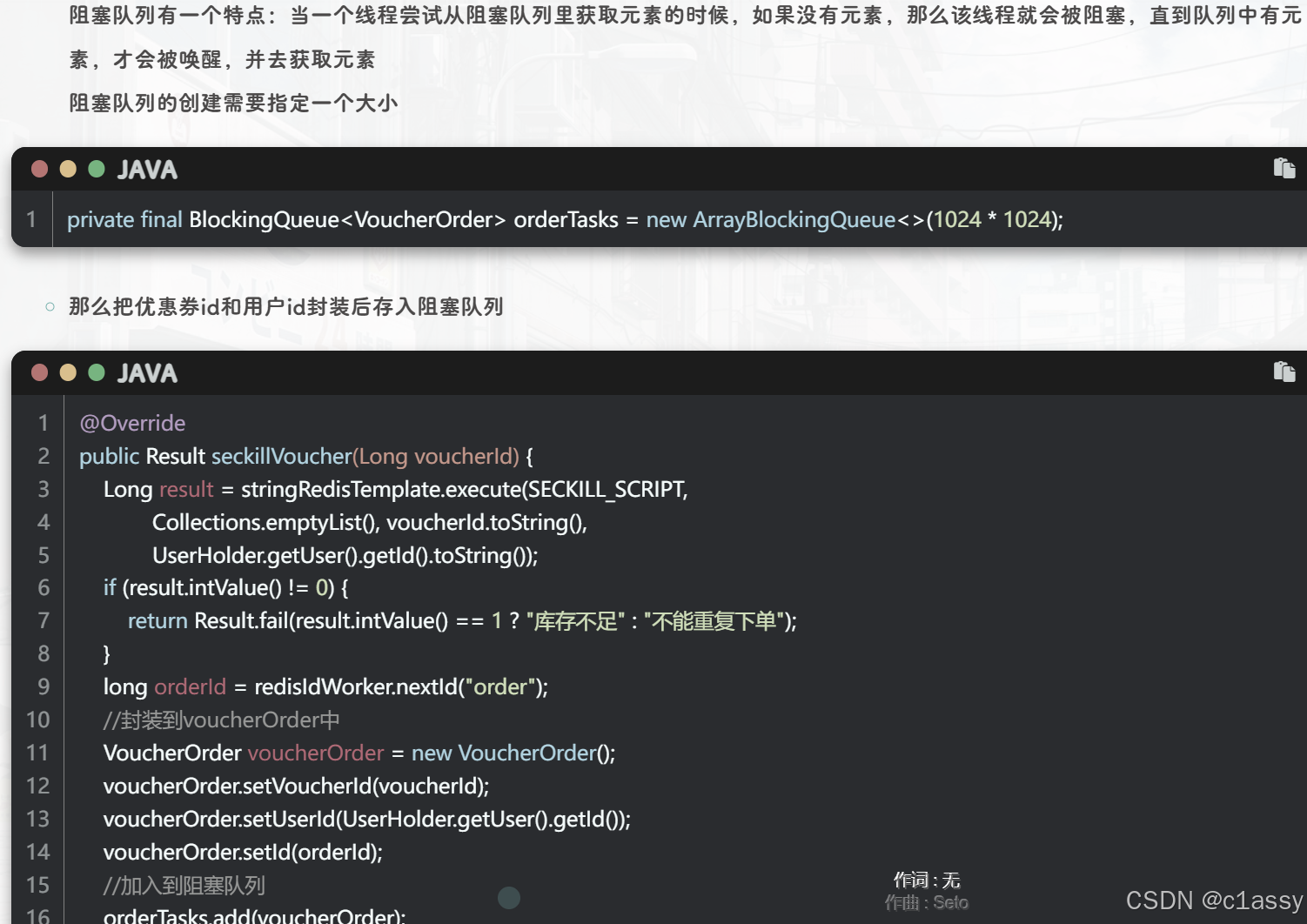
步骤二:实现异步下单功能
先创建一个线程池
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
创建线程任务,秒杀业务需要在类初始化之后,就立即执行,所以这里需要用到@PostConstruct注解
@PostConstruct
private void init() {
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
private class VoucherOrderHandler implements Runnable {
@Override
public void run() {
while (true) {
try {
//1. 获取队列中的订单信息
VoucherOrder voucherOrder = orderTasks.take();
//2. 创建订单
handleVoucherOrder(voucherOrder);
} catch (Exception e) {
log.error("订单处理异常", e);
}
}
}
}
编写创建订单的业务逻辑
private IVoucherOrderService proxy;
private void handleVoucherOrder(VoucherOrder voucherOrder) {
//1. 获取用户
Long userId = voucherOrder.getUserId();
//2. 创建锁对象,作为兜底方案
RLock redisLock = redissonClient.getLock("order:" + userId);
//3. 获取锁
boolean isLock = redisLock.tryLock();
//4. 判断是否获取锁成功
if (!isLock) {
log.error("不允许重复下单!");
return;
}
try {
//5. 使用代理对象,由于这里是另外一个线程,
proxy.createVoucherOrder(voucherOrder);
} finally {
redisLock.unlock();
}
}
查看AopContext源码,它的获取代理对象也是通过ThreadLocal进行获取的,由于我们这里是异步下单,和主线程不是一个线程,所以不能获取成功
private static final ThreadLocal<Object> currentProxy = new NamedThreadLocal("Current AOP proxy");
但是我们可以将proxy放在成员变量的位置,然后在主线程中获取代理对象
@Override
public Result seckillVoucher(Long voucherId) {
Long result = stringRedisTemplate.execute(SECKILL_SCRIPT,
Collections.emptyList(), voucherId.toString(),
UserHolder.getUser().getId().toString());
if (result.intValue() != 0) {
return Result.fail(result.intValue() == 1 ? "库存不足" : "不能重复下单");
}
long orderId = redisIdWorker.nextId("order");
//封装到voucherOrder中
VoucherOrder voucherOrder = new VoucherOrder();
voucherOrder.setVoucherId(voucherId);
voucherOrder.setUserId(UserHolder.getUser().getId());
voucherOrder.setId(orderId);
//加入到阻塞队列
orderTasks.add(voucherOrder);
//主线程获取代理对象
proxy = (IVoucherOrderService) AopContext.currentProxy();
return Result.ok(orderId);
}

7.5 Redis消息队列-基于Stream的消息队列-消费者组

9.3 好友关注-Feed流实现方案
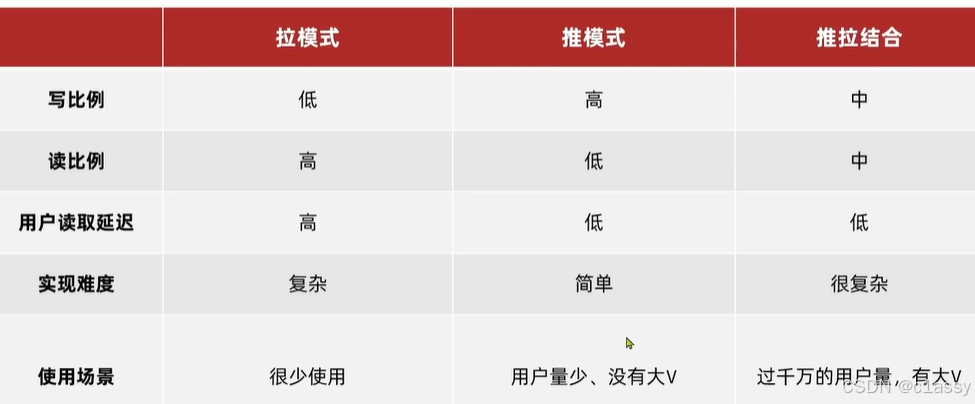
Feed流有两种模式:
- 拉模式:也叫做读扩散
该模式的核心含义就是:当张三和李四和王五发了消息后,都会保存在自己的邮箱中,假设赵六要读取信息,那么他会从读取他自己的收件箱,此时系统会从他关注的人群中,把他关注人的信息全部都进行拉取,然后在进行排序
推模式:也叫做写扩散。
- 推模式是没有写邮箱的,当张三写了一个内容,此时会主动的把张三写的内容发送到他的粉丝收件箱中去,假设此时李四再来读取,就不用再去临时拉取了
优点:时效快,不用临时拉取
缺点:内存压力大,假设一个大V写信息,很多人关注他, 就会写很多分数据到粉丝那边去
推拉模式是一个折中的方案,站在发件人这一段,如果是个普通的人,那么我们采用写扩散的方式,直接把数据写入到他的粉丝中去,因为普通的人他的粉丝关注量比较小,所以这样做没有压力,如果是大V,那么他是直接将数据先写入到一份到发件箱里边去,然后再直接写一份到活跃粉丝收件箱里边去,现在站在收件人这端来看,如果是活跃粉丝,那么大V和普通的人发的都会直接写入到自己收件箱里边来,而如果是普通的粉丝,由于他们上线不是很频繁,所以等他们上线时,再从发件箱里边去拉信息。
9.4 好友关注-推送到粉丝收件箱
需求:
- 修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
- 收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
- 查询收件箱数据时,可以实现分页查询
传统了分页在feed流是不适用的,因为我们的数据会随时发生变化:因为List查询只能按照角标查,所以不用List结构
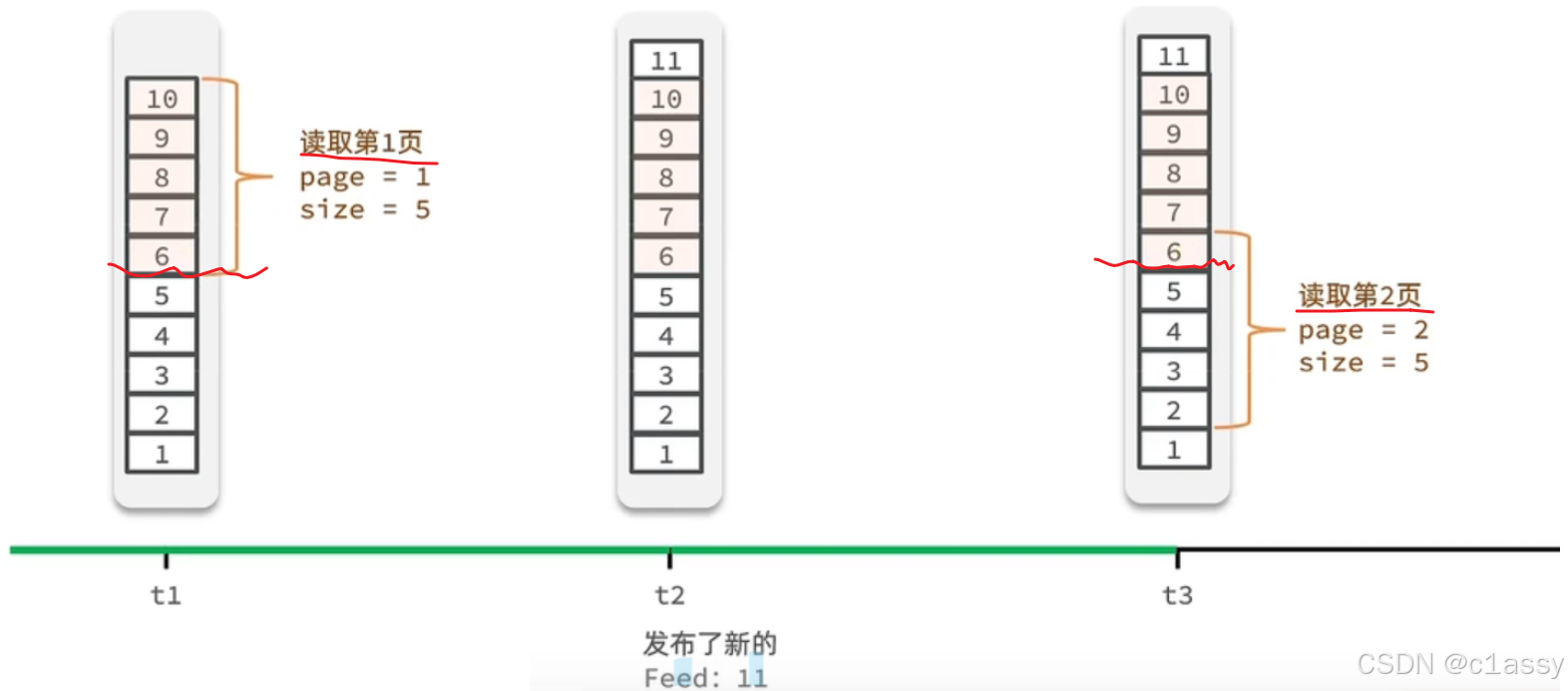
数据有变化的,不用List,而采用sortedSet来做,可以进行范围查询,并且还可以记录当前获取数据时间戳最小值,就可以实现滚动分页了
8. redis实现签到等
利用redis中的bitmap数据结构存储签到信息,把每一个bit位对应当月的每一天,形成了映射关系。
zset实现点赞排行榜
Zdd zincrby zscore
https://blog.youkuaiyun.com/m0_68657832/article/details/139177872
String key = BLOG_LIKED_KEY + id;
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if (score == null) {
// 3.如果未点赞,可以点赞
// 3.1.数据库点赞数 + 1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2.保存用户到Redis的set集合 zadd key value score
if (isSuccess) {
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
String key = FOLLOW_KEY + userId;
if (isFollow) {
// 用户为关注,则关注
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = this.save(follow);
if (isSuccess) {
// 用户关注信息保存成功,把关注的用户id放入Redis的Set集合中,
stringRedisTemplate.opsForSet().add(key, followUserId.toString());
}
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;
// 获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 写入Redis SETBIT key offset 1
stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);

















 1452
1452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









